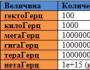
新しい分析ポータル「電子機器の時間」。 SystemVerilogでFPGAをプログラムする方法優れたfpgaプロジェクトのデザインを適用する
65ナノメートル-ゼレノグラード植物「Angstrem-T」の攻撃的なメタ、3億から3億5000万ユーロの費用。 企業はすでに、生産技術の近代化のためのパイロットローンの撤回をZovnishekonombank(ZEB)に申請しました。これは、Vidomostiと呼ばれ、工場のディレクターであるLeonidReimanのために頭に送られました。 同時に、Angstrem-Tは、90nmトポロジーからマイクロ回路を製造するためのラインを立ち上げる準備をしています。 2017年半ばに成長するために、それを獲得したWEBUへの最後のローンの支払いをします。
北京はウォール街を崩壊させた
主要なアメリカのインデックスは記録的な落ち込みでニューロックの最初の日をマークしました、億万長者ジョージソロスは2008年のロック危機の繰り返しのために警戒している人々をすでに上回っています。
60ドルの価格で最初のロシアのプロセッサBaikal-T1が大量生産で発売されます
2016年の初めに会社「BaikalElectronics」はロシアのプロセッサBaikal-T1を約60ドルで発売すると発表しました。 添付ファイルは、州が飲むかのように、飲む母親になり、市場の参加者はそうであるようです。
MTSとエリクソンは同時にロシアで5Gを拡張および実装します
PJSC「MobileTeleSystems」とエリクソン社は、ギャラリーでのスパイ活動とロシアでの5Gテクノロジーのプロモーションの基礎を築きました。 パイロットプロジェクトでは、ES-2018の営業時間中に、MTSはスウェーデンのベンダーの開発に抗議する可能性があります。 攻撃的な運命の穂軸で、オペレーターは通信省からのrozpochne対話と、第5世代のモバイル通信への技術サポートの提供を行います。
Sergiy Chemezov:Rostecは、すでに世界で10大機械製造企業の1つです。
GosterPannnyaのRBCVidpovivにあるRostecSergiiChemezovの責任者:プラトンシステム、AvtoVAZの問題、MARMBISHICHAのINNITERES、ROZPOVIVの聖時間鉱山について。
Rostec「zagorodzhuetsya」とSamsungとGeneralElectricの栄光に揺れるロブ
RostecのNaglyadovaRadaは、2025年まで開発戦略を承認しました。 主なタスクは、ハイテク民間製品の一部を増やし、主要な財務指標についてゼネラルエレクトリックとサムスンに追いつくことです。
PLIS(Programmed Logic Integrated Circuit)-私の特別なプログラミングの説明とともにデジタル言語を誘発することで認められた回路集積回路。 それ以外の場合、FPGAはチップであるように思われます。74HCxxkshtaltの多数の要素に対して、自分で復讐するのは良いことです。 ほとんどのように論理的な要素であり、それらの間にリンクがあり、リンクのようにスキームになります zvishnіshnіmsvіtom、FPGAプログラミングの段階で示されます。
ノート:今のところ、ロシア語では、この日、FPGAとFPGA(フィールドプログラマブルゲートアレイ、Koristuvachゲートマトリックスによってプログラムされた)という用語は互換性があるものとして受け入れられ、テキストの後ろに示されます。 Prote vartoは、ギャップの代替ポイントであるzgidnoと任意のFPGA(FPGA)(PLIS(PLD、プログラマブルロジックデバイス)の1つ)の基礎について知っています。
FPGAに関する基本情報
FPGAをプログラミングするために、ムービーハードウェア記述言語(HDL、ハードウェア記述言語)が記述されています。 その中で最も人気があるのは、Verilog(そのヨガ方言、SystemVerilogコード)とVHDLです。 映画は多くの点で豊富ですが、構文が異なり、細部がいくつか異なります。 VerilogがそのようなCの世界的な機器の記述であるように、VHDLは明らかにPascalです。 やや人気が低く、VHDLはあまり人気がありませんが、Verilogと比較してyogoの豊富さに基づいています。 3つのVHDLの利点(そうでなければ、ヤクの対象となるnedolіkіv)を呼び出すことができます 厳密に 静的型付け。 Verilogは、暗黙的に型をキャストできる場合があります。 Cとパスカルとのアナロジーを続けるために、映画はそれほど強くなく、不快感を与えないようにしています。
現在、主要なFPGAビルダーはアルテラ(Intelと共に)とザイリンクスです。 さまざまなdzherelsの情報については、悪臭は市場の少なくとも80%によって一度に制御されます。 他の3つの砂利には、Actel(Microsemiが購入)、Lattice Semiconductor、Quicklogic、SiliconBlueが含まれます。 ザイリンクスの入り口から、ザイリンクス(Vivadoと呼ばれる)への開口部の中央からのみ作業でき、アルトラ(Quartusと呼ばれる)への開口部の中央からは、アルテラへの開口部の中央からのみ作業できます。 。 したがって、最新のベンダーロックインを使用し、プロジェクトに特定のFPGAを選択すると、自動的に 技術サポート、ドキュメント、ライセンスソフトウェアの洗浄、サポートの申請方法のポリシー、次に。
FPGAは、ほとんどの場合zavdannyahのzastosovuyutであり、deyaki deyakiは計算を大幅に高速化し、ゲートでそれらを実現したいと考えています。 たとえば、FPGAは、信号処理の分野、たとえば、オシロスコープ、スペクトラムアナライザ、ロジックアナライザ、信号ジェネレータ、ソフトウェア無線、およびその他のモニタで広く使用されています。 Zokrema、LimeSDR vikoristovuetsya Altera Cyclone IV、およびオシロスコープのRigol DS1054Zは、ザイリンクスSpartan-6と、ActelのProASIC3の価格です。 zastosuvanからもっと、私が感じているyakіについて、私はコンピューターサイエンス、映画の認識、バイオインフォマティクスに名前を付けることができます。 Єyіnshіプロジェクト、FPGAで動作するWebサーバーとDBMSの開発。 エール、私が知る限り、全体はまだもっと実験的なもので溢れています。
ザイリンクスchiアルテラ?
