情報の採用と処理。 データ構造。 コンピュータによる情報処理方法に関連する問題
処理は情報から生じる主要な操作の 1 つであり、主に情報の多様性を高めます。
情報処理の方法は、人類が作成したシステムのすべてのデバイスに基づいており、最も重要なことに、コンピューターは情報を処理するための万能の機械です。
p align="justify">コンピュータは、さまざまなアルゴリズムを使用して情報を処理します。
生物や植物は、その器官やシステムに関する情報を収集します。
情報処理とは、情報の場所と形式を体系的に変更するプロセスです。
情報の処理は、任意の主体または対象(たとえば人間や自動装置)によって規則に従って実行されます。 彼はヴィコナヴィアン情報処理者と呼ばれています。
外部メディアと対話するすべての処理は、処理可能な入力情報をそこから抽出します。 処理結果が出力情報となり、外部媒体に送信される。 したがって、外部中間は、入力情報のソースおよび出力情報の生成として機能します。
情報の処理には法律で定められた規則が適用されます。 隣接する処理手順の順序を記述した処理規則は、情報処理アルゴリズムと呼ばれます。
すべての処理は、プロセッサと呼ばれる処理ユニットと、処理された情報と処理ルール (アルゴリズム) の両方が保存されるメモリ ユニットの記憶に基づいています。
「情報処理」というトピックを説明し、新しい情報の削除に関連する処理と、情報の表示形式の変更に関連する処理の例を示します。
1 番目のタイプの処理: 新しい情報、新しい知識の作成に関連する処理。 最も重要な数学的タスクをどのような種類の処理に行うべきか。 世の中のさまざまな問題を解決するには、どのような情報処理を行うべきかという論理的な判断が必要です。
たとえば、特定の証拠に従えば、悪者が誰であるかがわかります。 人は、起こった状況を分析して、将来の行動について決定を下します。 今後は古文書の謎を解き明かすことになる。
別のタイプのトリミング:形状を変えて編むトリミングですが、場所は変えません。 このタイプの情報処理には、たとえば、テキストを 1 つの言語に翻訳することが含まれます。つまり、形式が変更され、そうでない場合は置き換えたものが保存されます。 コンピューター サイエンス処理の重要なタイプはコーディングです。 コーディングとは、情報を記号形式に変換し、手動で保存、送信、処理することを意味します。
データの構造は別のタイプの処理に転送できます。 この構造は、曲順の導入、情報収集の曲構成に関連付けられています。 データのアルファベット順の配置、さまざまな分類記号によるグループ化、表形式とグラフ表現の選択 - これらすべてが構造に適用されます。
特殊な種類の情報処理は検索です。 現在の検索は次のように定式化する必要があります。大量の情報があります - 情報の配列 (電話相談員、辞書、電車の時刻表など)、歌う心に冗談を与えるのに適した必要な情報 (電話番号) を知る必要があります。この組織の内容、この単語の英語への翻訳、この列車の出発時間)。 検索アルゴリズムは情報を整理する方法にあります。 情報が構造化されている場合、検索結果はより速く表示され、最適化することができます。
情報処理システム
データ処理には、集中型、分散型、分散型、統合型などさまざまな種類があります。CC の可視性は一元化されています。 この方法では、通信相手は出力情報をコンピュータセンターに納品し、処理結果を有効な文書の形で保管します。 この処理方法の特徴は、スムーズで中断のない接続を確立することの複雑さと難しさ、(大きな義務のための)VC 情報の非常に重要性、財務業務条件の規制、可能性からシステムを保護しない組織です。不正アクセス。
処理は分散化されています。 この方法は PEOM の出現に関連しており、特定の作業領域を自動化することが可能になります。 現在、分散データ処理には 3 種類の技術があります。
Persha は、ローカル ネットワークに接続されていないパーソナル コンピュータ上で実行されます (データは別のファイルおよび別のディスクに保存されます)。 表示を削除するには、コンピュータに情報を書き換えてください。 欠点: 相互に関連するタスクの数、大量の情報を処理できないこと、不正アクセスのレベルが低いこと。
その他: PC はローカル ネットワークに統合されているため、統合されたデータ ファイルが作成されます (多くの情報の無駄が回避されます)。
3 番目: ローカル ネットワークに統合された PC。その中には特殊なサーバーが含まれます (「クライアント/サーバー」モード)。
これらの基盤の処理方法を、対策前に含まれるさまざまな EOM 間の処理機能の細分化に分割します。 この方法は 2 つの方法で実装できます。 1 つ目は、EOM インストールをネットワークのスキン ノード (またはシステムのスキン レベル) に転送します。そこでは、実際の機能に従って 1 つまたは複数の EOM ノードでデータ処理が行われます。それが現時点で必要とされているものです。 もう 1 つの方法は、1 つのシステムの中央に多数の異なるプロセッサを配置することです。 このようなパスは、ある程度のデータ処理が必要な銀行および財務情報を処理するシステム (支店、支店など) に見られます。 分割法の利点: 指定されたデータから任意の項を取得できること。 ある技術的特徴が特定された場合、それを別の技術的特徴に即座に置き換えることができるという事実による、高いレベルの信頼性。 貢物の移送に必要な時間が短い。 システムの柔軟性の向上、ソフトウェアの開発と運用の簡素化など。 したがって、分割方式は特殊なプロセッサの複合体にあります。 EOM のスキンは、最高位の歌唱コマンドとそのピアのコマンドに割り当てられます。
データ処理の高度な方法は統合です。 作成したセラミックオブジェクトの情報モデルを転送し、分散データベースを作成します。 この方法により、オペレータの利便性が最大限に高まります。 一方で、データベースは集団ガバナンスと集中管理に移行されます。 一方、情報を取得する目的では、関与するタスクが多様であるため、データベースのさまざまな部分が必要になります。 統合情報処理技術は、EOMに一度入力された単一の情報配列に基づいて処理が行われるため、処理の精度、信頼性、流動性を向上させることができます。 この方法の特徴は、データの収集、準備、入力の手順から技術的に分離されており、時間のかかる処理手順であることです。
現在の情報処理システムは、紙データや自動化されたワークステーション技術間でデータを交換するデジタル技術に依存しており、スピブロビットグループの共同部隊の統合も可能にしている。 )、リアルタイムモードでいつでも交渉中の意見交換(電話会議)、電子メール、電子メールボックスなどによる迅速な資料交換。 このようなシステムについては、「企業業務プロセス管理システム」という用語を拡張して、業務全体をサポートする必要があります。 このようなシステムは、グローバル インターネット ネットワークを介したリモート クライアントの接続など、「クライアント/サーバー」テクノロジの使用を特徴としています。 さまざまな国や大陸にある 40,000 を超えるクライアントをシステムがグローバルな情報空間に統合することは、珍しいことではありません。 そのようなアプリケーションの 1 つとして、ウクライナを含む世界中に支店を展開するマクドナルド社が考えられます。
デジタル情報の処理
実際、あらゆる工学装置はエネルギーの変換または情報の変換に依存しています。 最も重要な意味での制御システムのタスクは、ロボット オブジェクトのフロー モードを指定された値に近づけるために、ロボット オブジェクトのフロー モードに関する情報を処理し、制御される信号に基づいて選択することです。 1つ。 情報を処理するときは、システムのステータスを均等にするために、何らかの方法で決定を尊重することが常に必要です。電子デバイスには、アナログとデジタルという 2 つの主な情報処理方法があります。
アナログ方式の情報処理の基本的な特徴は、システムの変化に対応して電気信号の値を滑らかに変化させる能力です。 すべての変換は実際的な方法で実行されます。
情報をデジタル処理する場合、スキン変数値には、システム内のデータ型にデジタル コードが割り当てられます。 システム内の関数は、基礎となるプログラムの背後でこれらおよびその他の数値的手法を使用するシステムの最高レベルによって実装されます。 このソリューションを実装するデバイスはプロセッサと呼ばれます。
デジタル制御システムの重要な機能は、レベルの背後にある信号のサンプリングであり、その値は計算のビット深度によって決まります。 したがって、8ビットシステムの場合、信号の値が変化する全範囲を256個の区間に分割し、その256個の値のうちの1つだけで、どの信号に対応するデジタルコードを受信することができる。 これにより、デジタル制御システムの精度が損なわれる可能性があります。 長い間、高精度システムはアナログな情報処理方法に依存し続けてきました (場合によっては引き続き)。 徹底した分析を行ってみましょう。 アナログ システムでは、振幅に情報が含まれるアクティブ信号は 0 ~ 10 V の間で変化します。ノイズのレベルは 1 mV を超えません。 ノイズの流入を排除して情報を確実に送信するには、信号の最小増加は少なくとも 1 mV である必要があります。
このような大量の情報をデジタル コードで送信するには、少なくとも 14 2 桁のビット深度が必要です。 また、容量が低いデジタル システムでもアナログ システムの精度と同等の精度を得ることができます。 ただし、明らかな容量のため、14 ビットを超えるデジタル システムは故障するだけでなく、フラグメントのアナログ精度を超えてしまう可能性があり、そのパラメータは時間の経過とともに変化せず、温度、湿度などの外部要因によっても変化しません。これは素晴らしい段階にあり、ほぼすべてのアナログシステムに強力です。
特に現時点では、過剰再保険の影響で、ほぼすべての活動分野でマイクロプロセッサ技術が大規模に導入されていますが、つい昨日までアナログな情報処理方法は衰退していました。
今日の最新テクノロジーでは、マイクロコントローラーは、特殊な周辺機器を実装するための送信機の直接制御の役割だけでなく、デジタルコントローラー、保護システム、診断システム、および技術ネットワークに接続されたシステムの役割も果たしています。最高レベル。
同時に、伝送スイッチの管理に特化したマイクロコントローラーも不足しています。 Їх 計算コア、pobudovane、zazvichay、z urahuvannyam t.zv。 「デジタル信号処理プロセッサ」、一連の再帰多項式デジタル制御アルゴリズムが採用されています。 含まれる周辺デバイスには、マルチチャネル PWM 信号発生器、アナログ - デジタル コンバータ、ベクトル座標変換ユニット、トリートメント タイマー、ウォッチドッグ タイマーなどが含まれます。 このようなデバイスの例には、Analog Devices の ADMC330 マイクロコントローラ、Texas Instruments の TMS320C240、Motorola の 56800、Analog Devices の ADMC200 ベクトル プロセッサなどがあります。
最初のプロセッサは、ソフトウェア機能デバイスとして、算術演算と論理演算を実行できるだけでなく、以前の計算結果に基づいてその機能のアルゴリズムを調整することができ、今世紀の 40 年代に米国で作成されました。 IBMの代表者による。 これは電気機械リレー上のデバイスであり、多数の表面を占有し、速度と信頼性が非常に低く、非常に高度なクラスの特定の計算にのみ適しています。 電子技術の進歩に伴い、日常的に使用されるプロセッサの基本的な基盤は改善されました。 電子管、トランジスタ、および小さな集積段の個別論理マイクロ回路に基づくプロセッサが登場しました。 世界で最も洗練されたプロセッサはますます小型化し、消費電力が減少し、生産性と信頼性が低下しています。 しかし、その悪臭は依然として現実の管理業務とはあまり関係がなく、主に経理部門の歌の授業でのみ使用されていました。
コンピューティング技術における真の革命は、いわゆる最初のものが登場した後に起こりました。 つまり「マイクロプロセッサ」です。 一見 1 つの高段集積マイクロ回路を備えたプロセッサ。 これは INTEL の 4 ビット マイクロプロセッサ 4004 です。 1973年生まれ INTEL は 8 ビット マイクロプロセッサ 8080 を 1978 年に生産しました。 - 16 ビット マイクロプロセッサ 8086、チップ上には 29,000 個のトランジスタがあり、コストは 360 ドルです。 マイクロプロセッサの進化は常にゆっくりですが、1993 年に市場に投入されてから加速しています。 マイクロプロセッサ INTEL Pentium MAV はすでに 3.2 です。 チップ上に100万個のトランジスタを搭載し、価格は878ドル。 マイクロプロセッサの進化の主な方向性は、急速に変化する計算能力の向上と時間ごとの計算の変化です (そして、現在も)。
デジタル情報を処理し、処理プロセスを制御するために使用されるマイクロプロセッサ ソフトウェア コーディング デバイス。電子要素を高度に統合した 1 つ (または複数) の集積回路の形式で処理します。
マイクロプロセッサの性能の変化、重量と全体の寸法の削減、信頼性と生産性の向上により、マイクロプロセッサの開発範囲は大幅に拡大しました。 従来の計算システムに加えて、管理業務において悪臭がますます顕著になってきています。 マイクロプロセッサの前には、さまざまな周辺オブジェクトをソフトウェアで制御するタスクが割り当てられました。
情報処理管理
情報システムは、技術的な制限があってもなくても機能します。 価格も経済的です。 組織の管理システムにおける情報プロセスの自動化の段階を手動、自動、および自動化に分類することが重要です。手動インテリジェンスは、情報を処理し、人間によるすべての操作を変換するための最新の技術的手法の存在によって特徴付けられます。 たとえば、毎日コンピュータを使用する会社の管理者の活動については、マニュアル IV を使用して作業していると言えます。
自動化された IV は、人間の介入なしに情報を処理するためのすべての操作を排除します。
自動化システムには、情報処理において人間と技術の両方のプロセスが関与し、コンピューターが主導的な役割を果たします。 現在の「情報システム」という用語には、システムの強制的な自動化も含まれます。 自動保険システムは、制御プロセスの組織化に広く使用されており、さまざまな変更が可能であり、たとえば、停滞の分野で提供される情報の性質などを分類できます。
組織の情報システムにおける情報の必要性が増大し、より高速かつ効率的な処理方法の必要性により、情報システムの作業を自動化して情報処理を自動化する必要が生じています。
非自動化された情報システムでは、情報に関連するすべてのアクションは人間によって決定されます。 情報処理プロセスの自動化は、処理アルゴリズム内の一般的なルールの出現につながり、純粋な情報システムが情報管理システムに発展する可能性があります。 残りの部分的に実装された機能の枠組み内で、人々はすぐに決定を下すでしょう。
組織を管理するための自動化された情報システム - データ、所有権、ソフトウェア、人員、手順の標準、収集、処理、配布、保存、および生成 (データ) の目的の全体が相互に関連しています。組織の目標。 通常、このシステムは、コンピュータ情報技術をサポートする情報製品の開発と、コンピュータや電気通信を扱う人材をサポートします。 コンピュータ化された情報システムにおける作業の技術は、ファシストにとっては理解できるかもしれない。 このシステムは、顧客の情報ニーズを満たし、経営上の意思決定を行うための経済的な施設の動的な情報モデルをサポートします。
自動化された IS を有効にして、フロントデスク担当者向けの自動化されたワークステーション (AWS)、通信方法、および情報交換を有効にします。 これらすべてにより、ロボットを効果的に自動化できます。 経済対象(企業、銀行、業界団体、政府機関など)の管理における IV の使用の有効性を念頭に置き、管理ソリューションを迅速に準備し、変更が発生する前に適応させる必要があります。特派員の。
情報技術は、情報プロセス (情報の収集、処理、蓄積、保管、検索、配布) を確実に実行するためのインフラストラクチャです。 IT は、情報リソースを取得するプロセスの複雑さを軽減し、信頼性と効率を高めることを目的としています。 IT ウェアハウスには、ハードウェアとソフトウェア、データ、通信が含まれます。
機能サブシステムは、IT に基づいてデータを準備し、特定の機能領域に関する意思決定を行うための情報の処理と分析を確実に行うように設計された特殊なプログラムです。 機能サブシステムとアドオンの範囲には、生産、会計、財務、人事、マーケティング、生産が含まれます。
IV 管理は、ライフサイクル全体を通じて、IT、機能サブシステム、関連ファシリエイトと IV 開発の間の最適な対話を保証するコンポーネントです。 ІВは、人事、会計、運営、財務、セキュリティ、ヤクスト、開発の管理に携わっています。
皮膚は自動化されており、甲状腺の必須機能の実現を目指しています。
経済情報システム (EIS) は、経済対象のさまざまなレベルの管理のためのデータと情報の処理に関連付けられています。 この情報により、効果的な管理上の意思決定を行うために、計画、制御、分析、計画および規制の機能を実行できるようになります。 EIS の政府レベルは、州、地方、地方自治体に分かれています。 EISは管理対象に応じて産業用と非産業用に分けられます。
意思決定支援システム (DSS) は、歌っている時間全体にわたるオブジェクトの完全性や行動の結果を反映するデータの分析に基づいて、可能な行動オプションの学習、予測、開発、評価の可能性を保証する分析インテリジェンスです。 DSS は、知られる前に人々に受け入れられ、意思決定が行われる情報を生成します。
DSS は、意思決定や意思決定に関連する複雑で構造が弱い状況において、管理者による意思決定プロセスをサポートするために開発されたシステムです。 DSS の開発は、情報技術、閉鎖通信ネットワーク、パーソナル コンピューター、動的スプレッドシート、エキスパート システムの敵対的な進歩によって強い影響を受けてきました。
戦略的管理のレベルでは、長期、中期、短期、および設備投資の分割システムを含む財務計画の低 DSS が開発されます。 運用管理指向の DSS は、マーケティング (予測と分析、市場監視と価格)、科学調査と設計作業、および人事管理に関与しています。 業務と情報の停滞は、在庫の生産、取得、量、物流、会計形態に関連しています。
ビジネス情報システム (BIS) は、ネットワーク化されたデスクトップに基づいてビジネス上の意思決定をサポートするために、オンラインで信頼できる情報をトップ マネージャーに提供するように設計されたコンピュータ化されたシステムです。 最高レベルの最新カーネルの一貫した形式と指示でサウンドの準備を確実に行うための手段的な方法があります。 それらは、世界の準備と開始する能力を明確に示しています。 VIS は、科学者が重要な情報を分析し、組織内で戦略的意思決定を行うよう指示するためのさまざまなツールを特定するのに役立つ特殊な DSS として分類されます。 したがって、BIS は、ウィコナビア人が組織の運営、競合他社、従業員、従業員のより正確かつ最新の状況を把握できるように支援します。
BIS の専門分野は、内部および外部の現在の傾向を監視することです。 より多くの情報とツールが利用できるようになり、上級管理者は組織の能力を向上させ、問題を軽減するために戦略的変更を行う準備が整います。 VIS は競争力があり、戦略計画に役立ちます。 市場で作成されるソリューションの充実度を高めます。 問題を特定するのに時間がかかりました。 組織管理の上層部における計画のレベルを向上させる。 組織内の管理を改善し、データとモデルへのアクセスを増やすためのメカニズムを提供します。
BIS フラグメントは、上位レベルの管理と戦略的代替案の検討を目的としており、システムは管理プロセスや下位レベルの DSS に適合させることができます。 さらに、販売業者は、最高品質のケアを提供するビコリスタン システムを実現するための取り組みを開発するための創造的なアプローチを担当します。 BIS の設計により、DSS、医療ソリューション、および医師の種類がより詳細に、より低レベルで開発される可能性があります。
情報および聴取システムは、複雑なデータ処理を行わずに、情報の入力、体系化、保存、およびユーザーへの配信を可能にします。
情報コンピューティング システムは、特定のアルゴリズムに従って情報処理のすべての操作を実行します。 その中で、生成された出力情報を意思決定プロセスに注入することで段階的に分類を実行し、役に立つ情報と喜ばれる情報の 2 つのクラスを確認することができます。
慎重な情報は情報を生み出し、それに基づいて人々は意思決定を行います。 これらのシステムは、rozrakhunkovy キャラクターのタスクの種類とデータの大きな義務の処理によって特徴付けられます。
ІС、頭に浮かぶ前に人々に受け入れられ、必然的に一連の具体的な行動にならない情報を生成するのは良いことです。 それらは知識の蓄積によって特徴付けられますが、知識によってではありません。 これらのシステムは、rozrakhunkovy キャラクターのタスクの種類とデータの大きな義務の処理によって特徴付けられます。
上記のすべてのカテゴリに加えて、情報システムも統合されており、経済的な施設を運用するためのすべての制御機能 (システムの運用を分析する前の科学研究、設計、生産、リリース、実装など) を自動化するように設計されています。
自動情報処理
自動化された情報処理により、さまざまな更新情報、情報、特別な専門的特性、サービスの動きに関する情報などを記録モードで (リアルタイムで) 迅速に処理できます。より高いレベルに引き上げられました。基本機能の形での情報の自動処理により、ファイリング キャビネットの手動ファイリングの必要性が変化し、会計担当者は手動操作の必要性や基本機能の変更、減価償却の内訳や償却費の内訳の変更から解放されます。手動の会計記録やその他のフォームの作成。
作成された合成データに関する情報の自動処理は、会計システム内のすべてのデータの自動処理に基本的な考え方を移します。 このビジネスの情報処理は特殊です。 情報の自動処理はロボット通信チャネルの中核にまで進み、送信速度と信頼性を示します。 在庫の形での自動情報処理の必要性により、大量の文書を迅速に処理する必要があります。
信頼性に関する情報を自動処理するために、主要な形式のデータが自動処理構造に分割された障害データの特別なマップに転送されます。
自動化された情報処理の場合、臭いは消えないかもしれませんが、グラフィック テキストは短くて快適です。
p align="justify"> 自動情報処理の技術プロセスには、元の文書の記入、文書からコンピューターへのデータの転送、EOM 上の情報の処理の段階が含まれます。 このような情報処理の過程においては、技術的手法の信頼性の欠如や人間の操作者の過失による許容が行われます。 自動情報処理のメタシステムは、保存および処理された出力情報を操作して、意思決定に現在必要な情報を分離します。
情報処理の自動化を確実にするために、一次または二次コンバータを使用して出力電圧信号を提供します。 これらには、誘導式、変圧器、旋風式、メカノトロニック、ニューモトロニック、ラスター、光電、およびその他のタイプのコンバーターが含まれます。
自動化された情報処理を設計する場合、要素をプラグマティック、セマンティック、シンタックスという 3 つの主要な側面に統合することが重要です。
自動情報処理システム (AIP) を効果的に機能させて日常生活の安全を確保することは、信頼できる数学的セキュリティがなければ事実上不可能です。 SAO の数学的安全性とは、社会学的、社会経済的、工学的、技術的、衛生的および衛生的データ、およびその他のデータ (作業中の指標、労働の保護、生産性、職業病およびウイルス傷害、それらの評価は、生産の効率、作業の生産性、および指定された方法を実装するその他のプログラムに影響を与えます。
自動化された情報処理の重要性の増大と情報フローの増大により、情報を保存する根本的に新しい方法や方法の探求が絶えず刺激されています。
以下に、このソフトウェア複合体のアプリケーションによる支払いの形での自動情報処理の技術を示します。
新しい情報の自動処理に基づくシステムのすべてのリストは、システムのライフサイクルの段階、つまり設計前の科学的作業と最終的な作業、設計、作成、機能の段階における意思決定方法の分解にすぎません。 フェーズは 1 時間以内のシステム寿命のプロセスを区切るため、システムをプロセスの時間ごとの異なるフェーズに分割できます。 システム的アプローチの原理では、クロック位相の外側を単独で見ることはできません。 いつの段階でも、大規模な決定が称賛されるという遺産は、この段階だけでなく、いつでも見られるはずです。 たとえば、家族の誕生を計画する段階での重大な漏れは、初期段階で修正することが不可能であるため、重要です。
