Calcolo GPU esteso. Ottimizzazione della GPU: grandi verità. Estrazione su una scheda video: centesimi facili e falsità
Parlando delle cariche parallele sulla GPU, siamo colpevoli di memoria, a un'ora in cui viviamo, quest'anno, se tutto nel mondo è stato accelerato, trascorriamo un'ora con te, senza ricordare, come se fosse portato via. Tutto ciò che lavoriamo è connesso con l'elevata precisione e velocità di elaborazione delle informazioni, in tali menti avremo sicuramente bisogno di strumenti per elaborare tutte le informazioni, poiché dobbiamo trasformarle in dati, finora sembra che dobbiamo ricordare che questi compiti sono necessari non solo per le grandi organizzazioni, ma per le mega-corporazioni, l'ascesa di tali compiti richiederà immediatamente e file di coristuvachi, come violare le loro vite di compiti, usando le alte tecnologie a casa sui personal computer! L'emergere di NVIDIA CUDA non è stato meraviglioso, ma, più veloce, preparato, non appena sarebbe stato necessario completare attività significativamente laboriose su un PC, meno prima. Il lavoro, come prima richiedeva un'ora buona, ora ci vuole un po' di tempo, è tutto a posto nel quadro generale del mondo intero!
Qual è il calcolo sulla GPU
Calcolo sulla GPU per il calcolo della GPU per il calcolo di compiti tecnici, scientifici, on-bottom. Il calcolo sulla GPU si basa sul numero di CPU e GPU con una diversa selezione di s-simile a loro stessa: l'ultima parte del programma viene smistata dalla CPU, quindi allo stesso modo il carico di lavoro viene calcolato dalla GPU . Per questo motivo, è necessario aumentare il numero di attività, in modo che l'elaborazione delle informazioni e la modifica dell'ora di lavoro vengano eseguite il prima possibile, il sistema diventa più produttivo e può elaborare contemporaneamente un numero maggiore di attività, inferiore prima. Tuttavia, per ottenere un tale successo, non è sufficiente il solo supporto hardware, in questo caso è necessario il supporto software, in modo che il programma possa trasferire la maggior parte dei costi di manodopera alla GPU.
Cos'è CUDA
CUDA è una tecnologia di programmazione semplificata dai miei algoritmi C, che viene utilizzata su processori grafici di ottava generazione e processori GeForce precedenti, nonché su schede Quadro e Tesla simili di NVIDIA. CUDA consente di includere funzioni speciali nel testo del programma C. Queste funzioni sono scritte in modo semplificato dal mio programma C e sono scritte sul processore grafico. La prima versione di CUDA SDK è stata rilasciata il 15 febbraio 2007. Per tradurre correttamente il mio codice nel magazzino CUDA SDK, è necessario includere il compilatore C della riga di comando NVIDIA nvcc. Creazioni del compilatore nvcc basate sul compilatore open source open64 e assegnazioni per la traduzione di host-code (head, key code) e device-code (codice hardware) (file con estensione .cu) in file oggetto, appendici nel processo di compilazione dei programmi finali o librerie in qualsiasi ambiente di programmazione, ad esempio Microsoft Visual Studio.
Possibilità di tecnologia
- Linguaggio standard C per lo sviluppo parallelo di programmi su GPU.
- Pronte librerie di analisi numerica per la trasformazione svedese di Fur'є e il pacchetto base di programmi di algebra lineare.
- Driver CUDA speciale per il calcolo e il trasferimento di dati tra GPU e CPU.
- Possibilità di intermodalità del conducente CUDA driver grafici OpenGL e DirectX.
- Supporto per sistemi operativi Linux 32/64 bit, Windows XP 32/64 bit e MacOS.
La tecnologia avanza
- L'interfaccia di programmazione per i programmi CUDA (CUDA API) si basa sulla programmazione Cі mobile standard con centrali esistenti. Chiedi e semplifica il processo di sviluppo dell'architettura CUDA.
- La memoria (memoria condivisa) con una dimensione di 16 Kb, che è divisa tra i flussi, può essere rotta per organizzare una cache con un'ampia gamma di larghezza di banda, inferiore con una scelta di ottime trame.
- Transazioni più efficienti tra memoria CPU e memoria video.
- Supporto hardware Povna per operazioni ciliare e side-by-side.
Un esempio di tecnologia stosuvannya
cRak
La cosa migliore di questo programma è l'infusione. Il programma ha un'interfaccia console, ma ci sono istruzioni su come accedere al programma stesso, può essere danneggiato. Distanza puntata breve istruzione s programmi nalashtuvannya. Controlliamo la praticità del programma e lo confrontiamo con un altro programma simile, non come NVIDIA CUDA, in questo caso utilizziamo il programma Advanced Archive Password Recovery.
Dall'archivio cRark scaricato, abbiamo bisogno solo di tre file: crark.exe, crark-hp.exe e password.def. Сrark.exe utilità della console Decompressione delle password RAR 3.0 senza file crittografati nel mezzo dell'archivio (quindi dobbiamo nominarlo quando apriamo gli archivi, ma non possiamo decomprimere gli archivi senza una password).
Сrark-hp.exe - è un'utilità della console per estrarre le password RAR 3.0 dalla crittografia dell'intero archivio (quindi non possiamo nominare o estrarre archivi senza una password).
Password.def - se si vuole rinominare un file di testo anche con una piccola modifica (ad esempio: 1a riga: ## 2a riga: ?*, in tal caso la differenza di password dovrebbe essere ricavata dai segni comuni). Password.def - Catena del programma cRark. Il file ha le regole per l'apertura della password (altrimenti, l'area dei segni, come crark.exe, verrà hackerata dal suo robot). Una relazione sulla possibilità di scegliere questi segni è scritta in un file di testo, tratto dalla selezione dell'autore del programma cRark sul sito: russian.def .
Preparazione
Ti dirò ancora una volta che il programma funziona solo se la tua scheda video è basata sulla GPU del livello accelerato CUDA 1.1. Quindi la serie di schede video basate sul chip G80, come la GeForce 8800 GTX, cade, perché l'aggiornamento hardware CUDA 1.0 può puzzare. Il programma raccoglie per l'aiuto di CUDA solo le password per gli archivi RAR delle versioni 3.0+. Devi installare tutto sicurezza del software, che è correlato a CUDA , ma a se stesso:
- Driver NVIDIA che supportano CUDA a partire da 169.21
- SDK NVIDIA CUDA, a partire dalla versione 1.1
- Kit di strumenti NVIDIA CUDA, a partire dalla versione 1.1
Creiamo una cartella in un determinato luogo (ad esempio, sull'unità C:) e chiamiamola "3.2". Utilizzare i seguenti file: crark.exe, crark-hp.exe e password.def e protezione/crittografia con password degli archivi RAR.
Quindi, esegui la console della riga di comando di Windows e vai alla cartella creata. In Windows Vista, scorri per fare clic sul menu Start e inserisci "cmd.exe" nel campo del prompt, in Windows XP, dal menu Start, fai clic con il pulsante destro del mouse sulla finestra di dialogo "Vikonati" e quindi inserisci "cmd.exe" nel nuovo. Dopo aver aperto la console, inserisci un comando come: cd C:\cartella\, cd C:\3.2 nel modo che preferisci.
Digitare editor di testo due righe (puoi anche salvare il testo come file .bat dalla cartella cRark) per selezionare una password per un archivio RAR protetto da password con file non crittografati:
eco spento;
cmd /K crark (denominare l'archivio).rar
per selezionare una password per un archivio RAR protetto da password e crittografato:
eco spento;
cmd /K crark-hp (archivio nomi).rar
Copia 2 righe di un file di testo sulla console e premi Invio (o esegui un file .bat).
Risultati
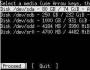
Il processo di decifrazione della testimonianza del piccolo:
La velocità di risposta su cRark per l'aiuto di CUDA era di 1625 password al secondo. In un intervallo di trentasei secondi, la password è stata scelta tra tre caratteri: “q)$”. Giusto per chiarire: la forza bruta di Advanced Archive Password Recovery sul mio processore dual-core Athlon 3000+ è fino a 50 password al secondo e la forza bruta è prevista per 5 anni. Questo è il motivo per cui l'archivio RAR bruteforce di cRark per una scheda video GeForce 9800 GTX+ aggiuntiva è visto 30 volte più veloce, inferiore sulla CPU.


Per chi ha un processore Intel va bene una scheda madre con un'elevata frequenza del bus di sistema (FSB 1600 MHz), l'indicatore di frequenza della CPU e la velocità di ricerca saranno elevati. E se hai un processore choti-core e un paio di schede video uguali a GeForce 280 GTX, il codice di forza bruta accelererà la forza bruta della password. Devo dire che il compito è stato tolto alla tecnologia CUDA per un totale di 2 anni, vale la pena parlare dell'alto potenziale di opportunità per questa tecnologia!
Visnovki
Dopo aver esaminato la tecnologia odierna per i calcoli CUDA paralleli, abbiamo concepito tutto il grande potenziale per lo sviluppo di questa tecnologia sull'applicazione del programma per il recupero delle password per gli archivi RAR. È necessario dire sulle prospettive di questa tecnologia, data tecnologia conoscere invariabilmente il posto nella vita di una persona di pelle, come renderlo veloce, qualcosa di scientifico, chi zavdannya, relativo all'elaborazione di video, o per creare un compito economico, come un accurato rozrahunka svedese, lo stesso improduttivo puoi non ricordare. Oggi il lessico inizia già a includere la frase "supercomputer domestico"; È abbastanza ovvio che per inserire un tale oggetto nella realtà in una cabina della pelle, esiste già uno strumento chiamato CUDA. Dal rilascio delle schede basate sul chip G80 (2006), un gran numero di schede basate su NVIDIA è stato rilasciato per supportare la tecnologia CUDA, come un modo per trasformare in realtà il sogno dei supercomputer in una cabina di pelle. Spingendo la tecnologia CUDA, NVIDIA aumenta la sua credibilità agli occhi dei clienti capacità aggiuntiveїх obladnannya, gli yak sono già stati acquistati dai ricchi. C'è poca speranza che CUDA si sviluppi presto ancora più velocemente e dia ai coristuvachi il mondo intero per accelerare con tutte le possibilità di calcoli paralleli sulla GPU.
Caratteristiche dell'architettura AMD/ATI Radeon
È simile alle persone di nuove specie biologiche, se, durante lo sviluppo delle sfere, le basi viventi evolvono per l'espansione dell'attaccamento al centro. Quindi, la GPU, dopo aver accelerato la rasterizzazione e il rendering delle texture dei trucchi, ha sviluppato ulteriori miglioramenti nei programmi shader per il rendering di questi trucchi. І tsі zdіbnosti sono apparse richieste da calcoli non grafici, de tempo per dare un aumento significativo della produttività rispetto alle soluzioni tradizionali.
Tracciamo analogie in lontananza: dopo l'evoluzione a lungo termine sulla terraferma, i mari sono penetrati nel mare, deprimendo i grandi sacchi marini. Nella lotta competitiva, i savt sono emersi vittoriosamente come nuove prospettive, come se fossero apparsi sulla superficie terrestre e si sono adattati in modo speciale alla vita bevendo acqua. Quindi la stessa GPU, radicata all'avanguardia nell'architettura per la grafica 3D, è più probabile che Daedalus acquisisca capacità funzionali speciali, simili alla visione di tipi di grafica distanti.
Quindi, cosa consente alla GPU di rivendicare il settore energetico nella sfera del riconoscimento del software? La microarchitettura della GPU è stata ispirata in modo diverso, inferiore nelle CPU standard, e in primo luogo, alla base del vantaggio principale. Il gestore grafico esegue un'elaborazione parallela indipendente dei dati e la GPU è multi-thread. Il parallelismo di Ale tsya per te è meno che un piacere. La microarchitettura è progettata in modo tale da sfruttare un gran numero di fili, che richiedono traspirazione.
La GPU è composta da decine di dozzine (30 per Nvidia GT200, 20 per Evergreen, 16 per Fermi), che sono chiamati Streaming Multiprocessor nella terminologia Nvidia e SIMD Engine nella terminologia ATI. Nell'ambito di questo articolo, li chiameremo miniprocessori, perché possono puzzare centinaia di thread di programma e possono essere tutti uguali a una CPU standard, ma non ancora tutti.
I nomi di marketing sono fuorvianti: indicano, per maggiore importanza, il numero di moduli funzionali, poiché possono vedere e moltiplicarsi: ad esempio, 320 "core" vettoriali (core). I chicchi di Qi più indovinano i grani. È meglio immaginare la GPU come un processore rich-core con un gran numero di core, che possono essere fatti girare senza thread contemporaneamente.
Il mini processore skin ha memoria locale, 16 KB per GT200, 32 KB per Evergreen e 64 KB per Fermi (essenzialmente, programmazione della cache L1). Potrebbe essere simile alla cache del primo livello di una CPU standard per un'ora di accesso e svolgerà funzioni simili alla consegna dei dati più recente ai moduli funzionali. Nell'architettura Fermi, parte della memoria locale può essere patchata come una cache considerevole. La GPU ha una memoria locale che serve per lo scambio svedese di dati tra i thread che vengono avvolti. Uno degli schemi più comuni dei programmi GPU è il seguente: sulla pannocchia la memoria locale è occupata dai dati della memoria globale della GPU. È solo una memoria video sonora, è ordinata (come memoria di sistema) ad eccezione del "proprio" processore - in un altro video è saldata con microcircuiti sulla textolite della scheda video. Dali centinaia di thread vengono elaborati con i dati dalla memoria locale e scrivono il risultato nella memoria globale, dopodiché viene trasferito alla CPU. Prima di obov'yazku programmatore includere istruzioni scritte zavantazhennya e dati vivantage dalla memoria locale. In effetti, è necessario battere i dati [compiti specifici] per l'elaborazione parallela. La GPU supporta anche le istruzioni di scrittura/lettura atomica in memoria, ma la puzza è inefficiente e richiede nella fase finale di incollare i risultati del calcolo di tutti i mini-processori.
La memoria locale è globale per tutti i thread archiviati in un miniprocessore, ad esempio, nella terminologia di Nvidia è chiamata condivisa e il termine memoria locale significa direttamente opposto, ma se stessa: come area personale attorno a un thread nella memoria globale, è visibile solo disponibile. Inoltre, c'è un'altra area di memoria nei miniprocessori, in tutte le architetture è circa quattro volte più grande della memoria. Il vinto è diviso equamente tra noi da fili, che vengono avvolti, ce registri per salvare il cambio e risultati intermedi di calcolo. Decine di registri cadono su un filo di pelle. La quantità esatta di tempo per depositare dipende da quanti thread vince il miniprocessore. Questo numero è molto importante, perché la latenza della memoria globale è già grande, centinaia di tick, e senza cache non c'è modo di salvare i risultati intermedi.
