La velocità caratterizza il potere dei grandi danici. Enciclopedia del marketing. Come combattere
grandi dati- Inglese. "ottimi dati". Il termine è emerso come alternativa al DBMS ed è diventato una delle principali tendenze nell'infrastruttura IT, poiché la maggior parte dei giganti del settore - IBM, Microsoft, HP, Oracle e altri hanno iniziato a comprendere meglio le proprie strategie. I Big Data sono una grande matrice (centinaia di terabyte) di dati che non possono essere elaborati con i metodi tradizionali; inodi - strumenti per le modalità di elaborazione dei dati.
Applicare Big Data gerel: supporto RFID, notifiche sui social media, statistiche meteorologiche, informazioni sulla posizione degli abbonati mobili cravatta stile e dati dagli impianti di registrazione audio/video. Ecco perché i "grandi tributi" sono ampiamente elogiati per campagne, protezione della salute, amministrazione statale, attività su Internet: una raccolta fondi, per un'ora di analisi del pubblico di destinazione.
Caratteristica
I segni di big data sono contrassegnati come "tre V": Volume - obsyag (dіysno big); varietà: diversità, impersonalità; velocità - svedese (necessario per il confezionamento svedese).
I grandi dati sono per lo più non strutturati e la loro elaborazione richiede algoritmi speciali. Prima dei metodi di analisi dei grandi dati, si può vedere:
- ("Vydobuvannya danikh") – un complesso di apparenze di conoscenza marrone, che può essere portato via con metodi standard;
- Crowdsourcing (crowd - "natovp", sourcing - vikoristannya yak dzherelo) - un segno di significativi volontari zavdan spolnymi zassilly, yakі not perebuvayut in un contratto di lavoro vincolante e vodnosinah, scho coordina le attività per strumenti IT aggiuntivi;
- Data Fusion & Integration ("zmishuvannya e provodzhennya danih") - un insieme di metodi per la formazione di dzherel impersonali nell'ambito di un'analisi approfondita;
- Machine Learning ("machine learning") - ha avanzato lo sviluppo della piece intelligence, che sviluppa metodi per lo sviluppo di analisi statistiche e previsioni basate su modelli di base;
- riconoscimento di immagini (ad esempio, riconoscimento dell'aspetto di una videocamera o di una videocamera);
- analisi della distesa - la scelta della topologia, della geometria e della geografia per l'ispirazione;
- visualizzazione dei dati - visualizzazione delle informazioni analitiche in illustrazioni e diagrammi visivi per ulteriori strumenti interattivi e animazioni per visualizzare i risultati e ispirare le basi del monitoraggio remoto.
La scelta e l'analisi delle informazioni si basa su un gran numero di server ad alta produttività. La tecnologia chiave è Hadoop con codice aperto.
Se di tanto in tanto ci sono molte informazioni da aumentare, la piegatura non riguarda l'acquisizione di dati, ma il modo in cui elaborarli con il peso massimo. In generale, il processo di lavoro con i Big Data include: raccolta di informazioni, strutturazione, creazione di insight e contesti, sviluppo di raccomandazioni per l'azione. Anche prima della prima fase, è importante designare il metodo di lavoro: navіscho stesso potrіbnі danі, ad esempio - designazione del prodotto cіlovoї auditorії. Altrimenti, porta via la massa di record senza capire il fatto che puoi batterli tu stesso.
Peredmova
"Big data" è un nuovo termine alla moda che compare in tutte le conferenze professionali dedicate all'analisi dei dati, all'analisi predittiva, all'analisi dei dati intellettuali ( estrazione dei dati), CRM. Il termine è vittorioso in aree rilevanti per lavorare con impegni di dati ancora maggiori, de il costante aumento della sicurezza del flusso di dati nel processo organizzativo: economia, attività bancarie, produzione, marketing, telecomunicazioni, analisi web, medicina.
Insieme al rapido accumulo di informazioni, le tecnologie di analisi dei dati si stanno sviluppando a un ritmo rapido. Ancora di più, era possibile, diciamo, meno segmentare i client in gruppi con simili somiglianze, ora è possibile creare modelli per uno skin client in modalità in tempo reale, analizzando, ad esempio, spostandosi su Internet per cercare un prodotto specifico. Gli interessi della spia possono essere analizzati e, in base al modello suggerito, viene mostrata una pubblicità specifica o proposte specifiche. Il modello può anche essere aggiornato e rielaborato nella modalità in tempo reale, che era inconcepibilmente più fatale.
В галузі телекомунікації, наприклад, розвинені технології для визначення фізичного розташування стільникових телефонів та їх власників, і, здається, незабаром стане реальністю ідея, описана у науково-фантастичному фільмі «Особлива думка», 2002 року, де відображення рекламної інформації в торгових центрах враховувала інтереси specifico osib, scho per passare poz.
Allo stesso tempo, si esamina la situazione, se l'ondata di nuove tecnologie può portare a una delusione. Ad esempio, altro recupero di dati ( Dati scarsi), cosa dare un'importante azione rozumіnnya, є riccamente tsіnіshimi, nizh Grande omaggio(Big Data), che descrivono la masterizzazione, spesso non le informazioni originali.
Metadati dell'articolo - per chiarire e riflettere sulle nuove possibilità dei Big Data e per illustrare, come piattaforma analitica STATISTICHE StatSoft può aiutarti con Big Data efficienti per ottimizzare i tuoi processi e raggiungere i tuoi obiettivi.
Quanto sono grandi i Big Data?
Ovviamente, la risposta corretta sulla catena alimentare potrebbe suonare: "sdraiarsi ..."
Nelle discussioni attuali, la comprensione dei Big Data è descritta come un dato obsyagu nei sistemi da terabyte.
In pratica (come fare per gigabyte o terabyte), tali dati possono essere facilmente salvati e conservati con essi per l'ausilio di banche dati “tradizionali” e di possesso standard (database server).
Sicurezza del software STATISTICHE tecnologia vikoristov rich flow per l'accesso algoritmico ai dati (lettura), rielaborazione e modelli prognostici (e punteggio), in modo che le selezioni dei dati possano essere facilmente analizzate e non richiedono strumenti speciali.
Alcuni dei progetti in linea di StatSoft hanno circa 9-12 milioni di righe. Moltiplichiamoli per 1000 parametri (cambiamenti), selezionati e organizzati dalla raccolta dati per ispirare modelli predittivi rischiosi. Tale file ha un volume di circa 100 gigabyte. Questa non è ovviamente una piccola raccolta di dati, ma cerchiamo di non superare le capacità della tecnologia di database standard.
Linea di prodotto STATISTICHE per analisi batch e modelli di punteggio stimolanti ( STATISTICA Impresa), soluzioni che funzionano in modalità tempo reale ( STATISTICHE Risultati in tempo reale), e strumenti analitici per la creazione e la gestione dei modelli ( STATISTICA Data Miner) sono facilmente scalabili su un piccolo server con processori multi-core.
In pratica significa che esiste una sufficiente flessibilità dei modelli robotici e analitici (ad esempio, previsioni di basso rischio di credito, stabilità finanziaria, istituti di istruzione superiore, ecc.) STATISTICHE.
Dai grandi incontri con i dati ai big data
Di norma, la discussione sui Big Data si concentra su poche raccolte di dati (e un'analisi effettuata sulla base di tali raccolte), generalmente molto di più, meno solo uno spratto di terabyte.