自動情報処理を導入する企業では、データの収集と検証、さまざまな種類の分類器や暗号化器の編集と運用に多くの人員が必要です。 高度な自動制御システムで大きな成果を上げている工場では、その数は50以上に達していると言えます。 情報を管理および処理するための自動化システムの作成。 自動情報処理への産業的アプローチは、その価格が卸売価格であることを意味します。 私たちは、重要な情報に先立って、絶対に必要な費用に近い何らかの収集や処理に個別の費用を費やす必要があります。 分析情報の一定の力が増大し、成形プロセスが個別の性質を持ち、コストが高くなる前に、価格設定には一貫したアプローチが必要になります。 同じ価格で、この情報の時間に敏感な側面も反映されています。これは、バッチ モードでの処理は簡単ですが、ダイアログ モードよりも安価であるためです。
組織が情報処理を自動化している状態にある場合は、各行の隣にある特別に指定されたフィールドに追加コードを入力できます。 コーディング システムは組織自体によって断片化されるか、ソフトウェアに転送される必要があります。
自動情報処理システムの開発と実装には、技術仕様の作成が含まれます。 システムの最初の部分の代わりに、倉庫は自動化に最も適しており、企業の経営上の意思決定を行う上で非常に重要な設計、分析、計画、運用管理に割り当てられます。 システムの運用面を開発する過程で、機能タスクの出力複合体、情報と数学的セキュリティの拡張と統合、および技術的機能の複合体の最新化が増加します。 EIS の初稿が作成されると、技術仕様はシステム全体に分割され、技術プロジェクトと運用プロジェクトは、システムの初稿が保存される前に含まれる運用システムとサブシステムに分割されます。
このセクションでは、FGS 接続のトポロジ構造を担う自動情報処理の原理を考察します。 リンク図の意味、情報密度、および構造的組織化により、リンク図をシステムの数学的記述の他の同等の形式に変換するための、(デジタル コンピュータ上での実装を伴う) 即時効果的な正式な手順の可能性が保証されます。 この部門は、FGS のレベルまで標準形式で表示される、運用上の原因と継承ラインを結び付ける図で自動化された分割手順をレビューし、モデル化する FHS アルゴリズム、プロジェクトについて折り畳まれた信号グラフ、および動的なデータを表示するための伝達関数を促します。線形システムの動作。
自動情報処理の発展における輝かしい発展は、通信チャネルによって接続された大小の電子計算機の不在である EOM 対策の出現を示しています。 EOM ネットワークを介して多数の加入者ポイントに接続すると、ネットワークに含まれる EOM のメモリに保存されているさまざまな情報にユーザーが集合的にアクセスできるようになります。
自動情報処理下でコードを手動で入力する。 手動で会計を行う場合は、コードを設定する必要はありません。
自動情報処理に関与する従業員の数は、特別な方法を使用して決定されます。
情報システムでは情報処理が自動化されているため、技術的セキュリティには電子計算技術とそれらの間の通信方法が含まれます。 技術的セキュリティの主要部分は EOM です。 現代の大企業は、あらゆる技術的な情報処理技術と新しいテクノロジーおよび情報処理方法論を組み合わせた、複雑で自動化された情報処理を開発しています。 複雑な自動化システムの作成は、いくつかの段階で行われます。
IVO 企業の主な活動プロファイルは、追加の EOM を使用した情報の自動処理と、情報を効果的に処理するための情報、ソフトウェア、技術的および技術的環境の作成であり、これは結果の形式化です。
自動化された情報処理の機能を定義する手順。 組織はすでに自動情報処理のサービスになっているため、多くの場合、タスクの開発は専門家自身が任されます。 したがって、このプロセスを通じて、専門家のチームが作成されます。 プロジェクトに配属される場合があります。 チームのメンバーは、自動化の実装に参加したファシストから選ばれる可能性があります。 したがって、この場合、サービスを提供する企業を支援する場合、自動化管理をサポートするコンサルタントを 1 人または複数人雇うことが重要です。 医療専門家(解体される任務に関連する可能性のある組織のサブセクションと専門家チーム)の間で働く医師はしばしば緊張を抱えており、専門家の選択には儀式を遂行する責任がある。自動情報処理のためのサービス、および組織のデータベースを維持する目的のサービス。
計算センターは現在、保険業務における保険情報の自動処理プログラムを開発および実装しています。 保険会社のすべての構造部分とのやり取り。 保険請求、保険会社のカテゴリ、およびその他のグループの電子データベースを形成します。 保険会社の中央オフィスおよび支店内に、中央コンピューターに接続された閉じた電子システムを構築します。 他のローカル コンピュータ ネットワークの作成に取り組んでいます。 自動制御システムによる自動情報処理のための河川運営費のコストをどのように決定するか。
独立したバランスにあるロボット情報コンピューティングセンターの頭の中で、情報処理は州政府サービスの順序で自動化され、EOM 機械年と拡張の実行時間の利用可能性に基づいて割り当てられます。 。 自動情報処理の記号論的問題 – 以下に特化した出版資料。コンピュータ システムの構文力と意味論力の間の関連問題の探求。 知識に関連した自然科学および形式化された科学技術の研究、情報の保存と検索。 機械によるテキストのインデックス作成、抽象化、翻訳のための実用的なシステムを作成することにより、自動テキスト処理を提供します。 研究によると、Galusa はテキストを機械処理するための特別なプログラムとそれからの翻訳プログラムを作成しました。
現在のコンピューティング技術の機能は、ナフサ鉱床の開発中に情報を自動処理するために開発されていると考えられています。 地質学的および産業情報を処理するために検討された方法の有効性は、ウラル・ヴォルガ地域と西シベリアの裕福な氏族の発展で示されています。
残りの年間では、EOM 上の情報の自動処理にコンピューター グラフィックスが広く使用されています。 何百もの科学論文がコンピュータグラフィックスで発表され、会議、国際会議、展示会が体系的に開催されています。
EOM 上でクラウド情報を処理する際、情報の自動処理では、その非常に困難なため制御の治療法が停滞します。原則として、最初の文書からマシンへの転送の正確性を検証することは困難です。現金展示品。 他の指標はソフトウェア制御方法を使用して EOM 上で検証され、文書の詳細の論理検証を保証できます。 論理検証により、多くの場合、特に元の文書に記入されている場合にエラーを特定することができます。 これらの一次文書の機械媒体への転送を監視する他の方法は、その有効性を保証するために確立されるであろう。
賃金や給与の情報を自動処理する過程で保持される出力マシンの 3 番目のグループまでは、分析レジスタなどのさまざまな種類のデータシートが含まれており、これらのイベントの合計の外観と詳細は次のとおりです。計画され、解決されました。 部門記録の情報は追加の処理を必要とせず、付随ファイルに保存され、支払われた賃金やその他の種類の支払いに関するデータの一部として削除されます。 事前ビデオレポートのいくつかを見てみましょう。
サブシステムが完全に稼働すると、数学的手法とコンピューティング技術の手法に基づいて、自動化された情報処理と直接計画された支出の手法が使用され、周辺地域での消費を推定します。主な方向性のための材料と技術リソースの種類ガラス瓶と資金排出装置のセクションでの開発、自然および廃棄物収支機械製品の折り畳み、材料および技術的リソースの分割計画の作成と検証、およびファンドマネージャー向けのステートメントの編集。 制御システム技術者は、機械処理の前に情報を準備し、作業から結果として得られる情報を取得するための手順を備え、自動化された情報処理の基本概念に精通している必要があります。 CE 所有権の信頼性に関する情報の自動処理を組織化する実現可能性と原則を示す例として、発電機の信頼性に関する情報を生成するために重要な電気機械で機能する ASNI 信頼性について以下に検討します。 バルクコンピュータセンターのvykoristannyaサービスの頭の中では、情報の自動処理のための支出は、EOMロボットの1機械年の性能指標に基づいて実行されます。 現金会計センターへの補助サービスの場合、情報の自動処理のコストは、EOM ロボットの 1 機械年コストに基づいています。
このアドバイザーは、自動化された情報処理、設計、科学技術実験の自動化、生産管理などのシステムを開発する幅広い科学者だけでなく、学生や大学院生にも役立ちます。 明らかに、コンピューター サイエンスには、自動化された情報処理以外にも多くの機能があります。
その結果 (組織がすでに自動化された情報処理を導入しているという事実に関係なく)、組織は自動化計画に沿った自動化された情報処理のポリシーを策定する必要があります。 残りの部分は、組織の高度な管理方針の規制だけでなく、手動手順によって義務を削除する際に管理装置が直面する具体的な困難に基づいて策定される可能性があります。
操作の完全性、処理の複雑さ、および情報の自動処理のさまざまな結果に基づいて、自動制御システムは情報 (または情報ベース)、情報に基づいたもの、および丁寧に分類されます。
データベースの概念は、長い間、効果的な自動情報処理システムの作成の主な推進力でした。 しかし、残りの時間では、ファシストたちは、この概念の最も重要な要素はデータベースを設計するための統一された方法論であるという結論に達しました。 これは、新しいデータベースの設計が困難で労働集約的なプロセスであり、高度な資格を持つ会計士の獲得が必要であるという事実だけでなく、情報モデルであるため、現実世界の多くの部分では常に部品が使用されるためでも説明されます。アクションを適切に反映するには、データベースも変更する必要があります。 したがって、情報システムをサポートおよび運用するには、一貫したデータベース設計手順が必要です。 当然のことながら、データベース設計に自動化システムを使用すると、情報システムの開発コストが変化し、日常的で非創造的な作業 (出力データの収集と編集に関連する) の短縮、およびアプリケーション システムの開発コストの短縮につながる可能性があります。 。 現在、ナフサ産業では、ナフサ生産におけるあらゆる種類の生産に関する効率の大幅な向上を確実にするために、従来の制御システムと組み合わせた効率的な自動情報処理、制御、および通信が非常に必要とされています。
アプリケーション登録カードの詳細の登録倉庫により、自動情報処理の時間内で合理的に検索手順を実行できます。
加速度的に、手用の紙、自動情報処理用の紙、包装用の紙とボール紙、およびグラブや工業製品の包装用の紙と段ボールの生産と販売促進を開発します。 紙や段ボールなどの古紙回収をさらに拡大します。
情報処理方法
IT の主な目的の 1 つは、管理者が経営上の意思決定を行うための情報を収集、処理、提供することです。経済情報を処理するこの方法に関連して、経営上の意思決定を行うプロセスのライフサイクルの段階を確認するのは簡単です。
1) 問題の診断、
2) 代替案の特定(生成)、
3) 決定の選択、
4) 決定の実施。
問題の診断段階で使用される方法により、信頼性の高い最新の説明が保証されます。 当社のウェアハウスには、調整、要因分析、モデリング (経済数学的手法、大量サービス理論の手法、在庫理論、経済分析)、および予測 (正確かつ個別の手法) の手法が含まれています。 これらすべての方法には、情報の収集、保存、処理、分析、最も重要な側面の記録が含まれます。 一連の方法は、問題の性質と場所、策定段階で発生する条件とコストによって異なります。
代替案を開発(生成)する段階では、情報を収集する方法も開発されていますが、それは第 1 段階と同時に、「何が起こったのか?」などの質問に対する回答の検索に影響します。 そして、「理由は何ですか?」という質問で、管理上のアクションを利用して問題を解決する方法を学びます。
代替案(目標を達成するための管理行動の方法)を開発するときは、個人と集団の両方の問題解決方法を選択してください。 個々の方法は時間当たりの投資が最も少ないという特徴がありますが、ソリューションは最適です。 代替案を生成するときは、直感的なアプローチと論理的 (合理的) な問題解決方法を使用してください。 意思決定者 (DM) を支援するために、現在の問題に関する専門家が集められ、代替案の開発に参加します。 集団的な問題は、脳攻撃/暴行モデル、Delphi、および名目上のグループテクノロジーから発生します。
脳発作中は自由形式のディスカッションが行われますが、これは 4 ~ 10 人の参加者からなるグループで行うことが重要です。 自分自身に対する脳攻撃も可能です。
参加者間の差異が大きければ大きいほど、(証拠、気質、作業領域の違いにより)より良い結果が得られます。
参加者は、この方法に関する大規模または面倒な準備や知識を必要としません。 ただし、さまざまなアイデアが飛び交っており、参加者やグループ全体がこの方法の原則と基本的なルールをどの程度認識しているかを示すには 1 時間かかります。 参加者が分析分野の知識と証拠を持っていることは間違いありません。 脳発作の枠組み内でのセッションの期間は、数日から数年の間で選択できますが、通常、セッションの期間は 20 ~ 30 分です。
小グループでの脳攻撃の好ましい方法では、2 つの原則を厳密に遵守する必要があります。1 つはアイデアの評価を避けること (ここでは多くのことが辛辣なものになります)、そして 4 つの基本ルールを遵守することです。- 批判は無視し、より強いつながりを持ちます。量に関する限り、理解と改善が求められています。
意思決定の選択は、重要性、リスク、重要性を念頭に置いて行われます。 これら中間段階の違いは、さまざまな情報、問題の本質に関する意思決定者の知識レベル、意思決定プロセスの考え方によって示されます。
意思決定者が選択に割り当てられたスキンの代替案の結果 (出力) を後で決定できる場合は、心が意思決定を行う (問題の本質に気づく) ことが重要です。 これは、機知に富んだ短い解決策の場合に当てはまります。 そして、ここでは意思決定者が独自に注文した報告情報を持っていることになります。 状況に関する包括的な知識があり、その決定を賞賛することができます。
精神的リスクは、意思決定者が真皮代替品の導入によって起こり得る結果の信頼性を認識している場合、問題の本質に関するそのような知識状態によって決定されます。 危機と無意味さの心は、外部環境の現在の状況についての、いわゆる非常に重要な認識の心によって特徴付けられます。 この場合、意思決定者は要因とその結果への影響を正確に特定せずに代替案を選択する可能性があります。 心の中で、皮膚の代替の結果は心の機能、つまりドブキルの役人(粗さの機能)であり、それが意思決定者の伝達の最初のステップです。 代替戦略の選択結果を分析するために、支払いマトリックスとも呼ばれる決定マトリックスが作成されます。
取るに足らない心とは、皮膚の代替品が多くの結果を生み出す可能性があり、これらの遺伝の犯人の確実性が不明である場合、過度の中流階級(現象の本質の知識)の状態です。 中間の重要性は、情報の数と信頼性の関係にあると判断されました。 外部の精度は重要ではないため、効果的な決定を下すことがより重要です。 ミドルもダイナミクスのレベルやミドルの緩みなどに合わせてライを決めていきます。 予想される変化のスピードが決断につながります。 つまり、組織の発展によって考え方が変わることもあります。 それに加えて、更新前に生じた新たな問題や、組織によって規制される可能性のある新しい役人の流入によって、新たな問題に直面する可能性も加わります。 したがって、取るに足らない心に対する最善の解決策の選択は、この取るに足らないものの段階であるこれに基づいて行われなければなりません。 さらに、情報は意思決定者によって提供されます。 このような選択は、考えられる心の選択肢の数が不明である場合でも、行動の結果を評価するためのアプローチの原則を確立するために、次の 4 つの基準の選択を保証します: 最大の Wald 基準、Savage 基準を使用したミニマックス、Hurwitz 基準悲観主義と楽観主義の場合、ラプラス基準またはベイズ基準。
決定を実行する場合、決定の実行を計画、整理、監視する方法を確立する必要があります。 決定を実行するための計画の順序は、誰に、どのように、どこで働くかという主要な栄養源に移されます。 この栄養の証拠は文書化される可能性があります。
経営上の意思決定の実施計画との一貫性を確保する主な方法は、特定の義務を適度にモデル化することです。 エッジ モデリングの主なツールは、カレンダー スケールのグリッドからの接続のエッジ グラフであるエッジ マトリックスです。
意思決定を組織化する方法には、意思決定を実行するための情報テーブルを作成する方法 (ITPP) と、注入と動機付けの方法が含まれます。
財務上の意思決定を管理する方法は、中間および最終結果の監視と、金融システムの条件(ITRR での運用)の監視に分けられます。 コントロールの主な目的は、最終決定を保証する確立されたシステム、つまり決定を可能な限り最大限に保証するシステムにあります。
情報処理技術
情報プロセス中、企業または組織内で流通する情報は、その活動の一環として何らかの処理の対象となります。 舞台裏では、入力と出力、内部情報と外部情報を確認できます。 処理のプロセスでは、情報は一次と二次、中間と結果として存在し、その間にデータがあるタイプから別のタイプに変換されます。 情報技術の発展に伴い、データ処理にかかる作業量は増大し、高度な技術の使用が必要となります。テクノロジー(gr. techne - 熟練、ロゴス - 知識、熟練に関する知識) - 製造されるオブジェクトに必要な明確な変化が存在する、製造プロセスの方法と特徴に関する知識の全体。
情報技術は、情報を収集、処理、送信するための技術と方法の組み合わせを使用して、オブジェクト、プロセス、またはデバイスに関する新しい情報を収集するプロセスです。 同様の意味がアートでも与えられています。 連邦法第 149-FZ 号「情報、情報技術および情報保護について」の 2: 情報技術 - データの検索、収集、保存、処理、情報の拡張のプロセス、方法、およびそのようなプロセスおよび方法を開発する方法。
メタ情報技術は、人間による分析とあらゆる行動の意思決定のための情報の収集です。 一般に、情報技術とは、コンピューター上の情報処理による人々の明らかに意味のある一連の行為です。 情報を処理する技術的プロセスは、データ処理をもたらす段階、操作、およびオペレーターの特定のアクションで構成されます。
データに基づいて可能な操作の構造は次のように名付けられます。
データの収集と形式化です。 新しい形に縮小されました。
濾過と選別。
与えられたタスクに従ってデータを処理および変換する。
次に、データのアーカイブです。 データストレージをコンパクトで使いやすく、簡単にアクセスできる形式に整理します。
データ保護 - データの損失とその変更を防ぐことを目的とした複合的なアプローチ。
データの転送、tobto。 情報プロセスにおける遠隔参加者間のデータの送受信。
情報技術の発展の歴史には、情報処理分野の根本的な変化に関連した多くの段階が含まれます。
文字の発達とのつながりの最初の段階。 ここでの情報の収集、保存、処理の手段はペン、インク、紙、本であり、この段階での情報処理の効率は極めて低かった。 16世紀半ばの友好関係のヴィナキッド。 ダイヤルボードやDrukarsky verstatなどの情報処理の効率が大幅に向上しました。
19 世紀末、「手作業」の技術は、情報の迅速な伝達を可能にする「機械」技術に取って代わられました。
20 世紀半ばまで、電動 Drukar マシン、テレビ塔、コピー機、テープレコーダーが開発されました。 「電気」情報技術の台頭につながりました。
XX世紀の後半から。 EOM、そしてパーソナルコンピュータの出現により、情報技術の発展における新たな段階、つまり「電子」技術が誕生しました。
電子計算機は、計算および情報タスクを増やすために情報を入力、表示、蓄積、処理、送信するための汎用デバイスです。 「コンピュータ」という用語は「EOM」という用語と同じ意味で使用されます。 EOM は電子機械であり、その断片は電子回路で構成されており、デジタル形式の情報の断片、有限計算、数値演算、および論理演算を人間の入力なしで処理する計算機械です。 デジタル形式でデータを表示することにより、コンピュータは汎用性やさまざまなタスクへの適合性などの機能を得ることができます。
1 つ目は、19 世紀に入力装置、記憶装置、プロセッサ、登録レター表示装置を備えた倉庫内の分析機械 (計算機) の設計でした。 チャールズ・ベイビージ。 そもそも、このような機械でソフトウェア処理をすることを思いつきました。 このアイデアのさらなる発展は、最初の電子計算機の導入によって継続されることが知られています。 EOM の機能は、数値を表現し、デバイスに制御プログラムを配置するための二重数値システムに基づいていました。 最初の EOM は米国と英国で開発され、ヨーロッパ大陸では最初の「小型電子医療機械」(MESM) がソ連で作成されました。
電子計算機は下位に分類されます。
収集される物理データには次のものが含まれます。
アナログ コンピューティング マシンは、ノンストップ (アナログ) 形式で提供される情報を処理するノンストップ動作です。 一見連続した系列で、あらゆる物理量 (ほとんどの場合は電圧) の値。
情報を離散形式 (デジタル) で処理するデジタル コンピューティング マシン。
ハイブリッド コンピューティング マシンは、アナログ コンピューティング マシンとデジタル コンピューティング マシンの利点を組み合わせ、折り畳み式スライド技術複合体の高度な制御に使用されます。
EOM の作成段階の背後には、20 世紀を通じて形成されたコンピューター技術の数世代にわたる発展を見ることができます。
第一世代には、1950 年代に製造された車両が含まれます。 電子管の配置で。 当時の医療機器は、MESM(小型電子医療機器)、BESM(大型電子医療機器)、「Strira」、「Ural」シリーズ、M-20に分かれていました。 最初の EOM の主な結果は、科学的および技術的開発の停止でした。
10 年後、個別導体デバイス (トランジスタ) に基づいた EOM が作成されました。 EOM の別の世代は、技術的および開発目的で停滞しました。
1970 年代に第 3 世代の自動車が登場しました。 そして、中小規模の集積レベル(1つのパッケージに数百、数千のトランジスタ)を備えた導体集積回路上に分離がありました。 この世代の EOM は、経済発展の管理と実施において停滞し始めています。
EOM の第 4 世代は 1980 年代に形になりました。 偉大な、そして超偉大な集積回路、つまりマイクロプロセッサー(クリスタルごとに数万から数百万のトランジスタ)の理解が必要です。 この世代の EOM の手法は、すでに情報の提示と管理における広範な発展でした。
したがって、EOM の作成は、効率的な知識処理システムを可能にする、並列動作する数十のマイクロプロセッサによって特徴付けられます。 この世代は、パーソナル コンピュータ、通信データ処理、コンピュータ ネットワークの停滞、データベース管理システムの広範な停滞、データ処理システムとデバイスのインテリジェントな動作の要素によって特徴付けられます。
大規模な並列処理とニューラル構造を備えた光電子 EOM の作成は、21 世紀初頭に遡ります。 次世代コンピュータでは、データ処理から知識処理への明確な移行が行われることが予想されます。
情報処理プロセス
情報処理は、タスクを解決するためのアルゴリズムと一致する順序付けと変換のプロセスです。情報の処理が完了すると、結果が必要な形式でエンド ユーザーに表示されます。 この操作は、最新の情報が入手可能になり次第実行されます。 情報の提示は、テキスト、表、グラフなどの追加の外部 EOM デバイスを使用して実行されます。
情報技術は情報技術の重要な基盤であり、情報の収集、保管、送信、処理も含まれます。 情報の収集と蓄積のプロセスが主流だった 19 世紀半ばまでは、情報技術の基礎はペン、インクつぼ、紙でした。 通信(コンタクト)は、パケットを転送(ディスパッチ)するルートを通じて行われました。 19 世紀末の「手動」情報技術は「機械」情報技術 (タイプライター、電話、電信など) に取って代わられ、これが情報処理技術の根本的な変化の基礎となりました。 情報を処理する前に保存および転送することから移行するには、さらに多くの労力が必要になります。 これは、私たちの世紀の残りの半年間に電子計算機などの情報技術が出現し、「コンピューター技術」が誕生したことで可能になりました。
古代ギリシャ人は、テクノロジー(テクネー - 熟達 + ロゴス - 知識)がスピーチの熟達(神秘)であることを尊重しました。 この概念の最大の意義は、結婚の産業化の過程で生まれました。
テクノロジーとは、形成される物体に明らかな変化を伴う製造プロセスを実行するための方法と方法に関する知識の総体です。
セラミックの力のプロセスの技術は、自然発生的なプロセスとは対照的に、秩序正しく組織化されています。 歴史的に、「テクノロジー」という用語は材料生産の分野で使用されてきました。 この文脈における情報技術は、この主題分野におけるコンピューティング技術のハードウェアおよびソフトウェアの技術の影響を受ける可能性があります。
情報技術とは、情報リソースを取得するためのプロセスの複雑さを軽減し、信頼性を向上させることによってフォーマットの収集、処理、保存、拡張、表示を確実にする技術装置に統合された一連の方法、生産プロセス、ソフトウェアおよび技術的特徴です。効率 。
情報テクノロジーは、次の主な機能によって特徴付けられます。
処理(プロセス)の主体(オブジェクト)がデータであること、 2.