Un'altra cosa importante per il riso GPU è la vettorizzazione "soft". La skin del miniprocessore può avere un gran numero di moduli (8 per GT200, 16 per Radeon e 32 per Fermi), e tutti possono seguire solo una stessa istruzione, con un indirizzo di programma. E gli operandi possono essere diversi tra loro, thread diversi hanno i propri. Ad esempio, l'istruzione mettere insieme due registri: un'ora saranno conteggiate da tutti gli annessi, ma i registri sono presi in modo diverso. Si scopre che tutti i thread dei programmi GPU, che sono paralleli all'elaborazione dei dati, stanno collassando in un corso parallelo dietro il codice del programma. In questo ordine, tutti i moduli di conteggio sono ugualmente vinti. E se i thread attraverso il razgaluzhennya nel programma rozіyshlis si stanno dirigendo verso il codice, allora dovrebbe essere la cosiddetta serializzazione. Lo stesso vikoristovuyutsya nell'intera gamma di moduli di conteggio, i frammenti del thread danno istruzioni diverse e il blocco di moduli di conteggio può essere contato, come abbiamo già detto, solo l'istruzione con un indirizzo. І, ozumіlo, la propria produttività cade al massimo del cento per cento.
Un vantaggio sono quelli che la vettorizzazione viene eseguita di nuovo automaticamente, senza programmazione con le alternative SSE, MMX. І La stessa GPU gestisce le differenze. Teoricamente è possibile scrivere programmi per la GPU senza pensare alla natura vettoriale dei moduli variabili, ma la velocità di tali programmi non sarà troppo elevata. Il meno indica la grande larghezza del vettore. Ha vinto di più, un numero nominale inferiore di moduli funzionali e diventa 32 per le GPU Nvidia e 64 per Radeon. I fili sono rifilati con blocchi di dimensione variabile. Nvidia chiama questo blocco di thread il termine warp, AMD - wave front, che è lo stesso. In questo grado, sui 16 annessi di conteggio del "fronte hvilyovy", vengono tagliati lunghi 64 fili per chotiri tact (per la mente di una grande lunghezza di istruzione). L'autore considera più chiaramente il termine ordito in questo caso, attraverso l'associazione con il termine marittimo ordito, che indica l'uso di spire ritorte di una fune. Quindi i fili "si attorcigliano" e creano una solida connessione. Vtіm, "fronte d'onda" può anche essere associato al mare: le istruzioni arrivano anche agli annessi, come i venti, uno per uno, si precipitano a riva.
Se tutti i fili sono comunque scivolati attraverso i programmi vikonnі (rebuy in un posto) e, in un tale rito, si realizza un'istruzione, allora tutto è miracoloso, ma in caso contrario, sarà migliorato. In un certo senso, i fili di un ordito o di un fronte d'onda si trovano in diverse aree del programma, la puzza è divisa in gruppi di fili, che possono avere lo stesso valore del numero dell'istruzione (in altre parole, il puntatore dell'istruzione). Già come prima, i fili dello stesso gruppo vengono avvolti un'ora alla volta: tutti i fili vengono avvolti con la stessa istruzione, ma con operandi diversi. Il risultato dell'ordito cambia nello stile delle volte di più, il numero di fili nel gruppo non è significativo. Navit come gruppo è composto da un thread, lo stesso ci saranno vykonuvatisya stilks allo stesso tempo, skіlki povny warp. Al cancello, è realizzato per l'ulteriore mascheramento dei fili cantanti, in modo che le istruzioni siano formalmente malvagie, ma i risultati della traspirazione non sono registrati da nessuna parte e non vengono sviati.
Volendo allo stesso tempo, un miniprocessore skin (Streaming MultiProcessor o SIMD Engine) vykonuє іnstruktsії, scho mentire più di un warp (collegamento di thread), potrebbero esserci dozzine di warp attivi al proiettile, che è vikonuєtsі. Dopo aver seguito le istruzioni di un ordito, il miniprocessore non calpesterà le istruzioni dei fili di questo ordito, ma le istruzioni di un altro ordito. Quell'ordito può trovarsi in una certa altra area del programma, se non paghi sulla velocità, quindi solo a metà dell'ordito sono dovute le istruzioni di tutti i fili, ma lo stesso per l'ordito con il piena velocità.
In questo tipo di skin con 20 motori SIMD, potrebbe esserci un fronte d'onda attivo e la skin con 64 thread. Filo di pelle con una linea corta. Totale: 64×4×20=5120 fili
In questo modo, guardando quelli che skin warp o wave front sono costituiti da 32-64 thread, il miniprocessore potrebbe avere centinaia di thread attivi, che sono quasi dall'oggi al domani. Di seguito, possiamo vedere quanto è grande il numero di thread paralleli, come in un modo architettonico, ma possiamo guardare il retro, come un obmezhennya nei processori mini-GPU di magazzino.
Peccato che non ci sia stack nella GPU, quindi non è stato possibile salvare i parametri delle funzioni e le modifiche locali. Attraverso un gran numero di fili per la pila, semplicemente non c'è spazio sul cristallo. Infatti, poiché la GPU ha un clock vicino a 10.000 thread contemporaneamente, quando si espande lo stack di un thread in 100 KB, il volume di archiviazione totale è di 1 GB, che è più del volume di memoria video standard. Tim è più grande, non c'è la possibilità di posizionare uno stack di una sorta di spazio scalabile nel cuore stesso della GPU. Ad esempio, se metti 1000 byte di stack per thread, è necessario solo 1 MB di memoria per un miniprocessore, che potrebbe essere cinque volte di più per la quantità totale di memoria locale del processore minimo e memoria allocata per il salvataggio registri.
Ecco perché non c'è ricorsione nei programmi GPU e non sarai particolarmente entusiasta delle chiamate di funzione. Queste funzioni vengono introdotte direttamente nel codice durante la compilazione del programma. Tse circondano la sfera del blocco della GPU con compiti di tipo numerico. A volte è possibile passare dall'emulazione dello stack agli algoritmi ricorsivi della memoria globale con una ridotta profondità di iterazioni o un sovraccarico della GPU atipico. Pertanto, è necessario espandere in modo speciale l'algoritmo, per garantire la possibilità di implementazione senza garanzia di un'accelerazione riuscita contro la CPU.
Fermi ha mostrato per primo la possibilità di funzioni virtuali vittoriose, ma si è limitato anche al giorno della grande cache svedese per il filo di cuoio. Per 1536 thread, cadono 48 KB o 16 KB L1, in modo che le funzioni virtuali nel programma possano essere vittoriosamente raramente, altrimenti per lo stack c'è anche memoria globale sufficiente per supportare la vittoria e, cosa più importante, non apportare modifiche la variante CPU.
In questo modo, la GPU si presenta nel ruolo di uno spivprocessor computazionale, in cui vengono presi i dati, la puzza viene elaborata da qualche algoritmo e si vede il risultato.
Vantaggi dell'architettura
Ale vvazha GPU duzhe shvidko. І in questo modo, il multithreading aiuta con questo tempio. Un gran numero di thread attivi consente di allegare spesso una grande latenza dell'espansione intorno alla memoria video globale, che si avvicina a 500 cicli. È particolarmente utile per il codice con un'alta densità di operazioni aritmetiche. In questo modo non è necessaria alcuna strada dal punto di vista dei transistor nella gerarchia delle cache L1-L2-L3. Sostituendolo su un cristallo si possono posizionare una pluralità di moduli di conteggio, garantendo la stessa produttività aritmetica. E mentre vengono coniate le istruzioni di un filo di un ordito, centinaia di fili possono essere facilmente controllati sui tuoi dati.
Fermi ha introdotto una cache di un'altra uguale dimensione di circa 1 MB, ma non può essere paragonata alle cache dei moderni processori, ci sono più usi per la comunicazione tra kernel e diversi trucchi software. Come se yogo rosmarino fosse diviso tra decine di migliaia di fili, sulla pelle ci sarà un obbligo insignificante.
Ale, crim di latenza della memoria globale, nell'estensione computazionale ci sono ancora latenze impersonali, come se dovessi prenderlo. Integrità della latenza di trasmissione in mezzo al cristallo dal conteggio degli allegati alla cache di primo livello, alla memoria locale della GPU, e ai registri, oltre alla cache delle istruzioni. File di registrazione, come memoria locale, roztashovani okremo in moduli funzionali e l'accesso ad essi per diventare circa la seconda dozzina di cicli. E ancora, il numero di thread, warp attivi, è ancora elevato, consentendoti di catturare efficacemente la latenza. Inoltre, la larghezza di banda (larghezza di banda) per accedere alla memoria locale dell'intera GPU è notevole, mentre è stato migliorato il numero di mini-processori di archiviazione, notevolmente maggiore, la larghezza di banda inferiore per l'accesso alla cache di primo livello nelle moderne CPU. La GPU può essere ricostruita significativamente più dati all'ora.
Si può dire che se la GPU non sarà dotata di un gran numero di thread paralleli, la nuova avrà produttività zero, che è la colpa di questo stesso ritmo, avrò bisogno di più entanglement e avremo una minore carico di lavoro. Ad esempio, sostituiamo 10.000 thread con più di uno: la produttività calerà circa mille volte, perché non solo non tutti i blocchi saranno occupati, ma appariranno tutte le latenze.
Il problema di collegare le latenze allo stato dell'arte e per le moderne CPU ad alta frequenza, per її l'uso di metodi di assottigliamento - deep konveierizatsija, poi vykonannya іnstruktsіy (fuori servizio). Per quello che ti serve pianificatori e istruzioni pieghevoli, diversi tamponi, ecc., che occupino spazio sul cristallo. Tutto è necessario per la più breve produttività in modalità single-thread.
Ma per la GPU non tutto è necessario, è architettonicamente perfetta per contare attività con un gran numero di flussi. Allora il vino trasforma il flusso della ricchezza in produttività, come una pietra filosofale trasforma il piombo in oro.
GPU un mucchio di allegati per lo shading ottimale dei programmi shader per i pixel trick, che, ovviamente, sono indipendenti e possono essere hackerati in parallelo. Diventerò colpevole di evolvermi aggiungendo varie capacità (memoria locale e accesso di indirizzamento alla memoria video, nonché un insieme semplificato di istruzioni) a un componente aggiuntivo di calcolo troppo stretto, che può ancora essere effettivamente consentito per il implementazione della memoria locale obsyagu obsyagu limitata.
Culo
Uno dei compiti classici per la GPU è il compito di calcolare l'interdipendenza di N fino a, che crea un campo gravitazionale. Ma se noi, per esempio, abbiamo bisogno di sviluppare l'evoluzione del sistema Terra-Luna-Sole, allora la GPU è per noi uno sporco aiutante: gli oggetti sono pochi. Per un oggetto skin, è necessario calcolare il numero totale di altri oggetti, ad esempio due in totale. Ai tempi del sistema Sonyachny con molti pianeti in quei mesi (circa poche centinaia di oggetti), la GPU è ancora poco efficiente. Vtіm, e un processore ricco di core attraverso alti costi generali sul controllo del flusso non può mostrare tutta la sua potenza, ma in modalità single-thread. Ma se è anche necessario espandere le traiettorie di comete e oggetti nella cintura degli asteroidi, allora è già un compito per la GPU, quindi ci sono abbastanza oggetti per creare il numero necessario di flussi paralleli da espandere.
Anche la GPU dovrebbe mostrarsi gentile, in quanto è necessaria per ripulire gli spazi ristretti di centinaia di migliaia di stelle.
Un'altra possibilità per battere la pressione della GPU nell'attività N fino a quando è necessario risolvere l'attività impersonale, lasciare che sia con una piccola quantità di tempo. Ad esempio, è necessario sviluppare le opzioni di evoluzione di un sistema per diverse opzioni di cob shvidkos. Per ottimizzare efficacemente la GPU per andare senza problemi.
Dettagli della microarchitettura AMD Radeon
Abbiamo esaminato i principi di base dell'organizzazione della GPU, la puzza è assonnata per i processori video dei nostri vibratori, quindi avevano un obiettivo in mente: i programmi shader. I prototipisti conoscevano la capacità di espandersi nei dettagli dell'implementazione della microarchitettura. Sebbene le CPU di altri fornitori siano a volte fortemente scosse, sono sommariamente, come, ad esempio, Pentium 4 e Athlon o Core. L'architettura di Nvidia è già ampiamente conosciuta, in un momento possiamo guardare Radeon e sembra essere la caratteristica principale degli approcci di questi vendor.
Le schede video AMD hanno tolto il prezzo pieno del riconoscimento principale alla famiglia Evergreen, in cui hanno implementato in precedenza anche le specifiche DirectX 11.
I dettagli dell'espansione della memoria locale (32 KB per Radeon contro 16 KB per GT200 e 64 KB per Fermi) non sono affatto importanti. Come espandere il fronte d'onda in 64 thread per AMD contro 32 thread per warp in Nvidia. In pratica, se un programma GPU può essere facilmente riconfigurato e adattato ai parametri digitali. La produttività può cambiare di decine di centinaia, ma per una GPU non è così importante, perché il programma GPU suona dieci volte meglio, l'analogo più basso per la CPU, o dieci volte più veloce, oppure non funziona.
La più importante è la tecnologia AMD VLIW (Very Long Instruction Word). Nvidia vicorist scalari semplici istruzioni, che operano con registri scalari. Її prikoryuvachі implementa un semplice RISC classico. Le schede video AMD possono avere lo stesso numero di registri della GT200, ma anche registri vettoriali a 128 bit. Skin VLIW-instruktsiya gestisce dekilkom chotirikomponentnym registri a 32 bit, scho SSE, ma la possibilità di VLIW più ricca. Non SIMD (Single Instruction Multiple Data), come SSE - qui le istruzioni per la coppia di skin dell'operando possono essere diverse e simili! Ad esempio, le componenti del registro A siano chiamate a1, a2, a3, a4; per il registro B - allo stesso modo. È possibile calcolare un'istruzione per ulteriore aiuto, come vincere in un ciclo di clock, ad esempio il numero a1×b1+a2×b2+a3×b3+a4×b4 o un vettore bidimensionale (a1×b1+ a2×b2, a3×b3+a4×b4).
È diventato possibile rallentare le frequenze più basse della GPU, abbassare quelle della CPU e un forte cambiamento dei processi tecnici nei restanti destini. Con questo, non c'è bisogno di una normale pialla, molte delle quali vengono battute per battito.
Seguendo le istruzioni del vettore, il picco di produttività di Radeon in numeri a precisione singola è già più alto e diventa già teraflop.
Un registro vettoriale può sostituire quattro numeri a precisione singola e salvare un numero a precisione variabile. Un'istruzione VLIW può aggiungere due coppie di numeri doppi, o moltiplicare due numeri, oppure moltiplicare due numeri e quindi aggiungere il terzo. Pertanto, la produttività massima in double è circa cinque volte inferiore a quella in float. Per i vecchi modelli Radeon, le prestazioni di Nvidia Tesla sulla nuova architettura Fermi sono superiori e inferiori rispetto alle prestazioni delle doppie schede sull'architettura GT200. Per le vecchie schede video Geforce basate su Fermi, la velocità massima del doppio calcolo è stata quadruplicata.

Lo schema del robot Radeon è importante. Presentato solo un miniprocessore su 20 funzionante in parallelo
Gli hack della GPU simili agli hack della CPU (per quelli pazzi per x86) non sono legati al potere della follia. Il programma GPU viene compilato in un codice intermedio e, quando il programma viene avviato, il driver compila il codice in istruzioni macchina specifiche per un particolare modello. Come descritto sopra, i produttori di GPU si sono affrettati a trovare un efficiente ISA (Instruction Set Architecture) per le loro GPU ea cambiare questi tipi di generazione in generazione. Tse, in ogni caso, ha aggiunto qualche centinaio di produttività tramite il decoder giornaliero (per non necessario). Ma l'azienda AMD è andata oltre, prevedendo formato ufficiale istruzioni di decodifica per codice macchina. La puzza non è ordinata in sequenza (dall'elenco del programma), ma in sezioni.