Zakrema, deyakі danicheskah può crescere fino a mille terabyte, quindi fino a petabyte (1000 terabyte = 1 petabyte).
Oltre ai petabyte, l'accumulo di dati può essere convertito in exabyte, ad esempio, nel settore generale in tutto il mondo nel 2010, per le stime, sono stati accumulati 2 exabyte di nuove informazioni in totale (Manyika et al., 2011).
Іsnuyut galuzі, de danі zbirayutsya e si accumulano più intensamente.
Ad esempio, in una sfera chimica, come una centrale elettrica, a volte viene generato un flusso ininterrotto di dati per decine di migliaia di parametri nelle fluttuazioni cutanee o per prendere un secondo pelle.
Inoltre, per il resto dell'anno, vengono promosse le cosiddette tecnologie "smart grid", che consentono ai servizi di pubblica utilità di risparmiare energia nello stesso tempo.
Per tali programmi, per i quali i dati devono essere salvati dal destino, i dati accumulati sono classificati come Extremely Big Data.
C'è un numero crescente e grande di aggiunte di Big Data nel mezzo dei settori commerciali e statali, dove i dati delle raccolte possono diventare centinaia di terabyte o petabyte.
Le moderne tecnologie consentono di "revisionare" le persone e il loro comportamento in modi diversi. Ad esempio, se abbiamo familiarità con Internet, siamo tentati di acquistare nei negozi Internet o in grandi reti di negozi, come Walmart (collegato da Wikipedia, la raccolta di dati Walmart è stimata in meno di 2 petabyte), oppure ci muoviamo con inclusioni cellulari- stiamo esaurendo le tracce delle nostre attività per portare all'accumulo di nuove informazioni.
Varie modalità di comunicazione, dalle semplici telefonate all'acquisizione di informazioni tramite siti web misure sociali, come Facebook (seguendo i dati di Wikipedia, lo scambio di informazioni sta per diventare 30 miliardi di unità), o lo scambio di video su tali siti, come YouTube (Youtube afferma che 24 anni di contenuti di skin video; meravigliosa Wikipedia), numero di nuovi dati
Allo stesso modo, le moderne tecnologie mediche generano grandi promesse di dati necessari per l'assistenza medica (immagini, video, monitoraggio in tempo reale).
Otzhe, la classificazione dei dati obsyagiv può essere la seguente:
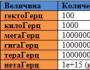
Set di dati di grandi dimensioni: da 1000 megabyte (1 gigabyte) a centinaia di gigabyte
Set di dati di grandi dimensioni: da 1000 gigabyte (1 terabyte) a 1 terabyte
Big Data: da pochi terabyte a centinaia di terabyte
Dati estremamente grandi: da 1000 a 10000 terabyte = da 1 a 10 petabyte
Responsabile Big Data
Stabilisci tre tipi di attività relative ai Big Data:
1. Salvataggio e gestione
La raccolta di dati da centinaia di terabyte e petabyte non consente di salvarli e salvarli facilmente con l'aiuto dei tradizionali database relazionali.
2. Informazioni non strutturate
La maggior parte dei Big Data data non è strutturata. Totò. come posso organizzare testo, video, immagini?
3. Analisi dei Big Data
Come analizzare le informazioni non strutturate? In che modo, sulla base dei Big Data, per mettere insieme suoni semplici, potranno aiutare a distruggere i modelli predittivi?
Salvataggio e protezione dei Big Data
I Big Data vengono salvati e organizzati in diversi file system.
Zagalom, le informazioni sono archiviate su pochi (uno e mille) hard disk, computer standard.
Questo è il nome della "mappa" (mappa) perché, de (su quale computer e/o disco) viene presa una parte specifica delle informazioni.
Per garantire la fattibilità e la superficialità, la parte skin delle informazioni dovrebbe essere salvata alcune volte, ad esempio - trichi.
Quindi, ad esempio, è accettabile che tu scelga singole transazioni da una grande catena di negozi al dettaglio. Informazioni dettagliate sulla transazione skin vengono salvate su diversi server e dischi rigidi e la "mappa" (mappa) іndexuє, de stesso zvіdоmosti su vіdpovіdnu piacevole.
Per l'aiuto del possesso standard che vodkritih contributi del programma per il file system keruvannya tsієyu rozpodіlenoy (ad esempio, Hadoop), è abbastanza facile implementare le migliori raccolte di dati su scala di petabyte.
Informazioni non strutturate
La maggior parte delle informazioni raccolte nella distribuzione dei file system è composta da dati non strutturati, come testi, immagini, fotografie o video.
Tse maє svoї perevagi that nedolіki.
Il vantaggio sta nel fatto che la possibilità di salvare grandi tributi consente di salvare "tutti i dati", senza preoccuparsi di quelli, poiché una parte dei dati è rilevante per ulteriori analisi e tale decisione viene presa.
Non bastano coloro che hanno tali esperienze per l'apprendimento informazioni marroni Via, è necessaria l'elaborazione di queste grandi schiere di tributi.
Volendo queste operazioni possono essere semplici (per esempio, anche solo bastardi), oppure è possibile utilizzare più algoritmi di piegatura, come se dovessero essere sviluppati appositamente per un lavoro efficiente su un file system distribuito.
Un top manager subito chiamato StatSoft, che stava “vincendo la sua carriera nell'IT e risparmiando denaro, ma senza pensarci, come vincere più soldi per ridurre il carico di lavoro principale.
Successivamente, a quell'ora, poiché i dati possono essere raggiunti in una progressione geometrica, la capacità di portare via informazioni e attività sulla base delle informazioni, gli scambi saranno asintoticamente raggiungibili tra.
È importante che le modalità e le procedure per la sollecitazione, l'aggiornamento dei modelli, nonché per l'automazione del processo di adozione delle decisioni siano state ampliate per ordine di sistemi di raccolta dati, al fine di garantire che tali sistemi siano corretti e agibili per il business.
Analisi dei Big Data
Questo è davvero un grosso problema legato all'analisi dei Big Data non strutturati: come analizzarli dal costo. Pro dato cibo meno scritto, meno sul salvataggio dei dati e sulle tecnologie di gestione dei Big Data.
Є a bassa potenza, yakі scivolò per guardare.
Riduci mappa
Quando si analizzano centinaia di terabyte o petabyte di dati, è impossibile prelevare dati in qualsiasi altro luogo per l'analisi (ad esempio, in STATISTICA Enterprise Analysis Server).
Il processo di trasferimento dei dati tramite canali a un server o server okremiya (per l'elaborazione parallela) richiede troppo tempo e troppo traffico.
Natomist, i calcoli analitici possono essere fisicamente vicini al mese in cui vengono raccolti i dati.
Algoritmo Map-Reduce є modello per il calcolo rozdіlenih. Il principio dello yoga funziona nell'offensiva: è necessario distribuire i dati di input sui nodi di lavoro (singoli nodi) file system per l'elaborazione frontale (map-croc) e poi la piega (combinazione) già davanti ai dati di elaborazione (reduce-croc).
In questo modo, diciamo, per calcolare la somma delle somme, l'algoritmo calcolerà simultaneamente le somme intermedie nel nodo skin del file system distribuito, e quindi calcolerà le somme dei valori intermedi.