2. プロセスの方法は情報の削除です。
3. このプロセスの方法には、ソフトウェア、ハードウェア、およびソフトウェアとハードウェアのコンピューティング システムが含まれます。
4. データ処理プロセスは、特定の主題領域に対応する操作に分割されます。
5. 管理されるプロセスへの入力の選択は、意思決定に関与する人々の責任です。
6. プロセスを最適化するための基準は、一般への情報配信の適時性、その信頼性、有効性、完全性です。
あらゆる種類のテクノロジーの中で、管理分野における情報テクノロジーは「ヒューマンファクター」に最大の恩恵をもたらし、労働者の仕事や身体的および精神的能力に代わって、労働者の資質に重要な貢献をします。社会貢献のレベル。
情報処理の分析
一次的な社会学的情報は削除され、保存、分析され、科学的に統合されます。 この目的のために、収集されたすべてのアンケート、アンケート、レポートカード、インタビューフォームは検証され、コード化され、プログラムに入力され、グループ化され、収集され、表、グラフ、図などに編集される必要があります。 つまり、実証データを分析・加工する手法を確立する必要がある。情報を処理する主な方法は、実証的調査中に収集されたデータに基づいています。
二次メソッドは、インジケーターを削除し、頻度とグループ化されたデータを決定するために使用されるメソッドです。
社会学的情報の 6 つの段階:
ステージ 1. 情報のコーディングと編集。 研究方法や社会学的情報を収集する他の方法によって取り除かれてしまった経験的データを形式化することが重要です。 アンケート情報の一部はすでに形式化されているため、考えられるすべての回答が提供され、対応するデジタル コードが入力されます。 ただし、ほとんどの場合、すでに収集されたプロファイルを編集するときに解決する必要がある問題が発生します。 さらに、収集されるもう 1 つのタイプのデータは、電源オン時の出力です。 したがって、第 1 段階の重要なタスクをグループ化したり、さらにコーディングしたりすることはありません。
ステージ 2. 社会学的データの磁気メディアへの転送。 社会学調査の過程で収集される情報の量は多くの場合、大量になります。調査の平均では、少なくとも数千の情報が得られます。 現在のコンピューターをシャットダウンせずにこのような大量のデータを処理することは非常に重要ですが、非効率的です。 コンピューティング技術の重要性により、収集された情報は特別に設計されたキャリア上に配置される必要があります。 したがって、アンケートからのデータをそのようなメディアに転送することは、社会学的情報を処理する別の段階に置き換わることになります。
ステージ 3. コンピューターに情報を入力します。 特別なメディアに保存されている必要な研究データはコンピュータに入力され、特別なデータ処理プログラムによって事前に断片化および変更された新しいバージョンでできるだけ早く取得されます。 この段階は、計算センターの従業員と現在のプログラムによって実装されることがほとんどです。
ステージ 4. 社会学的データの検証と不正確さの修正。 多くの場合、多かれ少なかれ深刻な結果を復讐するために、情報がコンピュータに入力されます。 このようなキャンセルの理由はさまざまです。アンケート記入時の回答者のキャンセルやコンピュータ可読媒体へのコードの転送、さらにはコンピュータの技術的装置の故障などです。 しかし、それは問題ではありません、星は消えています。 社会学的情報の分析の次の段階に進むためには、データをコンピューターに入力した後、直ちにそれらを特定して修正する必要があります。 この目的のために、社会学者のプレスレッドニクは、調査時間内にデータを削除することで満足できる可能性についての歌を定式化します。 これらおよび他の提案に関する削除された情報に基づいて、社会学者兼研究者はそれらの削除について決定を下し、それによって情報が削除されます。
ステージ 5. 変化の創造。 追加のアンケートから収集された情報は、調査中に必要な栄養に直接対応していないことがよくあります。 これは、ほとんどの場合、追跡可能な特性のうち必要な特性を取得することが非常に難しいという事実によるものです。 この目的のために、すべてを完了するには、収集したデータを修正する必要がある場合があります。 豊富なアンケートの場合、情報は研究結果に直接対応しており、この意味で栄養そのものは変更可能です。
ステージ6。ファイナル。 社会学情報の統計分析。 その重要性により、この段階は社会学的データの分析において最も重要です。 統計分析中に、必要な統計パターンと関係が明らかになります。 社会学者は、さまざまな数理統計手法を使用して、入手可能なすべての社会学的情報に簡単にアクセスし、徹底的に分析します。 この場合、情報の数学的および統計的処理のための同様のプログラムを備えた現代のコンピューティング技術の停滞は、社会学的データの精神的で迅速かつ明確な分析に必要です。
社会学的データは正しく、正確で、安定しており、情報に基づいた、代表的なものでなければなりません。 アラームの分類は、社会学的情報の信頼性を評価するために重要です。 社会学では、すべての試みは通常、手段と理論の 2 つのグループに分類されます。
手段によるリラクゼーションは、記号の仮想的かつ真の意味の目的を果たします。 悪臭はいくつかの段階に分けられ、系統的に分類されます。 ヴィパドコヴィムは修正を意味し、死亡が繰り返されると国際法に従って変更されます。 繰り返し死亡する組織的な排除は永続的になるだろう。
社会学的情報の信頼性を高める他の方法を使用して、コンプライアンスを確保し、経験的データの信頼性を制御することができます。 外部および内部制御の方法を発見する。 外部情報は、提供される経験的情報との関係で重要であり、その後に他の外部情報が続きます。 内側のものは真ん中に研究者の断面サインが入っています。
おそらく、社会学的情報の信頼性を高める方法によって、追跡調査の結果を再提示する際に除去された信頼性のレベルを確立することが可能になるという考えを発展させることが可能である。まさにその方法論と技術によってである。同じ思いです。
文字情報の処理
さまざまな情報を処理するためにコンピューターを使用する幅広い可能性にもかかわらず、最も普及しているコンピューターには、以前と同様に、テキストを処理するために設計されたプログラムが含まれていません。コンピュータ上でテキスト ドキュメントを準備する場合、主に 3 つの操作グループがあります。
入力操作を使用すると、出力テキストを外部フォームから電子フォーム、つまりコンピューターに保存されているファイルに転送できます。 入力は、追加のキーボードで入力するだけでなく、紙の原稿をスキャンし、文書をグラフィック形式からテキスト形式に変換する (認識) ことによっても行うことができます。
- 編集操作では、フラグメントの追加または削除、文書の一部の再配置、複数のファイルの分割、単一の文書を複数の小さな文書に分割するなど、既存の電子文書を変更できます。 紹介と編集は 1 時間の間に行われ、テキストの作業は並行して完了することがよくあります。 入力および編集すると、置換テキスト文書が作成されます。
- ドキュメントの書式設定は、書式設定操作によって指定されます。 フォーマット コマンドを使用すると、テキストがモニター画面上、紙上、プリンター上でどのように表示されるかを正確に決定できます。
テキスト情報を処理するプログラムはテキストエディタと呼ばれます。
現在のさまざまなテキスト エディタはすべて、次の 3 つの主要なグループに分類できます。
1. まず、最も単純なテキスト エディタが使用されます。これにより、最小限の機能を使用して、元のテキスト形式のドキュメントを操作できます。 このエディタのグループには、Windows オペレーティング システムに含まれるワードパッド エディタや非常に低機能の NotePad、および他のメーカーの同様の製品 (Atlantis、EditPad、Aditor Pro、Gedit など) などが含まれます。
2. 中間クラスのテキスト エディタには、ドキュメント デザインの幅広い可能性が含まれています。 これらは標準のテキスト ファイル (TXT、RTF、DOC) で動作します。 このようなプログラムは、Microsoft Works および Lexicon からダウンロードできます。
3. 3 番目のグループまでは、Microsoft Word や StarOffice Writer などの重いテキスト プロセッサです。 テキストを使用したすべての操作に注意してください。 ヴィコリーライターのほとんどは、日常業務で編集者を務めています。
テキスト エディターとプロセッサーの主な機能は次のとおりです。
本文中の記号の導入と編集。
- シンボルに異なるフォントを選択する可能性;
- テキストの一部をある場所から別の場所に、またはある文書から別の文書にコピーおよび転送する。
- 文脈上のジョークとテキストの一部の置き換え。
- 段落とフォントの追加パラメータを設定します。
- 排水管を新しい列に自動的に移動します。
- ページの自動番号付け;
- ワインの加工と番号付け。
- 表と日次図を作成します。
- 単語のスペルをチェックし、同義語を追加します。
- ポブドワの場所と主題の指標。
・作成したテキストをプリンターで配布するなど。
また、ほとんどすべてのテキスト プロセッサには次の機能があります。
さまざまなドキュメント形式のサポート。
-それでは豊かさ。 大量のドキュメントを一晩で処理できる能力。
- 数式の挿入と編集。
- 編集したドキュメントの自動保存;
- 豊富なコラムテキストを備えたロボット。
- さまざまな書式設定スタイルを使用する可能性。
- 文書テンプレートの作成。
- 統計情報の分析。
現在、ほとんどすべての最新のテキスト エディターは、日常のオフィスのニーズを対象とした統合ソフトウェア パッケージの倉庫に含まれています。 たとえば、Microsoft Word は、最も人気のあるオフィス スイートである Microsoft Office のウェアハウスに含まれています。
同様の MS Office プログラムには、OpenOffice.org Writer、StarOffice Writer、Corel WordPerfect、Apple Pages があります。
個人情報の処理
ロシア連邦は、ヨーロッパのために「個人データの自動処理の下での身体の保護に関する条約」を批准しました。 この国際文書の批准により、私たちの国、私たち、そして私たちの地域社会は、人々の権利と「事業者」の権利が再び重要視される新しい社会経済的形成に入りました。 条約の終了に際し、ロシアは連邦法第 152 号「個人データに関する」(以下、連邦法第 152 号)を急いで採択したが、これはすべての基本規定において条約を繰り返している。 しかし、連邦法第 152 号により、人々は最近まで、図書館や歯医者に行くときに、自分自身、家族、仕事、権力など、自分の生活に関する新しい情報を伝える機会がありませんでした。人々の生活のあらゆる側面に関する残忍かつ徹底的な情報収集は、連邦法第 210 号「政府および地方自治体のサービスの組織に関する」の当局にとって驚くべきことではありませんでした。 ここで彼らはまた、欧州のための「個人データの自動処理中の身体の保護に関する条約」および連邦法第152号の採択を要請した。 連邦法第152号に基づき、住民は子どもを育てる保育園をはじめとする職場でも「個人データの処理のため」のさまざまな書類に署名する必要がある。 学校、診療所、図書館、およびすべての社会機関は、私たちの自発的な給付金を集めています。 また、割引を提供する際に、個人データの処理に対する特典に関する文言を太字で記載したアンケートを配布する店舗も指摘しました。
まず第一に、人々はフォームで使用される概念の背後にあるものを知る必要があります。
1. 連邦法第 152 号に従い、個人データとは、個人に直接または間接的に伝達できるあらゆる情報を指します。
2. 「個人データの処理」という概念は、私たちのほとんどが考えているほど無害ではありません。 連邦法第 152 号第 3 条第 3 項に従い、「処理」には、個人データの収集、記録、自動化方法の使用の有無にかかわらず実行されるあらゆるアクション (操作) または一連のアクション (操作) が含まれます。個人データの体系化、蓄積、保存、明確化(更新、変更)、取得、検索、移転(拡張、移転、アクセス)、分離、遮断、削除、削減。
3. 「オペレーター」という用語は非常に重要です。 どの個人データを選択するか、およびこのデータをどのように扱うかはオペレータが独自に決定することを覚えておく必要があります。 連邦法第 152 号に従い、オペレーターは、独立して、または他の人と共同で、個人データを整理および/または処理し、また個人情報の秘密保持の目的を決定する政府機関、地方自治体、法人または団体です。データ、個人データの倉庫、個人データを扱う処理、アクション (操作) を容易にするもの。
4. 「個人データ Wiki」の概念とは何を意味しますか? オペレーターには当社の個人データに対してあらゆる措置を講じる権利が与えられているため、法的に重要な決定の承認にはこの権利が適用されます。 個人データを処理する時間を与えられると、人々はオペレーターがあらゆるアクションを実行したり、機密情報を含む自分自身の情報を操作したりすることを喜んで許可します。
5. 連邦法第 152 号「rozpovyudzhennya」の対象 - これらの行為は、不特定多数の個人への個人データの開示に直接関連しています。 個人データの断片は、個人に関する情報であれ、より広範な情報であれ、実際には、オペレーターの裁量によって、物理的または法的な機密情報に対する人々の認識によって制御されません。 オペレーターが必要であると認識した場合、処理の過程で、個人データの国境を越えた転送が行われる場合があります。オペレーターによる個人データの、ロシア連邦の国家非常線を通じた外国勢力、外国の物理的実体の当局への転送です。または外国法人。
6. 連邦法第 152 号は、人々の「個人データの処理」を拒否した事業者に対して、当社の個人データを操作する事実上無制限の可能性を与えています。 個人データの処理を要求する人々の権利に関するフォームの正式な文言は適用されません。 個人データをクリックした時点で、人々はすでに別のデータベースに送られており、権利が剥奪され、悪用される可能性があります。 さらに、ここをクリックすると、オペレータが報復攻撃を受けると脅迫されます。 すぐにそれについて話すオペレーターもいますが、すぐに実際に停滞するオペレーターもいます。 連邦法第 152 号の第 9 条が改正され、処理をクリックした後も個人データの処理を継続する権利がオペレーターに与えられました。 この法律の第 6 条の変更により、州サービスの単一ポータルへの登録を含む州および地方自治体のサービスを実行する際に、人を介さずに個人データを処理できるようになります。 これらの規定の論理に従って、電子サービスはいかなる種類の個人データも処理することは許可されません。 さて、情報分野では、人々と権力に自分の考えを指示するオペレーターという新しい人物が前面に出てきています。
7. 宗教的なつながりを背景とする何千ものコミュニティは、多数の特別な識別子 (SNILZ、IPN など) にリンクされた個人データの自動保存方法、情報のバーコード化、個人データベースの作成、アクセスに基づくものを受け入れることができません。個人のデジタル識別子に基づいて。 いかなる法的枠組みにおいても個人のデジタル識別子を使用することは、ロシア連邦民法第 19 条で保証されている自分の名前で活動する権利を侵害することになります。 すべての人にとって、名前をデジタル識別子に置き換えることは不快なものです。なぜなら、洗礼の際に与えられた名前がデジタル番号に実際に置き換えられるからです。デジタル番号は生まれる前に生まれ、権利やサービスになる前に義務的な精神的アクセスとなるからです。
ただし、個人データを保存するための自動化された方法の使用は、ロシア連邦憲法で保証されている権利を低下させるものではありません。 vidmovaに対する制裁の最初の適用は、オペレーターの指示以外で自分に関するすべての情報を提供することです。 個人データの処理の公開日を承認したいわゆる事業者は、国民に補助金の支払いや医療支援の提供を強制しており、科学者らは検査を受けることを許可されない、または受けられなくなるという脅威について情報を提供している。証明書を参照してください。 これは国民の権利に対する重大な侵害です。
ロシア連邦憲法は、社会保障、医療扶助、教育、および個人データの処理義務年ではカバーされないその他の権利に対する国民の権利を有しています。 憲法には直接的な効力があり、法的効力を持ちます。 居住者は、すべての権利を行使し、個人データを処理する権利を有します。
ロシア正教会の司教評議会は、「技術の発展と個人データの処理に関する教会の立場」という文書を採択した。 この文書には、憲法上の権利に基づき、また宗教的動機に基づいて、何千人もの国民が新しい身分証明書システムを開発することが奨励されていると記載されている。
教会は、あらゆる識別子を受け入れる際の自主性の原則を特に重視しており、憲法上の国民の権利を尊重し、電子メールを受け入れるとみなされる人々を識別方法によって差別してはならないと指摘しています。
教会は、個人データを処理する権利がある市民の権利を侵害することは許されないことを尊重します。
第 5 項では、「個人情報の提供により、生活のさまざまな領域(経済、医療、家族、社会保障、権力など)を通じて人々が統制および管理される可能性が生じるという事実に関連して、現実的な問題が存在する」と述べられています。人々を日常生活に導入し、彼らの魂に平和をもたらすだけではありません。 教会は国民の懸念を共有し、すべての人が個人データを処理する権利を持つという容認できない権利侵害を尊重します。」
情報処理の組織
いずれの場合も、外部の役人、個人の役人、特定の企業の役人など、組織の構造の設計には可能なオプションがあります。個別の要因には次のようなものがあります。
企業内の OI の変数と浸透レベル (幅/数、深さ/共通、およびアドオンの統合段階) の三値性。
kerivnitstva スタイル。
組織の基本構造とOIの範囲。
特定の企業における情報処理の問題の規模に応じて、この分野ではさまざまな組織構造が存在します。 さまざまな規模の下位部門 (またはサービス) を組織するための典型的なオプションを特徴付けるさまざまな構造図 (組織) を見てみましょう。
OI の大部門の構造は、中央組織の他のランク、アプリケーション システムの設計とその保守、IC、基本的な技術機能の開発、およびメイン VC に分かれています。 どうやら、ここのスタッフには幅広いスタッフ機能が与えられているようです。
大企業におけるサービス提供は、当然の取り組みの 50 ~ 70% を占めており、これは構造の重要な自律的な部分と見なすことができます。 同時に、この解体された下部構造に反対することが多いのは、実際にはロボットの設計がより権威あると考えられている人々であり、販売代理店によるシステムの保守とサポートが、原則として依然として最も明確であるということです。これらの機能を徹底的に確保するのが妥当です。 これらの人々自身からの助けを求めて。
計算センターは、たとえば、データの中心ハブである可能性があります。 多くの企業はデータ構造の分割を採用しています。
車の前に来ると、彼らは粘土彫刻、より正確にはキャラバンの計画を吐き出します。 計算作業を整理するときは、原理的にその変化しやすい性質を認識することが必要になることがよくあります。
設計(開発)の対象となり、平均的なユニットOIの構造にもシステム開発をお勧めします。 サードパーティ組織によって追加される標準アプリケーション ソフトウェアの選択と実装 (インストール) は、すべての企業にとってますます重要になっています。 ターミナル koristuvachs の整備もこの同じグループで行われます。 このような構造には、ウイルス種を分散制御する目的で設計されたデータの中央ハブが存在しないことがよくあります。
計画とサポートの機能には、その種のケア部門の権限の範囲外である組織的なタスクが含まれます。 計画とサポート機能も、技術的機能とソフトウェア機能、および境界計画に依存します。 スタッフ間で生じたこれらの状況やその他の状況に応じて、特定の機能を別または第 3 レベルの作業グループに委任することも可能です。
小規模支部の OI の少数の実践者にとって重要です(さまざまな機能が同じ人によって実行され、タスクが計画され、その責任は別の個人組合と協力して作業します。管理は多くの場合子供に伝わり、組織化、データ収集、処理、制御が継続する産業プラントでは、標準的なアプリケーション ソフトウェアが存在しないことが多く、そのような企業におけるサポートやサポートの機能が銀行に移管されることがよくあります。 、プロファイルがまだ形成されていない政府の部分。
経済情報の処理
1. 経済情報を表形式で表示します。表は、ビジネス活動をデジタル表現でよりコンパクトに凝縮したものです。 テキスト分析を必要としない機能により、テーブルの役割は高くなります。 そして情報を受け取るための最も便利で合理的な形式。 テーブルには、単純、グループ、結合の 3 種類があります。
分析場所の背後には、インジケーターの配置順序、追跡インジケーターのダイナミクス、インジケーターの倉庫の構造変化などを含むオブジェクトの特性を表示するテーブルがあります。さまざまな兆候の背後にある指標、出展者の調査前のレベルへの要因の流入の内訳の結果。
2. 情報をグラフィックで表示する方法。
グラフは、幾何学的図形を使用した指標とその位置の大規模な画像です。
グラフの主な形式は図であり、その形状の背後には、積み上げられた、濃い色の、円形、正方形、線形の形状があります。 置換の背後にある - アラインメント図 (インジケーターの値の位置合わせの最も単純なグラフ - スタッカー、ダークダイアグラム。それらのために、折り畳まれた直交座標系が作成されます。)、構造 (セクター)、動的、連結グラフ(OS と横軸には因子指標の値が表示され、縦軸には同様のスケールでの実効指標の値が表示されます。)、コントロール グラフ (グラフ上には 2 本の線があります: 計画および 1 時間のインジケーターの実際のレベル。) など。
3. レベリング方法。
評価とは、隠れた特性とそれらに関連する値を特定する単一の方法を使用して、未知の現象において物体がすでに知られている、以前に調査されたものと一緒に提示されることを理解するための科学的方法です。
Vikoristavayutsya の場合:
実際のデータと計画されたデータの調整。
- パフォーマンス指標の変更。
- 分析された PP のインジケーターとガルーサの平均インジケーターの調整。
・経営判断前後の活動成果を高める。
4. 極値と平均値の変動。
絶対的なインジケーターは、世界中の他のアイテム (vaga、obsyagu、trivalost、plosh、vartosti など) に関係なく、アイテムの膨大な寸法を示します。
これらの指標は、調査中のオブジェクトのサイズと他のオブジェクトのサイズ、またはこのオブジェクトのサイズ、または異なる期間または別のオブジェクトから取得されたオブジェクトのサイズとの間の関係を確立します。 関連する指標は、ある値を別の値で除算した結果から取得され、それが均等化の基礎となります。
一定期間にわたるインジケーターの変化を特徴付けるには、特定のダイナミクス値を使用します。 これらは、前期間(月、四半期、世代)のフロー期間の指標の値の分割によって指定されます。 それらは成長率(増加率)と呼ばれ、パーセンテージと係数に応じて表されます。 特定のダイナミクス値は、基本値またはランチェジアン値のいずれかになります。 構造の指標は、滅菌部分の目に見える部分 (穴のある部分) であり、百と係数で表されます。
5. 情報のグループ化。
AHD で広く使用されているのは、情報のグループ化、つまりオブジェクト全体を分割し、同様の標識の背後にあるある程度均質なグループに分割することを理解することです。 分析中に、類型的、構造的、分析的なグループを分析することが重要です。
類型的なグループ化の例としては、活動に関する人口グループ、権力形態に関する企業グループなどが挙げられます。
構造的なグループ化により、内部構造の開発や新しい要素間の接続が可能になります。 また、職業、職歴、年齢、雇用基準に基づいて労働者の倉庫に分類されます。
分析 (因果関係の継承) グループ化は明確さを高めるために使用され、研究されている指標間のつながりを直接形成します。
6. バランス方式。
バランス法は、相関関係、つまり相互に関連する経済指標の 2 つのグループの比率 (一部は同一である) の主な原理として機能します。 労働力、財源、原材料、燃料、資材、主な生産方法などの企業の安全性を分析し、廃棄物の量を分析するために広く使用されています。
バランシング方法は、決定論的な加法因子モデルの場合に使用できます。 分析により、物品のバランスに基づいたモデルを確立できます。 例えば、
決済剰余金 + Virobnitstvo + 輸入 = 販売。 製品 + ビザ + 市場の余剰
7. 豊かな世界レベル。
その日のニーズに合わせて、同じ地域、地域、主題の複数の企業の活動を評価します。 これらの指標の比較に基づいて、企業の活動のランキングが実行されます。 1 つの企業が異なるディスプレイに対して異なる場所を占めることができるため、異なる方法を使用できます。 ユークリッドスケール法に基づくリッチスケール分析では、絶対値だけでなく、標準企業の指標に対する特定の指標の近さ/距離も決定できます。 これに伴い、整列した企業の座標は、基準企業の座標(座標=1)に対応する部分で表現される。