Sul retro è presente una sezione di istruzioni per transizioni intelligenti, che possono essere inviate a sezioni senza interruzioni di istruzioni aritmetiche, adatte a diverse transizioni. Sono chiamati bundle VLIW (collegamenti di istruzioni VLIW). In queste sezioni ci sono solo voci aritmetiche con dati da registri o memoria locale. Tale organizzazione faciliterà la gestione del flusso di istruzioni e la consegna delle stesse agli annessi. Questo è il modo migliore, vrakhovuyuchi scho VLIW-іnstruktsії potrebbe essere ugualmente eccezionale. Іsnuyut anche sezioni per le istruzioni zvernenen a memoria.
| Sezioni di istruzioni per transizioni intelligenti | ||||
|---|---|---|---|---|
| Sezione 0 | dissalazione 0 | Invio alla sezione n. 3 senza interruzioni di istruzioni aritmetiche | ||
| Sezione 1 | Rifinitura 1 | Domanda per la sezione n. 4 | ||
| Sezione 2 | dissalazione 2 | Domanda per la sezione n. 5 | ||
| Sezioni di istruzioni aritmetiche ininterrotte | ||||
| Sezione 3 | Istruzione VLIW 0 | Istruzione VLIW 1 | Istruzione VLIW 2 | Istruzione VLIW 3 |
| Sezione 4 | Istruzione VLIW 4 | Istruzione VLIW 5 | ||
| Sezione 5 | Istruzione VLIW 6 | Istruzione VLIW 7 | Istruzione VLIW 8 | Istruzione VLIW 9 |
Entrambe le GPU (Nvidia, AMD) possono anche fornire istruzioni per calcolare il calcolo per ciclo di funzioni matematiche di base, radice quadrata, esponenziale, logaritmo, seno e coseno per numeri a precisione singola. Io a quello є blocchi di enumerazione speciali. Il fetore "era disturbato" per la necessità di implementare una rapida approssimazione di queste funzioni negli shader geometrici.
Yakby naviga fino a non sapere che le GPU vincono per la grafica e ne diventa più consapevole caratteristiche tecniche, quindi per il momento si indovina che il numero di spivprocessor dovrebbe assomigliare a videopriskoryuvachiv. Allo stesso modo, dietro gli antichi risi dei savt di mare, i vcheni si resero conto che i loro antenati erano fonti di terra.
Ma il più ovvio è il riso, che sembra un'estensione grafica, blocchi di lettura di texture bidimensionali e tridimensionali per un'ulteriore interpolazione bilineare. La puzza è ampiamente utilizzata nei programmi GPU, i frammenti sono più veloci e facili da leggere in array di dati di sola lettura. Una delle opzioni standard per il comportamento dell'addendum della GPU è la lettura di array di dati esterni, l'elaborazione in core di enumerazione e la scrittura del risultato in un altro array, che viene ritrasferito alla CPU. Tale schema è standard ed esteso, adatto all'architettura della GPU. Attività che richiedono un'intensa lettura e scrittura in una grande area della memoria globale, per vendicare, in una tale posizione, lo stallo dietro i dati, è importante implementare in modo efficiente il parallelismo sulla GPU. Inoltre, la loro produttività dipende fortemente dalla latenza della memoria globale, anche se è ottima. E da ciò che l'attività è descritta dal modello "lettura dei dati - elaborazione - scrittura del risultato", puoi cantare un grande aumento dell'output sulla GPU.
Per i dati delle texture GPU, esiste una gerarchia di piccole cache della prima e delle altre regioni. Vaughn e bezpechuє priskornnya con le trame vikoristannya. Questa gerarchia è apparsa nei processori grafici per velocizzare l'accesso locale alle texture: ovviamente, dopo aver elaborato un pixel per un pixel secondario (con alta efficienza), è necessario chiudere l'elaborazione dei dati delle texture. Tuttavia, ci sono molti algoritmi per i calcoli più significativi e potrebbe esserci una natura simile di accesso ai dati. Inoltre, le cache delle texture dalla grafica saranno più marroni.
Sebbene l'espansione della cache L1-L2 per le schede Nvidia e AMD sia approssimativamente simile, il che, ovviamente, non è possibile a causa dell'ottimalità delle schede grafiche, la latenza di accesso a queste cache è in continua evoluzione. La latenza di accesso di Nvidia è maggiore e le cache delle texture in Geforce tendono ad aiutare ad accelerare il bus di memoria, piuttosto che accelerare l'accesso ai dati. Questo non è importante per i programmi grafici, ma è importante per le applicazioni software. Radeon ha una latenza della cache delle texture inferiore, ma è migliore per la latenza della memoria locale dei miniprocessori. È possibile segnalare un esempio del genere: per la moltiplicazione ottimale delle matrici sulle schede Nvidia, è più veloce velocizzare la memoria locale, facendo sparire le matrici affiancate, e AMD è migliore affidarsi alla cache delle texture a bassa latenza, leggendo gli elementi della matrice nel mondo del consumo. Ale tse dosit fine optimization, e fondamentalmente già tradotto nell'algoritmo della GPU.
Questa differenza si manifesta anche in diversi tipi di texture 3D. Uno dei primi benchmark da calcolare sulla GPU, che ha mostrato la seria superiorità di AMD, è la più comune texture 3D, i cui frammenti sono stati elaborati dalla più banale matrice di dati. E la latenza di accesso alle texture di Radeon è molto più veloce e l'adattamento 3D è più avanzato rispetto alle ottimizzazioni dell'otturatore.
Per otrimanna massima produttività secondo la sala di varie aziende, il rapporto di tuning necessario per una specifica scheda, ma è significativamente meno importante, inferiore al principio di sviluppo dell'algoritmo per l'architettura della GPU.
Scambio della serie Radeon 47xx
Per questa famiglia, il calcolo sulla GPU non è corretto. Puoi nominarne tre momento importante. In primo luogo, non c'è memoria locale, quindi è fisicamente impossibile, ma non c'è possibilità di accesso universale, come richiesto dall'attuale standard dei programmi GPU. Non sarà programmaticamente nella memoria globale, quindi non porterà alcun vantaggio all'esecuzione su una GPU completa. Un altro punto è che le istruzioni per diverse istruzioni di operazioni atomiche dalla memoria e le istruzioni di sincronizzazione sono state tagliate. І il terzo momento: non è necessario completare una piccola espansione della cache delle voci: a partire dall'espansione del programma, aumenta l'aumento della velocità. Є inshі drіbnі obmezhennya. Si può dire che solo i programmi ideali per la GPU potranno essere utilizzati su questa scheda video. Utilizziamo dei semplici programmi di test che funzionano solo con un registro, una scheda video può mostrare un buon risultato con i Gigaflop, ma è problematico programmarla in modo più efficiente.
Vantaggi e difetti Evergreen
Se si confrontano i prodotti AMD e Nvidia, guardando la GPU, la serie 5xxx sembra un GT200 ancora più stretto. Così stretto, che per la massima produttività ribalta Fermi di circa due volte e mezzo. Tanto più che i parametri delle nuove schede video Nvidia sono stati ridotti, il numero di core è stato accorciato. E l'aspetto della cache L2 in Fermi renderà più semplice l'implementazione di determinati algoritmi sulla GPU, ampliando così l'ambito del jamming GPU. Ebbene, per una buona ottimizzazione dell'ultima generazione GT200, i programmi CUDA delle innovazioni architettoniche di Fermi spesso non davano nulla. La puzza è accelerata proporzionalmente all'aumento del numero di moduli di conteggio, quindi è meno inferiore (per i numeri a precisione singola), o meno, perché la larghezza di banda della memoria non è aumentata (per altri motivi).
І in compiti che vanno bene per l'architettura GPU, che possono mostrare la natura vettoriale (ad esempio, matrici moltiplicate), Radeon mostra prestazioni vicine al picco teorico e supera Fermi. Non sembra già per la ricca CPU nucleare. Soprattutto nei problemi con numeri a precisione singola.
Ale Radeon potrebbe avere meno area cristallina, meno termografia, risparmio energetico, più accessori e, apparentemente, meno varietà. E senza intoppi nella grafica 3D, Fermi vince, così come vzagali є, un tipo di vendita al dettaglio riccamente più piccolo nell'area del cristallo. È ricco di motivi per cui viene spiegato che il numero di architettura Radeon con 16 numero di componenti aggiuntivi per un miniprocessore, una dimensione del fronte d'onda di 64 thread e istruzioni VLIW vettoriali è un eccellente compito principale per lo yoga: il numero di shader grafici . Per i giocatori più importanti, la produttività nei giochi e il prezzo sono una priorità.
Dal punto di vista dei programmi scientifici e professionali, l'architettura Radeon garantisce la più efficiente produttività in termini di costi, produttività per watt e produttività assoluta nelle attività, che in linea di principio rispettano l'architettura della GPU, consentono la parallelizzazione e la vettorizzazione.
Ad esempio, per una selezione di attività più parallele delle chiavi Radeon, che è facile da vettorializzare, il numero di volte più veloce di Geforce e una dozzina di volte maggiore per la CPU.
Pertanto, supporta il concetto fondamentale di AMD Fusion, motivo per cui la GPU è responsabile dell'integrazione della CPU, e in futuro può essere integrata nel core della CPU stessa, poiché prima il processore matematico veniva trasferito dal cristallo verde al core del processore (fu fatale vent'anni prima della comparsa Processori Pentium). La GPU sarà un core grafico integrato e un processore vettoriale per le attività di streaming.
Radeon vince una tecnica astuta per mescolare istruzioni con diversi fronti d'onda quando si utilizzano moduli funzionali. È facile da lavorare, perché le istruzioni sono completamente indipendenti. Il principio è analogo all'avvolgimento in pipeline di istruzioni indipendenti da parte delle attuali CPU. Ovviamente, ti consente di concatenare efficacemente, che occupano molti byte, le istruzioni VLIW vettoriali. La CPU necessita di un pianificatore pieghevole per visualizzare istruzioni indipendenti o utilizzare la tecnologia Hyper-Threading, poiché protegge anche la CPU con istruzioni indipendenti da thread diversi.
| misura 0 | barra 1 | misura 2 | misura 3 | barra 4 | barra 5 | barra 6 | barra 7 | modulo VLIW | |
| fronte d'onda 0 | fronte d'onda 1 | fronte d'onda 0 | fronte d'onda 1 | fronte d'onda 0 | fronte d'onda 1 | fronte d'onda 0 | fronte d'onda 1 | ||
|---|---|---|---|---|---|---|---|---|---|
| → | istr. 0 | istr. 0 | istr. sedici | istr. sedici | istr. 32 | istr. 32 | istr. 48 | istr. 48 | VLIW0 |
| → | istr. uno | … | … | … | … | … | … | … | VLIW1 |
| → | istr. 2 | … | … | … | … | … | … | … | VLIW2 |
| → | istr. 3 | … | … | … | … | … | … | … | VLIW3 |
| → | istr. 4 | … | … | … | … | … | … | … | VLIW4 |
| → | istr. 5 | … | … | … | … | … | … | … | VLIW5 |
| → | istr. 6 | … | … | … | … | … | … | … | VLIW6 |
| → | istr. 7 | … | … | … | … | … | … | … | VLIW7 |
| → | istr. otto | … | … | … | … | … | … | … | VLIW8 |
| → | istr. nove | … | … | … | … | … | … | … | VLIW9 |
| → | istr. dieci | … | … | … | … | … | … | … | VLIW10 |
| → | istr. undici | … | … | … | … | … | … | … | VLIW11 |
| → | istr. 12 | … | … | … | … | … | … | … | VLIW12 |
| → | istr. tredici | … | … | … | … | … | … | … | VLIW13 |
| → | istr. quattordici | … | … | … | … | … | … | … | VLIW14 |
| → | istr. quindici | … | … | … | … | … | … | … | VLIW15 |
128 istruzioni per due fronti d'onda, che consistono in 64 operazioni, sono collegate da 16 moduli VLIW per la maggior parte dei clock. È necessario disegnare e il modulo pelle può effettivamente richiedere due cicli per seguire l'intera istruzione per la mente, quale dei vini dell'altro ciclo ha maggiori probabilità di vincerne uno nuovo in parallelo. Imovirno, aiuta a sovrascrivere le istruzioni VLIW di tipo a1×a2+b1×b2+c1×c2+d1×d2, per sovrascrivere tutte queste istruzioni per tutti i cicli di clock. (Uscire formalmente, uno per orologio.)
Probabilmente Nvidia non ha quel tipo di tecnologia. І senza VLIW, per un'elevata produttività con più istruzioni scalari richieste alta frequenza robot che spostano automaticamente la termografia e appendono luci alte processo tecnologico(per progettare uno schema per un'alta frequenza più alta).
La Radeon di breve durata dal punto di vista del calcolo della GPU è molto antipatica al punto da essere ingannata. GPU vzagalі non shanyuyut razgaluzhennya attraverso la tecnologia sopra descritta vykonannya instruktsіy: vіdrazu gruppo di thread con un indirizzo di programma. (A proposito, questa tecnica si chiama SIMT: Single Instruction - Multiple Threads (un'istruzione - molti thread), analogo a SIMD, dove un'istruzione consiste in un'operazione con tributi diversi.) 'yazuvannya thread. Si è capito che se il programma non è vettoriale, maggiore è l'espansione dell'ordito o del fronte d'onda, ancora più importante, più gruppi verranno stabiliti in caso di espansione in futuro per il programma dei fili vascolari, è necessario vincere in sequenza (serializzato). È accettabile che tutti i thread si siano diffusi, anche se l'ordito si è espanso in 32 thread, il programma è pracyuvatime in 32 e più volte. E razіrozіru 64, come la Radeon, - 64 volte più povіlnіshe.
Ricorda, ma non l'unico che mostra "ostilità". Le schede video Nvidia hanno un modulo funzionale skin, altrimenti chiamato CUDA core, e possono avere un blocco di elaborazione speciale. E per le schede video Radeon con 16 moduli, ci sono un totale di due blocchi per il controllo dei blocchi aritmetici (non ci sono blocchi aritmetici nel dominio). Quindi è facile seguire le istruzioni per la transizione intelligente, lasciare che il risultato sia lo stesso per tutti i fili del fronte d'onda, ci vuole un'ora in più. І shvidkіst prosіdaє.
AMD sta girando la CPU. La puzza vvazhayut, che per i programmi con un gran numero di razgaluzhen tutto è più adatto per la CPU e per le assegnazioni della GPU per i programmi vettoriali.
Quindi Radeon offre un'opportunità complessivamente inferiore per una programmazione efficiente, ma offre il miglior rapporto costo-prestazioni per una varietà di modalità. In altre parole, i programmi possono essere trasferiti in modo efficiente (senza costi) dalla CPU a Radeon, meno programmi inferiori possono essere eseguiti efficacemente su Fermi. Ale tі, yakі può essere trasferito efficacemente, pratsyuvatimut su Radeon in modo efficiente nei sensi ricchi.