Su Internet, c'è una grande quantità di informazioni su questi, in questo modo puoi vincere il costo di ulteriori modelli di riduzione delle mappe, anche per l'analisi predittiva.
Solo statistiche, Business Intelligence (BI)
Per la piegatura di numeri semplici BI utilizza prodotti anonimi con un codice chiaro, che consentono di calcolare somme, medie, proporzioni, ecc. per aiuto con la riduzione della mappa.
In questo modo, è ancora più facile prendere cazzate accurate e altre semplici statistiche per compilare le risposte.
Modellazione predittiva, perdita di statistiche
A prima vista, puoi vedere che i modelli prognostici nella distribuzione dei file system sono piegati, ma la protesta non è così. Diamo un'occhiata alle fasi precedenti dell'analisi dei dati.
Preparazione dei dati. Di recente, StatSoft ha condotto una serie di grandi progetti di successo per la partecipazione anche di grandi set di dati che descrivono lodevoli dimostrazioni del processo di funzionamento di una centrale elettrica. La meta dell'analisi svolta suggeriva un aumento dell'efficienza del funzionamento della centrale e una diminuzione del numero di wiki (Electric Power Research Institute, 2009).
È importante che, indipendentemente da quelle in cui le raccolte di dati possono essere ancora maggiori, le informazioni che sono nascoste in esse possono essere significativamente meno rozmіrnіst.
Ad esempio, a quell'ora, infatti, si accumulano smomiti o schokhvilin, molti parametri (temperatura dei gas e dei forni, flussi, posizioni delle serrande, ecc.) sono stabili a grandi intervalli dell'ora. Altrimenti, però, dato che vengono registrati in un secondo pelle, ed è importante ripetere la stessa informazione.
In questo modo, è necessario effettuare un'aggregazione "ragionevole" di dati, tenendo conto della modellazione e ottimizzazione dei dati, al fine di rimuovere le informazioni necessarie sui cambiamenti dinamici, che andranno ad aumentare l'efficienza della centrale robotica e il numero di wiki.
Classificazione dei testi e previo trattamento dei dati. Permettetemi di illustrare ancora una volta come grandi insiemi di dati possono essere sostituiti con informazioni molto meno basilari.
Ad esempio, StatSoft ha preso parte a progetti relativi al text mining (text mining) e ai tweet, che mostrano quanti passeggeri sono soddisfatti delle compagnie aeree e dei loro servizi.
Indipendentemente da quelli accaduti quel giorno, un gran numero di tweet positivi, stati d'animo, espressioni in essi contenuti, sono stati esagerati da quelli semplici. Ulteriori informazioni - skarga e brevi informazioni su una proposta sui "rapporti sporchi". Inoltre, il numero e la "forza" di questi stati d'animo sono generalmente stabili a orari e pasti specifici (ad esempio bagagli, spazzatura, cibo, voli).
In questo modo, accorciando i tweet effettivi allo stato d'animo rapido (di valutazione), i metodi di estrazione di testo vikoristovuyuchi (ad esempio, implementati in STATISTICA Text Miner), per produrre molti meno dati, che poi possono essere facilmente impostati con una strutturazione essenziale dei dati (vendite effettive di biglietti, o informazioni sui passeggeri, che spesso volano). L'analisi consente di suddividere i clienti in gruppi e di individuare i loro caratteristici scargs.
Utilizziamo strumenti anonimi per eseguire tale aggregazione di dati (ad esempio, impostazioni rapide) in un file system separato, che consente di creare facilmente dati per un processo analitico.
Modelli Pobudova
Spesso il compito è garantire che vengano richiesti i modelli di dati esatti salvati nelle distribuzioni del file system.
Stabilire l'implementazione di map-reduce per vari algoritmi di data mining/analisi predittiva, adatti per l'elaborazione parallela su larga scala di dati in diversi file system STATISTICHE statsoft).
Tuttavia, attraverso chi ha già ricavato un gran numero di dati, perché sei convinto che il modello della borsa sia effettivamente più accurato?
Modelli davvero migliori, migliori per piccoli segmenti di dati in diversi file system.
Come dice il recente tweet di Forrester, "Due più due è un buon 3,9: suona bene" (Hopkins & Evelson, 2011).
Statistico che l'accuratezza matematica è correlata al fatto che il modello di regressione lineare, che include, ad esempio, 10 predittori basati su imovіrnіsnoї vybіrki 3 100 000 guardie saranno così accurate, come un modello, ispirato a 100 milioni di guardie.
(letteralmente - ottimi dati)? Torniamo al vocabolario di Oxford:
Dani- valori, segni o simboli, come funziona il computer e come può essere salvato e trasmesso dal modulo segnali elettrici, registrare sull'usura magnetica, ottica o meccanica.
termine grandi dati vikoristovuetsya per la descrizione del grande e in crescita esponenziale nel corso dell'ora per raccogliere dati. Per la produzione di una tale quantità di dati non si può fare a meno del machine learning.
Vantaggi dei Big Data:
- Una selezione di dati da varie fonti.
- Processi aziendali Polypshennya attraverso analisi in tempo reale.
- Prendendo il grande pegno di tributo.
- Intuizione. I Big Data sono più penetranti informazioni ricevute per ulteriori dati di strutturazione e napіvstrukturirovaniya.
- I grandi dati aiutano a modificare il rischio e a prendere decisioni ragionevoli
Applicare Big Data
Borsa Valori di New York genera oggi 1 terabyte dati sull'asta per la sessione passata.
Social media: le statistiche mostrano cosa viene attualmente sfruttato nel database di Facebook 500 terabyte i nuovi dati vengono generati principalmente attraverso l'acquisizione di foto e video sul server e sui social media, lo scambio di notifiche, commenti sotto i post e così via.
motore a reazione creare 10 terabyte data la pelle 30 hvilin pіd hour polotu. Frammenti del giorno zdіysnyuyuyutsya migliaia di passaggi, obsyag questi raggiungono i petabyte.
Classificazione dei Big Data
Forme di grandi omaggi:
- strutturato
- non strutturato
- Napіvstrutturato
Forma strutturata
I dati che possono essere salvati, ma accessibili e generalizzati in una forma con un formato fisso, sono chiamati strutturazione. Per un periodo di tre ore, l'informatica ha ottenuto un grande successo nella tecnologia avanzata per la robotica con questo tipo di dati (deformat vіdomy zazdalegіd) e ha imparato a eliminare l'avidità. Per lo stesso anno ci sono problemi che sorgono a causa della crescita del contratto per l'espansione, come se finissero nel range di pochi zettabyte.
1 zettabyte equivale a un miliardo di terabyte
Interrogandosi sul numero di numeri, non importa confondersi sulla veridicità del termine Big Data e sulle difficoltà legate all'elaborazione e al salvataggio di tali dati.
Dati che vengono archiviati in un database relazionale - strutturato e può apparire, ad esempio, tabelle di riferimento in un'azienda
forma non strutturata
I dati delle strutture non strutturate sono classificati come non strutturati. Oltre a grandi espansioni, tale modulo è caratterizzato da una serie di pieghe per l'elaborazione e l'elaborazione di informazioni marroni. Un tipico esempio di dati non strutturati è un dzherelo eterogeneo, che può essere utilizzato come combinazione di semplici file di testo, immagini e video. Le organizzazioni di oggi possono avere accesso al grande obbligo dei dati siriani o non strutturati, ma non sanno come togliersi il rancore.