最高のLinuxは、有名なLinuxの第一人者と同じもののようです。
私の有名なFPGAの第一人者、特にDmitry Oleksyukは、DigilentのArtyArtix-7開発ボードのほぼすべてを喜ばせています。 その中で勝っているFPGAは、ザイリンクスのArtix-7です。 Digilent自体はロシアへの配達を提供していませんが、必要に応じて、特別な国籍のAliExpressで利用できます(公式価格は99ドルです)。 eBayでヨガを販売することもできます。 厳しい料金を支払う価値はありますが、十分なペニーがたくさん必要です。
楽しい事実! VerilogまたはVHDLでプログラミングしたいだけの場合は、FPGAボードを購入する必要はないようです。 背面では、シミュレーターで身を包むことができ、ロボットを遠くから見ています。
W tsіkavihの特異性支払いは、Arduinoシールドと同じようにソケットの拡張と呼ぶことができます。 また、ボード付きのキットにはタブがあり、Vivadoのライセンスを取得してすべての可能性を示すことができます。 ライセンスはアクティベーションの瞬間から1日間有効であり、OSおよびMACアドレスごとに1台のコンピューターにもバインドされます。
配達時に。 ボード上のFPGAアタッチメントは、テストに合格しない可能性が高いと感じています。 他の国に送られるAliExpressのストアは、SPSRの宅配便サービスを通じてロシアに支払いを行います。 ミトニツァの通過には、オンラインフォームにパスポートデータ(データのみ、写真なし)を記入する必要があります。 電話に連絡するどうすればロシアの法律をより正確に支援できるでしょうか。 翌日、支払いは宅配便で食べ物なしでドアに届けられました。
インストールされているVivado
Vistaのディストリビューション環境は、ザイリンクスのWebサイトで購入できます。 登録を行う前に心の準備をし、予約前に自分でレポートフォームに記入してください。 「VivadoHLx2017.2」という名前でアーカイブされています。すべてのOSインストーラーのシングルファイルダウンロード。 vipadkovoと疑わしいVivadoラボソリューションを混同しないでください。必要なソリューションではないためです。 アーカイブは20GBを超える必要があるため、しばらくお待ちください。
アーカイブを解凍し、インストーラーを起動します。 Virginia HLSystemEditionを配置しました。 ローンの新しいバージョンは47GBのディスクにあります。 特に[ソフトウェア開発キット]チェックボックスをオフにして、サイズを12GBに変更した7シリーズアドオンのみのサポートを入力しました。 少し先に進むと、そのような構成で十分であることがわかりました。
このボードについては何も知らないので、Vivadoを起動する前に、ArtyArtix-7を新しいサポートに追加する必要があります。 このようにランブル:
cd〜/ opt / xilinx / Virginia / 2017.2 / data / board / board_files
wget https:// github.com/ Digilent / vivado-boards / archive / master.zip
master.zipを解凍します
mv vivado-boards-master / new / board_files /*./
rm -r vivado-boards-master
rmmaster.zip
また、Arty_Master.xdcファイルをどこかに持っていきます。 さらにワインが必要です。 このファイルには、光源、スイッチなどの説明が含まれています。 新しいダイオードがないと、Verilogのライトダイオードで点滅するのは簡単ではありません。
SystemVerilogの最初のプロジェクト
[Vivado]に[ファイル]→[新しいプロジェクト...]と表示されます。プロジェクトの種類として、[RTLプロジェクト]を選択し、[現時点ではソースを指定しない]チェックボックスをオンにします。 ダイアロの場合、支払いタイプの選択はArtyリストに記載されています。
XDCファイルの前にプロジェクト提案に追加します。 プロジェクトからカタログにヨガをコピーします。 次に、「ファイル」→「ソースの追加…」→「制約の追加または作成」→「ファイルの追加」と言います。ファイルのコピーがわかっているか、「終了」です。 Constraintsグループのプロジェクト(ソース)のファイルツリーには、ファイルArty_Master.xdcが含まれます。それ以外の場合、コピーはそこで名前が付けられます。 クロック信号、スイッチ、LEDのグループのすべての行を表示してコメントすることができます。
次に、「ファイル」→「ソースの追加…」→「デザインソースの追加または作成」→「ファイルの作成」と言います。 ファイルタイプとして、SystemVerilogを選択し、ファイル名にhelloという文字を入力します。 仕上げと言います。 次に、[モジュールの定義]ダイアログが表示され、モジュールインターフェイスをクリックするように求められます。 マークを完成させるためのダイアログ、コードに直接書き込むのに最も成功した人には、キャンセルをエンボス加工しました。
vih_dnikiの木で私たちは知っています 新しいファイル hello.svは、DesignSourcesグループに所属します。 次のコードを見て、書いてみましょう。
`タイムスケール1ns/1ps
モジュールhello(
入力ロジックCLK100MHZ、
入力ロジック[3:0] sw、
出力ロジック[3:0] LED
)
;
always @(posedge CLK100MHZ)
始める
if(sw [0] == 0)
始める
導いた<=
4"b0001
;
終わり
そうしないと
始める
導いた<=
4"b0000
;
終わり
終わり
エンドモジュール
すべてが正しく分割されている場合、Vivadoのどの段階で次のようになります(クリック可能、PNG、71 Kb)。

プログラムのコンパイルは、合成と実装の2つの段階で行われます。 合成段階で、プログラムは論理ゲートやその他の要素から抽象的な言語に変換されます。 実装の段階で、このランセットを特定のまつ毛に縫う方法について決定が下されます。
Flow→RunSynthesisと言うか、F11を押すだけで、合成を実行します。 右上隅に、プロセスが実行中であることを示す表示が表示されます。 コンピュータやプログラムの複雑さによっては、それを行うのに多くの時間がかかる場合があります。 私のラップトップでは、他のプログラムによって誘発された合成は10秒で10秒で完了しました。ここで、[フロー]→[合成デザインを開く]と言うと、次のような画像を作成できます。