ユークリッド法に基づいて広範囲の分析を行う段階:
1. 企業の活動の結果、収集された情報、および出力データの折り畳まれたマトリックスを評価する指標システムを設定します。
2. マトリックスの各グラフについて、1 と比較して最大値が計算されます。次に、グラフのすべての要素が最大値で除算されます。
3. 係数を 2 乗し、対応する有意係数の値を乗算して係数を削除し、評価スコアを周囲の列に追加します。
4 格付けの結果は、その合計に対する皮膚事業の順位を順位付けして示すものである。 最高の評価スコアを獲得した企業の第 1 位。
sum メソッドを使用する場合、指定された係数に関与する場所がスキン グラフに示されますが、それ以外の場合、その場所は包含されます。 額が少ない人は1額。 ただし、有意係数に注意を払うことが重要です (最も重要なのは絶対流動性係数です)。
8. 外国人から指標を持ち込む方法。
分析中に考慮する必要がある重要な点は、明らかに均一ではない値を比較する可能性があるため、指標の一貫性を確保する必要があることです。
指標の不一致は、価格水準の違い、企業の義務、構造変化、製品の異質性、指標の内訳方法の違いなど、さまざまな理由によって引き起こされる可能性があります。他の暦期間でも同様です。 未修正の指標を修正すると、分析結果に基づいて誤った結論が得られる可能性があります。 vartis 評価のレベルが異なると vyklikan の指標が一致しないため、この要因を中和するために、それらのレベルは同じ価格で表現されます。
情報の処理方法
現在の情報処理システムは、紙データや自動化されたワークステーション技術間でデータを交換するデジタル技術に依存しており、スピブロビットグループの共同部隊の統合も可能にしている。 )、リアルタイムモードでいつでも交渉中の意見交換(電話会議)、電子メール、電子メールボックスなどによる迅速な資料交換。 このようなシステムについては、「企業業務プロセス管理システム」という用語を拡張して、業務全体をサポートする必要があります。 このようなシステムは、実行不可能なテクノロジーを特徴としています。「クライアント/サーバー」。グローバル インターネット ネットワークを介したリモート クライアントの接続を含みます。 さまざまな国や大陸にある 40,000 を超えるクライアントをシステムがグローバルな情報空間に統合することは、珍しいことではありません。 そのようなアプリケーションの 1 つは、ロシアを含む世界中に支店を持つマクドナルド社です。
パソコンをワークステーションに設置し、ローカルで接続するだけでは、元の情報構造が完全に変わるわけではないため、経営に良い影響を与えるとは考えにくい。 時代遅れの作業方法を自動化することは不可能ですが、パソコンを新しい論文を高速に作成するためのツールに変えることはできます。 したがって、米国の企業の業務分析の結果は、企業のリスト倉庫へのタイムサービスを可能にするために、以下を含む 43 の異なる文書、合計 113 ページが作成された状況を説明しています。必要なコピー。 これは、情報システムがサブユニットと他のサービスとの間の接続 (通信) を確立しているためです。 さらに、企業が正常に機能するためには、20 ~ 30 件を超える内部コミュニケーションは必要ありませんが、実際には 3 ~ 4 倍以上の内部コミュニケーションが必要です。 さらに、ビジネス管理の自動化の実践は、生産性の高いコンピューター機器の確立により、コピーとその配布の「あらゆる問題」を管理するための通信量の増加につながる可能性があることを示しています。 コンピューター技術の生産におけるこの段階は、すべての通信 (通信) を最適なレベルまで高速化することによって達成できます。
最も広く蔓延している問題の 1 つは、コンピューターの明らかな能力の帰属です。 パーソナル コンピューターは、どれほど高価で生産性が高くても、単なる治療機械に過ぎません。複雑な経済問題を解決することはできず、私たち自身も目標を正しく立てることができないからです。
また、非常に重要なのは、コンピューター技術の導入直後にチームが抱えている社会心理学的問題であり、その結果、軍人の数が減少し、活動に対する管理が強化され(したがって強化され)、他のコロナウイルス患者も同様に増えます。
コンピュータ化は、会計技術と政府活動の分析技術を根本的に変えます。 非自動会計システムでは、政府取引に関するデータの処理が簡単に簡素化されるため、紙の文書、命令、譲渡、記録、地域ジャーナルなどの地域登録簿などの情報が伴います。 同様の文書はコンピューター システムに保存されることがよくありますが、多くの場合、電子形式でのみ見つかります。 さらに、会計コンピュータシステムの主要な会計書類(会計帳簿や仕訳帳)にはデータファイルが含まれており、コンピュータなしでは読み取りや変更が不可能です。
p align="justify"> コンピュータ技術は、インテリジェンスと制御手順を評価する際に考慮する必要がある多くの機能によって特徴付けられます。
単一の操作。 コンピュータ処理では、複数の同一の会計処理のために 1 つ以上のコマンドが送信されます。これには、手動処理などのランダムなエラーの発生も含まれます。 ただし、ソフトウェアの修正 (およびハードウェアとソフトウェアのその他の体系的な修正) は、新しい知識を持つすべての同一の操作の誤った処理につながります。
サブ機能。 p align="justify"> 自動化されていないシステムではさまざまな改ざんが行われるため、コンピュータ システムでは個人的なものではない内部管理手順を作成できます。 この状況により、コンピュータにアクセスできる最前線の従業員は他の機能を実行できなくなります。 その結果、コンピュータ システムは追加の入力を導入して、必要なレベルでの制御をサポートできます。非自動化システムでは、これは単純なサブ機能によって実現されます。 このようなログインの前に、対話モードの端末を介して資産およびクラウド文書に関する情報にアクセスできるファクシミリエージェント側で受け入れられないアクションを防止するために、パスワードシステムが導入される場合があります。
不正確さにより潜在的な可能性が現れました。 非自動会計システムと比較して、コンピュータ システムは、制御機能を含む不正アクセスの影響を受けやすくなっています。 また、データの変更や資産に関する情報の直接的または間接的な削除にも対応します。 操作の機械処理に関与する人が少なくなるほど、間違いや不正確さを特定する可能性が低くなります。 アプリケーションプログラムの開発または調整中に行われた申請は、試用期間中に不当に遅れる可能性があります。 行政側からのコントロールが強化される可能性。
コンピュータ システムは管理者に幅広い分析機能を提供し、会社の活動を評価および管理できるようにします。 追加のツールを利用できると、内部管理システムが確実に改善され、その結果、内部管理システムが無効になるリスクが軽減されます。 したがって、支出係数の実際の値と計画された値との通常の比較の結果、および計算の計算は、通常、管理前に情報のコンピュータ処理中に実行されます。 さらに、特定のアプリケーション プログラムは、コンピュータの動作に関する統計情報を蓄積し、会計取引の実際の進行状況を制御するために使用できます。
コンピュータ操作の開始。 コンピュータシステムは特定の取引を自動的に記録することができ、自動化されていない会計システムの場合のように、その承認は必ずしも文書化される必要はありません。これは、管理者がそのようなシステムを運用するという事実自体が暗黙の方法で自明性を伝えるためです。対応する制裁の内容。
このように、会計システムを維持する際の政府取引の処理方法は、企業の組織構造や内部統制の手順や方法に大きな影響を与えます。
会計士の役割と行政との関わりは明らかに変化しています。 しかし、会計士の仕事の自動化はロシア人の心の中で特定の人々を惹きつけている。例えば、一枚ずつ印刷する必要がある書類が大量にあるからだ。 ロシアの国際標準への移行に関連して、今後 3 年間にさらなる困難が生じるだろう。
情報処理の種類
情報処理には、さまざまなアルゴリズムによって 1 つの「情報オブジェクト」を他の「情報オブジェクト」から分離することが含まれ、情報の処理が多様性の増加につながる主要な操作の 1 つです。最上位レベルでは、数値処理と非数値処理が表示されます。 処理の種類を指定する場合、「与えられた」という概念の解釈が異なります。 数値処理では、変数、ベクトル、行列、豊富な配列、定数などのオブジェクトが処理されます。 数値以外の処理の場合、オブジェクトにはファイル、レコード、フィールド、階層、境界、テーブルなどが含まれる場合があります。 もう 1 つの重要な点は、非数値処理からオブジェクトの全体ではなく、オブジェクトに関する包括的な情報を取得できるため、データの数値処理には大きな意味がないことです。
現在利用可能なコンピューティング技術に基づいて、次の種類の情報処理が考えられます。
シーケンシャル処理は、1 つのプロセッサを使用する EOM の伝統的なノイマン型アーキテクチャに基づいています。
並列処理。EOM 内に多数のプロセッサが存在することを表します。
コンベア処理は、異なるタスクを実行するために EOM アーキテクチャ内の同じリソースに接続されます。両方のタスクはシーケンシャル コンベアと同じですが、タスクはベクトル コンベアです。
一般的な EOM アーキテクチャは、情報処理の観点からこれらのクラスのいずれかに分類されるのが通例です。
コマンドとデータの単一ストリームを備えたアーキテクチャ (SISD)。 このクラスには、属性と値のペアを処理する中央プロセッサを含む従来のシングルプロセッサ システムが含まれます。
単一のコマンドとデータ ストリーム (SIMD) を備えたアーキテクチャ。 このクラスの特徴は、多数のプロセッサを制御する 1 つの (中央) コントローラの存在です。
コントローラーと処理要素の機能、プロセッサーの数、検索モードの構成、ルーティングと制御手段の特性を検討することが重要です。
ベクトルおよび行列タスクの実行に使用される行列プロセッサ。
さまざまな無数のタスクに使用できる連想プロセッサと、そこに保存されている情報に直接アクセスするために使用できるメモリストレージ。
数値処理および非数値処理に使用できるプロセッサ アンサンブル。
コンベアおよびベクタープロセッサ。
マルチストリームおよびシングルデータ (MISD) アーキテクチャ。 コンベアプロセッサーはどのクラスに分類されますか?
マルチ命令マルチデータ (MIMD) アーキテクチャ。 どのクラスに変更を加えることができますか: マルチプロセッサ システム、マルチプロセッサを備えたシステム、複数のマシンを備えたコンピューティング システム、コンピューティング メジャー。
処理操作としてデータを作成すると、その結果としてその光が現在のアルゴリズムに転送され、より高いレベルで処理するためのさらなる処理が行われます。
データの変更は実際の対象領域の変更に関連しており、新しいデータの追加や不要なデータの削除によって影響を受けます。
データのセキュリティと整合性の確保は、情報モデルにおける対象領域の実際の状態の適切な表現に直接基づいており、不正アクセス (セキュリティ) や技術機能やソフトウェア機能の障害や障害コードからの情報の保護を保証します。
コンピューターのメモリに保存されている情報の検索は、さまざまなレコードから入力を選択するときは独立した操作として機能し、情報を処理するときは追加の操作として機能します。
意思決定は、情報を処理する前に行われる最も重要なステップです。 さまざまな数学モデルの使用を必要とするさまざまな決定が行われてきました。
セラミックオブジェクトの機械に関する情報のレベル、オブジェクトモデルと制御システムの精度と精度、外部環境との相互作用に応じて、意思決定のプロセスはさまざまな心の中で行われます。
1) 重要性を考慮して決断を下す。 オブジェクトと制御システムのこの特定のモデルでは、タスクが重要であり、追加の電力の注入はネットワーク化されていません。 したがって、選択したリソース利用戦略と最終結果の間には明確な関係があり、その重要性を念頭に置いて、ソリューション オプションのコストを評価するための一般規則を理解し、それらを最適なものとして受け入れるだけで十分であることは明らかです。それが最大の効果につながります。 このような戦略は類似しているため、それらはすべて同等であると見なされます。 理解のために、数理計画法の使用の重要性を説明します。
2)リジクの心の中での決断を称賛する。 危機を念頭に置いて決断を下すには、外部中間勢力の流入を考慮する必要があるが、これは正確に予測することはできないが、その勢力が想像を絶する分裂であることが知られている。 念頭に置いて、同じ戦略の使用は異なる結果をもたらす可能性があり、その可能性はタスクに関して表示され、決定することができます。 戦略の評価と選択は、最終結果を達成する可能性を保証する次の一般規則に従って実行されます。
3) 取るに足らないことの心の中で賞賛された決定。 戦略の選択と毎日の明確な接続の最終結果との間の主要なタスクと同様です。 さらに、最終結果が現れる可能性の重要性も不明であり、これは決定できないか、代替の意味では存在しません。 「戦略 - 最終結果」の各ペアは、外部評価が勝者であるように見えることを示唆しています。 最も広範な基準は、保証された賞金の最大額を達成することです。
4) 豊富な基準に基づいて意思決定を行う。 上記とは関係なく、基準の豊富さは、相互に還元できない独立した目標が多数あるという事実から生じます。 多数の決定事項が存在すると、最適な戦略の評価と選択が複雑になります。 考えられる方法の 1 つは、別のモデリング方法を使用することです。
文書、記録、レビューを作成すると、変換された情報が人間とコンピューターの両方が読み取ることができる形式に配置されます。 このアクティビティには、文書の処理、読み取り、スキャン、分類などの操作が含まれます。
情報を処理する場合、情報はある提出形式から別の提出形式に転送されますが、それは情報技術の実装プロセスから生じるニーズによって決まります。
情報処理プロセスに関わるすべてのプロセスの実装は、さまざまなソフトウェアツールを使用して動作します。
入力されたテキストを処理するには、コンピューター タイピング システム (DTP) が使用されます (DTP - デスクトップ パブリッシング)。 DTP - それはどのような準備技術ですか?何のために? 更新しますか? 文書は自律型ワークステーションで処理されますが、これは個人用ワークステーションとして機能しますか? コンピューターカイワークステーション。 テキスト、グラフィック、画像をレイアウトに従ってデザインし、スムージーに結合します。 最近、最新のシステムの安価な技術が高度な写植技術に取って代わりました。 ソフトウェア ツールは幅広いテキスト処理機能を提供しますか? そんなにすごい情報なの? フォントを選択するときに、別の写植機で行っていたことを犠牲にすることなく結果を選択できますか? テクノロジー。 最も人気のあるレイアウト プログラムは、Design (Adobe Systems) と QuarkXPress です。
標識のコーディング
電子システムにおける精神処理にはテキストのコーディングが必要です。 フォントはスキンサインのデジタルフォントに似ていますか? 機械? コード。 世界中で、テキストを表す標準は ASCII (American Standard Code for Information Interchange) です。 7 ビットの文字記述が標準であり、128 の異なる文字をエンコードするために使用できます。 スムガの代わりに作成に使用される 96 個の文字と、制御記号に使用される 32 個のコードはどのように特定されるのでしょうか? 情報。 ウムラウトと特殊文字は組み合わせて指定されていますか? 8 ビット目以降は、ソフトウェア製品の製造元によってインストール方法が決定されます。 これにより、データ転送の過程で変換時に問題が発生することがよくあります。
ファイルは、計算システムによって簡単に保存および処理できる形式で配置された、論理的に関連したデータの集合です。 ファイルは論理レコードの集合です。
ファイルに保存されるレコードについて話すとき、「論理的」という言葉が省略されることがよくあります。 Kozhen は、特に認識される可能性のあるトリビュートをファイルに記録します。 予約の種類に基づくファイルでは、各レコードはウイルスの 1 つの名前に対応するデータ全体を表すことができます。 管理者が管理する学生の進捗ファイルには、学生の名前、学科番号、コース番号、試験の成績が記録されます。 銀行口座ファイルの記録には、たとえば、顧客番号、顧客の名前、当座預金口座、および前月の顧客の取引に関する情報などのデータが含まれる場合があります。 提出管理ファイルのレコードは、フロー プロセスで以前の支払者から収集した合計額で構成されます。 現時点では、プログラミングの多くはファイルの編成と管理に関連しています。
オペレーティング システムの重要な部分は、ユーザーがデータを簡単に管理および処理できるように設計されています。 ただし、オペレーティング システムには他にも大量の情報が提供されます。 これには、コンピュータ プログラムの出力、サブプログラム ライブラリ、コンパイルされたタスクの入力データとその出力のテキストが含まれます。 オペレーティング システムによって処理されるデータは、データ セットの形式で提示される場合があります。 データのコレクションは、オペレーティング システムが使用する情報の最大のコレクションであり、データ自体は、保護および保護する追加情報とともに、何らかの特別な方法でメモリ内に表現されます。多重度の複数の要素にアクセスする可能性。 皮膚のオペレーティング システムは、多くの有効な構造の 1 つを生成するセットで動作します。
データ ファイルを使用するには、オペレーティング システムの機能を確認する必要があります。 分析される構造のタイプは、データ セットがどのように編成されているかを示します。 データ セットを編成する方法を簡単に説明します。まず、ファイルの論理レコードと入出力操作の間に表示されるメモを詳しく見ていきます。
レコードブロック
ご想像のとおり、ファイルは 1 つ以上の論理レコードで構成されています。 記録として、手または 1 枚のパンチカードの代わりにデバイスに表示される行が表示されることがあります。 アセンブラ プログラムについて話している場合、ここでのエントリは出力言語の命題であり、80 バイトを占めます。 特定の生徒に関する情報を含むファイル エントリには 500 バイトかかる場合があります。 レコードの合計数 (両方を合わせたもの) がファイルの属性に割り当てられているようです。
物理レコードまたはブロックは、入力デバイスまたは出力デバイスによって 1 回の操作で送信される情報です。 パンチカードまたは出力パンチから読み取るデバイスの場合、ブロックは 80 バイトで構成され、80 バイトのフラグメント自体が 1 枚のパンチカードによってエンコードされます。 使用するブロックは 132 バイトの行です。 このようなデバイス、つまりデバイスでは、ブロックのサイズは機器自体によって厳密に決定され、ブロック内の論理レコードの数は変更できず、一度に作成されるレコードは 1 つだけです。 このようなデバイスは、単一録音用デバイスと呼ばれます。 磁気ディスクや磁気ストリップなどの他のデバイスでは、ブロックの寸法は厳密に定義されていません。 このような状況では、プログラマー自身から悪臭が生じます。 物理レコードは必ずしも論理次元に従っているとは限りません。 データ セット内のレコードの形式は、タイプ レコードとブロックのサイズ間の設定によって決まります。
小さい 17.1. レコード形式。
物理レコードと論理レコードのサイズが大きすぎる場合、レコードはブロックされないようです。 1 つの物理レコードには複数の論理レコードが含まれるため、データ形式のブロック化についてよく話されます。 これは、周囲のレコードのサイズがブロックのサイズを超える場合に発生する可能性があります。 このようなセット内のレコードは、トランジショナルと呼ばれます。
データセット内のブロックのサイズは定数値です。 これが、私たちが交換可能な生命のブロックについて話し、ブロックの寸法を特徴付ける量の値がブロック自体の中央に書かれている理由です。 セット内のすべてのブロックは同じサイズであるため、固定値のブロックからのデータのセットについて説明します。
実際には、ブロック サイズと隣接するレコードのさまざまな組み合わせが存在します。 考えられるいくつかの結果を図に示します。 17.1. 図のデータ、画像のセット。 17.1、またはパンチカード ファイルなどかもしれません。 各ブロックの合計数は 80 バイトに等しく、各ブロックには論理レコードが 1 つだけ含まれます。 図に入力します。 17.1,6、100 バイトのレコードから折りたたまれます。 このセット内のブロックの合計は最大 300 バイトです。 これは、このセットにデータを入力または表示するプロセスで、1 回の操作内で 300 バイトの情報が入力または表示されることを意味します。 セットがコンピュータ プログラムまたはオペレーティング システム プログラムによって処理されると、ブロックは記録エッジに分割されます。 図では、 17.1は、最終日の推移記録を含む一連のデータを示しています。 十分なレコードの入力または出力は、2 つの入出力操作の出力に転送されます。 データセットの図。 17.1gは乗り換えの記録からまとめたものです。 ブロックの期間とブロックに含まれるレコードの数に応じて異なります。 記録用のスキン ブロックを配布するタスクも、詳細なプログラムに基づいて行われます。
データセットを整理する方法
ウェアハウス内でデータ セットを分散するさまざまな可能性 (ブロックとレコード) について理解したところで、次にセットの基本構造に関連する要素を見てみましょう。 コレクションを整理するとき、ブロックからのスキンとデータのコレクションを全体として結び付けるために、ストレージブロックとトレイが相互に配置されることが理解されます。 募集を組織するための適切な方法の選択は、数人の当局者に委ねられています。 これには、ダイヤルが保存されるデバイスのタイプ、隣接するレコードが読み取られる順序、ダイヤル時に再検査されるデータのタイプが含まれます。
一貫した組織。 磁気記憶装置や単一レコードを備えた装置などの一部の周辺装置は、特定のデータ セットを編成する方法を明確に示しています。 レコードは保存された順序で処理されます。 パンチカードリーダーの場合は、挿入の準備と同じ順序でカードごとに出力アレイを入力します。 装置は順番に隣り合って列ごとに配置されており、悪臭が次の列から出てきます。 情報はブロックと同じ順序で磁気ページに記録されます。 これらの行は、入力されると、ブロックが配置される順序で処理されます。

小さい 17.2. 順次編成のファイル。
一方、磁気ディスク上の記憶装置などの直接アクセス装置を使用すると、便利な方法でブロックの書き込みと読み取りが可能になります。 この目的のために、エントリにアドレスを入力する必要があります。 言い換えれば、セット内のレコードの処理は、レコードの配置先のアドレスまたはその背後にあるアドレスがわかっていれば、かなり秩序立った方法で実行できます。 ただし、ほとんどのプログラムでは、セット内のレコードの物理的な順序は、処理される順序と一致しています。 周囲の記録、倉庫の提案、出力プログラムを確認することはほとんどなく、それらが書かれた順序で実行する必要があります。 何百もの機械で作成されたオブジェクトやクリエイティブ モジュールについても同じことが言えます。
後続のレコードの処理が物理的な位置の順序で実行されるファイルをシーケンシャルと呼びます。 シーケンシャルファイルを作成したり、新しいエントリを追加したりする場合、情報が記録される順序は、周辺機器に送信される順序と同じになります。 シーケンシャル ファイルのレコードは、新しいファイルに挿入された順序で読み取られます。 デバイスやメモリ上に配置された順に情報を処理することを逐次処理といいます。
連続したファイルは、順次編成を通じてデータ セットに保存されます。 図では、 17.2 は、順番に編成されたデータ セットの一部を示しています。 セット内の残りのブロックの後には、ライン マークと呼ばれるデータ セットの終わりを示す特別なブロックが続きます。 次のセットに描画ブロックを追加すると、そのブロックにラインマークが重なって、その直後に新たなマークが書き込まれます。 データセットを入力すると、レコードはセットに記録されている順序で読み取られ、行マークが押されるまでエントリが読み取られます。
図書館組織。 私たちは、コンピュータ科学者にとって非常に重要である特定のシステム ライブラリの起源をすでに推測しています。 システム マクロ ライブラリ、カタログ作成プロシージャのライブラリ、システム プログラムとテスト アプリケーションのライブラリがあります。 ライブラリの各セクションには、最新のデータ セットが含まれています。 たとえば、OS システムのカタログ化プロシージャのライブラリには、ASMFCLG、FORTCLG、COBUCG などのセクションが含まれています。
ライブラリの代わりに追加のセクション名の入力を求められます。 たとえば、INITIAL マクロを解析する場合、アセンブラはシステム マクロ ライブラリにある INITIAL 名を持つセクションを照会します。 1 つ以上のセクションと組織で構成され、各セクションへのアクセスがそれらの名前によって提供されるようなデータのコレクションは、ライブラリ セットと呼ばれます。