API per il calcolo tramite GPU
Le specifiche molto tecniche della Radeon sembrano belle, non lasciano che sia perfetta e rendono il calcolo assolutamente assoluto sulla GPU. Ma non meno importante per la produttività è la sicurezza del software, necessaria per lo sviluppo e lo sviluppo di programmi GPU - compilatori per filmati di alta qualità e runtime, ovvero un driver che modifica l'interazione tra una parte del programma che lavora su la CPU, quella senza la GPU centrale. Dovrebbe essere più importante, più basso nel caso della CPU: non è necessario un driver per la CPU, il che migliorerebbe la gestione del trasferimento dei dati, e il compilatore GPU sembra più potente. Ad esempio, il compilatore è responsabile dell'utilizzo del numero minimo di registri per raccogliere risultati intermedi, nonché del conteggio accurato delle chiamate di funzione, sempre con un numero minimo di registri. Anche se c'è meno registro del thread vicorist, è possibile avviare più thread e più navantage della GPU, tempi migliori per l'accesso alla memoria.
Il primo asse del supporto software per i prodotti Radeon è ancora in corso nello sviluppo della sala. (Sulla base della situazione con Nvidia, dove è stato rilasciato il lancio, e il prodotto sembra un nuovo prodotto.) Più recentemente, il compilatore OpenCL di AMD ha raggiunto lo stato beta, ma non è un grosso problema. Visto che spesso generava un codice di grazia, o compilava il codice dal testo di output corretto, o dopo aver visto lui stesso la grazia, il robot si è bloccato. Solo per motivi di primavera viyshov rilascia dall'alta pratica. In tezh non perdono i perdoni, ma è diventato significativamente meno e puzza incolpare le linee di fallo, se sono programmate sull'intercorrettezza. Ad esempio, utilizzare il tipo uchar4 per specificare una modifica del componente choti a 4 byte. Questo tipo è nelle specifiche di OpenCL, ma non è possibile utilizzarlo su Radeon, ma il registro è a 128 bit: questi sono alcuni dei componenti, ma a 32 bit. E un tale cambiamento di uchar4 tutto un prestito tsiliy registr, saranno necessarie solo altre operazioni di imballaggio aggiuntive e accesso a componenti fino a ocremi byte. Il compilatore non è colpevole della madre dei perdoni quotidiani, ma non ci sono compilatori senza carenze. Navit Intel Compiler dopo la versione 11 potrebbe perdonare la compilazione. Le scuse sono state corrette per l'imminente rilascio, che sarà più vicino all'autunno.
Eppure ci sono ancora discorsi muti, che richiederanno ulteriore supporto. Ad esempio, il driver GPU standard per Radeon non supporta il calcolo GPU con le stranezze di OpenCL. Koristuvach è responsabile dell'organizzazione e dell'installazione di un pacchetto speciale aggiuntivo.
E soprattutto - l'esistenza di eventuali librerie di funzioni. Per i numeri vocali di accuratezza sottovariabile, non c'è seno, coseno o esponente. Bene, per aggiungere e moltiplicare matrici non è necessario, ma se vuoi programmare in modo più fluido, devi scrivere tutte le funzioni da zero. Abo controlla una nuova versione dell'SDK. ACML (AMD Core Math Library) per la GPU Evergreen con supporto per le principali funzioni della matrice può essere presto sviluppato.
Al momento, secondo l'autore dell'articolo, è reale che la programmazione delle schede video Radeon utilizzi API Direct Compute 5.0, naturalmente Piattaforma Windows 7 e Windows Vista. Microsoft potrebbe avere una grande conoscenza dei compilatori e possiamo controllare presto l'ultima versione di produzione, Microsoft è completamente citata a questo proposito. Ale Direct Calcolo degli orientamenti alle esigenze degli add-on interattivi: per verificare e visualizzare il risultato, ad esempio bypassando la superficie in superficie. Tse non significa che lo yoga non può essere vinto semplicemente per rozrakhunkiv, ma non significa yoga per il riconoscimento naturale. Diciamo che Microsoft non prevede di aggiungere funzioni di libreria a Direct Compute, proprio come AMD non ha. Quindi quelli che possono essere efficacemente intercettati in una volta su Radeon - non hanno bisogno di essere ridotti ai programmi - possono essere implementati su Direct Compute, che è molto più semplice di OpenCL e può essere stabile. Inoltre, è più portatile, pratico e su Nvidia e su AMD, quindi devi compilare il programma una sola volta, anche se l'implementazione dell'SDK OpenCL di Nvidia e AMD non costa molto. (In tal senso, se vuoi espandere un programma OpenCL su sistemi AMD con versioni di AMD OpenCL SDK, potresti non essere in grado di bere così facilmente su Nvidia. È possibile, è necessario compilare lo stesso testo dalle versioni di Nvidia SDK .
Quindi, OpenCL ha molte funzionalità trascendentali, frammenti di idee OpenCL come API di programmazione del linguaggio universale per un'ampia gamma di sistemi. І GPU, і CPU, і Cell. Quindi, a quanto pare, se hai solo bisogno di scrivere un programma per un tipico sistema core (processore più scheda video), OpenCL non sembra essere, per così dire, "altamente produttivo". La funzione skin può avere dieci parametri e nove di essi devono essere impostati su 0. E per impostare il parametro skin, è necessario chiamare una funzione speciale, in modo da poter avere parametri.
Il primo grande vantaggio in streaming di Direct Compute è che non è necessario installare un pacchetto speciale: tutto ciò di cui hai bisogno è già in DirectX 11.
Problemi di sviluppo della GPU
Che ne dici di prendere la sfera computer personale, La situazione è la seguente: non c'è un compito così ricco, per chi ha bisogno di una grande pressione e non di un potente processore dual-core. Dal mare alla terra, i miracoli grandi, senza pretese, ma non giranti, ma sulla terra, non poteva succedere nulla. Le prime tranquille dimore della superficie terrestre cambiano alle roselands, iniziano a calmarsi meno, come se sempre con una carenza di risorse naturali. Yakby allo stesso tempo era la stessa esigenza di produttività, come 10-15 anni fa, il calcolo della GPU sarebbe stato accettato con il botto. E così vengono alla ribalta i problemi di coerenza e complessità visiva della programmazione GPU. È meglio scrivere un programma che funzioni su tutti i sistemi, un programma inferiore che funzioni rapidamente, ma che funzioni solo sulla GPU.
Le prospettive per le GPU sono molto migliori dal punto di vista delle integrazioni professionali e dei settori delle workstation, quindi c'è più richiesta di produttività. Ci sono plug-in per editor 3D dietro l'aiuto della GPU: ad esempio, per il rendering per l'aiuto delle modifiche alla modifica, non perderti con l'ottimo rendering della GPU! Fai appello agli editor 2D e agli editor di presentazioni per accelerare la creazione di effetti di piegatura. Anche i programmi per l'elaborazione video, passo dopo passo, fanno tagliare la GPU. L'introduzione di una nuova attività, osservando la sua realtà parallela, fa bene all'architettura della GPU, ma allo stesso tempo è stata creata, migliorata e ottimizzata una base di codice ampia per tutte le capacità della CPU, quindi ci è voluta un'ora prima che le buone implementazioni della GPU. apparire.
In questo segmento, vengono mostrati i lati deboli della GPU, poiché la quantità di memoria video richiesta è di circa 1 GB per le migliori GPU. Uno dei principali fattori che riducono la produttività dei programmi GPU è la necessità di scambiare dati tra CPU e GPU sull'intero bus e, attraverso lo scambio di memoria, è possibile trasferire più dati. E qui il concetto AMD di combinare GPU e CPU in un unico modulo sembra promettente: puoi sacrificare uno sballo costruzione della produttività memoria grafica per motivi di facilità e facile accesso alla memoria globale e ancora meno latenza. La larghezza di banda di memoria più elevata dell'ultima memoria video DDR5 è molto più richiesta senza intermediari programmi di grafica, Qual è il software più calcolato dalla GPU. Vzagali, la memoria di GPU e CPU serve semplicemente ad ampliare la sfera di congestione della GPU, ad aumentare il numero di possibilità per piccoli programmi software.
І è necessaria la maggior parte delle GPU nel campo dell'informatica scientifica. Sono già stati sviluppati alcuni supercomputer basati su GPU, che già mostrano un risultato elevato nel test delle operazioni su matrice. La scienza è così diversificata e numerica che è sempre nota per essere impersonale, come un miracolo giace sull'architettura della GPU, per la quale la GPU consente di prendere facilmente un'elevata produttività.
Qual è la metà della giornata computer moderni scegline uno, poi lo farai computer grafica- Immagine del mondo, in cui viviamo. E l'architettura è ottimale per la città, non può essere brutta. I pavimenti di Tse sono importanti, quel compito fondamentale, che è appositamente progettato per esso, può portare versatilità in sé ed essere ottimale per diversi compiti. Inoltre, le schede video si stanno evolvendo con successo.
Wiki della GPU per la guida di C++ AMP
I dosi nei metodi discussi della programmazione parallela sembravano nient'altro che un core di processore. Abbiamo aggiunto alcuni nuovi arrivati alla parallelizzazione di programmi da un gran numero di processori, sincronizzando l'accesso a risorse a doppia risorsa e più primitive di sincronizzazione ad alta velocità senza bloccare il blocco.
Tuttavia, c'è un altro modo per parallelizzare i programmi: processori grafici (GPU), che può avere un numero maggiore di core, processori ad alte prestazioni inferiori. I core dei processori grafici sono miracolosamente adatti all'implementazione di algoritmi paralleli per l'elaborazione dei dati, e il loro gran numero paga più che la mancanza di manualità dei programmi su di essi. In questo articolo, conosciamo uno dei modi per programmare programmi su un processore grafico con una serie di estensioni di film C++ sotto il nome C++AMP.
L'estensione C++ AMP si basa sul mio C++ e quindi questo articolo illustrerà la mia applicazione C++. Tuttavia, con un vittorioso meccanismo di interazione vittorioso. NET, puoi trasformare gli algoritmi C++ AMP nei tuoi programmi .NET. Ale, parliamone ad esempio di statistiche.
Entrata in C++ AMP
In effetti, il processore grafico è un tale processore stesso, come se fosse altrimenti, ma con un set speciale di istruzioni, un gran numero di core e il suo protocollo per l'accesso alla memoria. Tra grafica moderna e processori eccezionali, ci sono grandi intuizioni e programmi їhnє rozumіnnya є zaporuchnya stavlennya che effettivamente vikoristovuyut stanchezza paralizzante processore grafico.
I moderni processori grafici potrebbero avere ancora una piccola serie di istruzioni. Il trasferimento delle attività di scambio: la disponibilità del richiamo delle funzioni, la raccolta dei tipi di dati supportati, la disponibilità delle funzioni bibliotecarie e altro. Deyakі operatsії, così come le transizioni intelligenti, può costare operazioni analoghe significativamente più costose e inferiori, come vykonuyutsya sui processori di notevoli dimensioni. È ovvio che trasferire la grande quantità di codice dal processore al processore grafico per tali menti richiederà uno sforzo significativo.
Il numero di core nel processore grafico medio è significativamente maggiore, inferiore nel processore medio. Tuttavia, le azioni dello zavdannya sembrano troppo piccole o non si lasciano suddividere in un gran numero di parti, in modo che possano trarre vantaggio dal blocco del processore grafico.
Tempistica di sincronizzazione tra i core del processore grafico, che dovrebbe essere fissata un giorno, anche poco, e più di un giorno tra i core del processore grafico, che dovrebbe essere fissata compiti diversi. Questo ambiente significa sincronizzazione del processore grafico con il processore superiore.
Ancora una volta, che tipo di attività sono adatte per l'esecuzione sul processore grafico? Tieni presente che non tutti gli algoritmi sono adatti per l'esecuzione su un processore grafico. Ad esempio, i processori grafici non consentono l'accesso ai dispositivi di input/output, quindi non sarai in grado di aumentare la produttività dei programmi, come estrarre linee RSS da Internet, per lo schermo del processore grafico. Tuttavia, è possibile trasferire molti algoritmi di calcolo al processore grafico e garantire la parallelizzazione di massa. Di seguito, indica alcuni esempi di tali algoritmi (questo elenco non è nuovo):
zbіlshennya e cambiamento nella nitidezza dell'immagine e altre trasformazioni;
Shvidke reinvenzione Fur'є;
trasposizione e moltiplicazione di matrici;
numeri di smistamento;
Inversione dell'hash "sulla fronte".
Il blog Microsoft Native Concurrency può essere utilizzato come riferimento per applicazioni avanzate, in cui è possibile trovare frammenti di codice e relative spiegazioni per vari algoritmi implementati in C++ AMP.
C++ AMP è un framework incluso nel magazzino di Visual Studio 2012, che offre ai rivenditori C++ un modo semplice per eseguire calcoli sul processore grafico e rende meno ovvio il driver DirectX 11. computer
Il framework C++ AMP ti consente di avvolgere il tuo codice acceleratori grafici, che sono conteggiati annessi. Dietro l'aiuto del driver DirectX 11, il framework C++ AMP rivela dinamicamente la velocità. Il magazzino C++ AMP include anche un emulatore software e un emulatore basato su un processore considerevole, WARP, come opzione di backup in sistemi senza processore grafico o con processore grafico, o senza driver DirectX 11, core vicorist e istruzioni SIMD.
Ed ora procediamo al completamento dell'algoritmo, che può essere parallelizzato per la visualizzazione su un processore grafico. L'implementazione seguente accetta due vettori e lo stesso valore e calcola il risultato per punto. È facile esprimere più chiaramente:
Void VectorAddExpPointwise(float* first, float* second, float* result, int length) ( for (int i = 0; i< length; ++i) { result[i] = first[i] + exp(second[i]); } }
Per espandere il parallelismo dell'algoritmo su un processore considerevole, è necessario dividere l'intervallo di iterazioni in una spolverata di sottointervalli ed eseguire un thread di viconazione per la loro pelle. Abbiamo dedicato molto tempo negli articoli precedenti proprio a questo metodo di deparallelizzazione del nostro primo calcio per lo studio dei numeri primi - abbiamo lavorato, come è possibile, creando flussi manualmente, passando i compiti al pool di flussi e utilizzando Parallel.For e PLINQ per la deparallelizzazione automatica. Indovina un po', quando abbiamo parallelizzato algoritmi simili su un processore superiore, abbiamo raddoppiato in particolare, in modo da non dividere l'attività in attività troppo piccole.
Per un processore grafico, l'orologio non è necessario. I processori grafici possono creare core impersonali, in grado di gestire i flussi ancora più rapidamente, e la variabilità del cambio di contesto è significativamente inferiore, inferiore nel caso di processori speciali. Un frammento è posizionato al di sotto, che viene mostrato per evidenziare la funzione parallelo_per_ciascuno Dal framework C++ AMP:
#includere
Ora doslіdzhuєmo skin parte del codice okremo. È altamente rispettato il fatto che la forma principale del loop della testa sia stata preservata, ma il loop, che ha vinto, è stato sostituito da un rapido clic della funzione parallel_for_each. In effetti, il principio di trasformare il ciclo in una funzione wiki o in un metodo non è nuovo per noi: abbiamo precedentemente dimostrato una tale tecnica dai metodi Parallel.For() e Parallel.ForEach() della libreria TPL.
Dali, i dati di input (parametri primo, secondo e risultato) sono racchiusi in istanze vista_array. La classe array_view viene utilizzata per il gagging dei dati, poiché viene passata al processore grafico (criptata). Questo parametro del modello determina il tipo di dati e la relativa dimensione. Sob vykonat sul processore grafico delle istruzioni, che vengono inviate ai dati, sputeremo sul grande processore, oppure è colpa della feccia di copiare i dati dal processore grafico, a quello più delle schede grafiche odierne є okremimi annessi dalla memoria. Non eliminare le istanze di array_view - fetore copia sicura dei dati per aiuto e solo se fetore è davvero necessario.