私たちのボードをフラッシュする時が来ました。 Flow→RunImlementation、次にFlow→GenerateBitstreamと言います。 ボードをUSB経由でコンピューターに接続します。Vivadoでは、[フロー]→[ハードウェアマネージャーを開く]→[ターゲットを開く]→[自動接続]→[デバイスのプログラム]と表示されます。 ビットファイルへのパスを指定する必要があります。 私のvinはこのようなものです:
./first-project.runs/impl_1/hello.bit
プログラムと言います。 これで、LD4ライトがボード上でオンになりました。これは、省略のスイッチSW0がオンになっていることを意味します(div。ボードの写真を表示します)。 スイッチが持ち上げられたかのように、ライトは燃えないはずです。 単純に、明らかに、しかし「こんにちは、世界」、あなたは何を得ましたか? :)
シミュレーション
シミュレーションは、PLICITを使用せずに、コンピューター上で直接VerilogまたはVHDL上のコードの仮想バージョンです。 これは1時間ごとの柔軟なツールであり、コードをテストでカバーするためのフレームワークです。
私が最初にシミュレーションを知ったとき、私が明らかにしたことは、うまくいかなかった人々がいました。 ログには単純なものがありました。
エラー:生成されたCファイル[...]xsim_1.cをコンパイルする前にスキップされました。
グーグルzcієїは「アンチウイルスをオンにしてみてください」というスタイルのnієїnіtnitsaであることだけを知っていることを許します。 その結果、ensign -v 2をスクリプト〜/ opt / xilinx / Vivado / 2017.2 / bin / xelabに追加することで、問題を解決しました。 このようなVivadoのバイナリであるClangが、このような慈悲を持ってあなたを追いかけていることを知っておくのを手伝います。
/ a / long / path / to / clang:共有ライブラリのロード中にエラーが発生しました:
libncurses.so.5:共有オブジェクトファイルを開くことができません:そのようなファイルはありませんまたは
ディレクトリ
そして、この許しはすでにArchWikiで説明されています。 特に、Vivado_HLSディレクトリからリファレンスファイルをコピーしました。
cp〜/ opt / xilinx / Vivado_HLS / 2017.2 / lnx64 / tools / gdb_v7_2 / libncurses.so.5 \
〜/ opt / xilinx / Vivado / 2017.2 / lib / lnx64.o / libncurses.so.5
...すべてがうまくいった後。 Otzhe、今、vlasne、シミュレーションの例。
これと同様に、hello.svを作成したときに、SimulationSourcesグループに新しいファイルhello_sim.svを作成します。 ファイルの次のコードを記述します。
`タイムスケール1ns/1ps
モジュールhello_sim();
ロジックclck_t;
logic [3:0] sw_t;
logic [3:0] led_t;
こんにちはhello_t(clck_t、sw_t、led_t);
最初の始まり
clck_t<=
0
;
sw_t<=
4"b0000
;
#
1
;
clck_t <=
1
;
#
1
;
clck_t <=
0
;
#
1
;
assert(led_t === 4 "b0001);
Sw_t<=
4"b0001
;
#
1
;
clck_t <=
1
;
#
1
;
clck_t <=
0
;
#
1
;
assert(led_t === 4 "b0000);
終わり
エンドモジュール
ツリービューでファイルを右クリックし、[ソースノードのプロパティ]を選択します。 [使用場所]セクションで、[合成と実装]チェックボックスをオンにします。 ええと、テスターが人間のFPGAから遠く離れた場所を嘲笑したとしても、私はしたくありません。
ここで、フロー→シミュレーションの実行→動作シミュレーションの実行と言います。 その結果、次のようなプランが得られます。

swがゼロに等しい場合、ledは1に等しく、navpakである場合、バチッティを使用できます。 この時点で、すべての変更はクロック信号の前で発生します。 プログラムは正常に動作しているようです。 まあ、何があっても、アサーションには何も落ちませんでした。
ヴィスノヴォク
上記のプロジェクトのアーカイブを入手できます。 追加の情報源として、次の2つの手順をお勧めします。
- あなたのようにホールの細部をチャープし、敬意を払う
FPGAでのプロジェクトの実装
機能モデルの代替案を使用して論理スキームを開発した後、それをクリスタル上に配置する必要があります。 次に、回路を水晶に配置した後に取り除いた、要素の実際のフィッティングを改善して回路をモデル化します。 必要に応じて、解決策を修正してください。 スキームがPLISに巻き込まれる理由がある場合は、スタンドで実行されます。
米。 82。 PLISでデジタルアドオンを設計する段階
FPGAデザインの主な段階(講義付き):
アタッチメントのレイアウトは開発中であり、ザイリンクスに入力されています。
実装は勝利です(ブロードキャスト、ライブラリ要素のパスを使用した回路の形成、最適化、水晶への配置)。
プログラミング。
連想記憶。 組織、選択の方法、vіdmіnuvіdアドレスza。
連想アクセスメモリ内のїїroztashuvannyamではなく、特定の記号の情報の検索を実装します(アドレスまたはハートのメッセージを含む)。 最新バージョンでは、メモリに保存されているすべての単語は、すぐに識別可能な記号に変換されます。たとえば、入力によって与えられた記号が付いた単語のzbіg歌うフィールド(タグ-英語の単語タグなど)に変換されますワード(タグアドレス)。 言葉は外側に見られ、それらは兆候を示しているようです。 単語を書くことの規律と、新しいデータを記録することの規律は異なる場合があります。 最新のEOMにおける連想メモリ保持の主な領域はデータのメモリです。

記憶されている連想添付ファイルでは、情報の検索は、メモリボックスのスキンに記録されている連想記号の背後で実行されます。
マスクのレジスターには、すべてを尋ねることができる単語が書かれています。または、いくつかの関連する記号が付いていても、zastosuvannyaマスクを使用すると、検索の領域を高速化または拡張できます。