小さい 17.3. 本書で使用される特別なマクロに対応するためのライブラリ データ セットの構造。
ライブラリ データ セットは、直接アクセス デバイスに保存されます。 これにより、さまざまなセクションを表示し、そのアドレスも示すことができます。 ライブラリのセクションを検索しやすくするために、システムはセクションごとにサブセットと呼ばれる特別なテーブルを作成します。データ セットはそのセクションのアドレスと一致します。 図では、 17.3 にライブラリセットの構造を示します。 ライブラリの次のセクションがクエリされるとすぐに、システムはユーザー名を検索する場所を探します。 次に、これらの名前とアドレスを使用して接続が作成され、すぐに検索されて、必要なセクションを表す連続したデータ セットの場所が特定されます。
オペレーティング システムは、外部ライブラリ セットの作成と管理のための特別なプログラムを提供します。 OS は、パブリック ライブラリを維持するためのライブラリ キットも提供します。 OS の DOS システムには DOS システムにはほとんどロボットがありません。DOS は特別なニュース、POSS POSSIBLISTE OPENSIA BIBLIOTECHI TO VIKONUVATI ROBOTIS IN THE ROBOTIS を作成できません。
インデックス順の組織。 このような状況では、各デバイスに格納されている順序でレコードを選択するセットの後続の処理と、レコードの配置による接続の完全な処理の両方を手動でクリーンアップする必要があります。レコードの読み取り、追加、変更。 クラウド情報を処理するためのプログラムを知る 私たちは、各明らかなブランド名に対応するメモリレコードを、スキン名ごとに 1 レコードずつ保存する責任を負います。 主な意味 スキンマッサージの終了時に、現在のファイルが表示されます。 新しい行。これは曲名と一致しています。
しかし、時間の経過とともに、現在の状況は変わる可能性があります。企業は完全に新しい製品を準備して購入することも、古い製品を段階的に販売することもできます。 これには、イメージ ファイルに書き込む前に変更を加える必要があります。 エントリーする前に変更するには、すぐに変更を知る必要があります。 レコードを見つけるには、必要なレコードが特定されるまで、ファイル全体を最初から最後までレビューすることができます。 ただし、ファイルに数千のレコードが含まれている場合、既存のレコードに変更を加える必要がある場合に毎回そのようなレビューを行うと、マシン時間の点でコストがかかりすぎることが判明する可能性があります。

小さい 17.4. インデックス順編成のファイル構造。
実際、一連のデータを編成するこのような方法が必要です。この方法では、個々のレコードへのアクセスを順次に、または順次キーを使用して行うことができます。
このデータ編成方法では、インデックス順編成が行われます。 索引順データ・セットを作成する場合、ファイル・レコードは最初にキーによって順序付けされます。 クラウド情報の処理に関連するアプリケーションでは、キー レコードは支店番号に基づきます。 その後、レコードが続いて表示されます。 これらは、システムによって直接アクセスできるデバイス上に配置されます。 1 つ以上のインデックスを持つ人。 これを手動で行う場合、このようにして作成されたセットの処理を、対応するデバイスを記録する順序で順次実行することができる。 一方、キーを使用して特定の各レコードをリクエストすると、システムによってインデックスが検索され、必要なレコードがすぐに見つかるように指示されます。
図では、 17.4 は、データ セットの単一インデックス構成の例を示しています。 出力ファイルはサブファイルに分割され、それぞれがインデックス テーブルの最初の行で表されます。 この行には、残りの 1 つのキーと、podfile の最初のエントリのアドレスに関する情報が含まれています。 特定の指定されたキー値を使用してレコードを入力する必要がある場合、システムは最初にインデックス テーブルを参照して最初の行を検索し、この値以上の値を配置します。 必要なエントリは、この行に対応する podfile の下に配置する必要があるため、この podfile の要素間でさらに検索が実行されます。
システムには、新しいエントリを別のファイルに追加したり、古いエントリを削除したりする機能があります。 したがって、インデックス順の構成により、ファイル処理の機能が大幅に拡張されます。 レコードは、十分な順序で順次処理できます。 ただし、これにより、出力ファイル内のレコードの順序が転送されます。
直接組織。 ファイル内で隣接するレコードが配置される直接アドレスはユーザー自身によって設定されるため、データ セットの直接構成について説明します。 レコードと同じように、レコードの正確なアドレスまたは領域のいずれかを提供するようにキーを設定します。 直接編成すると、ファイル内の個々のレコードに最適にアクセスできるようになりますが、同時にデータ セットの作成と維持に対するすべての責任がオペレーターに委ねられます。 直接編成は、オペレーティング システムによって作成された構造から見えるファイルで作業を完了する必要がある場合に使用されます。
アクセス方法
部門で セクション 17.4 では、周辺デバイスと、これらのデバイスを直接プログラミングする方法について説明します。 ただし、これほど低いレベルでプログラミングできることは非常にまれです。 メモリと周辺デバイス間のさまざまな交換を組織化し、それらのデータセットを作成するために、さまざまな組織がアクセスメソッドと呼ばれる特別なシステムプログラムを使用しています。 アクセス方式を使用する入口/出口コマンドは、入口/出口スーパーバイザと呼ばれる一連のシステム プログラムを作成するために使用されます。 入出力操作自体は、入出力スーパーバイザーとそれに関連付けられたサブプログラムによって直接調整されます。 実際、これは、アクセス方法が異なると、アクセス方法自体に含まれるさまざまな入出力操作に関連する特定の詳細に注意を払う必要があることを意味します。
各オペレーティング システムには多数のアクセス方法があります。 特定の方法の選択は、オペレーティング システム、収集されたデータ セットの構成、および必要なバッファリング方法の選択によって異なります。

小さい 17.5。 (a) 単純なバッファリングでは、バッファがいっぱいになるまでプログラムが遅延します。 (b) 複数のバッファを使用することで、データ転送プログラムを確実に圧縮できます。
バッファ バッファは、周辺機器から入力された情報および周辺機器への出力のために準備された情報を収容するように設計されたメモリの領域です。 最も拡張されたオプションでは、バッファ アドレスは入力からすぐに指定されます。 入出力スーパーバイザーは、任意のデバイスからのブロックのエンドツーエンド入力をバッファーに配置します。 新しいソリューションを作成したい場合は、私たち自身がバッファーではなく別のバッファーについて知る必要があります。 データが準備されると、バッファ アドレスを使用して新しいファイルに書き込みが適用されます。 建物自体はシステムによって完全に形作られます。
図では、 図 17.6a は、入力が単一のバッファに定期的に入力されるときに取得されるステップのシーケンスを示しています。 コリストヴァッハのプログラムの紹介。 断片はすべて回転し、交換が完了するまで特派員のロボットプログラムは続行できず、スーパーバイザーは交換が完了するまで即座にそれを適用します。
ほとんどのデバイスでは、すべての I/O 操作を非常に高速に実行でき、プロセッサーはいつでも何千もの操作を実行できます。 したがって、バッファを 1 つも持たないビコリスタンでは、プログラムのビコナニーが大幅に増加します。 ただし、入出力のプロセス中、プロセッサーは他の操作をキャンセルできないと考える必要はありません。 ヤク・ミ・バチモ対ロスド。 17.4 では、EOM システム 360 および 370 では、プロセッサーと周辺デバイスの 1 時間の動作が可能です。 基本的なプログラムコマンドの入出力量についてお話します。
このような接続は、たとえば 2 つのバッファを使用した振動交換でうまく実行できます。 そのようなビコリスタンのお尻を図に示します。 17.5、6。 最終処理中に、スーパーバイザーは、ファイルに表示される順序で情報が入力されるように調整します。 このようにして、システムは実際に、ステップを「転送」することにより、注文がキャンセルされる前であってもバッファを保存できます。 実際、データの処理はクライアントのプログラムによって 1 回だけ実行されるため、システムはバッファを保存および解放でき、複数のバッファを選択することで、クライアントとの接続から発生するコストを最小限に抑えることができます。必要 出力入力操作もあります。 複数のバッファを使用すると、表示される情報の速度が向上します。
ただし、後続のデータ処理中に、いくつかのバッファーを選択すると、1 時間以内に成功する可能性があります。 これらのデータの処理は長いランダムなシーケンスで実行されるため、システムの「転送」と呼ばれる人々は意味を失います。
スキン オペレーティング システムは、さまざまなアクセス方法を提供します。 代替バッファに関連する最も豊富な電源を確保するためのプログラムの必要な部分の段階は、主にアクセス方法にあり、それが停滞します。 これらのアクセス方法により、オペレータはバッファについて心配する必要がなく、必要な作業をすべて自動的に完了できます。 他の状況では、バッファの使用はすべてオペレータの負担となる場合があります。 システムのサービスを使用してバッファを管理する前に、選択を支援する方法があります。
DOS システムにアクセスする方法。 ディスク オペレーティング システムのすべてのアクセス方法は自動的にバッファリングされます。 システムの機能を確保するには、プログラムの途中に 1 つまたは 2 つのバッファ領域を確保する必要があります。 ロボットが 2 つのバッファ領域で構成されている場合、最新のファイルを使用した作業時間中のすべての入出力操作は、実際の入力が削除されるまでシステムによって保存されます。 Koristuvach は、削除時のデータのブロックと、エントリ時のブロックの解除をブロックできます。 DOS システムには、データ セットを編成するための方法として、シーケンシャル、インデックスシーケンシャル、およびダイレクトがあります。 DOS システムの主なアクセス方法は次のとおりです。
シーケンシャル アクセス方式 (SAM)
索引順次アクセス方式 (ISAM)
ダイレクトアクセス方式(DAM)
表17.1 OSシステムへのアクセス方法
|
名前 |
ニーモニック |
|
|
キューシーケンシャルアクセス方式 |
一貫したデータの構成、書籍からのアクセス方法 |
|
|
基本的なシーケンシャルアクセス方法 |
一貫したデータ構成、基本的なアクセス方法 |
|
|
キューに登録されたインデックス順次アクセス方式 |
索引順編成ファイルの作成と逐次処理 |
|
|
基本的なインデックス付きシーケンシャルアクセス方法 |
インデックスシーケンスファイルの十分な処理 |
|
|
BasicPartitioned アクセス方式 |
ライブラリデータセットの作成と処理 |
|
|
基本ダイレクトアクセス方式 |
直接編成を使用したファイルの処理 |
|
|
電気通信アクセス方法 |
リモート端末との対話 |
OS システムにアクセスする方法。 OS オペレーティング システムのアクセス方法は、基本アクセス方法と基本アクセス方法の 2 つのクラスに分類されます。 アクセス方法を使用すると、自動バッファリングを確実に行うことができます。 システム自体がバッファ領域を維持します。 システムはレコードをブロックおよびブロック解除するように機能します。 順編成ファイルや索引順編成ファイルを処理する場合は、アクセス方法を見直す必要があります。 これらの方法により、オペレーターのプログラムの前に最小限の遅延で最大の処理効率を達成できます。
使用されるメソッドは基本的なものと似ており、アクセス方法は非常に原始的です。 ティムも同様です。悪臭により、データを使用してロボットのより大きな不潔さに到達することができます。 バッファリング管理の負担の一部はユーザーの責任となり、レコードのロックを解除するのもユーザーの責任となります。 基本的なアクセス方法は主に、データセットの処理に一貫性がない場合に右側に移動される場合に使用されます。 OS システムにアクセスするための最適な方法のリストを表に示します。 17.1.
私たちの意見では、データ構造とオペレーティング システムの機能、および入出力操作に関連する栄養にわずかに焦点を当てただけでした。 プログラムされた出入りのための合意されたアクセス方法を普及させるために利用できる資料はこれほど多くありません。 現在、OS および DOS システムからの最新のアクセス方法を使用しています。 私たちが検討している 2 つのシステムではシーケンシャル アクセス方式の原理が異なるという事実にもかかわらず、具体的な詳細は依然として大きく異なる傾向があります。 特定のシステムの入出力プログラミングに関連する資料を詳しくご覧ください。 ただし、この後、他のセクションを参照して、2 つのシステムを使用する際の同様の問題に慣れることができます。
処理は、情報の処理を伴う主要な操作の 1 つであり、それによって情報の複雑さと多様性が増大します。 テクノロジーの前者の反転の健康のために、形式化されたヴィグミを表現するために、ダニのヴィウッギアン構造(「情報Op'Kktіkt」)、本物のSvitの抽象的な断片のヤキє行為で。 抽象化(ラテン語から。抽象化 - 抽象化)は、権威とつながりの仕事の観点から最も詳細なビジョンを伝えます。 したがって、たとえば、成功しているように見せるために必要な生徒に関する情報は、ニックネーム、名前、最初のグループの番号などの一連の識別データによって表すことができます。 この場合、髪の成長や髪の色などの特定の特性はカバーされません。 情報処理とは、一部の「情報オブジェクト」(データ構造)を、特定のアルゴリズムを構築する他の方法から分離することです。 アルゴリズムは、アルゴリズムによって表される、viconati dii によって作成された抽象または現実の (技術、生物学、または生物工学) システムです。 特定のアルゴリズムに準拠した情報処理と計算のプロセスを機械化および自動化するには、機械式、電気式、電子式 (EOM)、油圧式、自然式、空気式、光学式、複合式など、さまざまなタイプの計算機が使用されます。 現代の情報科学では、アルゴリズムの主なコンポーネントは EOM であり、コンピューター (英語のコンピューターに由来) とも呼ばれます。 EOM は、アルゴリズムによる情報処理と計算のプロセスを自動化するために使用される電子デバイスです。 処理された情報の送信形式に応じて、コンピューティング マシンは 3 つの大きなクラスに分類されます。 ■ デジタル コンピューティング マシン (DCM)。デジタル形式で提示された情報を処理します。 ■ 情報を処理するアナログ コンピューティング マシン (AVM) は、あらゆる物理量 (電圧、電流など) の値が連続的に変化する形で表現されます。 ■ アナログ コンピューティング デバイスとデジタル コンピューティング デバイスの両方を組み合わせたハイブリッド コンピューティング マシン (HCM)。 AVM の機能はモデリングの原理に基づいています。 したがって、タスクの可変サイズが電子ランセットの同じ可変サイズに設定される場合、タスクの可変サイズは電子ランセットの同じ可変サイズに設定される。 この場合、そのようなモデルの基礎は、追跡タスクと対応する電子モデルの同型性 (類似性) です。 AVM は、その計算能力に応じて、複雑なロジックを必要としない差分計算を可能にする数学的タスクの実行に最適です。 デジタルコンピュータの精度はその能力によって決まりますが、コンピュータでの計算の精度は、要素ベースとメインユニットの準備の種類によって決まります。 同時に、クラス全体にとって、AVM 上でタスクを解決する速度はデジタル コンピューターよりも大幅に速い可能性があります。 これは、決定の結果がモデルのすべてのポイントで同時にリリースされる場合、AVM 上でタスクをリリースする並列原理によって説明されます。 この機能により、クローズド自動制御システムにおける AVM の効率が向上し、リアルタイム モードでの制御が最大化されます。 ハイブリッド コンピューティング マシンは、アナログ コンピューティング デバイスとデジタル コンピューティング デバイスの両方を組み合わせたもので、コンピューターとデジタル コンピューターの利点を兼ね備えています。 このようなマシンでは、デジタル デバイスは論理演算の実装と実行を目的としており、アナログ デバイスはより高い差動レベルを目的としています。 ただし、ほとんどのコンピューターはデジタルであることが重要であり、そのため「コンピューター」という言葉や「デジタル コンピューター」を意味する「EOM」という言葉が使われています。 このようなコンピュータでアナログ情報を処理するには、まずデジタル形式に変換します (セクション 6.2)。 実際のデータ処理システムとしての現在のコンピュータ (EOM) には、前のセクションで検討した抽象アルゴリズム システムであるチューリング マシン (MT) からの多数の別個の図が含まれています。 ■ MT モデルと同様に、EOM にはそのスキンアルゴリズムの実装と実装の基礎となる、順序付けられた非個人的なコマンド。 MT モデルと同様に、EOM は RAM に保存されたプログラム制御の下で個別に (戦術的に) 機能します。 ■ 指定された目的の EOM 制御装置は、MT モデル制御装置と同様です。 ただし、EOM は、非常に複雑な組織と幅広い大規模チームを備えた MT モデルに似ており、タスクを解決するためのさまざまなアルゴリズムを効果的に表現できます。 さらに、必要なタスクのためにメモリを増やす可能性を考慮すると、スキン EOM は MT のようにモデル化でき、潜在的に普遍的になります。 可能性は、すべての EOM が、十分な、多くの場合再帰的な関数の計算可能性の普遍的な意味を考慮することは不可能であるという事実によってさらに説明されます。つまり、それは、不変性の心にとって無関係なタスクの主要なクラスです (記憶の前)。 現代のコンピューターの基礎は、電子的および電気機械的な要素とデバイスのセットであるハードウェア (ハードウェア) によって作られており、コンピューター情報処理の原理は、処理アルゴリズムの形式化された記述であるコンピューター プログラム (ソフトウェア) にあります。処理プロセスをガイドする一連のコマンド。 コマンドは、任意の演算に対する計算システムの動作を示す二重コードです。 操作は、プログラム コマンドの 1 つに基づく情報に対する技術的プロセスの複合体です。 EOM 上の情報を処理するときの主な操作は、算術演算と論理演算です。 算術演算には、プログラムによって開発された、整数、分数、および浮動小数点数に対するあらゆる種類の数学演算が含まれます。 論理演算は、論理結果から論理値に対する演算を提供します。 コンピューティング システムでは、情報の処理を開始する一連のアクションをプロセスと呼びます。 したがって、エディタプログラムによる特定のテキストの処理はプロセスであり、プログラムの同じコピーが破損する場合のように、プログラムによる追加コストをかけて別のテキストを編集することは別のプロセスです。 プロセスはホスト プログラムによって定義され、プロセスの実装時に読み取り、書き込み、ウィキペダリングできるデータのセットであり、プロセスにハンドルが割り当てられます。これは、リソース EOM の観察されたプロセスのフロー プロセスを意味します。 。 プロセス記述子はレコードの全体であり、プロセスに割り当てられた EOM リソースの初期段階です。 計算システムとの koristuvach のスキン セッション (EOM へのデータの導入と表示など) もプロセスです。 コンピューティング システムの問題により、多数のプロセスが同時に実行されている可能性があります。これは、システムのメイン コンピューティング デバイスであるプロセッサよりも先に、何らかのリソースと水をめぐる競合が発生する可能性があることを意味します。 EOM。 これは、プロセス管理と計画を組織化する必要があることを意味します。 今日の EOM はオペレーティング システム (OS) の役割を担っています。OS には、プロセスの管理、リソースの配布、入出力の編成、およびコンピューターとのインターフェイスのための一連のプログラムが含まれています。 EOM における計算プロセスの構成の観点からは、次のような多くのモードが考えられます。 ■ 単一プログラム、単一コスト モード。計算は逐次的な性質を持ち、EOM リソースは共有されません。 ■ マルチタスク。多数のプログラムが独自のハードウェアおよびソフトウェア リソース EOM からプロセッサ時間を一貫して使用する場合。 ■ 個々のプロセッサがプロセッサ時間のクォンタム (間隔) を認識した場合、リソース (まずプロセッサ時間とメモリ) の配分が非常に複雑になった場合に、多数のユーザーに対する保険が適用されます。 ■ マルチプロセッサ。コンピューティング システムに多数のプロセッサが含まれている場合、リソースの分散が最も複雑な実際の並列プロセスを組み合わせることができます。 コンピューター上で情報処理タスクを選択すると、クライアントと EOM 間の対話のバッチ モードと対話型 (クエリ、ダイアログ) モードが表示されます。 現在、バッチ モードは、同じ種類の作業を行うために機械時間の非生産的なコストを削減するために使用されています。 その本質は次のものにあります。 コマンドは、独自のコンパイラを使用してパッケージにグループ化されます。 コンパイラはタスクを 1 回実行し、その後パッケージ内のすべての命令のブロードキャストを開始します。 パッケージのコンパイルが完了すると、正常に翻訳され、二重コード化されたすべてのタスクが順番にダウンロードされ、処理されます。 このモードは、異なるクラスが常に同じ計算リソースに依存し、1 か所 (情報計算センター) に集中していた EOM (集中処理) の集中交換時代の主要なモードでした。 EOM へのアクセスがなければ、計算プロセスの組織化が重要になるのは誰にとっても重要です。 その機能は、情報が相互接続された複合タスクの出力データの準備と処理センターへの送信に限定されており、EOM のタスクのパッケージが変形していました。 現在、バッチ モードとは、サーバーとの対話の可能性を持たずにコンピューターでタスクを処理するプロセスを指します。 この場合、原則として、タスクは会計担当者によって端末から入力され、すぐには処理されませんが、最初はタスク ボックスに配置され、その後、利用可能なリソースを使用して処理に進みます。 このモードは、多くの多重アクセス システムで実装されています。 インタラクティブ モードは、ユーザーと情報およびコンピューティング システム間の対話を直接伝え、要求 (通常は規制されている) の性質や EOM との対話も変更する可能性があります。 電源モードでは、顧客に EOM で 1 時間のスリープ時間を与えるという、厳密に確立された差別化された順序が可能になります。 対話モードでは、ユーザーが特定の作業率に許容できるペースで計算システムと直接対話できる能力が明らかになり、反復、取得、分析されるタスクを形成するサイクルが実装されます。 この場合、EOM 自体がダイアログを開始して、結果を決定するための一連のステップ (このメニュー) について通知します。 Koristuvach と EOM の相互協力体制を図に示します。 6.1. 相互作用は、システムと EOM 間の関連信号の送信を通じて発生します。 入力メッセージは、キーボード、マウス タイプのマニピュレータなどの追加の入力方法を使用してオペレータによって生成されます。 ユーザーによって生成される主な通知の種類は、情報の要求、支援の要求、操作または機能の要求、情報の入力または変更などです。 どのような行動が必要か、証人からの行動が必要となる修正に関する通知など。 6.1. EOMとの相互協力の組織 この体制は、コンピュータ情報処理システムの開発の現段階における主要なものであり、パーソナルコンピュータ(PC)の活動のほぼすべての分野で広く使用されていることを特徴としています - 単一システム これらはマイクロですアクセスしやすさと多用途性により、満足のいくサイズです。 現在、科学者はコンピューターサイエンスと計算技術の基礎について十分な知識を持っており、タスクを解決するためのアルゴリズムを分解し、データを入力し、結果を抽出し、その精度を評価します。 人には、代替オプションを扱い、特定の心の中で特定のシステムに最も適したオプションを分析して選択する本当の機会があります。 追加のコンピュータでタスクを実行する主な段階を図に示します。 6.2. 科学、技術、製造のさまざまな分野でパーソナル コンピュータを導入する実践から、コンピューティング テクノロジの開発における最大の効率は、PC ではなく、追加のチャネルを介して接続されたコンピュータと端末の全体である計算手段によって確保されることが示されています。分散データ処理の単一接続システム。 6.1.1.