Se il processore grafico è scaduto, i dati vengono ricopiati. Creando un'istanza array_view con un argomento di tipo const, garantiamo che il primo e il secondo verranno copiati nel puzzle del processore grafico e non copiati di nuovo. Allo stesso modo, chiamando scartare_dati(), includiamo la copia del risultato dalla memoria del processore stellare alla memoria del più veloce, altrimenti i dati verranno copiati direttamente nel ritorno.
La funzione parallel_for_each accetta un oggetto extent, che assegna una forma dati e una funzione per disegnare all'elemento skin nell'oggetto extent. In questa applicazione, la funzione lambda è stata vinta e un trucco per loro è apparso nello standard ISO C ++ 2011 (C ++ 11). La parola chiave limit (amp) indica al compilatore di ignorare la possibilità di modificare il corpo di una funzione sul processore grafico e includere la maggior parte della sintassi C++, che può essere compilata nelle istruzioni del processore grafico.
parametro della funzione lambda, indice<1>L'oggetto rappresenta un singolo indice. Vin è colpevole di confermare l'estensione dell'oggetto, che è vittoriosa - yakby mi ha votato l'estensione dell'oggetto a due mondi (ad esempio, nominando la forma dei dati nell'aspetto della matrice dei due mondi), l'indice è anche colpevole di essere due mondi . Un esempio di una situazione del genere deve essere guidato un po' più in basso.
Nareshti, metodo viklik sincronizzare() Ad esempio, il metodo VectorAddExpPointwise garantisce una copia dei risultati calcolati da array_view avResult, generato dal processore grafico, nell'array dei risultati.
A tal fine, la nostra prima conoscenza con la luce del C++ AMP, e ora siamo pronti a presentare documenti, oltre a più applicazioni, che dimostrano i vantaggi dei calcoli paralleli sul processore grafico. La piegatura vettoriale non è il miglior algoritmo e non il miglior candidato per dimostrare la versatilità di un processore grafico attraverso una grande sovrapposizione di copie di dati. All'offensiva pіdrozdіlі verranno mostrati due mozziconi cіkavіshі.
Riproduzione di matrici
Il primo calcio di "riferimento", visibile al mondo, è una pluralità di matrici. Per l'implementazione, prendiamo un semplice algoritmo di moltiplicazione di matrici cubiche, e non l'algoritmo di Strassen, che può essere vicino a cubic ~O(n 2.807). Per due matrici: matrici A con dimensione m x w e matrici B con dimensione w x n, quindi il programma successivo moltiplicherà e trasformerà il risultato - matrice C con dimensione m x n:
Void MatrixMultiply(int * A, int m, int w, int * B, int n, int * C) ( for (int i = 0; i< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
Puoi implementare la deparallelizzazione in diversi modi e, se hai bisogno di deparallelizzare il codice per l'esecuzione su un processore stellare, scegliendo il modo giusto per deparallelizzare il ciclo corrente. Tuttavia, il processore grafico può gestire un gran numero di core e avendo parallelizzato solo il ciclo corrente, non possiamo creare un numero sufficiente di attività per catturare tutti i core con un robot. Pertanto, può esserci un senso di parallelismo tra due anelli esterni, lasciando vuoto l'anello interno:
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) ( array_view
Questa implementazione è ancora prossima a prevedere la successiva implementazione di matrici multiple e l'aggiunta di vettori, che sono stati introdotti di più, dietro l'indice del vigneto, che ora è bidimensionale e accessibile al ciclo interno dal ritardo dell'operatore. Quale versione è migliore dell'ultima alternativa, quale è migliore per un processore più grande? Moltiplicazione di due matrici (numeri) con una dimensione di 1024 x 1024 L'ultima versione sul processore più grande impiega una media di 7350 millisecondi, la stessa della versione per il processore grafico - tre volte più veloce - 50 millisecondi, a 147 volte più veloce!
Modellazione del movimento delle particelle
Applicare attività rozv'yazannya sul processore grafico, presentato di più, potrebbe essere un'implementazione ancora più semplice del ciclo interno. Mi sono reso conto che non sarai così. Nel caso di Native Concurrency, che è già stato più sottolineato, viene mostrato il problema della modellazione delle interazioni gravitazionali tra le particelle. La modellazione comprende un numero innumerevole di pezzi; sulla piega della pelle vengono calcolati i nuovi valori degli elementi del vettore e quindi vengono determinate le nuove coordinate. Qui, il vettore delle particelle è parallelizzato: quando finisci un gran numero di particelle (millemila e più) puoi creare un gran numero di lavori, in modo che i robot possano catturare tutti i core del processore grafico.
La base dell'algoritmo è l'implementazione del risultato dell'interazione tra due particelle, come mostrato di seguito, che può essere facilmente trasferito a un processore grafico:
// qui float4 è un vettore con più elementi, // che rappresenta le particelle che prendono parte alle operazioni. float absDist = dist.x * dist.x + dist.y * dist.y + dist.z * dist.z; float invDist = 1.0f/sqrt(absDist); = dist*PARTICLE_MASS*invDistCube; )
Esaminiamo i dati sul modello dell'inguine della pelle: un array con le coordinate e la casualità delle particelle e, di conseguenza, viene creato un nuovo array con le coordinate e la casualità delle particelle:
Particella struct (posizione float4, velocità; // implementazione del costruttore, costruttore di copia // operator = 3 limit(amp) omesso per risparmiare spazio); simulazione_step(array
A causa dell'interfaccia grafica visiva ottenuta, la simulazione potrebbe essere diversa. L'ultimo esempio fornito dal team dei rivenditori C++ AMP è disponibile nel blog Native Concurrency. Sul mio sistema, con un processore Intel Core i7 e una scheda video Geforce GT 740M, vengono acquisiti 10.000 frammenti di velocità a circa 2,5 fotogrammi al secondo (cps) con l'ultima versione, che cattura alla velocità massima del processore di 16 fotogrammi al secondo ottimizzazioni della versione, che verrà modificata sul processore grafico: il maggiore aumento della produttività.
Per prima cosa, concludiamo questa sezione, è necessario parlare di una caratteristica importante del framework C++ AMP, al fine di aumentare ulteriormente la produttività del codice che gira sul processore grafico. Supporto per processori grafici programmazione della cache di dati(spesso titoli memoria, scho rozdіlyaєє (memoria condivisa)). I significati che vengono salvati in ogni cache sono vicorati a spillo da tutti i flussi di un mosaico (tessere) vittorioso. Mosaic organizzatori di memoria, programmi basati sul framework C++ AMP possono leggere i dati dalla memoria di una mappa grafica nella memoria di un mosaico, che viene suddiviso, e poi risalire ad essi da una dozzina di flussi di viconannia senza riesaminare il memoria dati grafici kart. L'accesso alla memoria del mosaico è circa 10 volte più veloce, inferiore alla memoria della scheda grafica. In altre parole, hai dei motivi per leggere.
Per garantire che la versione mosaicata del ciclo parallelo venga passata, viene passato il metodo parallel_for_each tiled_extent dominio, che divide l'estensione di un oggetto ricco in tessere ricche del mosaico e il parametro lambda tiled_index, che imposta l'identificatore globale e locale per il flusso al centro del mosaico. Ad esempio, una matrice 16x16 può essere suddivisa in riquadri 2x2 (come mostrato nella miniatura qui sotto) e quindi passata alla funzione parallel_for_each:
Estensione<2>matrice(16,16); tiled_extent<2,2>tiledMatrix = matrice.tile<2,2>(); parallel_for_each (tiledMatrix, [=](tiled_index<2,2>idx) restringe (amp) ( // ...));

La pelle di diversi flussi di vikonannya, che giacciono su uno stesso mosaico, può dati completamente vittoriosi, che vengono salvati in macchie.
Quando si eseguono operazioni con le matrici, nel core del processore grafico, sostituire l'indice di indice standard<2>, come se le azioni fossero più grandi, puoi battere idx.global. L'uso corretto della memoria del mosaico locale e degli indici locali può garantire un aumento significativo della produttività. Per esprimere la memoria della tessera, podіluvanu vykonannya scorre in una tessera, lo zminnі locale può essere espresso con lo specificatore tile_static.
In pratica, è spesso vittorioso per la ricezione della memoria senza voce che viene divisa e l'inizializzazione di quattro blocchi in flussi diversi:
Parallel_for_each(tiledMatrix, [=](tiled_index<2,2>idx)strict(amp) ( // 32 byte sono condivisi da tutti i thread nel blocco tile_static int local; // assegna un valore all'elemento per questo thread local = 42; ));
È ovvio che se sei in grado di ordinare la memoria che viene divisa, puoi solo prendere in sincronizzazione diversi accessi alla memoria; quindi i flussi non sono colpevoli di rivolgersi alla memoria, finché non è iniziata da uno di essi. La sincronizzazione dei flussi nel mosaico è concatenata per oggetti aggiuntivi tile_barrier(che indovina la classe Barrier dalla libreria TPL) - possono continuare a chiamare il metodo tile_barrier.Wait(), che trasforma maggiormente la chiamata se tutti i thread chiamano tile_barrier.Wait. Per esempio:
Parallel_for_each (tiledMatrix, (tiled_index<2,2>idx) limit(amp) ( // 32 byte sono condivisi da tutti i thread nel blocco tile_static int local; // assegna un valore all'elemento per questo thread per wick local = 42; // idx.barrier - un'istanza di tile_barrier idx.barrier.wait(); // Ora questo flusso può essere convertito nell'array "locale", // indici vicorist di altri flussi!);
Ora è l'ora di portare via la conoscenza da un mozzicone specifico. Passiamo all'implementazione della moltiplicazione delle matrici, vikonana senza bloccare l'organizzazione a mosaico della memoria e aggiungiamo alla nuova ottimizzazione, che viene descritta. È consentito, il numero a matrice rosemica 256 - per permetterci di darci pratsyuvati con blocchi di 16 x 16. La natura della matrice è autorizzata a essere vittoriosa e molte persone, posso essere fieramente concentrato sulla navigazione di la matrice con un tipico algoritmo wholesale, e la moltiplicazione del multiplo del multiplo della moltiplicazione della moltiplicazione di molti processori cache recovery).
L'essenza del quale approccio deve essere offensivo. Per conoscere C i,j (elemento nella riga i e nella colonna j nel risultato della matrice), è necessario calcolare il twir scalare mіzh A i,* (i-esima riga della prima matrice) e B *, j (j-esima riga in un'altra matrice). Tuttavia, equivale al calcolo delle creazioni scalari private di una riga e al calcolo dell'ulteriore sussunzione dei risultati. Possiamo modificare l'ambiente per convertire l'algoritmo di moltiplicazione di matrici in una versione a mosaico:
Void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) ( array_view L'essenza dell'ottimizzazione, che è descritta nel fatto che lo skin flow nel mosaico (vengono creati 256 flussi per un blocco di 16 x 16) inizializza il suo elemento in 16 x 16 copie locali dei frammenti nelle matrici di output A e B .z tsikh blocca e tutti i flussi contemporaneamente verranno invertiti sulla riga della pelle e sulla pelle stovptsa 16 volte. Un tale suttєvo riduce il numero di animali alla memoria principale. Per calcolare l'elemento (i,j) del risultato della matrice, l'algoritmo necessita della i-esima riga della prima matrice e della j-esima riga dell'altra matrice. Se i flussi del mosaico sono 16x16, presentati sui diagrammi e k=0, le aree ombreggiate della prima e delle altre matrici verranno lette nella memoria che viene suddivisa. Il passaggio successivo consiste nel calcolare l'elemento (i,j) del risultato della matrice, calcolare l'addizione scalare parziale dei primi k elementi dalla riga i-esima e la colonna j-esima delle matrici esterne. Per chi, la stasi dell'organizzazione musiva assicura un grande incremento della produttività. La versione a mosaico di più matrici è più veloce della versione semplice e impiega circa 17 millisecondi (per le stesse singole matrici con una dimensione di 1024 x 1024), ovvero 430 shvid in più per versione, il che è più veloce su un processore considerevole! Per prima cosa, finisci di parlare del framework C++ AMP, vorrei indovinare gli strumenti (in Visual Studio), scoprire i rivenditori. Visual Studio 2012 пропонує налагоджувач для графічного процесора (GPU), що дозволяє встановлювати контрольні точки, досліджувати стек викликів, читати та змінювати значення локальних змінних (деякі прискорювачі підтримують налагодження для GPU безпосередньо; для інших Visual Studio використовує програмний симулятор), та профільник, що ti dà la possibilità di valutare il comportamento del componente aggiuntivo per parallelizzare le operazioni dal blocco del processore grafico. Per ulteriori informazioni su come migliorare in Visual Studio, vedere l'articolo "Protection helper. Personalizzazione del programma C++ AMP sul sito Web MSDN. Prima di questo articolo, sono stati dimostrati solo esempi del mio C ++, nonché modi proteo per superare la pressione del processore grafico nei componenti aggiuntivi in ceramica. Uno dei modi è utilizzare strumenti di interoperabilità che consentono di spostare il lavoro con i core del processore grafico ai componenti C++ di basso livello. Questa soluzione è consigliata a coloro che desiderano hackerare il framework AMP C++ oppure è possibile hackerare i componenti AMP C++ già pronti in componenti aggiuntivi di hacking. Il secondo modo è hackerare la libreria, che funziona direttamente con il processore grafico dal codice kern. Ninі іsnuє kіlka librіbrіkov. Ad esempio, GPU.NET e CUDAfy.NET (offeso da proposte commerciali). Passa il mouse sotto il repository GitHub di GPU.NET, che mostra l'implementazione della creazione scalare di due vettori: statico pubblico void MultiplyAddGpu(double a, double b, double c) (int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X; int TotalThreads = BlockDimension.X * GridDimension.X; for (int ElementIdx = ThreadId; Mi chiedo se sia più semplice ed efficiente padroneggiare le estensioni dei film (basate su C++ AMP), quindi è più facile organizzare le interazioni su librerie uguali o apportare modifiche al film IL. Da allora, da quando abbiamo visto la possibilità di programmazione parallela in .NET e GPU, singolarmente, nessuno ha perso il dubbio che l'organizzazione di calcoli paralleli sia un modo importante per aumentare la produttività. I ricchi server e workstation in tutto il mondo sono pieni di innumerevoli ceppi di grandi processori grafici, quindi le aggiunte semplicemente non li ottengono. La Task Parallel Library ci dà la possibilità unica di includere nel robot tutti i core reali del processore centrale, se vogliamo risolvere alcuni problemi di sincronizzazione, frammentazione trascendentale del compito e esaurimento nervoso del robot tra i fili di viconazione . Il framework C++ AMP e altre ricche librerie di organizzazione del calcolo parallelo su un processore grafico possono superare con successo il calcolo parallelo tra centinaia di core di un processore grafico. Nareshti, non è possibile aumentare i guadagni di produttività a causa del ristagno delle tecnologie oscure delle divisioni, che nell'ultima ora si sono trasformate in una delle principali direttrici per lo sviluppo delle tecnologie informatiche. Come se