情報の検索は、皮膚の中心の連想記号に沿って、すべての中央のパスに沿って並行して実行されます。
検索の結果は、信号を振動させる特別な組み合わせスキームであり、単語の数、冗談で心を満足させる、1つの単語の存在、いくつかの単語の存在などを示します。連想記号。
通知信号の形成と処理の後、制御回路は必要な情報を読み取ります。 記録するとき、私は雇用カテゴリーの正しい中間を知っています。最初に、情報を記録するための正しい中間を見つけました。
マスクのn番目のカテゴリ(雇用カテゴリ)のインストール時に、雇用カテゴリの再チェックが実行されます。 連想メモリ内の追加の組み合わせスキームを変更する場合、最大数と最小数、つまり同じ連想符号のみを持つ可能性のあるワード数を選択して、異なる論理演算を選択することができます。 連想接続の中間記憶は静的記憶の要素によるものであり、連想記憶では、記憶はすべての中間まで一度に実行され、再生サイクルによって中断されることは無罪です。 連想記憶は最も一般的ですが、皮膚の中間記憶の要求を送信できるようにする追加の整列スキームの導入が必要なため、さらに高価です。 したがって、そのような記憶は純粋な見た目では鳴り響きませんが、ケシュのような動きの速い記憶は部分的に連想的なもののように聞こえます。

でより連想的 キャッシュメモリ (FACM、完全に関連付けられたキャッシュメモリ)、中央のスキンはデータを取得し、「タグ」フィールド-情報の完全な物理アドレスであり、そのコピーが記録されます。 交換の場合、要求されている情報の物理アドレスがすべてのミドルの「タグ」フィールドと比較され、番号が変更されると、ヒット信号がミドルに設定されます。
読み取り時に信号Hit=1の値を読み取ると、メモリがないため(Hit = 0)、データがデータバスに送信されます。次に、メインメモリから読み取るときに、データとアドレスがアドレス、または長い間読み取られていないその他のキャッシュメモリ'yati。
フォルダのアドレスで一度にデータを書き込む場合、原則としてキャッシュメモリに格納されます(フォルダはHit = 1の場合に表示され、Hit = 0の場合は無効になります)。 メインメモリへのデータのコピーは、メモリへのメモリがない場合、特別なコントローラの監視の下で完了します。
メモリタイプFACMは、特別な追加のメインランクである小さなスペース専用の折りたたみ式拡張機能とvikoristovuєtsyaですらあります。 同時に、このタイプのキャッシュメモリは、最も機能的な柔軟性と競合のないアドレスを提供するため、キャッシュメモリコンボでキャプチャできる情報は1つだけです。
3回の講義:
覚えておくべき連想拡張
主な権限は、それらからの情報選択のシステムが、情報の一意のアドレスではなく、実際には、shukano情報の一部のサインのために確立されている権限です。
|
情報 |
タグはマークのシンボルです。zbіgzyakimには、情報があります。
連想RFPのスキームが簡略化されました。

ストレージゾーン-中央に番号が付けられたアドレスメモリ、情報とタグを収集します。
レジスタの連想メモリに検索するために、ジョークタグの文字が削除されます。 支払いスキーム zbіgはzbіgіvレジスタにインストールされ、クリアからのメモリからdezbіgタグが付けられます。 考えられる反応(十分なzbіgіv;є1つのzbіgのみが必要-このタイプの知識の場合、知識の中心をデータのレジスターに配置する必要があります;複数のzbіg-COPが決定を下すことができ、その結果、処理)。
Zastosuvannya:DB、基本的な知識、PCのヤクのキャッシュ。
プロセッサは、最初の一連の命令を完了し、スキンプログラムを再適用し、アルゴリズムを直接「salize」に書き直す必要性を置き換えることに注意してください。 これがFPGの練習方法です。 今日の記事では、それがどのように可能であるかを説明し、さまざまなFPGAの設計方法について説明します。
穂軸については、ASICマイクロチップロボットのデジタルロジックを理解する必要がありますが、それらから始めるのはより複雑で高価であり、FPGAから始める方が良いです。
FPGAとは何ですか?
FPGAフィールドプログラマブルゲートアレイ(プログラマブルゲートアレイ、FPGA)として解読されます。 悪臭はPLISと呼ばれます-論理集積回路のプログラミング。
FPGAを使用すると、文字通りデジタルマイクロ回路を設計できます。自宅に座って、手頃な給料で1,000ルーブルのソフトウェア小売店を利用できます。 エールとbezkoshtovnіのオプション。 敬意を払うために:それをプログラムするのではなく、自分で設計するために、最後に私たちは物理的なデジタル回路を取ります。これは、ロボットのプログラムではなく、ハードウェアレベルで歌のアルゴリズムを構築します。
このように練習してください。 一連のインターフェイスを備えたボードの準備ができているため、データセンター用のクールなボードなど、ボードに取り付けられたFPGAマイクロ回路に接続したり、トレーニング用の税金を支払ったりすることができます。
FPGAを実現するまでは、インターフェイスからのデータを処理するためのロジックがマイクロ回路の真ん中にないだけであり、明らかに作業するものはありません。 エール、設計の結果、FPGAが必要なデジタル回路を作成するとすぐにファームウェアが作成されます。 このようにして、メッシュ化されたパケットを処理できる100Gイーサネットコントローラーを作成できます。
FPGAの重要な機能は、再構成する機能です。 一度に100Gイーサネットコントローラーが必要になることは許容されます。しばらくすると、ボード自体をテストして、いくつかの独立した25Gイーサネットインターフェイスを実装できるようになります。
市場に出回っているFPGAチップメーカーには、Intelとザイリンクスの2つのリーダーがいます。 悪臭は市場の58%と42%を支配しています。 ザイリンクスの創設者である最初のFPGAチップは、1985年に誕生しました。 Intelはごく最近市場に登場しました。2015年に、アルテラを廃止した同社は、ザイリンクスと同時に設立されました。 アルテラとザイリンクスのテクノロジーは、開発の途中であるため、多くの点で非常に似ています。 ほとんどの場合、ザイリンクス製品を扱ってきたので、投稿の投稿に驚かないでください。
FPGAは、エレクトロニクス、電気通信、データセンター用のストレージボード、ロボット工学、ASICプロトタイピングなどのさまざまな分野で広く使用されています。 以下のトロッホを整理します。