入力
私は論文を書くにあたって「情報処理技術」というテーマを選びました。 このトピックは、保存、変革、伝達、回復の対象となる広大な世界に関する情報と情報を提供するため、最も関連性があると考えています。 人間の活動が情報の収集と処理のプロセスであっても、それに基づいて意思決定が行われ、意思決定が行われます。 現代のコンピューティング技術の出現により、情報は科学技術の進歩の最も重要なリソースの 1 つとして機能し始めました。
データ - この知識、信号、通知、通知、通知などの表現。 世界中のあらゆる人は、さまざまな種類の情報の海に囲まれています。
私の論文の目的は、送信形式での情報の処理原理、エンコードと保存の方法を研究することです。 そして、コンピュータサイエンスの基本概念である情報の概念を学ぶ必要があります。
プロセスを詳細に調査するには、ロボットをいくつかの段階に分割する必要があります。 まず、「情報処理」の概念を知り、次のことを学びます。 情報処理の目的、目的、種類。 情報を処理する方法。 情報処理スキーム。 現在の情報処理システム。 コンピュータの処理方法に関する問題。 非自動化されたデータのコンピュータ処理の改善。 情報処理の技術的プロセス つまり、データ処理の技術的方法の分類に従います。 その前に、トリビュートの処理モードが存在します。 データの処理方法。 情報を処理するための一連の技術的方法。 情報処理の技術的手段の分類
1. 情報処理
主要 情報の種類コンピューターサイエンスにとって最も重要なファイルの形式、エンコードと保存の方法は次のとおりです。
§ グラフィックとイメージクリエイティブ- 最初のタイプは、ロックベイビーの外観、およびその後の紙上の絵画、写真、図、椅子、キャンバス、マルマールなどの写真を描いた素材の外観における過剰な光に関する情報を保存する方法の実装のためのものです。現実世界。
§ 音- 私たちの周りの世界では、1877 年に録音装置が導入されたことで、音の発見とその保存と流通が始まりました。 これは別の種類の音楽情報です。この種類の場合、一連の記号の中に特殊記号をエンコードする方法を発見しました。これにより、同様のグラフィック情報を保存することが可能になります。
§ テキストの- 特殊文字 - 文字を使用して人々の言語をエンコードする方法。異なる人々は異なる言語を使用し、言語を表すために異なる文字のセットを使用できます。 この方法は、論文や医薬品の発売後に特に重要です。
§ 数値的- 世界のオブジェクトとさまざまな力の広い世界。 特に大きな重要性は、貿易、経済、ペニー為替の発展とともに生じました。 テキスト情報と同様に、vikoryst を表示する場合、特殊文字 (数字) を使用したエンコード方法と、エンコード (数値) システムが異なる場合があります。
§ ビデオ情報- 映画の公開に伴って出現した追加世界から「ライブ」ペインティングを保存する方法。
また、エンコードまたは保存する方法が見つかっていない種類の情報もあります。感覚によって伝達される触覚情報や、匂いや味によって伝達される感覚情報などです。
クロード シャノンは、高度な情報理論の創始者であり、デジタル コミュニケーションの創始者であると考えられています。 その世界的な人気は、1948 年の基本的な開発「コミュニケーションの数学理論」によってもたらされました。この理論では、情報を送信するために二重コードを使用する可能性が初めて導入されました。
異なる性質(物理的、経済的、生物学的など)のシステムにおける情報処理の法則の全体は、情報プロセス理論の基本的な基礎であり、これは情報プロセスが基本的に重要な存在と特異性であることを意味します。 この理論と情報の目的は、それが研究されている特定の知識分野に関連して「それ自体で」存在する抽象的な何かを理解することです。
日常生活における情報リソースは、物質的なリソースに劣らず、多くの場合それ以上の役割を果たします。 商品が誰に、いつ、どこで販売されるかを知ることで、商品のより低い価格と同じ価格を付けることができます。 これに関連して、情報処理方法が大きな役割を果たします。 ますます洗練されたコンピュータ、新しい手動プログラム、そして情報を保存、送信、保護する最新の方法が登場しています。
市場に関して言えば、情報は長い間商品となっており、この状況はビジネスのコンピュータ化の実践、産業、理論の集中的な発展を浮き彫りにしています。 情報媒体としてのコンピュータは、産業、科学、市場の組織において明確な傾向を発展させるだけでなく、コンピューティング技術、電気通信、ソフトウェア製品など、産業の新しい自己価値分野を明らかにします。
ビジネスのコンピュータ化の傾向は、コンピューティング技術に関連する新しい専門職やさまざまなカテゴリーのビジネスオーナーの出現に関連しています。 60 ~ 70 年代には、この分野はコンピューター エンジニア (電子工学およびソフトウェア エンジニア) によって支配されていたため、彼らはコンピューティング技術の新しい方法やアプリケーション プログラムの新しいパッケージを作成しており、今日では EOM 特派員のカテゴリーが集中的に拡大しています - 高度に専門化されたエンジニアの代表者彼らは大学レベルでコンピュータを使用し、特定のタスクを完了するためにコンピュータを使用します。
図1.1 情報処理サイクル
EOM マネージャーは、コンピューター環境で情報プロセスを組織する基本原則を理解し、必要な情報システムと技術的特徴を選択し、それらを迅速に習得する必要があります。x 完全に独自の主題領域に属します。
1.1 情報処理の目的、目的および種類
情報プロセス(情報の収集、処理、送信)は、科学、技術、家庭生活において常に重要な役割を果たしてきました。 人類の進化の結果、内部の変化は永続的に変化していませんが、これらのプロセスは自動化される傾向が強いです。
情報の収集- これは被験者の活動であり、その間に被験者は収集されているオブジェクトに関する情報を取得します。
情報の収集は、人間によって行うことも、技術的な機能やシステム (ハードウェア) を利用して行うこともできます。 たとえば、特派員は、電車や飛行機の流れに関する情報を、時刻表を読んで自分で入手したり、他の人から直接、あるいは人が編集した文書を通じて、または追加の技術的手段(自動確認や電話も)を通じて入手できます。 情報を収集するというタスクは、他のタスク、制約、情報を交換する(転送)というタスクよりも優れているわけではありません。
情報交換- これは、ホストによって情報が送受信されるプロセスです。
送信された通知でエラーが検出された場合、この情報の再送信が計画されます。 デバイスとその所有者の間で情報が交換されると、理想的にはデバイスと同じ情報を保持する、ある種の「情報バランス」が確立されます。
情報の交換は追加の信号を使用して行われ、これも物質的なものです。 情報の断片は、権力や富の歌など、現実世界のあらゆるオブジェクトにすることができます。 物体が無生物の自然と接触すると、その権威を即座に落胆させる信号が生成されます。 オブジェクトデバイスは人であるため、その人が発する信号はその人の力を直接表すだけでなく、情報の交換を通じて人が発する信号にも似ている可能性があります。
盗まれた情報は複数回悪用される可能性があります。 このように、それらを有形媒体 (磁気、写真、フィルムなど) に固定するのはユーザーの責任です。
情報の蓄積- これは、体系化されていない情報の出力を形成するプロセスです。
記録された信号の中には、侵害されることが多い貴重な情報を表示するものもあります。 将来的に必要になる可能性があっても、現時点では特に価値のない情報もあるかもしれません。
情報の保存- これは、ビュー内の出力情報をサポートするプロセスであり、インストール端末のエンドデバイスへのデータの出力を保証します。
処理情報- 注文後の変換プロセスは、問題を解決するためのアルゴリズムと一致しています。
情報の処理が完了すると、結果が必要な形式でエンド ユーザーに表示されます。 この操作は、最新の情報が入手可能になり次第実行されます。 情報の提示は、テキスト、表、グラフなどの追加の外部 EOM デバイスを使用して実行されます。
情報の力。
情報は物体として力を持ちます。 自然や繁栄の他の物体からの情報の特徴は二元論です。つまり、情報の力は、代替部品となる出力データの力と、この情報を記録するあらゆる方法を使用する力のように流れます。
コンピューターサイエンスの観点から見ると、最も重要なのは次のような曖昧で明確な力であると思われます: 客観性、信頼性、完全性、正確性、関連性、心地よさ、価値、関連性、洞察の可用性、アクセシビリティ、一貫性など。
情報の客観性 。 目的 - 人間の知識に関係なく、基本的な立場。 情報は外部の物体光の反射です。 情報は固定、思考、判断の方法にあるため、客観的です。
お尻。 「外は暖かいです」というメッセージには主観的な情報が含まれますが、「路上では 22 ℃ です」というメッセージは客観的ですが正確であり、個人の死を避けるためのものです。
振動デバイスのリファレンスセンサーを利用して客観的な情報を取得できます。 人々の知識に基づいた情報は、特定の主題に関する思考、判断、情報、知識に応じて(少なくとも程度は低いですが)矛盾する可能性があり、したがって客観的ではなくなります。
信頼性 情報 。 現在の参考状況を示しているため、情報は信頼できます。 客観的な情報は常に信頼できますが、信頼できる情報には客観的な情報と主観的な情報の両方が含まれる場合があります。 信頼できる情報は、正しい決定を下すのに役立ちます。 不正確な情報には、次のような理由が考えられます。
§ 自発的に作成された(偽情報)、または意図せずに作成された主観的な力。
§ コード転送の流入 (「zip 電話」) と正確な修正方法の欠如の問題。
情報の完全性 。 理解して意思決定を行うのに十分であれば、情報は完全であると言えます。 情報が間違っていると、和解や決定が下される可能性があります。
情報の正確性 オブジェクト、プロセス、現象などの実際の状態への近さの度合いによって示されます。
情報の関連性 - 今日の重要性、話題性、緊急性。 常に削除される情報は赤色になる場合があります。
情報の価値(価値) 。 協調性は、特定の仲間のニーズに基づいて評価でき、その助けを借りて達成できるタスクに基づいて評価されます。
最も価値のある情報は、客観的で信頼性があり、最新のものです。 客観的で信頼性の低い情報(フィクションなど)は人々にとって非常に重要だからです。 ソーシャル (社会) 情報には追加の力があります。
§ は意味論的 (意味のある) 性質を持っています。 概念自体が、より広い世界でのオブジェクト、プロセス、発現の実際の兆候を認識するため、概念的です。
§ 自然のものである可能性があります (創造的な芸術など、さまざまな種類の美的情報を除く)。 まったく同じ場所を、異なる自然な(形式的な)言葉で表現したり、数式などの形式で記述したりすることができます。
時間の経過とともに、情報の量は増加し、情報が蓄積され、体系化され、評価され、文書化されます。 この力を情報の成長と蓄積と呼びました。 (Cumulation - ラテン語のcumulatioから - 増加、買い占め)。
古い情報は時間の経過とともに価値が変化する傾向があります。 情報が古くなるのに時間はかかりませんが、新しい情報が現れるのに時間がかかり、明確化、追加、追加が行われ、多くの場合は早い段階で行われます。 科学的および技術的な情報は古く、より審美的であり(謎を生み出す)、より高度です。
論理性、コンパクトさ、マニュアル形式のプレゼンテーションにより、情報の理解と吸収が容易になります。
情報処理の概念はさらに広いです。 情報処理について話すとき、処理不変条件を理解する必要があります。 これを通知の場所 (連絡先から入手できる情報の場所) と呼びます。 情報の処理を自動化する場合、処理の対象を通知し、変換の不変量が処理された情報の不変量に対応するように処理を実行することが重要です。
情報の処理方法は、情報処理の分析に関連したオペレーティング システムの機能方法によって決定されます。 この目標を達成するには、まず相互に依存する一連のタスクを完了する必要があります。
例えば、情報処理の初期段階は受信である。 さまざまな情報システムにおいて、受信は、情報の選択(科学技術情報システム)、物理量の視覚信号への変換(情報システム)、自然システム)、耐久性などの特定のプロセスで明らかにされます。 しかしどうやら(生物学的システムでも)そうです。
この間に受信プロセスが始まり、外部からの情報システムが強化されます。 ここの境界では、外界からの信号が、さらなる処理のために手動で処理できる形式に変換されます。 生物学的システムと自動機械などの豊富な技術システムの場合、何を読み取るべきかというと、この違いが最も明確に表現されているということです。 他の場合には、大きな安心感と水の流れが得られます。 受信プロセスの内部境界については、常に精神的なものであり、情報プロセスに従いやすいため、個々の条件に応じて選択されます。
内部境界がどれほど「深く」挿入されたとしても、受信は分類プロセスと見なすことができることに注意してください。
情報処理モデルが定式化されている
ここで、独自の形式化された処理モデルを持つさまざまな倉庫情報プロセスとの情報処理プロセスに類似点と相違点がある点に戻りましょう。 事前に、情報の意味論的および実用的側面から、このフィードを(受信者に)受信した情報と区別することは不可能であることを考慮します。 通知 (シグナル) が割り当てられている受信者の存在は、通知とそれに含まれる情報との間に明確な関係があることを意味します。 同じ情報でも、宛先が異なれば異なる意味を持ち、実際的な意味も異なる可能性があることは完全に明白です。
・情報処理の過程における秘密の仕組み。
· 処理タスクのステートメント。
・ヴィコナヴェツ・オブロブキ。
· 処理アルゴリズム。
· 典型的な情報処理タスク。
1.2 情報処理方法
情報を処理する方法はありませんが、ほとんどの場合、テキスト、数値、グラフィック データを処理することになります。
文字情報の処理
テキスト情報はさまざまな要素から発生する可能性があるため、表現形式の背後にある複雑さのレベルが異なります。 さまざまな情報技術を使用してテキスト通知を処理するには、送信フォームに従ってください。 ほとんどの場合、テキスト エディタまたはプロセッサは、テキスト電子情報を処理するツールとして使用されます。 これらは、テキスト情報を作成、処理、保存するために設計された特別な機能をユーザーに提供するソフトウェア製品を表します。 テキスト エディターとプロセッサーは、さまざまな種類の情報を編集、編集、処理するために使用されます。 プロセッサーとしてのテキスト エディターの重要性は、まずエディターが同じ種類の情報 (テキスト、数式など) のみを処理し、プロセッサーを使用すると他の種類の情報を処理できることです。
テキストの作成に使用されるエディタは、プライマリ エディタ (シートやその他の単純なドキュメントの作成) とフォールディング エディタ (グラフや小さなドキュメントなど、さまざまなフォントを使用したドキュメントの作成) に分けることができます。 テキストの自動化作業に使用されるエディタは、単純なもの、統合されたもの、ハイパーテキスト エディタ、テキスト検索システム、科学テキスト エディタ、植字システムなど、いくつかのタイプに分類できます。
最も単純なフォーマッタ エディタ (メモ帳など) では、テキストの内部表現に追加のコードは使用されません。通常、テキストは ASCII コード テーブルの文字に基づいて形成されます。 テキスト プロセッサには、テキスト作成システム (ワード プロセッサ) が備わっています。 その中で最も人気のあるのは MS Word プログラムです。
このようなプログラムを使用してテキスト情報を処理する技術には、次の段階が含まれます。
) テキスト情報を保存するファイルを作成します。
) 電子形式で送信されたテキストを保存する。
) テキスト情報を保存するファイルを開く。
)電子テキスト情報の編集。
) 電子形式で保存されるテキストの書式設定。
) テキスト ファイルからの入力に基づいたテキスト ファイルの作成
デザインスタイルエディター。
)テキストの置換とアルファベットガイドの自動形成。
) 自動スペルチェックと文法チェック。
) テキストへのさまざまな要素やオブジェクトの挿入。
)文書コレクション。
) ドゥルクのテキスト。
主な操作の前に、編集には以下が含まれます。 先見の明のある; 変位; フラグメントをテキストにコピーするだけでなく、検索や文脈の置換も可能です。 テキストによってリッチなドキュメントが作成されるため、ページまたはセクションの書式設定を変更できます。 この場合、テキストにはブックマーク、ワインバー、クロスワード、フッターなどの構造要素が含まれます。
ほとんどのワード プロセッサは、折り畳まれたドキュメント (さまざまなオブジェクトを含むコンテナ) の概念をサポートしています。 これを使用すると、小さなドキュメント、表、グラフィック イメージ、その他のソフトウェア コンポーネントをドキュメントのテキストに挿入できます。 ヴィコリストゥヴァナ アット ツォム 物体の結合と増殖の技術呼ばれた OLE(オブジェクトのリンクと埋め込み – オブジェクトのリンクと転送)。
テキスト プロセッサで頻繁に繰り返されるプロセスを自動化するには、マクロ コマンドを使用します。 最も単純なマクロ - キーを押し、マウスを動かし、クリックするシーケンスが記録されます。 テープ録音と解釈できます。 標準マクロコマンドを追加することで処理および変更できます。
あるテキスト エディタから別のテキスト エディタへのテキストの転送は、プログラムによって行われます。 コンバータ。 出力ファイルは適切な形式で作成します。 テキスト処理プログラムには、一般的なファイル形式を変換するモジュールが含まれていることに注意してください。
テキストプロセッサの種類 デスクトップ表示システム。 印刷のルールに沿った資料をご用意いただけます。 デスクトップ パブリッシング システム (Publishing、PageMaker など) のプログラムと、レイアウト デザイナー、デザイナー、テクニカル エディター用のツール。 このヘルプを使用すると、ページの形式や番号、インデントのサイズを簡単に変更したり、異なるフォントを組み合わせたりすることができます。 印刷製品には大量の悪臭が伴います。
表形式データの処理
仕事の過程にある労働者は、計画の策定や組織のリソースの配分、科学研究の完了に伴い、会計帳簿、銀行口座、口座、記録を作成および維持する過程で、表形式のデータにアクセスすることがよくあります。 この種の作業の自動化が進むにつれ、表形式で表示される情報処理用の専用ソフトウェアが登場しました。 これらのソフトウェア機能は次のように呼ばれます。 テーブルプロセッサそれとも 電子テーブル。このようなプログラムを使用すると、テーブルを作成し、表形式データの処理を自動化できます。
電子スプレッドシートは効果的であることが証明されており、統計データの分類と処理、最適化、予測などのタスクが増加しています。 これらは、開発の定義を作成し、意思決定を促進し、実質的にすべての活動分野で結果をモデル化し、提示するのに役立ちます。 表形式のデータを扱う場合、コンサルタントは次のようないくつかの標準的な手順を使用します。
) テーブルを作成および編集します。
)テーブルファイルの作成(保存)。
) テーブルにデータを入力および編集する。
) さまざまな要素とオブジェクトのテーブルへの挿入。
) シート、書式設定、およびリンク テーブルの選択。
) 数式と数式を使用した表形式データの処理
特別な機能。
) 毎日の図表とグラフ。
) データの処理、リストからの提出。
)データの分析処理。
) その前にある他の表と図。
テーブルの構造には、番号付きのテーマ見出し、ヘッド (ヘッダー)、サイドバー (行見出しを含むテーブルの最初の列)、およびサブグラフ (テーブル データの下) が含まれます。
最も人気のあるスプレッドシート プロセッサは MS Excel プログラムです。 ボーンは、koristuvach に一連の作業用アーチ (側面) を提示し、それぞれを使用して 1 つのテーブルを作成できます。
ワークシートには、真っ直ぐな塊を作成するための一連の中間部分が含まれています。 それらの座標は、垂直方向 (列単位) と水平方向 (行単位) の位置を指定することによって示されます。 Arkoosh は、最大 256 行、最大 65536 行を収容できます。 行はラテンアルファベットの文字 (A、B、C... Z、AA、AB、AC... AZ、BA、BB...) で指定され、行は数字で指定されます。 したがって、たとえば、「D14」は 14 行目の「D」列の十字線にある中央を意味し、「CD99」は 99 行目の「CD」列の十字線にある中央を意味します。行。 作業者の名前は常に作業アーチの一番上の行に表示され、行番号は左端に表示されます。
スプレッドシート オブジェクトには、編集、グループへの参加、削除、クリア、挿入、コピーといった操作が割り当てられています。 フラグメントを移動する操作は、その後の削除と挿入の操作の完了に短縮されます。
計算を容易にするために、数学的、統計的、財務的、論理的およびその他の関数がテーブル プロセッサに導入されています。 テーブルに入力された数値は、さまざまな 2 次元、3 次元、および混合図 (20 以上のタイプとサブタイプ) に分類できます。
テーブル プロセッサはデータベース関数をラップできます。 この場合、テーブルはデータベースと同じ方法で画面フォームから入力されます。 それらのデータは盗まれたり、キーまたはキーの数によって並べ替えられたりする可能性があります。 これには、データベースへのクエリの処理、外部データベースの処理、テーブルの作成などが含まれます。 マクロ コマンドにプログラミング言語を使用することもできます。
テーブルの重要な機能は、その式と関数を使用できることです。 式はコンピュータのテーブルに送信したり、別の作業台やテーブルなどに広げたり、別のファイルに置いたりすることができます。 Excel には、関数と呼ばれるプログラムされた数式が 200 以上用意されています。 ナビゲートしやすいように、機能はカテゴリに分類されています。 「関数マスター」を使用すると、プロセスのどの段階でも関数を定式化できます。