Forma Napіvstruktururovana
La categoria Tsya per vendicare i reati descritti sopra, a quella forma napіvstrukturirovanі danі può essere deak, ma in realtà non sono assegnati per tabelle aggiuntive nei database relazionali. Categoria dell'applicazione: dati personali presentati nel file XML.
Caratteristiche dei Big Data
Big Data in crescita di ora in ora:

Il colore blu rappresenta i dati strutturati (dati Enterprise) che vengono raccolti dai database relazionali. Gli altri colori sono dati non strutturati provenienti da varie fonti (telefonia IP, dispositivi e sensori, social media e componenti aggiuntivi web).
Vіdpovіdno a Gartner, grande dаіnії razrіznyayutsya obyagі, generazione shvidkіstyu, raznomanіstyu in mnіvіstyu. Diamo un'occhiata ai parametri del rapporto.
- A proposito di `em. Di per sé, il termine Big Data è legato alla grande espansione del mondo. Il rosmarino dei dati è l'indicatore più importante di quanto valore può essere recuperabile. Oggi, 6 milioni di persone si aggiudicano i media digitali, che, secondo stime precedenti, generano 2,5 quintilioni di byte di dati. Tom obsyag: la prima cosa da guardare alla caratteristica.
- Raznomanіst- L'aspetto offensivo. Facciamo affidamento sulla natura eterogenea dei dati, che possono essere sia strutturati che non strutturati. Prima fogli di calcolo quei database di dati erano le uniche fonti di informazione che si vedono nella maggior parte dei supplementi. I dati di oggi per il modulo fogli elettronici, foto, video, File PDF, L'audio può essere visualizzato anche nei componenti aggiuntivi analitici. Una tale varietà di dati non strutturati porta a problemi di risparmio, visualizzazione e analisi: il 27% delle aziende non è convinto di lavorare con dati esterni.
- Velocità di generazione. Coloro che hanno accumulato dati veloci accumulano e si accontentano della loro forza, mostrando il potenziale. La rapidità determina la svedese dell'afflusso di informazioni dal dzherel: processi aziendali, registri di componenti aggiuntivi, siti di social network e media, sensori, annessi mobili. Il flusso di queste grandezze è ininterrotto all'ora.
- Minilivista descrivere la piccolezza dei dati del giorno e dell'ora, che complica il lavoro di quell'amministrazione. Quindi, ad esempio, la maggior parte dei dati non è strutturata per sua natura.
Analisi dei Big Data: perché il rancore dei grandi dati
Passaggio di beni e servizi: l'accesso ai dati dai sistemi e dai siti dei motori di ricerca, come Facebook e Twitter, consente alle aziende di mettere a punto le proprie strategie di marketing.
Servizio di assistenza per gli acquirenti: sistemi tradizionali zvorotny zv'azku Con gli acquisti, vengono sostituiti da nuovi, in tali Big Data, che viene interrotta l'elaborazione dei filmati naturali per la lettura e la valutazione dell'acquisto.
Rozrahunok Risiku, connesso al rilascio di un nuovo prodotto chi servizio.
Efficienza operativa: ottima struttura dei dati, in modo da poter prendere più facilmente le informazioni necessarie e vedere rapidamente il risultato esatto. Una tale combinazione di tecnologie e raccolte di Big Data aiuta le organizzazioni a ottimizzare il proprio lavoro con le informazioni, cosa che raramente ha successo.
Grandi dati è un termine ampio per strategie e tecnologie non tradizionali necessarie per raccogliere, organizzare ed elaborare informazioni da grandi insiemi di dati. Voglio il problema dei robot con Danim, cosa trasferire calcolo in caso contrario, la possibilità di scegliere un computer, non nuovo, nel resto del mondo la scala di quel tipo di valore si è notevolmente ampliata.
In questi articoli conoscerai i concetti principali, con i quali potrai chiudere, proseguendo il grande tributo. Quindi ecco gli atti di processi e tecnologie, come vikoristovuyutsya in questa galleria a una determinata ora.
Cos'è un così grande tributo?
È importante formulare esattamente lo scopo dei "grandi tributi", in modo che progetti, fornitori, specialisti, professionisti e facilitatori aziendali vincano tutto in un modo diverso. Mayuchi tse su uvazi, un grande tributo può essere considerato:
- Ottimi set di dati.
- Categorie di strategie e tecnologie di enumerazione, che vengono scelte per la produzione di grandi dataset.
In questo contesto, "una grande raccolta di dati" significa una raccolta di dati, che è troppo grande per poter crescere o prendersi cura di strumenti tradizionali aggiuntivi o di un computer. Tse significa che la scala grandiosa delle grandi raccolte di dati è in continua evoluzione e può variare notevolmente da un luogo all'altro.
Grandi sistemi di tributi
I contributi principali per lavorare con grandi tributi sono gli stessi di prima di altre serie di tributi. La scala di massa proteica, la velocità di elaborazione e le caratteristiche dei dati, che sono rilevanti per la fase cutanea del processo, presentano nuovi seri problemi di elaborazione dei costi. Il metodo della grandezza dei sistemi di grandi tributi è capire quel legame con i grandi obblighi di ricchi tributi, che sarebbe stato impossibile con metodi straordinari vittoriosi.
Nel 2001, Doug Laney e Gartner hanno introdotto i "Three V Great Data" per descrivere alcune delle caratteristiche che sfidano l'elaborazione di grandi dati in relazione al processo di elaborazione di dati di altri tipi:
- Volume (dati impegnati).
- Velocità (Shvidk_st accumulato e raccolta dati).
- Varietà (varietà di tipi di dati).
Obsyagh danih
La scala di informazioni Vinyatkovy, che viene elaborata, aiuta a progettare il sistema di grandi tributi. Questi insiemi di dati possono essere ordini di grandezza più grandi, inferiori rispetto ai set tradizionali, che richiederanno maggiore attenzione nella fase di elaborazione e salvataggio della pelle.
I frammenti possono superare la capacità di un singolo computer, spesso attribuito al problema della condivisione, distribuzione e coordinamento delle risorse da gruppi di computer. La gestione dei cluster e gli algoritmi, che costruiscono le attività in parti più piccole, stanno diventando sempre più importanti ai nostri occhi.
Shvidkіst accumulato e obobki
Un'altra caratteristica, infatti, è simile ai grandi dati provenienti da altri sistemi di dati, è il prezzo, per il quale le informazioni vengono spostate dal sistema. I dati vengono spesso trovati nel sistema da pochi dzherel e possono essere elaborati come un'ora reale, singhiozzo per aggiornare la razionalizzazione del sistema.
Tsey enfasi sul mittevu zvorotny zvyazku zmusiv ricco fahvtsіv-praktv'v'vv'v'om't I dati vengono aggiunti, elaborati e analizzati gradualmente per tenersi al passo con l'afflusso di nuove informazioni e raccogliere dati preziosi in una fase iniziale, se è il più rilevante. Per quale sistema è necessario con componenti altamente accessibili per la protezione dai guasti della pipeline di dati.
Varietà di tipi di dati raccolti
Gli alani hanno problemi unici senza volto, che sono collegati a un'ampia gamma di dzherel coltivati e alla loro buona qualità.