ハードウェアの再構成を保証するテクノロジーを見て、設計プロセスから学び、Verilogハードウェアデバイスを実装する簡単な例を見つけましょう。 カスタムFPGAボードをお持ちの場合は、自分で繰り返すことができます。 支払う必要がない場合でも、コンピューターの回路をシミュレートすることでVerilogを学ぶことができます。
FPGAの動作原理
FPGAチップは、同じASICチップ自体であり、同じトランジスタで構成されており、そこから最大の回路のトリガー、レジスタ、マルチプレクサ、およびその他の論理要素が選択されます。 これらのトランジスタの接続順序を変更することは明らかに不可能です。 しかし、アーキテクチャ的には、マイクロ回路は、より大きなブロック間で信号の切り替えを変更できるような狡猾なトリックに触発されました。それらはCLB(プログラミングロジックブロック)と呼ばれます。
CLBのオーバーライドなど、論理関数を変更することもできます。 マイクロ回路全体にスタティックRAM構成メモリのコアが浸透しているという事実に到達します。 メモリのスキンビットは、信号スイッチングキー、またはCLBを実装する論理関数の部分真理値表のいずれかを制御します。
コンフィギュレーションメモリはスタティックRAMテクノロジによって誘導されるため、最初にFPGAライブを有効にすると、言語チップをコンフィギュレーションする必要があります。別の方法では、マイクロ回路を何度も再コンフィギュレーションできます。
マイクロ回路の2D構造も、構成メモリなしで簡素化されますCLBブロックは、CLBブロックの入力と出力の関数として、スイッチングマトリックスに配置されます。
スイッチングマトリックスのスキーム導体の真皮ウェブには6つのキーがあり、それらは構成メモリコアによって角質化されてちらつきます。 いずれかの曲線を使用すると、CLB間で信号を確実に切り替えることができます。
CLBCLBは、いくつかの引数(ルックアップテーブル、LUTと呼ばれます)とトリガー(フリップフロップ、FF)を使用してブール関数を定義するブロックに単純にスタックされます。 最新のFPGALUTには6つの入力がありますが、簡単にするために3つを示しています。 LUT出力は、非同期(中間なし)または同期(システムクロック周波数で動作するFFトリガーを介して)のいずれかでCLB出力に適用されます。
LUT実装の原則Tsіkavoは、実装LUTの原則に驚嘆しています。 関数ブールy=(a&b)|を考えてみましょう。 〜c。 Її回路設計と真理値表は少し示しています。 関数には3つの引数があるため、2 ^ 3=8の値があります。 それらのスキンは、入力信号の組み合わせを可能にします。 値はFPGAファームウェア拡張プログラムによって計算され、特別な構成メモリに記録されます。
中間値のスキン値がLUTマルチプレクサの出力に入力され、ブール関数の入力引数が選択されて、関数の他の値が選択されます。 CLBは最も重要なFPGAハードウェアリソースです。 今日のFPGAクリスタルのCLBの量は、クリスタルのタイプと容量によって異なり、発生する可能性があります。 ザイリンクスには、CLBの量が約4000〜300万の結晶が含まれている場合があります。
Crim CLB、ミドルFPGAはまだ重要度の低いハードウェアリソースです。 たとえば、ハードウェアブロックは、累積ブロックまたはDSPブロックの倍数です。 それらのスキンは、スキンサイクルの18ビット数を乗算および折りたたむために使用できます。 トップクリスタルの場合、DSPブロックの数は6000を超える可能性があります。
2番目のリソースは、内部メモリのすべてのブロック(Block RAM、BRAM)です。 スキンブロックは2KBを節約できます。 Povnaは、そのようなメモリであり、水晶の休耕地であり、20Kバイトから20Mバイトに達する可能性があります。 CLBと同様に、BRAMおよびDSPブロックはスイッチングマトリックスによって接続され、水晶全体に浸透します。 CLB、DSP、およびBRAMブロックをリンクすることにより、さらに効率的なデータ処理スキームを使用できます。
FPGAの利点
1985年にザイリンクスによって作成された最初のFPGAチップには、64を超えるCLBがあります。 当時、マイクロ回路へのトランジスタの統合は、一度に非常に低く、デジタルデバイスでは、「ルーズロジック」のマイクロ回路が勝利を収めることがよくありました。 レジスター、リチルニック、マルチプレクサー、マルチプライヤーのマイクロ回路もありました。 具体的には、アタッチメントは、低集積度のマイクロ回路が設置された独自のボードによって作成されました。
Wikoristannya FPGAは、このアプローチに従うことを許可しました。 64CLB上のNavitFPGAは、他のボードのスペースを大幅に節約します。再構成が可能であるため、1時間の操作の準備ができた後、「現場で」(名前と名前-フィールドプログラマブル)のように、アタッチメントの機能をアップグレードできます。ゲートアレイ)。
FPGAの途中でハードウェアデジタル回路を作成できるため(最も重要なことはリソースを取得することです)、最も重要なPLICプロジェクトの1つはASICチップのプロトタイピングです。
ASICの開発はより複雑で費用がかかり、許しの代償はさらに高く、ロジックをテストする力は非常に重要です。 したがって、回路の物理トポロジに関する作業の開発の最初の段階の1つは、1つまたは複数のFPGAクリスタルでのプロトタイピングでした。
ASIC拡張では、相互に接続された多くのFPGAをカバーするために特別なボードが発行されます。 マイクロ回路のプロトタイプは、かなり低い周波数(おそらく数十メガヘルツ)で動作しますが、特定された問題やバグを節約することもできます。
しかし、私の意見では、іsnuyutcіkavіshizastosuvannyaPLISです。 FPGAの柔軟な構造により、アルゴリズムを変更する機能を備えたデータの高幅並列処理用のハードウェア回路の実装が可能になります。
 ハードウェアプラットフォームのペアリング
ハードウェアプラットフォームのペアリング CPU、GPU、FPGA、ASICが基本的に何であるかを考えてみましょう。 CPUはユニバーサルであり、その上で最も柔軟なアルゴリズムを実行でき、多数のプログラムやミドルウェアを簡単に実現できます。
この場合、汎用性と最後のCPU命令により、生産性が低下し、回路の電源が増加します。 CPUの算術演算のスキンには、命令の読み取り、レジスタとキャッシュ間のデータの移動、およびその他の本体の変更に関連する多くの追加の演算があることに注意してください。