Excel スプレッドシート エディター、Word テキスト エディター、および Office アプリケーション パッケージ (APP) に含まれるその他のプログラムは、OLE データ交換標準をサポートしており、「リスト」を使用することで、大規模で均一なデータ セットを効果的に操作できるようになります。 同様の OLE メカニズムが他のソフトウェア アプリケーションでも使用されています。
Excel では、さまざまな経済データや統計データを効率的に処理できます。
グラフィック情報の処理
グラフィック情報 パソコンのモニター画面に点が現れます。
グラフィックス モードでは、モニター画面は点灯するドットの集合、つまりピクセル (「ピクセル」、英語では「絵素」) を表します。 画面上の合計ポイント数は次のように呼ばれます。 モニターの別パーツ、これはこのタイプのロボット モードにも当てはまります。 サイズの 1 単位は、1 インチあたりのドット数 (dpi) です。 現在のディスプレイの間隔は、水平方向に 1280 ピクセル、垂直方向に 1024 ピクセルです。 1310720ピクセル。
表示される色の数は、ビデオ アダプターとディスプレイの機能によって異なります。 プログラムで変更できます。 肌の色は画面上の点の 1 つです。 カラー画像には、16、256、65536 (ハイ カラー) および 16777216 色 (トゥルー カラー) のモードがあります。
コンピュータ上にあるかどうかにかかわらず、画像は単一のグラフィック要素を形成する一連のグラフィック プリミティブで構成されます。 プリミティブには、英数字またはその他の記号を使用できます。
1.3 情報処理の仕組み
出力情報 – 最終処理 – 包含可能な情報。
情報処理のプロセスでは、伝統的な形式で最初に課せられる情報タスクがあります。つまり、特定の出力データのセットが与えられた場合、同じ結果を抽出する必要があります。 出力データから結果に移行するプロセス自体が処理プロセスです。 処理を実行するオブジェクトまたはサブジェクトは、ヴィコナヴィアン サンプルと呼ばれます。
世界中の情報 (人またはデバイス) を適切に処理するには、処理アルゴリズムが必要になる場合があります。 望ましい結果を達成するために従う必要がある一連のアクション。
情報処理には2種類あります。 1 つ目のタイプの処理: 新しい情報、新しい知識 (新しい数学的タスク、状況分析など) の抽出に関連する処理。 別の種類の編集: 形式の変更を伴うが、場所は変更しない編集 (たとえば、テキストをある言語から別の言語に翻訳する)。
情報を処理する重要な方法は、 コーディング- 保存、転送、処理のために手動で情報を記号形式に変換します。 コーディングは、情報 (電信、ラジオ、コンピューター) を扱う技術的な方法で積極的に研究されています。 別のタイプの情報処理 - 構造バスデータ(情報を保存するための適切な順序の入力、分類、データのカタログ化)。
別のタイプの情報処理 - 検索必要なデータの情報を持っている人もおり、若者の頭の中で検索(疑問)が生じます。 検索アルゴリズムは情報を整理する方法にあります。

Malyunok 1.3.1 情報処理スキーム
1.4 現在の情報処理システム
p align="justify"> 技術プロセスを設計するとき、私たちはその実装モードに焦点を当てます。 テクノロジーの実装モードは、リリースされるタスクの量と時間の特性、つまり処理速度に合わせて更新できる頻度と用語、および EOM に先立つ技術スタッフと私たちの運用能力によって決まります。 。
設定: バッチモード。 リアルスケールモード。 30分モード。 規制体制。 尋ねる; 対話; テレビ上映; 相互の作用; 単一プログラム。 豊富にプログラムされています(複数の問題)。
金融および信用システムの投資家にとって、最も関連性のあるものは、現在のものです。 モード: バッチ、ダイアログ、リアルタイム モード。
バッチモードこの体制では、koristuvach は EOM と直接的な関係を持ちません。 情報の収集と登録、入力と処理には1時間もかかりません。 今後、オペレーターは情報を収集し、それを整然としたパッケージまたはその他の兆候にまとめます。 (原則として、これは、決定の結果を表す適切な用語を持つ非操作可能なキャラクターです)。 受信した情報が完了してから処理を行うため、処理が遅れてしまう。 このモードは、集中型の情報処理方法に基づいています。
ダイアログモード(電源)モードいずれの場合でも、オペレーターは作業中に計算システムと直接対話することが可能です。 EOM は 1 時間ごとに、または EOM が一般に公開されている場合は短期間だけ利用できるため、データ処理プログラムは徐々に EOM のメモリに組み込まれます。 対話の形でのコリストヴァッハと計算システムとの相互作用は多次元的であり、さまざまな要因によって決定されます。 対話の開始者は誰ですか – コリストヴァッハまたは EOM。 時々; 会話の構造も。 対話の開始者がオペレーターである場合、母親は作業手順、データ形式などについてのオペレーターの知識に責任があります。 イニシエーターは EOM であるため、マシン自体がさまざまな選択肢を扱う必要があることを脳に通知します。 この方法を「メニュー選択」といいます。 彼は教師の行動を支持し、一貫して罰します。 この場合、必要な準備は少なくなります。
対話モードでは、オペレーターの最高レベルの技術的装備が必要です。 通信チャネルによって中央計算システムに接続された端末または PEOM の存在。 このモードは、情報、コンピューティング、およびソフトウェア リソースにアクセスするために使用されます。 ダイアログ モードでの作業能力は、作業の開始から終了までの時間に制限される場合もあれば、制限されない場合もあります。
リアルタイムスケールモードこれは、制御された化学プロセスと同じ速度で相互作用するための計算システムの存在を意味します。 EOM の反応時間は、制御されたプロセスのペースを満たすことができ、中断を最小限に抑えることができます。 原則として、このモードはデータ処理が分散化および分散される場合に使用されます。 例: オペレーターのデスクトップに PC がインストールされ、操作に関するすべての情報が世界中の EOM に入力されます。
これらはさまざまです データの処理方法:
集中型、分散型、分散型、統合型。
集中化 VCの存在を伝えます。 この方法では、通信相手は出力情報をコンピュータセンターに納品し、処理結果を有効な文書の形で保管します。 この処理方法の特徴は、スムーズで中断のない接続を確立することの複雑さと難しさ、(大きな義務のための)VC 情報の非常に重要性、財務業務条件の規制、可能性からシステムを保護しない組織です。不正アクセス。
分散型 オブロブカこの方法は PEOM の出現に関連しており、特定の作業領域を自動化することが可能になります。 現在、分散データ処理には 3 種類の技術があります。
Persha はパーソナル コンピュータ上で実行されますが、ローカル ネットワークには統合されません。 (データは別のファイルと別のディスクに保存されます)。 表示を削除するには、コンピュータに情報を書き換えてください。 欠点: 相互に関連するタスクの数、大量の情報を処理できないこと、不正アクセスのレベルが低いこと。
その他: PC はローカル ネットワークに統合されているため、統合されたデータ ファイルが作成されます (多くの情報の無駄が回避されます)。
3 番目: ローカル ネットワークに統合された PC。その中には特殊なサーバーが含まれます (「クライアント/サーバー」モード)。
部門 これらの根拠を、制限の前に含まれる異なる EOM 間の処理機能の細分化に基づいて処理する方法。 この方法は 2 つの方法で実装できます。 1 つ目は、EOM インストールをネットワークのスキン ノード (またはシステムのスキン レベル) に転送します。そこでは、実際の機能に従って 1 つまたは複数の EOM ノードでデータ処理が行われます。それが現時点で必要とされているものです。 もう 1 つの方法は、1 つのシステムの中央に多数の異なるプロセッサを配置することです。 このようなパスは、ある程度のデータ処理が必要な銀行および財務情報を処理するシステム (支店、支店など) に見られます。 分割法の利点: 指定されたデータから任意の項を取得できること。 ある技術的特徴が特定された場合、それを別の技術的特徴に即座に置き換えることができるという事実による、高いレベルの信頼性。 貢物の移送に必要な時間が短い。 システムの柔軟性の向上、ソフトウェアの開発と運用の簡素化など。 したがって、分割方式は特殊なプロセッサの複合体にあります。 EOM のスキンは、歌うコマンドや仲間のコマンドを最高のパフォーマンスで発揮することを目的としています。
データを処理する最良の方法は、 統合 。 作成したセラミックオブジェクトの情報モデルを転送し、分散データベースを作成します。 この方法により、オペレータの利便性が最大限に高まります。 一方で、データベースは集団ガバナンスと集中管理に移行されます。 一方、情報を取得する目的では、関与するタスクが多様であるため、データベースのさまざまな部分が必要になります。 統合情報処理技術は、EOMに一度入力された単一の情報配列に基づいて処理が行われるため、処理の精度、信頼性、流動性を向上させることができます。 この方法の特徴は、データの収集、準備、入力の手順から技術的に分離されており、時間のかかる処理手順であることです。
現在の情報処理システムは、紙データや自動化されたワークステーション技術間でデータを交換するデジタル技術に依存しており、スピブロビットグループの共同部隊の統合も可能にしている。 )、意見交換 Vリアルタイムでのあらゆる食品を含む交渉(電話会議)、電子メール、電子メールボックスなどによる迅速な資料の交換。 このようなシステムについては、「企業業務プロセス管理システム」という用語を拡張して、業務全体をサポートする必要があります。 このようなシステムは、グローバル インターネット ネットワークを介したリモート クライアントの接続など、「クライアント/サーバー」テクノロジの使用を特徴としています。 さまざまな国や大陸にあるグローバルな情報空間に 40,000 人以上のユーザーを統合するシステムは珍しくありません。 そのようなアプリケーションの 1 つとして、ウクライナを含む世界中に支店を展開するマクドナルド社が考えられます。
1.5 コンピュータの処理方法に伴う問題点
パソコンをワークステーションに設置し、ローカルで接続するだけでは、元の情報構造が完全に変わるわけではないため、経営に良い影響を与えるとは考えにくい。 時代遅れの作業方法を自動化することは不可能ですが、パソコンを新しい論文を高速に作成するためのツールに変えることはできます。 したがって、米国の企業の業務分析の結果は、企業のリスト倉庫へのタイムサービスを可能にするために、以下を含む 43 の異なる文書、合計 113 ページが作成された状況を説明しています。必要なコピー。 これは、情報システムがサブユニットと他のサービスとの間の接続 (通信) を確立しているためです。 さらに、企業が正常に機能するためには、20 ~ 30 件を超える内部コミュニケーションは必要ありませんが、実際には 3 ~ 4 倍以上の内部コミュニケーションが必要です。 さらに、ビジネス管理の自動化の実践は、生産性の高いコンピューター機器の確立により、コピーとその配布の「あらゆる問題」を管理するための通信量の増加につながる可能性があることを示しています。 コンピューター技術の生産におけるこの段階は、すべての通信 (通信) を最適なレベルまで高速化することによって達成できます。
最も広く蔓延している問題の 1 つは、コンピューターの明らかな能力の帰属です。 パーソナル コンピューターは、どれほど高価で生産性が高くても、単なる治療機械に過ぎません。複雑な経済問題を解決することはできず、私たち自身も目標を正しく立てることができないからです。
また、非常に重要なのは、コンピューター技術の導入直後にチームが抱えている社会心理学的問題であり、その結果、軍人の数が減少し、活動に対する管理が強化され(したがって強化され)、他のコロナウイルス患者も同様に増えます。
コンピュータ化は、会計技術と政府活動の分析技術を根本的に変えます。 非自動会計システムでは、政府取引に関するデータの処理が簡単に簡素化されるため、紙の文書、命令、譲渡、記録、地域ジャーナルなどの地域登録簿などの情報が伴います。 同様の文書はコンピューター システムに保存されることがよくありますが、多くの場合、電子形式でのみ見つかります。 さらに、会計コンピュータシステムの主要な会計書類(会計帳簿や仕訳帳)にはデータファイルが含まれており、コンピュータなしでは読み取りや変更が不可能です。
p align="justify"> コンピュータ技術は、インテリジェンスと制御手順を評価する際に考慮する必要がある多くの機能によって特徴付けられます。
.6 コンピュータデータ処理と非自動化データ処理の特徴
単一の操作。コンピュータ処理は、同一の操作の実行中に一連の同じコマンドを会計部門に送信します。これには、権力側のエラーを含むランダムなエラーの出現も含まれます。
手動カット。 ただし、ソフトウェアの修正 (およびハードウェアとソフトウェアのその他の体系的な修正) は、新しい知識を持つすべての同一の操作の誤った処理につながります。
サブ機能。 p align="justify"> 自動化されていないシステムではさまざまな改ざんが行われるため、コンピュータ システムでは個人的なものではない内部管理手順を作成できます。 この状況により、コンピュータにアクセスできる最前線の従業員は他の機能を実行できなくなります。 その結果、コンピュータ システムは追加の入力を導入して、必要なレベルでの制御をサポートできます。非自動化システムでは、これは単純なサブ機能によって実現されます。 このようなログインの前に、対話モードの端末を介して資産およびクラウド文書に関する情報にアクセスできるファクシミリエージェント側で受け入れられないアクションを防止するために、パスワードシステムが導入される場合があります。
不正確さにより潜在的な可能性が現れました。非自動会計システムと比較して、コンピュータ システムは、制御機能を含む不正アクセスの影響を受けやすくなっています。 また、データの変更や資産に関する情報の直接的または間接的な削除にも対応します。 操作の機械処理に関与する人が少なくなるほど、間違いや不正確さを特定する可能性が低くなります。 アプリケーションプログラムの開発または調整中に行われた申請は、試用期間中に不当に遅れる可能性があります。
行政側からのコントロールが強化される可能性。コンピュータ システムは管理者に幅広い分析機能を提供し、会社の活動を評価および管理できるようにします。 追加のツールを利用できると、内部管理システムが確実に改善され、その結果、内部管理システムが無効になるリスクが軽減されます。 したがって、支出係数の実際の値と計画された値との通常の比較の結果、および計算の計算は、通常、管理前に情報のコンピュータ処理中に実行されます。 さらに、特定のアプリケーション プログラムは、コンピュータの動作に関する統計情報を蓄積し、会計取引の実際の進行状況を制御するために使用できます。
コンピュータ操作の開始。コンピュータシステムは特定の取引を自動的に記録することができ、自動化されていない会計システムの場合のように、その承認は必ずしも文書化される必要はありません。これは、管理者がそのようなシステムを運用するという事実自体が暗黙の方法で自明性を伝えるためです。対応する制裁の内容。
このように、会計システムを維持する際の政府取引の処理方法は、企業の組織構造や内部統制の手順や方法に大きな影響を与えます。 会計士の役割と行政との関わりは明らかに変化しています。 自動化に反対して、会計士の仕事はウクライナ人の心の中で特定の人々を惹きつけています。たとえば、1つずつ印刷する必要がある大量の文書があります。
1.7 情報処理の技術プロセス
データ処理、情報、知識から必要な結果が得られるまでの順序付けられた一連のアクション。 その結果、IT の理解は、さまざまなアルゴリズムや個人を介して情報を処理する、これらのタスクの成長に必要なタスクを収集するための低レベルの操作の選択に関連する経済的タスクや管理タスクを解決するために重要であることがわかりました。新しいフォームについて手動で決定を下す人。
情報処理の技術的プロセスは、関連するタスクの性質、使用される技術的機能、制御システム、従業員の数、およびその他の要因によって異なります。 情報処理の技術的プロセスには、次の操作が含まれる場合があります。
データ、情報、知識の収集 - アイデア、オブジェクト(現実および抽象)、接続、記号およびその他のものに関する詳細情報(データ、知識)の登録、固定、記録のプロセスです。 この場合、業務範囲には「データや情報の収集」と「知識の収集」が見られます。 データと情報の収集は、さまざまな要素からデータを識別して分離し、分離したデータをグループ化し、EOM への入力に必要なフォームに送信するプロセスです。 知識の収集 - 調査員や専門家から対象分野に関する情報を抽出し、知識ベースに記録するために必要な形式で送信します。
データ、情報、知識の処理。 処理は広い概念であり、相互に関連する多数の操作が含まれます。 処理とは、データを処理する体系的なプロセスであり、あらゆる形式のデータや情報を計算、分析、合成する変換のプロセスであることを忘れないでください。 その知識は、体系的に操作を実行するのに役立ちます。 このような操作を行うと、データ処理、情報処理、知識処理といった処理が見られます。 データ処理とは、データ (数字、記号、文字) を管理し、その情報を変換するプロセスです。 情報処理とは、ある種類の情報 (テキスト、音声、グラフィック) を処理して、別の種類の情報に変換することです。
しかし、最新の新しいテクノロジーを使用すると、あらゆる種類の情報 (テキスト、グラフィックス、オーディオ、ビデオ、アニメーション) の包括的なプレゼンテーションと即時処理、および変換が保証されます。 知識の処理の概念は、ユーザーが状況を認識し、診断を行い、解決策を策定し、ルールと事実に基づいて推奨事項を作成できるようにするエキスパート システム (または人工知能のシステム) の概念に関連しています。行動は慎重に。
データ、情報、知識の生成とは、データ (情報、知識) を整理、再編成し、方法や処理を含む必要な形式に変換するプロセスです。 たとえば、フォーマットされたドキュメント (ドキュメント) を削除するプロセスです。
データ、情報、知識の保存 - データ(情報、知識)をさらに回復(処理および送信)するために蓄積、配置、抽出およびコピーするプロセス。
ダニ、情報、知識の転送 - ダニ (情報、知識) のプロセス、コモニカティ トム (重複) の TA システムのプレハットのための Koristuvachiv の中間、ダニ ヴィッド ジェレル (ヴィジュヴァチ)。
2. ミニハンドブック「オペレーティングシステムのアップデート」の開発
2.1 DJVU から PDF へのテキストの変換
DjVu から PDF にドキュメントを変換するにはどうすればよいですか? DjVu は、印刷ドキュメント、書籍、定期刊行物を電子的に表示するための最も高度な形式の 1 つです。 Universal Document Conveter ツールを使用すると、DjVu から PDF へのドキュメントの最適な変換を実行できます。
-
Internet Explorer で DjVu ファイルを開き、プラグイン ツールバーの [印刷] ボタンをクリックします。

小さい 2.1.1 Internet Explorer でのファイルの表示
使用可能なプリンタのリストから Universal Document Converter を選択し、電源ボタンをクリックします。

小さい 2.1.2 ユニバーサルドキュメントコンバータ
設定パネルの「エンチャント」ボタンをクリックします。

小さい 2.1.3 カスタマイズの導入
「開く」ウィンドウで「Text Document to PDF.xml」ファイルを選択し、「開く」ボタンをクリックします。

小さい 2.1.4 「テキストドキュメントを PDF.xml に変換」
Druk ウィンドウの [OK] ボタンをクリックして、変換されたドキュメントを印刷します。 完成した PDF ファイルは「My Documents\UDC Output Files」フォルダーに作成されます。
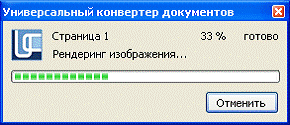
小さい 2.1.5 ドキュメントの変換
情報処理編集変換
-
ドキュメントのコピーは、Adobe Acrobat または PDF 拡張子を持つファイルを表示するためにシステムで使用される別のプログラムで開かれます。
2.2 PDFからWORDへの変換
PDF ファイルの側面を Word ファイルにコピーするには、以下を選択します。
必要なページに移動します。
「基本ツール」ツールバーの「テキスト選択ツール」ボタンをクリックします。
Word 文書から PDF ファイルをコピーするには、次の手順を選択します。
Adobe Acrobat Reader で PDF ファイルを開きます。
[表示] メニューで [連続] コマンドが選択されています。
「編集」メニューから「すべて選択」コマンドを選択します。
「コピー」コマンドは「編集」メニューから選択します。
Word に移動し、[編集] メニューから [貼り付け] を選択します。
小さなものをコピーすると、そのようなアクションが表示されます。
Adobe Acrobat Reader で PDF ファイルを開きます。
Shift キーを押したまま「テキスト選択ツール」ボタンをクリックします。 マウスボタンを放さずに、表示されるツールバーの「グラフィック選択ツール」ボタンをクリックします。
カーソルが十字形でいっぱいになったら、カーソルをドラッグする方法で、必要な赤ちゃんの隣に長方形をペイントします。
「コピー」コマンドは「編集」メニューから選択します。