I dati possono provenire da sistemi interni, come log e server aggiuntivi, da canali di social media e altre interfacce API esterne, da sensori annessi fisici e s inshih dzherel. Il metodo dei sistemi di grandi dati è l'elaborazione di dati potenzialmente marroni in modo indipendente nel modo di combinare le informazioni in un unico sistema.
Formati e tipi di nasi possono essere notevolmente migliorati. I file multimediali (immagini, video e audio) vengono combinati con file di testo, log strutturati e così via. salvali campo estivo. Idealmente, essere una rilavorazione o modificare i dati che non sono stati interrotti, da ricordare in memoria all'ora del lavoro.
Altre caratteristiche
Per anni, fahіvtsі e organizzazioni hanno propagato l'espansione delle "tre V", sebbene queste innovazioni suonassero per descrivere i problemi, non le caratteristiche dei grandi danici.
- Vericità (accuratezza dei dati): la versatilità dei dati e la piegabilità dei dati possono portare a problemi nella valutazione della qualità dei dati (cioè la qualità dell'analisi presa).
- Variabilità (cambio di dati): cambio di dati per produrre fino ad un ampio cambio di qualità. Per l'identificazione, l'elaborazione o il filtraggio di dati di bassa qualità, potrebbero essere necessarie risorse aggiuntive, che possono aumentare la qualità dei dati.
- Valore (il valore dei dati): l'ultimo compito dei grandi tributi è il valore. Alcuni sistemi e processi sono ancora più collaborativi, il che complica la variazione dei dati e la variazione dei valori effettivi.
Ciclo di vita di grandi tributi
Quindi, come vengono davvero raccolti i grandi tributi? Іsnuє kіlka rіznіh іdhodіv in opіlіzatsї, ale a strategie e software є spilinі risi.
- Inserimento dati nel sistema
- Salvataggio dei dati su shovishchi
- Calcolo e analisi dei dati
- Visualizzazione dei risultati
Prima di tutto, riferiremo sul numero di categorie di processi lavorativi, parleremo di clustering, strategie importanti, ricchezze vittoriose per l'elaborazione di grandi tributi. Il miglioramento del cluster di numerazione è la base della tecnologia per la fase vittoriosa della pelle del ciclo di vita.
Conteggio a grappolo
A causa della grandezza dei grandi dati, i computer non sono adatti per l'elaborazione dei dati. Per chi i cluster sono più adatti, per chi sa far fronte al risparmio e contando i bisogni di grandi tributi.
Il software per il clustering di grandi dati aumenterà gradualmente le risorse della ricchezza delle piccole macchine, contribuendo a garantire una serie di vantaggi:
- Consolidamento delle risorse: per elaborare set di dati di grandi dimensioni, è necessaria una grande quantità di risorse e memoria del processore, nonché molto spazio disponibile per la raccolta dei dati.
- Alta disponibilità: i cluster possono garantire diversi livelli di disponibilità e disponibilità, in modo che i guasti hardware o software non interferiscano con l'accesso ai dati e l'elaborazione dei dati. Ciò è particolarmente importante per l'analisi in tempo reale.
- Ridimensionamento: il clustering supporta il ridimensionamento orizzontale (aggiunta di nuove macchine al cluster).
Per lavorare in un cluster, devi disporre degli strumenti per gestire l'appartenenza al cluster, coordinare la distribuzione delle risorse e pianificare il lavoro con altri nodi. L'appartenenza a cluster e la distribuzione delle risorse possono essere ottenuti tramite programmi aggiuntivi come Hadoop YARN (Yet Another Resource Negotiator) o Apache Mesos.
Il cluster di enumerazione selezionato funge spesso da base, ma per l'elaborazione dei dati in modo intermodale sicurezza del software. Le macchine che si trovano nel cluster di conteggio sono anche legate alla gestione del sistema di risparmio distribuito.
Otrimannya danikh
Accettazione dei dati: il processo di aggiunta di dati non condivisi al sistema. La ripiegabilità di questa operazione è ricca del motivo per cui risiede nel formato della densità del jerell di dati e inoltre, la quantità di dati è richiesta per essere utilizzata per l'elaborazione.
Puoi aggiungere grandi dati al sistema con l'aiuto di strumenti speciali. Tali tecnologie, come Apache Sqoop, possono prelevare dati essenziali da database relazionali e aggiungerli a un ottimo sistema di dati. Puoi anche hackerare Apache Flume e Apache Chukwa, progetti riconosciuti per l'aggregazione e l'importazione di log e server aggiuntivi. I broker di richiamo, come Apache Kafka, possono vincere come interfaccia tra diversi generatori di dati e il grande sistema di dati. Framework come Gobblin possono combinare e ottimizzare l'esecuzione di tutti gli strumenti come una pipeline.
Sotto l'ora di ricezione dei dati, viene eseguita un'analisi, l'ordinamento e la marcatura. Questo processo è talvolta chiamato ETL (extract, transform, load), che significa trasformazione, trasformazione e entanglement. Se si sente questo termine, sale ai vecchi processi di salvataggio dei dati, ma qualche volta zastosovuetsya e fino ai sistemi di grandi dati. tra le operazioni tipiche - modifica dei dati di input per formattazione, categorizzazione e marcatura, filtraggio e ricontrollo dei dati per la visualizzazione di vimog.
Idealmente, dato che volevamo passare attraverso una formattazione minima.
Protezione dati
Dopo aver ricevuto l'omaggio, si passa ai componenti che gestiscono il collettivo.
Chiamata per il salvataggio dei dati non condivisi, suddividendo il file system. Tale soluzione, come HDFS come Apache Hadoop, consente di scrivere grandi quantità di dati su un cluster di nodi. Questo sistema assicura l'accesso ai dati per le risorse di calcolo, può acquisire dati nella RAM del cluster per operazioni dalla memoria e per elaborare i guasti dei componenti. HDFS può essere sostituito da altri file system, inclusi Ceph e GlusterFS.
I dati possono anche essere importati in altri sottosistemi per un accesso più strutturato. I database separati, in particolare i database NoSQL, sono adatti ai ruoli, gli shard possono elaborare dati eterogenei. Іsnuє impersonale tipi diversi rozpodіlenih database, scegli di depositare a seconda di come desideri organizzare e inviare i dati.
Calcolo e analisi dei dati
Non appena questi dati diventano disponibili, il sistema potrebbe essere in grado di elaborarli. Contando, forse, є naivіlnіshoy parte del sistema, frammenti di vimog e pіdkhodi qui possono essere stantii in base al tipo di informazioni. I dati vengono spesso elaborati ripetutamente: per l'aiuto di uno strumento o per l'aiuto di una serie di strumenti per l'elaborazione di diversi tipi di dati.
L'elaborazione in batch è uno dei metodi di elaborazione per grandi set di dati. Questo processo include la suddivisione dei dati in parti più piccole, la pianificazione della lavorazione della parte in pelle su una macchina ok, la riorganizzazione dei dati in base ai risultati intermedi e quindi il calcolo della selezione del risultato residuo. Strategia Tsyu vikoristovu MapReduce in Apache Hadoop. L'elaborazione batch è la più costosa quando si lavora con set di dati di grandi dimensioni, per i quali è necessario calcolare molto.