反対側にはASICがあります。 このプラットフォームでは、トランジスタを直接接続するために必要なアルゴリズムがハードウェアに実装されており、すべての操作はアルゴリズムにのみ関連しており、変更することはできません。 エネルギー効率が最も低いプラットフォームの最大の生産性をご覧ください。 また、ASIC軸を再プログラムすることはできません。
CPUの右側にはGPUがあります。 マイクロ回路は、グラフィックスを処理するために分割されましたが、同時にハッキングされ、マイニングのために、主な機能を計算しました。 悪臭は、数千の小さなカウント核と、データの配列に対する並列操作でのカウントで構成されています。
アルゴリズムを並列化できる場合、GPUではCPUと比較して大幅な高速化を実現できます。 一方、次のアルゴリズムはより高速に実装されるため、プラットフォームの柔軟性が低く、CPUが低くなります。 また、GPUの開発には、特別なスキルの母、OpenCLとCUDAの知識が必要です。
Zreshtoy、FPGA。 このプラットフォームは、プログラムを変更できるため、ASICの効率が向上します。 PLISは普遍的ではありませんが、あるクラスのアルゴリズムとタスクを使用するため、CPUとGPUの生産性が向上し、生産性が低下します。 FPGAのディストリビューションの折りたたみ性はより高く、protenovіzasobirozrobki rozrobytseirozryvはより小さくなっています。
FPGAの重要なポイントは、応答の遅延を最小限に抑えながら、選択したペースでデータを処理する必要があることです。 例として、多数のポートを備えたスマートインターフェイスルーターを明らかにすることができます。ポートの1つにイーサネットパケットが必要な場合は、匿名ルールを逆にして、最初に発信ポートを選択する必要があります。 必要に応じて、パッケージの実際のフィールドを変更したり、新しいフィールドを追加したりすることができます。
FPGAバリアントを使用すると、タスクを変更できます。パケットのバイトがメディアインターフェイスのマイクロ回路に入り始めたばかりであり、そのヘッダーはすでに分析されています。 ここでプロセッサを選択すると、トラフィックの処理速度が大幅に向上します。 推奨されるASICチップをルーターに使用できることは明らかですが、これが最も効率的な方法ですが、なぜパケット処理ルールを変更する必要があるのでしょうか。 FPGAのみを支援する高い生産性で、将来必要な柔軟性を実現します。
このランクでは、FPGAが勝ち、高いデータ処理の生産性、最短の反応時間、および低消費電力が必要です。
クラウド内のFPGA
悲観的なFPGA課金では、迅速なアカウントが必要であり、トラフィックとデータアレイへのアクセスを高速化します。 ここでは、取引所での高頻度取引用のFPGAスイッチボードを見ることができます。 サーバーには、PCI ExpressとIntel(Altera)またはザイリンクスの光インターフェイスを備えたFPGAボードが挿入されます。
暗号化アルゴリズムはFPGAに直接影響を与え、DNA配列と科学的タスクを分子動力学の展望に合わせます。 Microsoftは、Bing jockeyサービスを高速化し、Azureの真ん中でソフトウェア定義ネットワークを編成したことでFPGAを長い間獲得してきました。
機械学習のブームはFPGAをバイパスしていません。 ザイリンクスとIntelは、ディープニューロトランスミッターと連携するFPGAベースのチップを提案しています。 FPGAファームウェアを使用できるため、CaffeとTensorFlowの中間フレームワークなしで同じものを実装できます。
さらに、あなたは家と牧師の悲観的なサービスを離れることなくすべてを試すことができます。 たとえば、Amazonは、FPGAボードや、機械学習を含むあらゆる種類の開発ツールにアクセスできる仮想マシンをレンタルできます。
エッジ上のFPGA
セミはFPGAで他に何ができますか? その学校は恥ずかしがり屋ではありません! ロボット工学、無人機、ドローン、科学機器、医療機器、corystuvalモバイルアタッチメント、スマートビデオ監視カメラなど。
従来、FPGAは、レーダーアタッチメントのシングルモード信号のデジタル処理(およびDSPプロセッサと競合)に使用され、無線信号を受信していました。 マイクロ回路の統合の増加とFPGAプラットフォームの生産性の向上に伴い、たとえば「暗闇の端」での2つの世界の信号の処理など、高性能計算の停滞がますます進んでいます。コンピューティング)。
この概念は、車の番号を認識する機能を備えた車の交通を分析するためのビデオカメラに基づいて理解しやすくなっています。 イーサネット経由でビデオを送信する機能を備えたカメラを撮影し、リモートサーバーで処理することができます。 カメラの数が増えると、カメラの数も増え、システム障害につながる可能性があります。
ビデオカメラの本体に直接取り付けられたエンコーダーで数字の認識を実装し、暗闇の中で車の数字をテキスト形式に転送する方が効率的です。 この目的のために、低消費電力で同等に安価なFPGAを使用して、バッテリーを使用することができます。 これにより、たとえば車番号の基準を変更する場合など、FPGAロボットのロジックを変更することができなくなります。
ロボット工学とドローンに関して言えば、この分野では、高い生産性と低いエネルギーという2つの心を克服することが特に重要です。 ドローンのフィールドコントローラーを作成するには、FPGAプラットフォームの方が適していて、勝利を収めることができます。 彼らは多くの解決策を賞賛することができるので、すでに同時にUAVを咆哮します。
FPGAでのプロジェクトの開発
Іsnuyetraznііvnіデザイン:低、ブロック、高。 最も一般的なタイプのVerilogタイプまたはVHDLへの低レベルの転送。これは、レジスタ転送レベル(RTL-レジスタ転送レベル)でのみ使用できます。 このようにして、プロセッサのようにレジスタを形成し、それらの間でデータを変更する論理関数を指定します。
FPGA回路は常に最高のクロック速度(100〜300 MHz)で動作し、等しいRTLで、システム周波数の正確なクロックに対する回路の動作を決定します。 この少しの作業は、生産性、FPGAクリスタルのリソース削減、およびエネルギー節約の観点から最も効率的なスキームを作成するために行われます。 しかし、ここでは回路の真剣なスキルが必要であり、それらを使用すると、プロセスは非標準になります。
ブロックレベルでは、必要なシステムオンチップ機能を削除するために、機能を選択しているかのようにすでに準備ができている優れたブロックの開発に、より重要に関与します。