avessi la possibilità di parlare di mercato dei computer con il direttore tecnico di una delle più grandi aziende che vendono laptop. Tsey "fahіvets" namagavsya con l'aiuto dell'azienda per spiegare, poiché la configurazione del laptop stesso è meno necessaria. È stato molto divertente per un monologo che l'ora dei processori centrali (CPU) era finita e allo stesso tempo tutti i programmi si stavano caricando attivamente sul processore grafico (GPU) e che la produttività del laptop sarebbe dovuto al processore grafico e sulla CPU non si potrebbe eseguire alcun rispetto. Comprendendo che dovevo parlare e cercare di ricordare in modo assolutamente stupido il direttore tecnico, non mi sono fermato all'ora e ho comprato il portatile che mi serviva nell'altro padiglione. Prote, il fatto stesso di una tale incompetenza urlante del venditore mi colpisce. Bulo b zrozumіlo, yakbi vin ha cercato di ingannarmi come un acquisto. Non. Vіn schiro vіriv a coloro che hanno parlato. Quindi, forse, i marketer di NVIDIA e AMD non sono liberi di dare il loro pane e sono lontani da riconsiderare una sorta di idea coristuvachiv sul ruolo dominante del processore grafico nei computer moderni. Il fatto che gli attuali costi del processore grafico (GPU) stiano diventando sempre più popolari non significa alcun dubbio. Tuttavia, non sminuire il ruolo del processore centrale. Inoltre, se parli dell'importanza di più componenti aggiuntivi principali, in questo giorno la produttività è piena e diminuirà maggiormente a causa della produttività della CPU. Tobto è più importante del numero di programmi per il calcolo del numero di programmi sulla GPU. Inoltre, il calcolo sulla GPU è più importante che sui sistemi HPC specializzati per gli sviluppi scientifici. E l'asse dell'addenda coristuvatsky, in cui zastosovuyutsya sulla GPU, può essere rifinito sulle dita. Con questo in mente, va notato che il termine "calcolato sulla GPU" in questo caso non è del tutto corretto e può essere introdotto in Oman. A destra, solo perché il programma è in esecuzione sulla GPU, non significa che la CPU non sia in esecuzione. Il calcolo sulla GPU trasferisce il trasferimento della carica dal processore centrale a quello grafico. Suono, il processore centrale si sta dando da fare e il processore grafico, istruendo il processore centrale, consente di aumentare la produttività, di velocizzare l'ora della giornata di lavoro. Inoltre, la GPU stessa qui svolge il ruolo del proprio processore per la CPU, ma allo stesso tempo non la sostituisce di nuovo. Per capire perché il calcolo sulla GPU non è una tale panacea e perché non è corretto stverzhuvat, qual è il calcolo della capacità di superare la CPU, è necessario capire la differenza tra il processore centrale e grafico. I core della CPU sono progettati per seguire un singolo thread di istruzioni successive con la massima produttività e le GPU sono progettate per eseguire un gran numero di thread paralleli di istruzioni. A chi i principi di poligaє tra i più grafichi protsesorі vіd centralnyh. La CPU è un processore universale, o un processore di riconoscimento generale, ottimizzazioni per ottenere un'elevata produttività di un singolo flusso di istruzioni, che elabora numeri interi e numeri a virgola mobile. In caso di accesso alla memoria con dati e istruzioni, è ancora più importante il rango vipadkovym. Per migliorare le prestazioni della CPU, le puzzolenti sono progettate in modo tale da poter scrivere più istruzioni in parallelo. Ad esempio, nei core del processore è presente un blocco di digitazione post-ordine dei comandi, che consente di riordinare le istruzioni fuori ordine, il che consente di aumentare il parallelismo dell'implementazione delle istruzioni sullo stesso thread. Prote ce lo stesso non consente la creazione di un gran numero di istruzioni in parallelo e quella sovrapposizione sulla parallelizzazione delle istruzioni al centro del core del processore sembra essere ancora più significativa. Proprio per questo fatto, i processori della confessione criptica possono avere un piccolo numero di blocchi vittoriosi. Il processore grafico del governo è fondamentalmente diverso. Sinceramente proiettato fino alla fine del numero maestoso di flussi paralleli di comandi. Inoltre, i flussi di comandi sono parallelizzati e semplicemente non ci sono costi generali giornalieri per la parallelizzazione delle istruzioni per il processore grafico. Processore grafico di assegnazioni di visualizzazione delle immagini. Per dirla semplicemente, accettiamo un gruppo di poligoni in ingresso, eseguiamo le operazioni necessarie e vediamo i pixel in uscita. L'elaborazione di poligoni e pixel è indipendente, possono essere elaborati in parallelo, ad eccezione di un tipo di uno. Pertanto, attraverso l'organizzazione parallela del lavoro in GPU, si ha un gran numero di blocchi differenti, di cui è facile sfruttare, vista il flusso sequenziale di istruzioni per la CPU. La grafica e i processori centrali differiscono per i principi di accesso alla memoria. L'accesso della GPU alla memoria è facile da trasferire: non appena una texture texture viene letta dalla memoria, tra una certa ora arriverà un termine per i land texel. Durante la registrazione, lo stesso verrà registrato: se un pixel viene registrato al framebuffer, dopo alcuni tatti, il pixel verrà registrato, indicando di essere riordinato. Quella GPU, sulla parte frontale della CPU, semplicemente non ha bisogno di una cache della grande espansione, e per le texture bastano pochi kilobyte. Differenziale e principio di lavoro con memoria per GPU e CPU. Quindi, tutte le moderne GPU possono avere un po' più di controller di memoria, la stessa memoria grafica è veloce, quindi i processori grafici possono essere più ricchi di maggiore capacità di costruzione della memoria, uguale ai processori universali, importante anche per i rozrakhunkiv paralleli, che operano con flussi di dati maestosi. Nei processori universali b di La maggior parte dell'area del cristallo è occupata da diversi buffer di comandi e dati, blocchi di decodifica, blocchi di riordino hardware, blocchi di riordino dei comandi e cache del primo, secondo e terzo uguali. Tutti questi blocchi hardware sono necessari per velocizzare l'esecuzione di flussi di istruzioni non numerosi per la distribuzione dei paralleli sui core del processore uguali. I blocchi vykonavchi stessi occupano poco spazio nel processore universale. Al processore grafico, invece, l'area principale è occupata dai blocchi numerici stessi, che consentono di elaborare migliaia di flussi di comandi contemporaneamente. Si può dire che sulla base delle attuali CPU, i processori grafici sono riconosciuti per il calcolo parallelo di un gran numero di operazioni aritmetiche. È possibile calcolare la complessità dei processori grafici per attività non grafiche, ma solo in quel caso, poiché l'attività sviluppata, consente la possibilità di parallelizzazione di algoritmi su centinaia di blocchi grafici, che si trova nella GPU. Zokrema, vykonannya rozrahunkiv sulla GPU ti mostrerà i risultati della fluttuazione, se quella stessa sequenza di operazioni matematiche zastosovuetsya fino al grande obbligo. Nel minor tempo si raggiungono i risultati, anche se il numero di istruzioni aritmetiche viene portato in memoria, è ottimo. Questa operazione presenta meno aiuto alla gestione di vikonannyam, non richiederà più di qualche keshpam'yati. È possibile introdurre applicazioni impersonali di ricerche scientifiche, de la superiorità della GPU sulla CPU in termini di efficienza non è calcolabile. Pertanto, una serie di aggiunte scientifiche dalla modellazione molecolare, dalla dinamica dei gas, dalla dinamica del rіdin e da altre cose collegate a razrahunkіv sulla GPU. Inoltre, poiché l'algoritmo per il disaccoppiamento di un'attività può essere parallelizzato su migliaia di thread, l'efficienza del disaccoppiamento di tale attività dagli inceppamenti della GPU può essere maggiore, inferiore è possibile disaccoppiare solo il processore di un singolo riconoscimento. Tuttavia, non è così facile prendere e trasferire la decisione di qualsiasi attività dalla CPU alla GPU, se solo la CPU e la GPU cambiassero comandi diversi. Cioè, se il programma è scritto sulla CPU, il set di comandi x86 si fermerà (altrimenti il set di comandi, riassumendo con l'architettura specifica del processore) e l'asse per il processore grafico verrà già scritto con gli stessi altri set di comandi, quindi puoi ancora proteggere quell'architettura. Durante lo sviluppo di moderne montagne 3D, verranno installate le API DirectX e OrenGL, che consentono ai programmatori di lavorare con shader e trame. Tuttavia, l'utilizzo delle API DirectX e OrenGL per calcoli non grafici sul processore grafico non è l'opzione migliore. Per la prima volta, se inizi a lavorare per primo, prova a implementare calcoli non grafici sulla GPU (General Purpose GPU, GPGPU), il compilatore di vino BrookGPU. Fino ad allora, i rivenditori dovevano accedere alle risorse della scheda video tramite le API grafiche OpenGL e Direct3D, che semplificavano notevolmente il processo di programmazione, ma erano necessarie alcune conoscenze specifiche: dovevano lavorare sui principi di lavorare con oggetti 3D (shader, texture, ecc.). Tse è diventato il motivo del blocco della GPGPU nei prodotti software. BrookGPU è diventato un traduttore a sé stante. I flussi Qi espansi al film Ci sono stati adottati dai programmatori di API trivimer e per qualche ragione la necessità di conoscere la programmazione 3D potrebbe essere andata persa. Il calcolo della pressione delle schede video è diventato disponibile per i programmatori come processore aggiuntivo per espansioni parallele. Il compilatore BrookGPU, dopo aver elaborato il file con codice C ed estensioni, codice vedova, collegandosi alla libreria con supporto per DirectX o OpenGL. Perché le aziende BrookGPU, NVIDIA e ATI (non AMD) sono passate in secondo piano rispetto alla tecnologia emergente del calcolo del riconoscimento critico sui processori grafici e hanno iniziato lo sviluppo delle proprie implementazioni, che forniranno un accesso diretto e più aperto alla grafica 3D blocchi di elaborazione. Di conseguenza, NVIDIA ha sviluppato l'architettura hardware e software CUDA (Compute Unified Device Architecture) per il calcolo parallelo. L'architettura CUDA consente di implementare calcoli non grafici sui processori grafici NVIDIA. Il rilascio della versione beta pubblica di CUDA SDK è stato rilasciato nel febbraio 2007. L'API CUDA si basa sulle semplificazioni del dialetto linguistico Cі. L'architettura CUDA SDK garantisce che i programmatori implementino algoritmi implementati sui processori grafici NVIDIA, incluse funzioni speciali prima del testo del programma C. Per tradurre correttamente il mio codice nel magazzino CUDA SDK, è necessario includere il compilatore della riga di comando NVIDIA nvcc. CUDA è un software multipiattaforma per sistemi operativi come Linux, Mac OS X e Windows. AMD (ATI) ha anche rilasciato la propria versione della tecnologia GPGPU, precedentemente chiamata ATI Stream e ora AMD Accelerated Parallel Processing (APP). L'APP AMD si basa sullo standard del settore OpenCL (Open Computing Language). Lo standard OpenCL garantisce il parallelismo a livello di istruzioni e a livello di dati e l'implementazione della tecnica GPGPU. Cambierò lo standard, questo standard non è soggetto ad approvazioni di licenza. È significativo che AMD APP e NVIDIA CUDA siano indiscutibili una per una, la versione rimanente di NVIDIA CUDA supporta OpenCL. Testare GPGPU su convertitori video Inoltre, abbiamo spiegato che per l'implementazione della GPGPU sui processori grafici NVIDIA, la tecnologia CUDA è riconosciuta e sui processori grafici AMD - APP API. Come dovrebbe essere, il numero di numeri non grafici sulla GPU è inferiore a quello, poiché è possibile parallelizzare il numero di flussi. Tuttavia, la maggior parte degli integratori del koristuvach non soddisfa questo criterio. Vtim, є deakі vinyatki. Ad esempio, la maggior parte dei convertitori video odierni migliora la capacità di calcolo su processori grafici NVIDIA e AMD. Per capire l'efficacia con cui vengono utilizzate le tariffe GPU nei convertitori video, abbiamo scelto tre soluzioni popolari: Xilisoft Video Converter Ultimate 7.7.2, Wondershare Video Converter Ultimate 6.0.3.2 e Movavi Video Converter 10.2.1. I convertitori digitali migliorano la capacità di diversi processori grafici di NVIDIA e AMD e nei convertitori video personalizzati è possibile disabilitare la capacità, che consente di valutare l'efficienza del caricamento della GPU. Per la videoconversione, abbiamo zastosovuvali tre diversi video. Primo videoclip 3 min 35 min 1,05 GB. Tra i record buv nel formato di archiviazione dati (contenitore) mkv e maw tali caratteristiche: Un altro videoclip 4 min 25 min 1,98 GB. Tra i record buv nel formato di archiviazione dati (contenitore) MPG e maw tali caratteristiche: Il terzo video clip Mav trivalità 3 xv 47 con 197 MB. Vinci record per il formato di archiviazione dati (contenitore) MOV e maw tali caratteristiche: Tutti e tre i video di prova sono stati convertiti da diversi convertitori video in formato di archiviazione dati MP4 (codec H.264) per la revisione su tablet iPad 2. Significativamente, non siamo diventati assolutamente identici e abbiamo migliorato la conversione di tutti e tre i convertitori. La stessa ora di conversione non è corretta per migliorare l'efficienza dei convertitori video. Ad esempio, il convertitore video Xilisoft Video Converter Ultimate 7.7.2 aveva un iPad 2 predefinito per la conversione: video H.264 HD. Quale preset ha la seguente codifica ottimizzata: Il convertitore video Wondershare Video Converter Ultimate 6.0.3.2 ha l'intero iPad 2 preimpostato con le seguenti regolazioni aggiuntive: Movavi Video Converter 10.2.1 ha un preset iPad bloccato (1280*um*720, H.264) (*.mp4) con le seguenti modifiche: La conversione dello skin video clip è stata effettuata cinque volte sullo skin video converter, inoltre sia per il processore grafico che per la CPU. Dopo la conversione della skin, il computer viene ripristinato. Bene, il video skin è stato convertito dieci volte con il convertitore video skin. Per automatizzare il lavoro di routine è stata scritta un'utilità speciale con un'interfaccia grafica, che consente di automatizzare nuovamente il processo di test. Stand per il test maw la seguente configurazione: Sul supporto è stato installato il sistema operativo Windows 7 Ultimate (64-bit). Di recente abbiamo effettuato dei test nella modalità normale del processore robotico e risolto tutti i componenti del sistema. Con questo, il processore Intel Core i7-3770K funziona a una frequenza nominale di 3,5 GHz con la modalità Turbo Boost attivata (la frequenza massima del processore in modalità Turbo Boost diventa 3,9 GHz). Quindi abbiamo ripetuto il test, ma durante l'overclocking del processore a una frequenza fissa di 4,5 GHz (senza utilizzare la modalità Turbo Boost). Tse ha permesso di rivelare la validità della velocità di conversione della frequenza del processore (CPU). Nella fase successiva del test, siamo passati agli aggiornamenti del processore standard e abbiamo ripetuto il test con altre schede video: In questo modo è stata effettuata la conversione video su più schede video di diversa architettura. La vecchia