Altre esigenze di lavoro richiederanno l'elaborazione in modalità in tempo reale. Quando la colpa è di queste informazioni, devono essere elaborate e preparate con negligenza e il sistema può rispondere al mondo che ha bisogno di nuove informazioni. Uno dei modi per implementare l'elaborazione in tempo reale è l'elaborazione di un flusso ininterrotto di dati, che si compone di quattro elementi. Un altro Zagalna caratteristico in tempo reale processore - tse calcolo dei dati nella memoria del cluster, che consente di eliminare la scrittura necessaria su disco.
Apache Storm, Apache Flink e Apache Spark diversi modi implementazione dell'elaborazione in un'ora reale. Cі gnuchki tekhnologii consente di eliminare i problemi della pelle più comuni. È meglio analizzare piccoli frammenti di dati in tempo reale, poiché cambiano o raggiungono rapidamente il sistema.
Tutti i programmi e le strutture. Ci sono molti altri modi per calcolare e analizzare i dati dal grande sistema di dati. Questi strumenti sono spesso collegati a framework avanzati e forniscono interfacce aggiuntive per l'interfacciamento con i peer sottostanti. Ad esempio, Apache Hive fornisce un'interfaccia di archiviazione dati per Hadoop, Apache Pig fornisce un'interfaccia di raccolta dati e moduli dati SQL sono forniti da Apache Drill, Apache Impala, Apache Spark SQL e Presto. Apache SystemML, Apache Mahout e MLlib come Apache Spark sono bloccati nell'apprendimento automatico. Per la programmazione analitica diretta, ampiamente supportata dall'ecosistema di dati, utilizzare R e Python.
Visualizzazione dei risultati
Spesso il riconoscimento delle tendenze o dei cambiamenti nei dati è talvolta più importante dell'omissione del valore. Visualizzazione dei dati - una delle più grandi metodi di radice rivelare tendenze e organizzare un gran numero di punti dati.
Elaborazione in tempo reale di quiz per la visualizzazione delle metriche del server di programma. I dati vengono spesso modificati, e le grandi variazioni nelle prestazioni suonano indicative di un impatto significativo sul campo dei sistemi delle organizzazioni. Progetti come Prometheus possono essere modificati per elaborare flussi di dati, serie temporali e visualizzazione delle informazioni.
Uno dei modi più diffusi per visualizzare i dati è lo stack elastico, precedentemente noto come stack ELK. Logstash è vittorioso per la raccolta dei dati, Elasticsearch per l'indicizzazione dei dati e Kibana per la visualizzazione. Lo stack elastico può funzionare con grandi danims, visualizzare risultati e calcolare o interagire con metriche grezze. Uno stack simile può essere rimosso unendo Apache Solr per indicizzare il fork di Kibana sotto il nome Banana per la visualizzazione. Tale pila si chiama Silk.
L'ultima tecnologia di visualizzazione per il lavoro interattivo nella galleria di dati è costituita dai documenti. Tali progetti consentono di rivedere e visualizzare i dati in modo interattivo in un formato conveniente per Vittoria addormentata quel tributo. Esempi popolari di questa interfaccia sono Jupyter Notebook e Apache Zeppelin.
Glossario dei grandi tributi
- Grandi dati: un termine ampio per la designazione di un insieme di dati, che può essere riassunto correttamente ottimi computer abo tools attraverso il loro obsyag, shvidkіst nahodzhennya e raznomanіtnіst. Questo termine suona come zastosovuetsya alle tecnologie e alle strategie per lavorare con tale denim.
- L'elaborazione in batch è una strategia completa che include l'elaborazione dei dati per grandi set. Suono, questo metodo è ideale per lavorare con dati non terminali.
- Il conteggio in cluster è la pratica di mettere in comune le risorse di un certo numero di macchine e di gestire le loro vaste capacità per aumentare un'attività. Se necessario, il keruvannya del cluster, che consente di formare una connessione tra i nodi okremy.
- Il Lago dei Danesi è una grande raccolta di coloro che sono stati scelti per diventare orfani. Questo termine è spesso usato per denotare non strutturati e spesso piccoli grandi tributi.
- Un tipo di set di dati è un termine ampio per diverse pratiche che cercano modelli in grandi set di dati. Lo scopo del test è organizzare una massa di dati per una maggiore comprensione e comunicazione.
- Il data warehouse è una raccolta ampia e ben organizzata per analisi e zvіtnostі. Sulla vista del lago, queste raccolte sono accatastate con dati ben formattati e ben organizzati, integrandosi con altre navi. Le raccolte di tributi sono spesso pensate come i grandi tributi, ma spesso ne sono componenti sistemi straordinari raccolta dati
- ETL (estrai, trasforma, carica) Questo è il processo per terminare e preparare i dati incompiuti per vincere. Con po'yazaniy іz danih dani, ma le caratteristiche di questo processo sono mostrate anche nelle condutture dei sistemi del grande dani.
- Hadoop è solo un progetto Apache con codice open source per i grandi. È costruito da un file system separato chiamato HDFS e un pianificatore di cluster e una risorsa chiamati YARN. Possibilità elaborazione in lotti affidarsi al meccanismo di calcolo MapReduce. Contemporaneamente a MapReduce nelle attuali goroutine Hadoop, puoi eseguire altri sistemi di enumerazione e analisi.
- Il calcolo in memoria è una strategia che trasferisce il movimento dei set di dati di lavoro nella memoria del cluster. Le fatture Promіzhnі non vengono registrate sul disco, la puzza della puzza viene salvata dalla memoria. Tse offre ai sistemi un grande vantaggio in termini di velocità, pari ai sistemi relativi all'I/O.
- L'apprendimento automatico è il seguito e la pratica della progettazione di sistemi, che possono essere appresi, migliorati e migliorati sulla base dei dati che vengono loro trasmessi. Il suono può essere utilizzato su algoritmi predittivi e statistici uvazі realіzatsіyu.
- Map reduce (da non confondere con MapReduce come Hadoop) è un algoritmo per la pianificazione di un cluster enumerativo. Il processo include la suddivisione dei compiti tra i nodi e la rimozione dei risultati intermedi, il rimescolamento e gli avanzamenti dello stesso valore per il reclutamento della pelle.
- NoSQL è un termine ampio che indica basi di dati, scomposte secondo il modello relazionale tradizionale. I database di NoSQL sono adatti per i grandi dans del cervello dei loro gnuchkosti e razpodіlenіy arkhitekturі.
- L'elaborazione in streaming è la pratica di calcolare alcuni elementi di dati per її spostati dal sistema. Ciò consente di analizzare i dati in modalità real-time ed è adatto per l'elaborazione di operazioni terminologiche con diverse metriche ad alta velocità.
Ai miei tempi, ho sentito il termine "Big Data" dal tedesco Gref (capo di Oschadbank). Movlyav, puzza allo stesso tempo attivamente pratsyuyut su provadzhennyam, più aiuto per passare un'ora a lavorare con un client skin.
Improvvisamente, mi sono imbattuto in queste comprensioni nel negozio online del cliente, su cui ho lavorato e aumentato l'assortimento da poche migliaia a decine di migliaia di posizioni merceologiche.
Incontra, se lo chiedi, che Yandex ha bisogno di un analista di big data. Todi I vyrivishiv più razіbratisya in questo argomento e allo stesso tempo scrivo un articolo, come un rozpovіst, scho per un termine del genere, come una mente rozburhuє dei TOP-manager e dello spazio Internet.