高レベルの設計で、皮膚のタクトに関するデータを制御しなくなったため、アルゴリズムに集中します。 コンパイラまたはトランスレータを使用して、CおよびC++をRTL(Vivado HLSなど)に変換します。 ハードウェアレベルで幅広いクラスのアルゴリズムを変換できるようにするdositrazumnyを使用してください。
RTL movsの前のこのようなアプローチの主な問題は、アルゴリズムの開発と特にテストを高速化することです。C++コードはコンピューターで実行および検証でき、よりリッチでテストが少なくなり、アルゴリズムを変更します。 RTLレベル。 zruchnіst、zvichaynoの場合、支払う必要があります-スキームはそれほど速くなく、より多くのハードウェアリソースを借りることができます。
多くの場合、代償を払う準備ができています。トランスレータを正しく調整するために、効率はそれほど低下せず、最新のFPGAのリソースは十分です。 市場投入までの時間の重要な指標がある世界では、それは真実であるように見えます。
多くの場合、1つのデザインで、3つのスタイルのデザインすべてを組み合わせる必要があります。 アタッチメントを作成する必要があるとします。これをロボットに入れて建物に渡し、ビデオストリーム内のオブジェクト(道路標識など)を認識します。 ビデオセンサーチップを取り、FPGAに直接接続してみましょう。 カスタマイズには、HDMIモニターとFPGAへの接続を使用できます。
カメラからのフレームは、センサーピッカー(ここではUSBは問題ではありません)によって事前に決定されたインターフェイスを介してFPGAに転送され、処理されてモニターに表示されます。 フレームを処理するには、元のDDRメモリにあるフレームバッファが必要です。このサウンドは、FPGAチップの順序で別のボードにインストールされています。
 一般的なFPGAプロジェクトのブロック図
一般的なFPGAプロジェクトのブロック図 ビデオセンサーメーカーはFPGAチップにインターフェイスIPを提供していないため、データ転送プロトコルの仕様に応じて、クロック、ビット、ビットに応じて独自のRTLを作成する必要があります。 前処理、DDRコントローラー、HDMI IP miをブロックし、すべてに適しています。簡単に操作して、インターフェースを取得できます。 また、検索およびデータ処理のように見えるHLSブロックは、C ++で記述し、VivadoHLSを変換して支援を求めることができます。
何よりも、FPGAバージョンに適合した道路標識の検出器と分類器のライブラリを準備する必要があります。 このアプリケーションでは、明らかに、設計のフローチャートが非常に単純化されていますが、ロボットのロジックが正しく表示されません。
RTLコードの記述からFPGAキャプチャ用のコンフィギュレーションファイルの開始までのデザインパスを見てみましょう。
デザインの方法次に、必要なスキーマを実装するRTLコードを記述します。 まず第一に、あなたは実際に再考する必要があります、あなたは再考する必要があります、それは正しいですそして必要な仕事を修正します。 RTLモデリングがコンピューターのシミュレーターで行われる人。
とりあえずRTLコードでのみ表示される回路を仮想スタンドに置き、回路の入力にデジタル信号のシーケンスを適用し、出力を図に登録し、出力信号の時間を確認し、確認します。結果。 あなたはRTLが書かれるまで回る許しを知っているように聞こえます。
Daliは、コードがプログラムシンセサイザーへの入力に送信されることを論理的に検証します。 彼女は、回路のテキスト記述を、このFPGAダイで使用可能なライブラリのデジタル要素のリストに変換しています。 このリストには、LUT、トリガー、それらの間のリンクなどの要素が含まれます。 この段階では、要素はまだ特定のハードウェアリソースに関連付けられていません。 これを行うには、回路に制約を適用する必要があります。たとえば、回路の出力を論理的に入力するためのFPGAマイクロ回路の導入と視覚化の物理的な接触を使用してzocremaを適用します。
これらの交換では、回路の原因となるクロック周波数を示す必要もあります。 シンセサイザーとファイルの出力は実装プロセッサーに渡され、実装プロセッサーはさらに配置とルーティング(配置とルーティング)を行います。
ネットリスト要素のスキンドックを配置するプロセスは、FPGAチップの中央にある特定の要素にバインドします。 次に、ルートプロセスを開始します。これは、PLICスイッチングマトリックスの特定の構成に対するこれらの要素の最適な構成を知るのに役立ちます。
場所とルートは境界線を超えており、回路上にオーバーレイされています:入出力接点とクロック周波数。 クロック周波数の周期は、実装にさらに強く影響します。障害は、最後の2つのトリガー間のクリティカルランスの論理要素のクロック遅延が小さく、低いことのせいではありません。
多くの場合、私は満足せずにはいられません。次に、最初の段階に戻ってRTLコードを変更する必要があります。たとえば、重要な言語でロジックを高速化してみてください。 実装が正常に完了すると、要素がどのように認識され、悪臭がどのように発生するかがわかります。
少し後、FPGAファームウェアのバイナリファイルを作成するプロセス。 本物のzalizoでヨガzavantazhitを失い、再確認します。 問題の原因となるステージの数、以降、モデリングは不正確であり、すべての恩赦と欠点を使用したステージの数。
シミュレーションの段階に移り、ランダムな状況をシミュレートすることができますが、そうでない場合でも、ホールで問題なく改善のメカニズムを転送するという極限まで機能します。 1時間に表示する信号を指定すると、分析の途中で追加のロジックアナライザ回路が生成されるため、回路とともに水晶に注文が出され、チャープする信号に接続されて、時間ごとの値。 必要な信号の図による時間の節約は、コンピューター上で実行して分析することができます。
SUCHASHNYhアトラクションでのVICORISTANNYPLIS
トゥピコフ・パブロ・アンドリヨビッチ
5年生、芸術学科OmDTU、ロシア連邦、m。オムスク
この日、論理集積回路(PLIC)のプログラミングは、さまざまな現代の別棟でますます混雑しています。これは、PLICが最も強力なデジタルマイクロ回路によって大きな利点を持っている可能性があるためです。 これらの進歩が見られる前に:
・pokraschuyusya時計の特徴virobu。
・価格が変わります。
・ビロバの寸法を変更します。
・ディスクリートマイクロサーキットの数の変化(ディスクリートマイクロ回路の数の変化)