scheda video NVIDIA GeForce 660Ti si basa su un processore grafico a bit singolo con codice GK104 (architettura Kepler), che gira su una tecnologia di processo a 28 nm. L'intero processore grafico dovrebbe avere 3,54 miliardi di transistor e l'area del cristallo dovrebbe essere 294 mm2. Indovinando, il processore grafico GK104 include diversi cluster ed elaborazione grafica (Graphics Processing Clusters, GPC). Cluster GPC є annessi indipendenti nel magazzino del processore e costruzione di pratsyuvati come okremі pristroї, oskolki potrebbe avere le risorse necessarie: rosette, motori geometrici e moduli di trama. Se un tale cluster può avere due multiprocessori di streaming SMX (Streaming Multiprocessor) e nel processore GK104 in un cluster, un multiprocessore di blocco, ovvero un multiprocessore SMX. Mentre il multiprocessore di streaming SMX ha 192 core di conteggio dello streaming (core CUDA), il processore GK104 ha 1344 core CUDA di conteggio. Inoltre, la skin multiprocessore SMX contiene 16 unità texture (TMU), 32 unità funzione speciali (SFU), 32 unità Load-Store (LSU), motore PolyMorph e molto altro. La scheda video GeForce GTX 460 si basa su un processore grafico con designazione in codice GF104 basato sull'architettura Fermi. Questo processore funziona con una tecnologia di processo a 40 nm ed è vicino a 1,95 miliardi di transistor. Il processore grafico GF104 include due grafici cluster GPC. Ci sono diversi thread di multiprocessori SM in essi, e nel processore GF104 in uno dei cluster c'è un multiprocessore bloccante, che è la ragione di tutti i multiprocessori SM. Il multiprocessore di streaming SM ha 48 core di elaborazione in streaming (core CUDA), mentre il processore GK104 ha 336 core di elaborazione CUDA. Inoltre, la skin del multiprocessore SM può ospitare un totale di moduli texture (TMU), un totale di Special Function Unit (SFU), 16 Load-Store Unit (LSU), un motore PolyMorph e molto altro. Il processore grafico GeForce GTX 280 appartiene a un'altra generazione dell'architettura unificata dei processori grafici NVIDIA e, per la sua architettura, è fortemente influenzato dalle architetture Fermi e Kepler. Il processore grafico GeForce GTX 280 è costituito da cluster di elaborazione delle texture (Texture Processing Clusters, TPC), che sono simili, a volte simili e talvolta sono anche combinati con cluster di elaborazione grafica GPC nelle architetture Fermi e Kepler. Ci sono dieci di questi cluster nel processore GeForce GTX 280. Il cluster Skin TPC include tre flussi, multiprocessori SM e un blocco totale di vibrazione e filtraggio delle texture (TMU). Il multiprocessore skin è costituito da otto stream processor (SP). I multiprocessori possono anche sostituire i blocchi di selezione e filtraggio dei dati delle texture, come quelli grafici e alcune attività rozrachunk. Pertanto, in un cluster TPC ci sono 24 stream processor e nel processore grafico GeForce GTX 280 ce ne sono già 240. Nella tabella sono presentate le caratteristiche delle schede video testate sui processori grafici NVIDIA. In bilico sul tavolo non ci sono schede video AMD Radeon HD6850, il che è abbastanza naturale, è importante confrontarle con schede video NVIDIA per caratteristiche tecniche. E a questo guarderemo її okremo. Il processore grafico AMD Radeon HD6850, che potrebbe essere chiamato in codice Barts, viene prodotto utilizzando una tecnologia di processo a 40 nm e può ospitare 1,7 miliardi di transistor. L'architettura del processore AMD Radeon HD6850 è un'architettura unificata con una serie di processori di alto livello per l'elaborazione in streaming di visualizzazioni di dati numerici. Il processore AMD Radeon HD6850 è composto da 12 core SIMD, ciascuno contenente 16 blocchi di processori stream superscalari e alcuni blocchi di texture. Processore di flusso superscalare skin per sostituire cinque processori di flusso universali. Pertanto, ci sono 12*um*16*um*5=960 processori stream universali nel processore grafico AMD Radeon HD6850. La frequenza del processore grafico della scheda video AMD Radeon HD6850 è impostata su 775 MHz e la frequenza effettiva della memoria GDDR5 è 4000 MHz. A chi la memoria obsyag diventa 1024 MB. Otzhe, attendiamo con ansia i risultati del test. Iniziamo con il primo test, se la scheda video NVIDIA GeForce GTX 660Ti e la modalità normale del processore Intel Core i7-3770K funzionano. Sulla fig. Le figure 1-3 mostrano i risultati della conversione di tre video di prova con tre convertitori in modalità con e senza inceppamenti del processore grafico. Come si può vedere dai risultati del test, l'effetto della scelta del processore grafico è є. Per il convertitore video Xilisoft Video Converter Ultimate 7.7.2, quando il processore grafico viene rallentato, l'ora di conversione si riduce del 14,9 e del 19% per il primo, l'altro e il terzo video clip, ovviamente. Per il convertitore video Wondershare Video Converter Ultimate 6.0.32, il processore grafico ti consente di velocizzare un'ora di conversione del 10, 13 e 23% per il primo, secondo e terzo videoclip. Inoltre, la cosa più importante in caso di disturbo del processore grafico è Movavi Video Converter 10.2.1. Per il primo, l'altro e il terzo video clip, il tempo di conversione è 64, 81 e 41% è corretto. Era chiaro che abbiamo riprodotto il video utilizzando il processore grafico, per impostarlo come clip video e per correggere la conversione video, quindi, bene, e dimostrare i risultati ottenuti da noi. Ora chiediamoci come vinceremo la conversione di un'ora overcloccando il processore Intel Core i7-3770K a 4,5 GHz. Va notato che in modalità normale, tutti i core del processore, quando l'unità viene convertita e in modalità Turbo Boost, funzionano a una frequenza di 3,7 GHz, aumentando la frequenza a 4,5 GHz si ottiene un overclock del 22%. Sulla fig. Le figure 4-6 mostrano i risultati della conversione di tre video di prova durante l'overclocking del processore in modalità con e senza un processore grafico diverso. Al momento del blocco del processore grafico, ti consente di detrarre le vincite entro l'ora di conversione. Per il convertitore video Xilisoft Video Converter Ultimate 7.7.2, quando il processore grafico viene rallentato, l'ora di conversione si riduce del 15,9 e del 20% per il primo, l'altro e il terzo video clip, ovviamente. Per il convertitore video Wondershare Video Converter Ultimate 6.0.32, il processore grafico ti consente di velocizzare un'ora di conversione del 10, 10 e 20% per il primo, secondo e terzo video clip. Per Movavi Video Converter 10.2.1, il rallentamento del processore grafico consente di accelerare il tempo di conversione del 59, 81 e 40% ok. Ovviamente, non puoi fare a meno di chiederti, come una divisione del processore ti permette di cambiare l'ora di conversione con un processore grafico diverso e senza uno nuovo. Sulla fig. Le Figure 7-9 mostrano i risultati della conversione del video senza utilizzare il processore grafico in modalità normale e in modalità overclocking. Le conversioni in questo modo vengono effettuate solo dalla CPU senza essere caricate sulla GPU, è ovvio che l'aumento della frequenza di clock del processore robotico comporterà un breve tempo di conversione (aumento della velocità della conversione). Quindi è evidente che la velocità di conversione può essere approssimativamente la stessa per tutti i video di prova. Quindi, per il convertitore video Xilisoft Video Converter Ultimate 7.7.2, quando il processore viene overcloccato, l'ora di conversione si accorcia del 9, 11 e 9% per il primo, l'altro e il terzo video clip, ovviamente. Per il convertitore video Wondershare Video Converter Ultimate 6.0.32, l'ora di conversione è ridotta del 9,9% e del 10% per il primo, secondo e terzo videoclip. Bene, per il convertitore video Movavi Video Converter 10.2.1, l'ora di conversione è ridotta del 13, 12 e 12% è corretta. In questo modo, quando si overclocca il processore con una frequenza del 20%, l'ora di conversione si riduce di circa il 10%. L'ora di conversione dei videoclip nelle alternative del processore grafico nella modalità normale del processore robot e nella modalità di overclocking viene equalizzata (Fig. 10-12). Per il convertitore video Xilisoft Video Converter Ultimate 7.7.2, quando il processore è overcloccato, l'ora di conversione si riduce del 10, 10 e 9% per il primo, l'altro e il terzo video clip. Per il convertitore video Wondershare Video Converter Ultimate 6.0.32, l'ora di conversione è ridotta del 9,6 e del 5% per il primo, il secondo e il terzo video clip. Bene, per il convertitore video Movavi Video Converter 10.2.1, il tempo di conversione è breve di 0,2, 10 e 10% è corretto. Come Bachimo, per i convertitori Xilisoft Video Converter Ultimate 7.7.2 e Wondershare Video Converter Ultimate 6.0.32, il tempo di conversione più breve durante l'overclocking del processore è approssimativamente lo stesso di un processore grafico diverso, quindi senza alcuna balbuzie, che è logica, oscillante i convertitori non sono molto efficienti nel convertire i calcoli sulla GPU. E l'asse per il convertitore Movavi Video Converter 10.2.1, che è una varianza effettiva sulla GPU, cambiare il processore nella modalità varianza sulla GPU non aggiunge molto al tempo di conversione, il che è anche comprensibile, i chip in questo modo sono principalmente influenzati dal processore grafico. Ora diamo un'occhiata ai risultati dei test con diverse schede video. Sarebbe meglio se la scheda video fosse più sottile e ci fossero più core CUDA nel processore grafico (o processori stream universali per le schede video AMD), può essere più efficiente convertire video nei momenti in cui il processore grafico è occupato. Ale, in pratica, non voglio uscire così. Per quanto riguarda le schede video basate su processori grafici NVIDIA, la situazione sta arrivando. Con i convertitori alternativi Xilisoft Video Converter Ultimate 7.7.2 e Wondershare Video Converter Ultimate 6.0.32, è praticamente impossibile convertire l'ora di conversione a seconda del tipo di scheda video. Quindi per le schede video NVIDIA GeForce GTX 660Ti, NVIDIA GeForce GTX 460 e NVIDIA GeForce GTX 280 nella modalità di calcolo variabile sulla GPU, l'ora di conversione apparirà la stessa (Fig. 13-15). Riso. 1. Risultati della prima conversione Riso. 14. Risultati del tempo di conversione di un altro video clip Riso. 15. Risultati della conversione del terzo video clip in base all'ora Mi spiego solo che l'algoritmo di calcolo sul processore grafico, implementato nei convertitori Xilisoft Video Converter Ultimate 7.7.2 e Wondershare Video Converter Ultimate 6.0.32, è semplicemente inefficiente e non consente di convertire attivamente tutti i core grafici. Prima di parlare, viene spiegato il cim stesso e il fatto che per questi convertitori la differenza per ora di conversione in modalità alternative GPU è piccola. Movavi Video Converter 10.2.1 ha una situazione diversa. Per quanto mi ricordo, questo convertitore integrato è già efficiente per convertire le schede grafiche in GPU, quindi nella modalità convertitore GPU, l'ora di conversione dovrebbe essere simile al tipo di scheda video. E l'asse con la scheda video AMD Radeon HD 6850 va bene. O il driver della scheda video è "curvy", oppure gli algoritmi implementati nei convertitori richiederanno una seria elaborazione aggiuntiva, ma se devi calcolare i risultati sulla GPU, i risultati potrebbero non essere migliorati, ma verranno aggiornati. Per essere più precisi, la situazione è così. Per il convertitore Xilisoft Video Converter Ultimate 7.7.2, l'ora di conversione per la conversione del primo video di prova aumenterà del 43%, mentre la conversione di un altro video - del 66%. Inoltre, Xilisoft Video Converter Ultimate 7.7.2 è caratterizzato da risultati più instabili. La conversione dell'ora di Rozkid può raggiungere il 40%! A tal fine, abbiamo ripetuto tutti i test dieci volte e ottenuto il risultato medio. E l'asse per i convertitori Wondershare Video Converter Ultimate 6.0.32 e Movavi Video Converter 10.2.1 con un processore grafico diverso per convertire tutti e tre i video clip non cambia durante la conversione! I convertitori Wondershare Video Converter Ultimate 6.0.32 e Movavi Video Converter 10.2.1 non sfarfallano la tecnologia AMD APP durante la conversione, oppure il driver video AMD è semplicemente "storto", a causa della quale la tecnologia AMD APP non lo fa lavoro. Dalla prova condotta è possibile coltivare visnovki così importante. I moderni convertitori video possono disporre di una tecnologia basata su GPU che consente di aumentare la velocità di conversione. Tuttavia, ciò non significa che tutti i calcoli verranno trasferiti alla GPU e la CPU verrà lasciata incompiuta. Come mostra il test, con la tecnologia GPGPU il processore centrale non è più occupato e, pertanto, i processori centrali rich-core stretti nei sistemi utilizzati per la conversione video non sono più rilevanti. Il colpevole di questa regola è la tecnologia AMD APP sui processori grafici AMD. Ad esempio, quando si utilizza il convertitore Xilisoft Video Converter Ultimate 7.7.2 con la tecnologia AMD APP abilitata, il carico sulla CPU viene effettivamente ridotto, ma al punto che il tempo di conversione non si riduce, ma anzi aumenta. Prima di tutto, se stai parlando di convertire video con processori grafici aggiuntivi, quindi allo scopo di convertire schede video con processori grafici NVIDIA. Come dimostra la pratica, solo in questo modo è possibile ottenere una maggiore velocità di conversione. Inoltre, va ricordato che il vero aumento del tasso di conversione è da depositarsi in presenza di più fattori ricchi. Questo è il formato di input e output del video e, ovviamente, il convertitore video stesso. I convertitori Xilisoft Video Converter Ultimate 7.7.2 e Wondershare Video Converter Ultimate 6.0.32 non sono adatti a questo compito e il convertitore di assi Movavi Video Converter 10.2.1 è già efficace nello sfruttare le capacità delle GPU NVIDIA. Per quanto riguarda le schede video basate su processori grafici AMD, quindi per il compito di videoconvertirle, non è necessario fermarle. Nel più breve tempo non ci sarà conversione del tasso di turnover, ma in quello più grande si può prendere una diminuzione. Quale programma è necessario per il mining di criptovalute? Cosa proteggere quando si sceglie una proprietà per l'estrazione mineraria? Come estrarre bitcoin ed ethereum per una scheda video aggiuntiva su un computer? Si scopre che sono necessarie più schede video come fan dei giochi per computer. Migliaia di koristuvachiv in tutto il mondo adattatori grafici vikoristovuyu per guadagnare criptovaluta! 3 numero di carte con processori rigidi miniera creare fermi- Calcolo del centro, yakі vydobuvayut tsifrovі groshі praticamente z poіtrya! Questo è Denis Kuderin, esperto della rivista HeatherBober, sulle finanze di quella moltiplicazione letterata. Ti dirò cosa sei mining su scheda video a 17-18 anni, come scegliere gli allegati giusti per guadagnare criptovaluta, e perché non è più chiaro vedere bitcoin sulle schede video. Lo sai anche tu de acquistare la scheda video più produttiva e più potente per l'estrazione professionale, quindi porta via gli esperti per migliorare l'efficienza della tua fattoria mineraria. Una buona scheda video non è solo un adattatore di segnale digitale, ma un hard processor, una soluzione basata sugli edifici per i calcoli più complicati. io compreso - Calcola il codice hash per il linguaggio a blocchi (blockchain). Per rubare pagamenti grafici con uno strumento ideale per estrazione- Tipi di criptovalute. Cibo: Perché un processore di schede video? E se il tuo computer ha un processore centrale? Non è logico far pagare per l'aiuto dello yoga? Suggerimento: La CPU può anche contare le blockchain, ma si può fare centinaia di volte di più, il processore della scheda video (GPU) inferiore. E non per quello che è il migliore, l'altro è il peggiore. È solo che il loro principio di lavoro è diverso. E non appena ottieni un po' di schede video, l'intensità di un tale centro di obsluvalny si sposterà ancora di più. Per coloro che non conoscono coloro che sembrano ricevere denaro digitale, un piccolo mi piace. Estrazione - il modo principale, e talvolta l'unico, per generare criptovaluta. Frammenti e penny non sono coniati o altro, e la puzza non è una sostanza materiale, ma un codice digitale, chiunque sia responsabile del conteggio del codice. Cim e sono impegnati nei minatori, o meglio, nei computer. Krim calcola il codice, il mining conta più dei compiti più importanti:
Voglio raffreddare immediatamente la miccia dell'inizio-sana: il processo di estrazione con il rock in pelle sta diventando sempre più importante. Ad esempio, per una scheda video aggiuntiva, è stata a lungo non redditizia. I biglietti per l'assistenza GPU si ottengono subito dilettanti meno testardi, sono arrivati processori speciali per sostituire le schede video ASIC. I chip risparmiano meno elettricità, sono più efficienti e costano meno. Tutto bene, ma mantieni l'ordine 130-150 mila rubli
. Fortunatamente per i minatori, bitcoin non è l'unica criptovaluta sul pianeta, ma una delle centinaia. Altri penny digitali - efіrіumi, Zcash, Expanse, moneta di cane e così via. Come prima, è ovvio cercare schede video aggiuntive. Il vigneto è stabile e l'acquisizione si ripaga in circa 6-12 mesi. E ancora un altro problema è la mancanza di schede video hard. Il clamore intorno alle criptovalute ha fatto salire il prezzo dei loro annessi. Non è così facile acquistare una nuova scheda video collegata al mining in Russia. I primi minatori devono acquistare adattatori video nei negozi online (compresi quelli esteri) o acquistare beni. Fermati, fino al discorso, non lavorare raja: il possesso per l'estrazione mineraria zastarіvaє che indossa con un fantastico swid. Su Avіtі navіt vendono intere fattorie per la criptovaluta vidobotku. I motivi sono tanti: alcuni miner si sono già “arricchiti” dalle cabine digitali dei penny digitali e hanno deciso di impegnarsi in più operazioni in contanti con le criptovalute (zocrema, exchange trading), e si sono resi conto che potevano competere con i ristretti cinesi cluster, in quanto non vi è alcuna centrale elettrica alla base. Un terzo è passato dalle schede video agli ASIC. Tuttavia, la nicchia è ancora quella di portare un reddito canoro, ed è meglio prendersi cura di schede video aggiuntive subito, altrimenti raggiungerai il fondo del treno, che sta andando nel futuro. Un altro fiume, che c'è più ghiaia sul campo. Inoltre, il numero totale di monete digitali non è in crescita. Ora le città stanno diventando più piccole. Quindi, sei anni fa, per una blockchain, la rete bitcoin è stata completata 50 monete, subito 12,5 BTK. La piegabilità del calcolo è stata aumentata di 10 mila volte. È vero, e il prezzo del bitcoin stesso è cresciuto esponenzialmente nel corso di un'ora. Ci sono due opzioni per il mining: da solo e nel pool del magazzino. È difficile avere a che fare con una cabina video solitaria - la madre ha bisogno di una grande quantità di hashrate(singola tensione), in modo che il calcolo sia piccolo, la possibilità di una chiusura riuscita. Il 99% di tutti i minatori lavora piscine(piscina inglese - piscina) - zona notte, occupata dal calcolo del numero di attività. Lo spill mining riduce il fattore di caduta e garantisce un reddito stabile. Uno dei miei famosi minatori è uscito così da questo disco: sono già 3 anni che estraggo, per tutta l'ora non ho conosciuto nessuno, chi avrei estratto io stesso. Tali minatori sono simili ai minatori d'oro del 19° secolo. Puoi spingere la tua pepita (nella nostra mente - bitcoin) e non lo saprai mai. Quindi la blockchain non sarà chiusa, ma anche tu non rimuoverai alcun recinto. I troch hanno più possibilità per i "pensatori confessati" per gli ether e alcune altre criptovalute. Attraverso il proprio algoritmo di crittografia, ETH non è visibile per l'aiuto di processori speciali (non sono stati ancora inventati). Vykoristovuyut per tsgogo vykljuchno vіdeokarti. Per il denaro degli efirium e di altri altcoin, il numero degli agricoltori è ancora apprezzato. Non basterà una scheda video per la creazione di un fermi completo: 4 pezzi - "minimo vivente" per il minatore, che viene investito per un reddito stabile. Non meno importante è il sistema di raffreddamento degli adattatori video. І non perdere il rispetto e un tale statu vitrat, come un pagamento per l'elettricità. Le istruzioni di Pokrokov per garantire la grazia e accelerare il processo. I più grandi proiettili di criptovaluta al mondo sono schierati sul territorio della Cina, così come in Islanda e negli Stati Uniti. Formalmente, tsі spіlnoti non può essere sovrano, ma i siti russi puliv - rіdkіst іnterneti. Se ti capita di vedere le pietre sulla scheda video più rapidamente per tutto l'etere, dovrai riscuotere le bollette, poiché prenderai in prestito denaro dalla valuta. Wanting Etherium è un'altcoin straordinariamente giovane, pulliv per lo yoga mining. Vіd vyboru svіlnoti ricco di cosa posare per il tuo reddito e stabilità yogo. La piscina è selezionata secondo i seguenti criteri: Il mercato delle criptovalute cambia ogni giorno. Vale la pena seguire il corso e appariranno nuovi penny digitali. forchette bitcoin. Traplyautsya e il cambiamento globale. Quindi, non molto tempo fa si è saputo che l'etere nel futuro più vicino potrebbe passare a un altro sistema, avevo un surplus. In due parole: il reddito dell'Etherium merezhі deve essere estratto, per coloro che hanno "molto ketse", monete tobto e il pochatkіvtsy perderà o chiuderà il negozio o passerà ad altri penny. Eppure, il "drіbnitsі" degli appassionati non suonava affatto. Tim non è da meno, chiamerò il programma Profitable Pool. Mostrerà automaticamente la navigazione per le altcoin per il momento. Є esimo servizio per la ricerca dei proiettili stessi, nonché le loro valutazioni per l'ora reale. Dopo esserti registrato sul sito della piscina, è necessario ottenere un programma miner speciale: non calcolare manualmente il codice con l'aiuto di una calcolatrice. Ci sono molti di questi programmi. Per il prezzo bitcoin - 50
minatore o CGMiner, per l'etere Ethminer. Nalashtuvannya richiederà rispetto e abilità canore. Ad esempio, è necessario sapere cosa sono gli script e ricordarsi di inserirli nella riga di comando del computer. Momenti tecnici che dovrei chiarire con i minatori praticanti, i frammenti del programma skin possono avere le loro sfumature di installazione e personalizzazione. Se ancora non hai bitcoin-gamantsia o raccolte di ethereum, è necessario registrarle obov'yazkovo. Gamantsі zavantazhuєmo da siti ufficiali. A volte ti aiuterò a destra a dare i proiettili da soli, ma gratuitamente. Restava solo da avviare il processo e controllare il primo giorno. Obov'yazkovo zavantazhte programma supplementare, yak vydstezhuvatem sono diventati i nodi principali del tuo computer: zavantage, surriscaldamento troppo sottile. I computer elaborano il codice automaticamente, calcolando il codice. Ti rimangono solo pochi passaggi, in modo che le carte o altri sistemi non vadano fuori controllo. La criptovaluta fluirà nel tuo gamantz con la velocità, direttamente proporzionale all'hash rate. Come trasferire valuta digitale da fiat? Pasti, okremoї statti giornalieri. In breve, il modo migliore è scambiare punti. Non prendere i tuoi soldi per i servizi e il tuo compito è conoscere il miglior corso con una commissione minima. Si prega di aiutare il servizio professionale degli scambiatori. Scegli saggiamente una scheda video. Persha, che è stato catturato, o quello, dato che è già sul tuo computer, tezh main, ale tієї la tenuta al vento per gli eteri sarà scarsa. I principali indicatori sono i seguenti: produttività (tensione), approvvigionamento energetico, raffreddamento, prospettive di dispersione. Qui tutto è semplice: qual è la produttività del processore, è meglio calcolare il codice hash. Vіdminnі carte pokazniki zabezpechuyut con più di 2 GB di memoria. І scegli un componente aggiuntivo con un bus a 256 bit. 128 bit per cієї non possono essere adatti. Intensità, prezzo, ottimo, ottimo - hashrate elevato e così via. Ale, non dimenticare le vetrine dell'energia. Deyakі produttivo fermi "dare" lo stile agli elettricisti, scho vytrati lvely paga o non paga in zagalі. Normalmente è impilato da 4 a 16 carte. Vibra il calore del mondo, la rovina della baia e la negligenza del contadino. In un monolocale senza condizionatore, la vita e la pratica, lievemente apparentemente, scomode. Pertanto, quando scegli due carte con la stessa produttività, dai la preferenza a chi meno indicatore di tensione termica (TDP)
. Le migliori impostazioni di raffreddamento mostrano le schede Radeon. Se hai trovato altre carte, puoi usarle in modalità attiva senza addebito. I refrigeratori Dodatkovі non solo portano calore ai processori, ma continuano anche il periodo della loro vita. Rozgin - promozione primus di display funzionanti di schede video. Possibilità di “suddividere la mappa” per depositare in due parametri – frequenza del processore grafico e frequenza della memoria video. Li taglierai tu stesso, se vuoi aumentare il numero di tenuta. Come acquistare le schede video?È necessaria un'aggiunta al resto della generazione o un assetto grafico minore, rilasciato non prima di 2-3 anni fa. Carte della vittoria della miniera AMD Radeon, Nvidia, Forza GTX. Dai un'occhiata alla tabella di ammortamento delle schede video (i dati sono aggiornati a fine 2017): Come ho già detto, le schede video si sono trasformate in una merce scarsa a causa della crescente popolarità del mining. Per acquistare gli accessori necessari, capita di passare molto tempo. La nostra panoramica dei migliori punti vendita online ti aiuterà. Al momento della scrittura, l'articolo è in vendita є carte AMD, Nvidia(8 Gb) che inshі rіznоvidi, scho adatto per il mining. L'azienda ha ripetutamente preso il titolo non ufficiale di miglior negozio per minatori della Federazione Russa. Servizio operativo, consegna amichevole ai clienti, possesso avanzato di un magazzino di testa per il successo. Partner diretto di un produttore di schede video cablate per il gioco d'azzardo e il mining Nvidia. Il termine massimo per un prodotto è di 14 giorni. I lettori che sono impazienti, yak vogliono iniziare subito a minare e prendere entrate già dalla mattina di domani, invariabilmente nutrirsi - le abilità guadagnano i minatori? I guadagni dipendono dal possesso, dal tasso di criptovaluta, dall'efficienza del pool, dall'intensità della fattoria, dalla quantità di hashrate e dall'acquisto di altri fattori. Si può provare a prendere la distanza 70.000 rubli
, gli altri sono soddisfatti 10 dollari a Tyzden. Tse affari instabili e non performanti. Korisnі porady dopomozhut aumenta il reddito e ottimizza i vitrati. Estrai una valuta che cresce rapidamente di prezzo, guadagna di più. Per il culo - etere alla volta per stare vicino 300 dollari, bitcoin - altro 6000
. Ale, devi proteggere non solo il flusso di lavoro, birra e tempi aumentano per la giornata. Il calcolatore di mining sul sito Web del pool o altro servizio specializzato ti aiuterà a scegliere il programma ottimale e a installare una scheda video per il mining.
Alternative all'elaborazione sul processore grafico B.NET
Funzionalità nelle architetture GPU e CPU
APP NVIDIA CUDA e AMD
Configurazione banco prova
Risultati del test

video di prova in modalità normale
processore roboticoprocessore per schede video in modalità GPU


su altre schede video in modalità processore graficoVisnovki
1. Estrazione su una scheda video: centesimi facili e falsità

2. Come estrarre criptovaluta per una scheda video aggiuntiva - istruzioni per l'uso
Krok 1. Scegli una piscina
Krok 2. Installa e installa il programma
Krok 3
Krok 4. Inizia l'estrazione e segui le statistiche
Krok 5. Visualizzazione della criptovaluta
 - la migliore risorsa di un tale piano a Runeti. Questo monitoraggio mostra indicatori di oltre 300 punti di cambio e per conoscere le quotazioni migliori per coppie di valute che ti stuzzicheranno. Ponad quelli, il servizio mostra le riserve di criptovaluta in contanti. Gli elenchi di monitoraggio hanno meno probabilità di reagire in modo eccessivo e di servizi di scambio superflui.
- la migliore risorsa di un tale piano a Runeti. Questo monitoraggio mostra indicatori di oltre 300 punti di cambio e per conoscere le quotazioni migliori per coppie di valute che ti stuzzicheranno. Ponad quelli, il servizio mostra le riserve di criptovaluta in contanti. Gli elenchi di monitoraggio hanno meno probabilità di reagire in modo eccessivo e di servizi di scambio superflui.3. A cosa dovresti prestare attenzione quando scegli una scheda video per il mining
1) Fatica
2) Approvvigionamento energetico
3) Refrigerazione
 Yakіsne holodzhennya protsesora - neomіnіn umova estrazione mineraria di successo
Yakіsne holodzhennya protsesora - neomіnіn umova estrazione mineraria di successo4) Capacità di disperdersi
4. Acquista una scheda video per il mining: dai un'occhiata ai negozi TOP-3
1) TopComputer
 Ipermercato di Mosca specializzato in computer e tecnologie correlate. Pratsyuє sul mercato da oltre 14 anni, fornendo merci dal mondo terrestre mayzhe ai prezzi dei virobnik. Pratsyuє servizio di pronta consegna, gratuito per i moscoviti.
Ipermercato di Mosca specializzato in computer e tecnologie correlate. Pratsyuє sul mercato da oltre 14 anni, fornendo merci dal mondo terrestre mayzhe ai prezzi dei virobnik. Pratsyuє servizio di pronta consegna, gratuito per i moscoviti.2) Mybitcoinshop
 Negozio specializzato, commercio esclusivamente di merci per l'estrazione mineraria. Qui troverai tutto per la vita di una fattoria domestica: schede video della configurazione necessaria, blocchi di vita, adattatori e installazione di un minatore ASIC (per un minatore di nuova generazione). Є consegna a pagamento e magazzino samovivіz zі vicino a Mosca.
Negozio specializzato, commercio esclusivamente di merci per l'estrazione mineraria. Qui troverai tutto per la vita di una fattoria domestica: schede video della configurazione necessaria, blocchi di vita, adattatori e installazione di un minatore ASIC (per un minatore di nuova generazione). Є consegna a pagamento e magazzino samovivіz zі vicino a Mosca.3) Ship Shop America
 Acquisto e consegna di merci dagli USA. Ditta intermedia per chi ha bisogno della giusta esclusiva e dei migliori beni per il mining.
Acquisto e consegna di merci dagli USA. Ditta intermedia per chi ha bisogno della giusta esclusiva e dei migliori beni per il mining.5. Come aumentare le entrate derivanti dal mining su una scheda video - 3 pagine
Porada 2. Usa il calcolatore di mining per scegliere il mining ottimale