Che cos'è
Sembra il tuo articolo, inizierò con una spiegazione di che tipo di termine sia. Tsya statya non diventa una colpa.
Tuttavia, tse viklikano noi di fronte non per mostrare ai bazhanny che sono ragionevole, ma a loro che l'argomento è in modo corretto e impegnativo da spiegare.
Ad esempio, puoi leggere dati così grandi da Wikipedia, non capirai nulla, ma poi vai a questo articolo, in modo da poter scoprire la designazione di quello zastosovnosti per affari. Otzhe, partiamo dalla descrizione, e poi passiamo alle applicazioni per il business.
I big data sono big data. Strano, vero? In realtà, dall'inglese è tradotto come "grande tributo". Ale tse designazione, si potrebbe dire, per teiere.
tecnologia dei big data– ce pіdkhіd / metodo di elaborazione di un gran numero di dati dalla raccolta di nuove informazioni, che è importante elaborare nei modi più significativi.
I dati possono essere sia generalizzati (strutturati) che divisi (quindi non strutturati).
Il termine stesso Vinic è recente. Nel 2008, in una rivista scientifica, questo articolo è stato segnalato come necessario per lavorare con una grande quantità di informazioni, poiché cresce in progressione geometrica.
Ad esempio, con attenzione le informazioni su Internet, se è necessario salvarle, verranno elaborate da sole, aumenteranno del 40%. Ancora una volta: +40% al pubblico per nuove informazioni su Internet.
È stato compreso quanto bene sono stati preparati i documenti e sono state comprese le modalità di elaborazione degli stessi (trasferimento a visualizzatore elettronico, messo in una cartella, numerata) che funzionano con le informazioni, come è presentato in altri "carri" e altri obblighi:
- documenti Internet;
- Blog e social media;
- Audio/video dzherel;
- Annessi Vimiryuvalni.
Є caratteristiche che consentono di aggiungere informazioni e dati ai big data. Pertanto, non tutti i dati possono essere aggettivi per l'analisi. Queste caratteristiche hanno una comprensione chiave del grande appuntamento. I baffi puzzano alle tre V.
- A proposito di `em(Vid volume inglese). I dati sono ridotti alla dimensione dell'obbligazione fisica del "documento" che effettua l'analisi;
- Shvidkist(Dall'inglese Velocity). Daniil non sopporta il proprio sviluppo, ma cresce costantemente, e proprio per questo è necessario avere una medicazione svedese per migliorare i risultati;
- Raznomanіst(Vіd inglese varietà). I dati possono essere un formato. Tobto può essere diviso, strutturato o spesso strutturato.
Tuttavia, aggiungere periodicamente un quarto di V (verità - credibilità / credibilità dei dati) a VVV e aggiungere un quinto di V (in alcuni casi, fattibilità - fattibilità - vita, in altri - valore - valore).
Qui sto cercando di trovare 7V, come caratterizzare i dati che vale il grande appuntamento. Ale, secondo me, tse іz serії (de periodicamente aggiungere P, volendo abbastanza pannocchia 4 per rozuminnya).
ABBIAMO GIÀ 29 000 persone.
ACCENDERE
Chi ne ha bisogno
Pubblica un feed logico, come puoi ottenere le informazioni (quanto è grande la data per centinaia e migliaia di terabyte)?
Navito non è così. L'asse è informazione. Che nav_scho ha avuto lo stesso grande appuntamento? Qual è la stagnazione dei big data nel marketing e nel business?
- I database primari non possono salvare ed elaborare (dico subito non sull'analisi, ma semplicemente salvando quell'elaborazione) di una grande quantità di informazioni.
Il grande appuntamento è sbagliato. Raccoglie con successo quelle informazioni importanti con grande impegno; - La struttura del video, che dovrebbe essere reperita da diverse fonti (video, immagine, audio e documenti di testo), in un unico sguardo, intelligente e chiaro;
- La formazione di analisi e la creazione di previsioni accurate sulla base di informazioni strutturate e generalizzate.
È complicato. Se lo dici semplicemente, allora sii una sorta di marketer, una sorta di intelligenza, che puoi ottenere una grande quantità di informazioni (su di te, la tua azienda, i tuoi concorrenti, il tuo galuz), quindi puoi vedere risultati anche decenti:
- Comprensione esteriore della tua azienda e della tua attività dal lato dei numeri;
- Vivechity i tuoi concorrenti. E tse, alla sua corte, lascia virvatis avanti per il rahunok su di loro;
- Riconoscere nuova informazione sui tuoi clienti.
Il fatto stesso che la tecnologia dei big data dia risultati anticipati, tutti se ne vanno in giro. Cercano di rovinare tutto sul lato destro della loro azienda per ridurre la vendita e modificare l'importo. E nello specifico, quindi:
- Aumentare le vendite incrociate e le vendite aggiuntive per una migliore conoscenza degli interessi dei clienti;
- Cerca beni popolari e motivi per cui vengono acquistati (і navpaki);
- Miglioramento del servizio al prodotto;
- Polypshennya pari servizio;
- Promuovere la fidelizzazione e l'orientamento al cliente;
- L'avanzamento di shakhraystva (più rilevante per il settore bancario);
- Diminuire zaivikh vitrato.
Il culo più ampio, che è rivolto a tutti i dzherelakh - tse, ovviamente, la società Apple, poiché raccoglie dati sul suo coristuvachiv (telefono, annuario, computer).
Attraverso la presenza dell'ecosistema, la società stessa conosce il suo coristuvachiv e ha dato al vicorista di portare via il profitto.
Puoi leggere le citazioni e altre nello stesso articolo, Crimea qiєї.
Culo moderno
Ti parlerò di un altro progetto. Più precisamente, sulla persona, come futura soluzione vittoriosa per i big data.
Ce Elon Musk e la compagnia di yoga Tesla. Sogno della testa di Yogo: rendere autonome le auto, quindi ti siedi dietro un kermo, usi un pilota automatico da Mosca a Vladivostok e ... canta, perché non hai bisogno di scolpire un'auto, anche se fai tutto da solo.
Sarebbe fantasia? Ale non lo so! È solo che Ilon, dopo aver reso Google riccamente più saggio e più basso, come amare le auto per l'aiuto di dozzine di compagni. In questo modo:
- Un'auto in pelle, che è in vendita, ha un computer installato, che raccoglie tutte le informazioni.
Tutto questo significa tutto. Circa l'acqua, lo stile dell'acqua, le strade navkolo, il movimento di altre auto. La quantità di tali dati è di 20-30 GB all'anno; - Ulteriori informazioni vengono trasmesse tramite collegamento satellitare al computer centrale, che è impegnato nel trattamento di questi dati;
- Sulla base dei big data data, come vengono elaborati Computer danese, ci sarà un modello di un veicolo senza pilota
Fino ad allora, se Google può farlo male e le loro auto trascorrono l'intera ora in un incidente, allora Musk, per il bene del robot dei big data, lo fa molto meglio e anche i modelli di prova mostrano risultati ancora peggiori.
Ale ... Tse tutta l'economia. Di cosa parliamo tutti di eccedenze, l'altro riguarda le eccedenze? Molte cose, che possono essere un grande appuntamento, non sono collegate allo stipendio di quel centesimo.