・振動の柔軟性を移動します(PLISはいつでも再プログラムできます)
PLISアーキテクチャは折りたたむことができます(図1)
図1.FPGAの内部構造
小さなものからわかるように、PLISの主要部分は、論理ブロックのプログラミングと内部リンクのプログラミングで構成されています。
プログラミング(ファームウェア)PLISのプロセスそのものが、入力と出力の間に必要な接続を形成するために使用されます。
この日、世界にはPLISの最前線に世界の2人のリーダーがいます。 すべてのアメリカ企業ザイリンクスとアルテラ。
皮革会社は、FPGAロボット用に独自のCADを推進しています。 ザイリンクスは、ザイリンクスソフトウェア開発キット(SDK)を宣伝しています。 アルテラは、Max + PlusIIとQuartusII、およびModelSimシミュレーションシステムを推進しています。
ファームウェアプログラムを作成するには、ロボット機器の映画の説明を呼び出します。これは、今日最も広く、そのような最も広いmoviです。
VerilogHDL。
MovaVHDLєNUBILSHはホーガンのために折りたたまれ、エールは抽象のバケツの機能で泥だらけであり、メンチは移動のベネです。

図2.等しい抽象化 Verilog і VHDL
Verilog HDLロボットのお尻は、Mini-DiLabスタンドのPLIC CYCLONE III EP3C5E1444C8Nに実装されたプログラムであり、図1のそのような表現の見事な外観です。 3.3。

図3 ミニ - DiLab
このプログラムは、追加のボタンpbaおよびpbbの「vognik」動作を増やすことを選択して、led0-led7ライトの後続の切り替えを実装し、追加のスイッチsw0、sw1の切り替えを制御します。
//プログラムテキスト
モジュール事業( 出力導いた、 入力 clk_25mhz、 入力 pba、 入力 pbb、
入力 sw);
//プロジェクトへの内部ドキュメントの割り当て
ワイヤー s1;
ワイヤー s2;
ワイヤー s3;
//プロジェクトに接続されている他のファイル(サブプログラム)を呼び出します
Tr tr_1(.out(s2)、. set(pba)、.res(pbb));
カウンターcounter_1(.q(s1)、. clk(clk_25mhz)、. up(s2));
Mx mx_1(.a(s3)、. in(s1)、. load(sw));
Dc3_8 dc3_8_1(.out(led)、.in(s3));
エンドモジュール//プログラムの終了
サブプログラムtr
モジュール tr(out、set、res); //プログラムの作成
//入力の割り当て/visnovkіv
出力regアウト;
入力設定;
入力 res;
//初期化
イニシャル
始める
外<= 1"d0;
//メインプログラムコード
いつも @(ネゲッジセットまたは ネゲッジ res)
始める
もしも(〜(セット))
外<= 1"d1;
そうしないと
外<= 1"d0;
endmodule //プログラムの終了
サブプログラムカウンター
モジュール counter(con、q、clk、up); //Cobプログラム
出力reg詐欺;
出力 q = con;
入力アップ、clk;
//メインプログラムコード
いつも @(ポーズ clk)
始める
もしも(clk)
もしも(上)
コン<= con - 1"d1;
そうしないと
コン<= con + 1"d1;
エンドモジュール//Kіnetsプログラム
サブプログラムmx(マルチプレクサ)
モジュール mx( output.reg a、 入力の、 入力ロード);
//メインプログラムコード
いつも @*
始める
場合(ロード)
2 "b00:a = in;
2 "b01:a = in;
2 "b10:a = in;
2 "b11:a = in;
エンドケース
エンドモジュール // プログラムの終了
サブプログラムdc3_8(マルチプレクサ)
モジュール dc3_8(out、in); //Cobプログラム
//入力/出力の割り当て
output.regアウト;
入力線の;
//メインプログラムコード
いつも @*
始める
場合(の)
3 "d0:out = 8" b11111110;
3 "d1:out = 8" b11111101;
3 "d2:out = 8" b11111011;
3 "d3:out = 8" b11110111;
3 "d4:out = 8" b11101111;
3 "d5:out = 8" b11011111;
3 "d6:out = 8" b10111111;
3 "d7:out = 8" b01111111;
エンドケース
エンドモジュール // プログラムの終了
プログラムはCADQuartusIIによって実装されました。
プログラムをコンパイルした後、コンパイラは、プログラムの分析と構文のために、プログラムによって尊重される許しを見ていません(図4)。

図4.プロジェクトの概要ウィンドウ
Quartus IIのライセンス数(学習用のプログラムの無料バージョンがありました)とプロジェクトのモデリングに必要なファイルの数について話すことは、コンパイラーによって尊重されています。
このプロジェクトの構造を図1に示します。 5.5。

図5.プロジェクトの実装( RTL 構造)
ヤクを図1に示します。 6このプログラムでは、このPLISの可能性のほんのわずかな部分しかありません。

図6.ロボットプロジェクトに参加するFPGAの一部
ヴィスノフキ:プログラミング論理集積回路は、アクセサリに詰まっている可能性があります。 彼らとの仕事を学ぶために、彼らは無線電子機器の設計と建設に関連する専門分野のプログラムに導入されるべきであり、機器の説明に精通している必要があります(VerilogHDLおよびVHDL)。
文献のリスト:
1. Grushevitskiy R.I. プログラムロジックマイクロサーキットに基づくシステムの設計/R.I. Hrushevitsky、A.Kh。 ムルサエフ、E.P。 しかめっ面。 サンクトペテルブルク:BHVピーターズバーグ、2002年。-608ページ。
2.コロモフD.A. Altra MAX +plusIIおよびQuartusIIのコンピューター支援設計システム。 セルフリーダーの簡単な説明/D.A. コロモフ、R.A。 Myalk、A.A. ゾベンコ、O.S。 Pylypiv。 M:IP RadioSoft、2002年。-126ページ。
3. MaxfieldK.PLISの設計。 若い兵士のコース。 /K.マックスフィールド。 M .:Vydavnichydіm"Dodeka-XXI"、2007.-408p。 (英語からの翻訳)。