Word に移動し、[編集] メニューから [貼り付け] を選択します。
このドキュメントからテキストをコピーすることが許可されているかどうかを判断するには、そのようなアクションを選択します。
Adobe Acrobat Reader で PDF ファイルを開きます。
「ファイル」メニューから「ドキュメント情報とセキュリティ」を選択します。
[テキストとグラフィックの選択] パラメーターが [許可] に設定されている場合、このドキュメントのテキストと画像を他のプログラムにコピーできます。
2.3 削除したテキストを編集する
- ドキュメントウィンドウを開く
- フォント、行間隔、インデント、幅で揃えるコマンドなどを選択します。
-
その結果、必要不可欠と思われる文書が完成しました。

プラツィの保護
1. 外国の規制
1. 特別な訓練、健康診断、初歩的な安全訓練、実地訓練および火災安全訓練を受けた人は、パーソナル電子計算機 (PEOM) を操作することが許可されます。 肌からの繰り返し指導 6ヶ月
2. コリストヴァッハは以下の罪を犯しています。
2.1. ヴィコヌヴァティの内部労働秩序規則。
2.3. 保護規則を遵守するために、碑文を書き留めないでください。
2.4. 同僚の従業員の保護と安全に関する規則の実施に対する特別な責任を忘れないでください。
2.5. なお、事故に遭われた方には応急処置をさせていただきます。
2.6. 消火のための最初の措置を講じてください。
2.7. 特別衛生規則に従ってください。
2.8. お客様に影響を与える可能性のある、安全で利益をもたらさないウイルス要因:
a) 物理的:
感電により放電。
電磁振動とX線振動の進歩。
紫外線振動の進歩。
動作中のファンからの騒音レベルが増加します。
プロセッサー、オーディオカード、プリンター。
明るさと明るさのレベルの増減。
進歩と時間の使い方。
視野内の明るさのムラ。
光のイメージの明るさが増加しました。
光の流れの脈動の動き。
c) 精神生理学的:
ナプルガ・ゾラ・タ・ウバギ。
知的かつ感情的な魅力。
自明の静的優位性。
練習の単調さ。
1時間に大量の情報が公開される。
職場の不合理な組織化。
1.3 PEOM を使用したアプリケーションは、自然で明るい色の性質を持っています。 明るさが不十分な場合、PEOM 実践の生産性が低下し、近視や疲労の可能性があります (図 3.1)。
1.4 PEOM 作業装置を地下エリアまたは地下表面の周囲で移動することは許可されていません。

小さい 3.1 – 作業場所
6.創造的な仕事を征服する時間未満の職場では、多大な努力と多大な敬意の集中が必要であり、その後1.5〜2.0メートルのパーティションでお互いを隔離します。
7. EOM が設置されている振動施設は、騒音と振動が基準を超えるため、施設に干渉する必要はありません (機械工場、鉱山など)。
8. PEOM を設置する職場は、次の場所に配置することをお勧めします。 労働者が個室にいる場合や、危険な要素や危険な要因がある部屋にいる場合は常に、自然光が入り、組織的に空気交換が行われる隔離された部屋で悪臭が発生する可能性があります。
9. PEOM を備えた 1 つの作業場所が開発される面積は 6.0 平方メートル以上、敷地面積は 20 平方メートル以上でなければなりません。
10. 表面は滑らかで、穴がなく、滑りにくく、掃除や片付けが簡単で、帯電防止でなければなりません。
11.作業場所がある場合は、自然照明装置によるスクリーンの直接照明の可能性をオフにする必要があります。
12. 2 つの異なる媒体 (PEOM 画面と紙媒体) からの情報をオペレーターが視覚的に理解できる可能性は異なります。
明るさのレベルが低くても、文書を読むときに情報が損なわれます。また、明るさのレベルが高くても、画面上の画像のコントラストが低下します。
したがって、PEOM スクリーンの輝度と過剰な作業面の輝度の比率は、作業領域では 3:1、作業面と過剰な物体 (壁、設備) - 5:1 では高すぎてはなりません。
13. PEOM を使用した敷地内での個別の照明には、成長の痕跡として、照明器具に代替蛍光灯器具を備えた複合照明システムの外観が必要であり、作業面の上にまっすぐかつ均一な順序で立つ必要があります。
14. 直接光の流れで PEOM スクリーンを照らすには、照明器具のラインを作業エリアまたはゾーンの列に十分な移動を加えて、また光の開口部に平行に移動する必要があります。 作業エリアの片側に窓が配置されています。
この肌タイプには、色係数 0.5 ~ 0.7 の明るい色のカーテンが適しています。
15. ピース照明は、作業エリアに 300 ~ 500 ルクスの明るさを提供できます。 アンビエント照明システムによって適切な照明を確保できない場合は、アンビエント照明ランプを静止させておくことができます。そうしないと、画面の表面がちらつき、照明が増加します。画面の明るさは 300 ルクス以上です。 。
16. 痕跡が自然に明るくなった場合、睡眠関連の問題の存在が明らかになる可能性があるため、この方法は、金属コーティングが施された釉薬や、調整可能な垂直スラットを備えたブラインドを除去するために使用できます。
17. 窓や照明器具によってオペレーターの視野が損なわれないように、PEOM を備えた作業場所を配置する必要があります。 彼らは無実で、彼のすぐ後ろにいます。
18. 作業中は、薄暗くした光または拡散した光を使用して、均一な照明を確保する必要があります。
19. キーボード、画面、および PC のその他の部分上の明るい色のライトは、オペレーターの目に直接見える必要があります。
20. まぶしさを防ぐため、照明器具は不透明な素材または乳白色を使用する必要があります。 ブロワーのドライコーナーは40°以上です。
21. 作業場は、窓開口部のある壁から最低 1.5 メートル、その他の壁から最低 1 メートルの水深を保って設置しなければなりません。 お互いの間と風が少なくとも1.5メートルあること。
22. PEOM 特派員のワークステーションの主な設備には、モニター、キーボード、作業テーブル、机 (椅子) が含まれます。 追加設備: 譜面台、フットレスト、ワードローブ、ポリスなど。
23. 作業領域の要素を配置するときは、次のことを確認してください。
コリストヴァッハのポーズをとっています。
キストゥヴァッハを収容するためのスペース。
作業環境の要素を確認することができます。
職場の枠を超えた広がりを少し眺めてみます。
記録を操作し、vikoryst 通信などの文書や資料を配置する機能 (図 3.2)。

小さい 3.2 – 作業場所
24. 作業場の要素の相互拡張は、PEOM の操作に必要なすべての要素の設置と移動を必要としません。 最適な操作および修理モードを採用し、体積消費量を削減します。
25. 情報を正確かつ容易に読み取るために、モニター画面の表面は、作業中のオペレーターの通常の視線に垂直な面内の情報フィールドの最適なゾーンに配置される必要があります。 この領域で曲がることは許可されています - 45°を超えてはなりません。 視線を通常から曲げることは許可されています - 30°を超えてはなりません。
26. スクリーンのサイズに応じて、スクリーンの表面がオペレーターの目の前の最適な位置に来るように PEOM を作業場所に設置する必要があります。
27. キーボードは、テーブルの表面、またはテーブルの隣の高さ調整可能な特別な作業台の右端に最も近いところから 100 ~ 300 mm の距離に置き、突き当たりによる損傷が発生する場所に配置する必要があります。 5°〜15°の間。
28. 各個人や同僚が手動でアクセスできるように、プリンタをインストールする必要があります。 プリンタのキーまでの最大距離が、伸ばしたアームの長さ (高さ 900 ~ 1300 mm、奥行き 400 ~ 500 mm) を超えないようにしてください。
29. 作業テーブルの設計は、設置場所の作業面上に最適に配置できることを保証しなければなりません。これは、サイズ、寸法、設計上の特徴によって決定されます(VDT、キーボード、プリンタ、P EOM のサイズはキャラクターとは異なります)。彼のロボットの。
30. テーブルの作業面の高さは 680 ~ 800 mm の間で調整できます。 途中で725mmになる場合があります。
31. 作業面の幅と深さは、運動野の境界で労働作業を実行する能力を確保する役割を果たします。これは、装置の可視性と制御装置の到達範囲の間の領域によって示されます。
テーブルのモジュール寸法に利点が与えられ、構造的な寸法が保証されます。 トレッド幅: 600、800、1000、1200、1400 mm。 奥行き - 800、1000 mm、高さ調節不可 - 725 mm。
32. テーブルの上部は、反射が少なく断熱効果のあるマット仕上げにすることができます。
33. 作業台は、曲線脚のスペースが 600 mm 以上、幅が 500 mm 以上、膝部分で少なくとも 450 mm、直線脚で少なくとも 650 mm の奥行きが必要です。んん。
34. 椅子は、基本的な作業を完了するときと、姿勢の意識を変えるときに、合理的な作業姿勢をサポートします。 椅子を前方に動かすことで、頸肩部と背中の筋肉の静的緊張を確実に軽減できます。
35. 作業椅子のタイプは、作業の性質と難易度に応じて選択する必要があります。 チルトとスイベルが可能で、座面と背もたれの高さ、座面前端からの背もたれの調整が可能です。 皮膚パラメータの調整は、独立性と信頼性の両方を実現できます。 浴槽内ではハンドル(調整用)を手で持つことが重要です。
36. 椅子の座面と背もたれは柔らかく、帯電せず、非浸透性のコーティングが施されており、その素材は汚れずに簡単に掃除できることが保証されています。
2 コブロボットの前のビモギベズペキ
1. 部屋の空調システムをオンにします。
2. 作業場所を見回して整理整頓します。 誰かが異物を持っていると寝返ります。 すべての機器と PEOM ユニットは、適切なコードを使用してシステム ユニットに接続されます。
3. デスクトップへの機器の設置の信頼性を確認します。 ディスプレイをテーブルの端に置くことはできません。 VDT を回転させて、画面上の直線エッジの下 (横からではなく) がわずかに下に直接見えるようにします。 この場合、スクリーンには多少の損傷があります。スクリーンの下端がバックボーンに近いためです。
4.機器の加熱回路を確認し、電気配線、接続コード、プラグ、ソケット、ドライスクリーンの接地が正しいことを確認してください。
絶縁体を使用した動作時間当たりの、損傷または電力損失のあるケーブルおよびワイヤの動作。
電圧ケーブルと絶縁されていない導体を取り除きます。
ポータブル電気配線に対する電気設備の制御に関する規則の要件に準拠していない内蔵型履物の使用。
焦げつき防止、非標準(自走式)電気加熱装置またはフライ用ランプの設置。
損傷したソケット、緩んだ箱、デバイス、および黒ずんだり損傷している可能性のあるランプの除去。
ランプを導体から直接吊り下げ、電灯や紙、布、その他の可燃性物質を使用したランプを点灯し、取り外したホース - ソケットで操作します。
製造会社の指示(推奨)に従わない欠陥のある電気機器および器具。
6. 作業領域の明るさを調整します。
7.椅子の高さを調整して固定すると、背もたれの調整が簡単になります。
8. 必要に応じて、必要な機器 (プリンタ、スキャナなど) をプロセッサに接続します。 コンピューターの電源が入っているときに、システム ユニット (プロセッサー) を他のデバイスに接続するすべてのケーブルが突き抜けたり突き抜けたりしません。
9. コンピュータ機器をケース上の回路に次の順序で接続します: 電圧安定器、モニタ、プロセッサ、プリンタ (これは別の回路に転送されます)。
10. モニター画面の明るさ、点灯する点の最小サイズ、フォーカス、コントラストを調整します。 目が疲れないよう、できるだけ早く画像を明るくする必要があります。
画面の明るさ – 100 cd/m 以上。
モニター画面の明るさと作業領域の余分な表面の明るさの比率 - 3:1 以下;
光点の最小サイズは、モノクロ モニターの場合は 0.4 mm 以上、カラー モニターの場合は 0.6 mm 以上です。
標識画像のコントラストは0.8以上である。
11. ロボットに何らかの異常が検出された場合は、修理せずにロボットのサービスセンターに連絡してください。
3.3 戦時中の仕事の扱い方
1.ビデオディスプレイ端子(VDT)の場合:
1.1. キーボードが改ざんされないように、デスクトップ上でキーボードをしっかりと移動する必要があります。 同時に、方向転換と移動の能力も伝達できます。 キーボードの位置が特派員のニーズを不適切に責めている。 キーボードの設計では手のひらを支えるのに十分なスペースが提供されていないため、手のひらは運動野の最適ゾーンでテーブルの端から 100 mm 以上上のスタンドに配置する必要があります。 キーボードを操作するときは、無理をせずにまっすぐに座ってください。
1.2. koristuvach koristuvach タイプの「ミシャ」の不快な流入(印象的な姿勢、動作を常に制御する必要性)を変更するには、「ミシャ」を移動し、肘関節を手動でサポートするために、テーブルに自由な広い表面を提供する必要があります。
1.3. 屋外での騒音を伴う演説は禁止です。
1.4. 定期的に、コンピューターの電源を入れたときに、マイルドなローズウォーターに浸した蜂蜜を使用して、装置の表面から氷を取り除きます。 アルコールに浸した脱脂綿で VDT 画面を拭き、画面を乾燥させます。 コンピューターの表面を掃除するために vicor またはエアゾール クリーナーを使用することは許可されていません。
機器、特にディスプレイを自分で修理してください。 機器の修理はコンピューターのメンテナンスと同じではなく、プロセッサーを開け、掃除機を使ってそこに溜まったゴミを取り除く責任もあります。
コンピューターのハードウェア上に物を置いたり、キーボードを押したり、使用したりすると、コンピューターの調子が悪くなる可能性があります。
1.6. 静電気を除去するには、その場所の接地された構造物(中央射撃砲台など)の金属表面に触れることをお勧めします。
1.7. PEOM での作業のストレスを軽減するには、作業の性質を均等に分散し、その複雑さとの一貫性を保つ必要があります。
単調さの負の流入を変えることで、テキストや数値データの転送(変更作業の変更)、編集テキストの変更とデータの転送(作業の変更と速度)などの動作を完全に安定させる必要がある。 (図3.3)。

小さい 3.3 - コンピューターの前にロボットが見えるチェルグワーニャ
3.1.8. ウイルス要因が労働者の健康に及ぼす悪影響を変えるには、規制された休憩を課す必要があります。
1.9. たとえどんな些細なことであっても、勤務変更の要件は6年を超える可能性があります。
1.10. 規定の休憩なしで VDT をノンストップで作業することの困難さは、2 年を超える必要はありません。
1.11. 毎日の休憩が取るに足らないことは、労働に関する正式な法律と企業の内部労働規制の規則によって示されています。
1.12. ディスプレイ作業者が視覚上の違和感や不快な主観的感覚を懸念する場合には、ディスプレイ作業や三迷走症の矯正作業の合間、修理のための休憩時間などに個別に対応するか、他のタイプに置き換える必要があります。ロボットの(ディスプレイとは関係ありません)。
2. レーザープリンターの場合。
2.1. コードに張力がかからないような方法で、プリンタをプロセッサから切り離す必要があります。 プロセッサーにプリンターをインストールすることは禁止されています。
2.2. まずプリンターロボットをプログラムし、コンピューターモードに接続するようにロボットに移動します。
2.3. 最もきれいで控えめな画像を実現し、マシンの圧縮を避けるには、プリンターの説明書の指示に従う必要があります。 紙の表面は熱い金属によって損傷を受けますが、傷はつきません。これにより、しわのある紙の品質が変化します。
片側が過剰武装。
非常に滑らかで光沢があり、質感も高い。
ラミネート加工;
破れたり、しわが寄ったり、紙やホッチキスなどの開口部が不規則なもの。
添え木やタバコの紙(コピー用紙の基)に穴を開けます。
会社フォームから、0.1 の伸びで 200 °C に耐えることができる非耐熱性接着剤を使用したオーバースリーブの見出し。 これらのファービーはヒートシール ローラーに切り替わり、他のローラーに欠陥を引き起こす可能性があります。
3.2.5. メーカーの指示に従ってカートリッジを保存するための規則に従ってください (温度 0 ~ 35 °C での直接交換を含む)。
守る:
- カートリッジは梱包せずに保管してください。
カートリッジの端を下にして垂直になるように置きます。
ラベルを下にしてカートリッジを裏返します。
ローラーのカバーを緩めて外に出します。
ビコリスタン カートリッジはご自身で交換してください。
作業終了後の安全のための4つのヒント
1. 終了し、コンピュータ内のファイルをコンピュータのメモリに保存します。 プログラム シェルを終了し、MS DOS 環境に移動します。
2. プリンタ、その他の周辺機器の電源を入れ、RCCB とプロセッサの電源を入れます。 コンピューターがスタビライザーを介して回路に接続されている場合は、スタビライザーをオフにします。 プラグがソケットから抜かれています。 キーボードをカバーで覆い、ノコギリによる切り傷を防ぎます。
3. 職場をピックアップします。 原稿とその他の書類を机の引き出しに置きます。
4. ぬるま湯で丁寧に手を洗います。
5. エアコンをつけ、照明をつけ、電気を消します。
緊急時に安全を確保する 5 つの方法
5.1.2. 警察官が発する「止まれ!」という命令は、それを感知した者全員を殺す恐れがあります。
5.1.3. 施術者が感電した場合は、患者を感電から解放してください。
v このプロットへの電力供給をオンにします。
v 影響を受ける部分、粘性および絶縁性のミトン、その他の化学薬品、絶縁材および物体を防水する。
v 医師を呼び、医師が到着するまで患者に手助けをする。
v 中年のケリブニコフにその過程を話す。
5.1.4. 電気回路で短絡が発生した場合は、ロボットの電源を投入し、障害のある電気回路をオフにすることが重要です。 病院長に通報してください。 短期間の自衛、DEFENSE!
5.1.5. 電源がオンになったら、PEOM を限界までオンにし、木工職人が現場に到達できるようにします。
5.1.6. 電源コードが燃えている場合は、直ちにロボットの電源を入れ、電源を入れ、二酸化炭素点火器で火を消してください; 必要に応じて、消防署に電話してください。 01. プロットの陶芸家へのアドバイス。
5.1.7. 緊急事態の恐れがある場合、甲状腺腫の医師は緊急事態を避けるために最善を尽くし、負傷者に応急処置を施し、救急隊員に通知し、必要に応じて助けを呼ばなければなりません。
5.1.8. 事故が発生した場合、可能であれば(他の労働者の生命と健康を危険にさらさず、より重要な相続につながらない限り)職場の環境を保全する必要があります。配達の瞬間。
1.9. 事故や自然災害が発生した場合には、あらゆるカテゴリーの労働者に安全規則を適用することが義務付けられています。
1.10. この指示に違反した医師は、法律で定められた命令の対象となります。
ヴィシュノヴォク
この論文の過程で、私は基礎に到達し、情報の種類を徹底的に研究した上で、さまざまな種類の情報を処理するための方法と技術を追跡して説明しました。 論文を書いている過程で、コンピュータ (我が国では当初 EOM と呼ばれていた電子計算機) の出現により、数値情報を処理する必要性が直ちに生じたことに気づきました。 しかし、その後、特にパーソナル コンピュータ (PC) の普及後、コンピュータはテキスト、数字、画像、音声、ビデオ情報の保存、処理、送信、検索に使用されるようになりました。 最初のパーソナル コンピューターである PC (80 年代から 20 世紀) が登場して以来、現在の労働時間の最大 80% がテキスト情報を扱う作業に費やされています。
取得した情報の分析では、情報の処理 (作成、変換、送信、外部メディアの記録) はコンピューター プロセッサーによって実行されることに注意してください。 コンピュータの助けを借りて、あらゆる種類の新しい情報を作成および保存することができます。そのために、情報を入力するためのコンピュータおよびデバイスに特別なプログラムがインストールされています。
p align="justify"> 現時点では、グローバル インターネット上に提供される特別な種類の情報を考慮に入れることができます。 ここでは、重要な義務を負う分散情報を保存、処理、検索、送信する特別な方法と、さまざまな種類の情報を扱う特別な方法を説明します。 あらゆる種類の情報を確実に共同作業できるよう、セキュリティ プログラムは着実に改善されています。
ウィキリストのリスト
1. 情報システム。 ウィキペディア フリー百科事典 [電子リソース]
2. ファイルサーバー。 ウィキペディア フリー百科事典 [電子リソース]
Shokin Yu.I.、Fedotov A.M. 情報システム部門[電子リソース]
L.F. クリコフスキー、V.V. モトフ「情報プロセスの理論的待ち伏せ攻撃: Navch. 大学向けハンドブック。」 - K. 2009
V.ドミトリエフ「情報の応用理論」。 – M.、2008
A.G. クシュニレンコ、G.V. レベデフ、R.A. 動物。 「情報とHIVテクノロジーの基礎」 キエフ「オスヴィータ」2008
ドクチャエフ A.A.、モシェンスキー S.A.、ナザロフ O.V. 商社オフィスにおけるコンピュータ サイエンスのコスト。 コシュティのコンピュータ通信。 – サンクトペテルブルク: TEI、2010 年、32 ページ。
情報処理のためのコンピュータ技術。 // 編集用。 ナザロワ S.I. - M.: 財務と統計、2008 年。
ナンズB.コンピュータ対策。 - M: シドナ ブック カンパニー、1996 年。
Friedland A. Informatics – 基本用語の包括的な辞書。 - M: 1998 年以前。
シャット S. コンピューター測定の世界。 – キエフ: BHV、2006
シャフリン・ユウ、情報技術。 - M.、2010