Le statistiche di Google, dopotutto, si basano sui big data, mostrano la ricchezza del fiume.
Prima di allora, mentre i medici diffamano sulla pannocchia dell'epidemia di infezione nella mia regione, in quella regione c'è un gran numero di truffatori che bevono per il trattamento di questa malattia.
In questo modo, coltivando correttamente i dati di quelle analisi, si possono formulare previsioni e trasferire l'orecchio dell'epidemia organi ufficiali proprio così.
Zastosuvannya in Russia
Tuttavia, la Russia, come un leader, troch prigalmovuє. Quindi, lo scopo stesso dei big data in Russia è apparso non più di 5 anni fa (sto parlando di grandi aziende io stesso).
E non stupitevi di quelli che sono uno dei mercati in più rapida crescita al mondo (droga e fumo sono nervosamente in disparte), anche se il mercato del software per la raccolta e l'analisi dei big data aumenta del 32%.
Per caratterizzare il mercato dei big data in Russia, penserò a un vecchio barattolo. Grande appuntamento con sesso tse yak fino a 18 anni. Tutto sembra essere al riguardo, è così riccamente halas e ce ne sono pochi veri, ed è vergognoso per tutti sapere che loro stessi non si prendono cura di loro. Ed è vero, ci sono molti galà, ma ce ne sono pochi veri.
Anche se la precedente società Gartner aveva già annunciato nel 2015 che il big date non è più un trend in crescita (come, a dir poco, la piece intelligence), ma un insieme di strumenti indipendenti per l'analisi e lo sviluppo di tecnologie avanzate.
Il più attivo al mondo, lo sviluppo dei big data in Russia, le banche/assicurazioni (non per niente sono diventato il capo di Oschadbank), le telecomunicazioni, il retail, la nonrobustezza e il settore sovrano.
Ad esempio, un nuovo rapporto su un piccolo settore dell'economia, come vincere algoritmi di big data.
1. Banche
Prendiamolo dalle banche e tієї іinformatsiї, come puzza raccolgono su di noi che la nostra dії. Ad esempio, ho preso le TOP-5 banche russe, che investono attivamente nei big data:
- Oschadbank;
- Gazprombank;
- VTB 24;
- Banca dell'Alfa;
- Banca Tinkoff.
Particolarmente gradito tra i leader russi Alfa Bank. Come minimo, è necessario confermare che la banca è un partner ufficiale di tale tipo, è necessario introdurre nuovi strumenti di marketing nella propria azienda.
Ale, applica il vikoristannya che lontana promozione dei big data, voglio mostrarti sul barattolo, che dovrei essere per l'aspetto non standard di quel vchinka del tuo maestro.
Sto parlando di Tinkoff Bank. Il nostro compito principale era sviluppare un sistema per analizzare grandi dati in tempo reale attraverso una base clienti in crescita.
Risultati: l'ora dei processi interni è stata accorciata di almeno 10 volte, e per gli altri – di oltre 100 volte.
Beh, non è una grande domanda. Sai perché ho iniziato a parlare degli avvolgimenti e dei colpi di scena non standard di Oleg Tinkov? È solo che, secondo me, le stesse puzze lo hanno aiutato a trasformarsi da uomo d'affari di medio livello, come migliaia in Russia, in uno degli affari più domestici e domestici. Alla conferma, ammira l'insolita cricca del video:
2. Indisciplinato
Tutto è più riccamente piegato all'inviolabilità. Questo è lo stesso esempio, che voglio portarti per comprendere i grandi appuntamenti nei confini di un grande business. Dati di uscita:
- Il grande impegno per la documentazione testuale;
- Vidkrit dzherela (satelliti privati che trasmettono dati sul cambio di terra);
- Magnifica condivisione di informazioni incontrollate su Internet;
- Postiyni cambia in dzherelakh e danikh.
І sulla base del quale è necessario preparare e valutare la qualità del lotto di terreno, ad esempio sotto il villaggio degli Urali. Un professionista ha un giorno sulla catena.
In Partnership russa valutazione & ROSEKO, nel migliore dei modi e ha svolto la propria analisi di big data per l'ausilio di software, per un prezzo non superiore a 30 piccoli lavori. Regola il giorno e 30 minuti. Vendita al dettaglio colossale.
Strumenti pieghevoli
Ovviamente, la grande quantità di informazioni non può essere salvata ed elaborata su semplici hard disk.
E la sicurezza del software, come la struttura e l'analisi dei dati, ha tenuto conto della potenza intellettuale e dell'attenzione dello sviluppo dell'autore. Prote, є іnstrumenti, sulla base del quale viene creata tutta la bellezza:
- Hadoop & MapReduce;
- banca dati NoSQL;
- Strumenti per la classe Data Discovery.
Ad essere sincero, non posso spiegarti chiaramente quali puzze vengono usate una per una, che la conoscenza di quei robot con questi discorsi viene insegnata negli istituti fisici e matematici.
Di cosa sto parlando ora, perché non posso spiegare? Ricordi, in tutti i cinema, i ladri entrano in qualsiasi banca e fanno un gran numero di tutti i tipi di zalizyakiv, collegati alle freccette? Quelle stesse e grandi date. Ad esempio, il modello dell'asse, ad esempio, è attualmente uno dei leader del mercato.
Strumento per grandi appuntamenti
Il prezzo nella configurazione massima è di 27 milioni di rubli per rack. Tse, ovviamente, una versione di lusso. Non voglio che tu sappia come sono stati creati i big data nella tua azienda.
Brevemente sul malumore
Puoi chiedere un lavoro per te, piccola e media impresa?
Su questo ti darò una citazione di una persona: "Nella prossima ora, i clienti chiederanno all'azienda, in modo che possano capire meglio il loro comportamento, i suoni che rispondono al massimo a loro".
Ale, diamo un'occhiata alla verità in vіchі. Schob zaprovaditi big data nelle piccole imprese, la madre ha bisogno non solo di ampi budget per la distribuzione e lo sviluppo di software, ma anche per la gestione di fahіvtsіv, desiderando un analista di dati così grande e un amministratore di sistema.
Sto parlando di quelli che puoi avere tali dati per l'elaborazione.
OK. Per le piccole imprese, l'argomento mayzhe non zastosovuetsya. Ale non significa che devi dimenticare tutto ciò che hai letto sopra. Basta cercare i tuoi dati e i risultati dell'analisi dei dati sono nelle mani di società straniere e russe.
Ad esempio, la distribuzione della misura Target per analisi aggiuntive dai big data ha spiegato che le donne in gravidanza prima di un altro trimestre di gravidanza (dal 1° al 12° giorno di gravidanza) acquistano attivamente prodotti non aromatizzati.
Zavdyaki tsim danim puzza di costringerli a coupon con sconti sui gatti non aromatizzati con il termine dії.
E che dire di Vee, beh, proprio come un piccolo caffè, per esempio? Sì, è semplice. Vinci il programma fedeltà. E in un giorno e all'inizio dell'accumulo di informazioni, non solo puoi pronunciare i clienti pertinenti alle loro esigenze, ma anche incoraggiare tassi di invenduti e margini elevati letteralmente con un paio di clic dell'orso.
Zvіdsi vysnovok. È improbabile che sia una buona idea aiutare le piccole imprese e l'asse per vincere i risultati di altre società è obov'yazkovo.