Оптимізація запитів MySQL. Оптимізація MySQL запитів MySQL кілька запитів в одному
У цій невеликій статті мова піде про бази даних зокрема MySQL, вибірку та підрахунок. Працюючи з базами даних, часто потрібно здійснити підрахунок кількості рядків COUNT() з певною умовою або без, це зробити вкрай просто наступним запитом
Перегляд коду MySQL
Запит поверне значення з кількістю рядків у таблиці.
Підрахунок з умовою
Перегляд коду MySQL
Запит поверне значення з кількістю рядків у таблиці, що задовольняють даній умові: var = 1
Для отримання кількох значень підрахунку рядків з різними умовами можна по черзі виконати кілька запитів, наприклад
Перегляд коду MySQL
Але в ряді випадків такий підхід не практичний і не оптимальний. Тому актуальним стає організація запиту, з кількома підзапитами, для отримання в одному запиті відразу кілька результатів. Наприклад
Перегляд коду MySQL
Таким чином, виконавши лише один запит до бази даних, ми отримуємо результат з підрахунком кількості рядків за кількома умовами, що містить кілька значень підрахунку, наприклад
Перегляд коду TEXT
| c1|c2|c3 -------- 1 |5 |8 |
Недоліком використання підзапитів у порівнянні з кількома окремими запитами можна вважати швидкість виконання та навантаження на базу даних.
Наступний приклад запиту, що містить кілька COUNT в одному запиті MySQL, побудований дещо інакше, в ньому використовуються конструкції IF (умова, значення 1, значення 2), а також підсумовування SUM (). Дозволяють зробити відбір даних за заданими критеріями в рамках одного запиту, потім підсумувати їх, і вивести кілька значень як результат.
Перегляд коду MySQL
Як видно із запиту, він побудований досить лаконічно, але швидкість його виконання теж не порадувала, результат цього запиту буде наступним,
Перегляд коду TEXT
| total|c1|c2|c3 -------------- 14 |1 |5 |8 |
Далі я наведу порівняльну статистику швидкості виконання трьох варіантів запитів для вибірки декількох COUNT(). Для тестування швидкості виконання запитів було виконано по 1000 запитів кожного типу з таблицею, що містить більше трьох тисяч записів. При цьому щоразу запит містив SQL_NO_CACHE для вимкнення кешування результатів базою даних.
Швидкість виконання
Три окремі запити: 0.9 сек
Один запит із підзапитами: 0.95 сек
Один запит з конструкцією IF та SUM: 1.5 сек
Висновок. Отже, ми маємо кілька варіантів побудови запитів до бази даних MySQL з кількома COUNT(), перший варіант з окремими запитами не дуже зручний, але має найкращий результат за швидкістю. Другий варіант із підзапитами дещо зручніше, але при цьому швидкість його виконання трохи нижча. І нарешті третій лаконічний варіант запиту з конструкціями IF і SUM, що здається найзручнішим, має найнижчу швидкість виконання, яка майже вдвічі нижча за перші два варіанти. Тому, при задачі оптимізації роботи БД, я рекомендую використовувати другий варіант запиту, що містить підзапити з COUNT(), по-перше його швидкість виконання близька до найшвидшого результату, по-друге така організація всередині одного запиту досить зручна.
Минулого уроку ми зіткнулися з однією незручністю. Коли ми хотіли дізнатися, хто створив тему "велосипеди", і робили відповідний запит:
Замість імені автора ми отримували його ідентифікатор. Це і зрозуміло, адже ми робили запит до однієї таблиці – Теми, а імена авторів тем зберігаються в іншій таблиці – Користувачі. Тому, дізнавшись ідентифікатор автора теми, нам треба зробити ще один запит – до таблиці Користувачі, щоб дізнатися його ім'я:

SQL передбачає можливість об'єднувати такі запити в один шляхом перетворення одного з них в підзапит (вкладений запит). Отже, щоб дізнатися, хто створив тему "велосипеди", ми зробимо наступний запит:

Тобто після ключового слова WHERE, за умови ми записуємо ще один запит. MySQL спочатку обробляє підзапит, повертає id_author=2 і це значення передається в пропозицію WHEREзовнішнього запиту.
В одному запиті може бути кілька підзапитів, синтаксис такий запит: Зверніть увагу, що підзапити можуть вибирати тільки один стовпець, значення якого вони повертатимуть зовнішньому запиту. Спроба вибрати кілька стовпців призведе до помилки.
Давайте для закріплення складемо ще один запит, дізнаємося які повідомлення на форумі залишав автор теми "велосипеди":
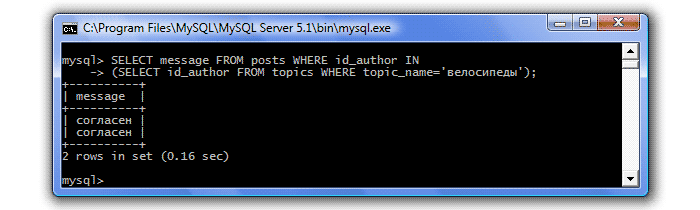
Тепер ускладнимо завдання, дізнаємося, в яких темах залишав повідомлення автор теми "велосипеди":

Давайте розберемося, як це працює.
- Спочатку MySQL виконає найглибший запит:
- Отриманий результат (id_author=2) передасть зовнішній запит, який набуде вигляду:
- Отриманий результат (id_topic:4,1) передасть у зовнішній запит, який набуде вигляду:
- І видасть остаточний результат (topic_name: про рибалку, про рибалку). Тобто. автор теми "велосипеди" залишав повідомлення у темі "Про рибалку", створену Сергієм (id=1) та в темі "Про рибалку", створену Світлом (id=4).
- Не рекомендується створювати запити зі ступенем вкладення більше трьох. Це призводить до збільшення часу виконання та до складності сприйняття коду.
- Наведений синтаксис вкладених запитів, швидше за найбільш вживаний, але зовсім не єдиний. Наприклад, ми могли б замість запиту
написати
Тобто. ми можемо використовувати будь-які оператори, які використовуються з ключовим словом WHERE (їх ми вивчали у минулому уроці).
Оптимізація MySQL запитів
- MySQL
У повсякденній роботі доводиться мати справу з досить однотипними помилками під час написання запитів.
У цій статті хотілося б навести приклади того, як не треба писати запити.
- Вибірка всіх полів
SELECT * FROM tableПід час написання запитів не використовуйте вибірку всіх полів - "*". Перерахуйте лише ті поля, які вам справді потрібні. Це скоротить кількість даних, що вибираються і пересилаються. Крім цього, не забувайте про індекси, що покривають. Навіть якщо вам дійсно необхідні всі поля в таблиці, краще їх перерахувати. По-перше, це підвищує читабельність коду. При використанні зірочки неможливо дізнатися, які поля є в таблиці без заглядання в неї. По-друге, згодом кількість стовпців у вашій таблиці може змінюватися, і якщо сьогодні це п'ять INT стовпців, то через місяць можуть додатись TEXT та BLOB поля, які уповільнюватимуть вибірку.
- Запити у циклі.
Потрібно чітко уявляти, що SQL - мова, оперуючий множинами. Іноді програмістам, які звикли думати термінами процедурних мов, важко перебудувати мислення на мову множин. Це можна зробити досить просто, взявши на озброєння просте правило - ніколи не виконувати запити в циклі. Приклади того, як це можна зробити:1. Вибірки
$news_ids = get_list("SELECT news_id FROM today_news");
while($news_id = get_next($news_ids))
$news = get_row("SELECT title, body FROM news WHERE news_id = ". $news_id);Правило дуже просте - що менше запитів, то краще (хоча з цього, як і з будь-якого правила, є винятки). Не забувайте про конструкцію IN(). Наведений код можна написати одним запитом:
SELECT title, body FROM today_news INNER JOIN news USING(news_id)2. Вставки
$log = parse_log();
while($record = next($log))
query("INSERT INTO logs SET value = ". $log["value"]);!}Набагато більш ефективно склеїти та виконати один запит:
INSERT INTO logs (value) VALUES (...), (...)3. Оновлення
Іноді потрібно оновити кілька рядків в одній таблиці. Якщо значення, що оновлюється, однакове, то все просто:
UPDATE news SET title="test" WHERE id IN (1, 2, 3).!}Якщо значення для кожного запису різне, то це можна зробити таким запитом:
UPDATE news SET
title = CASE
WHEN news_id = 1 THEN "aa"
WHEN news_id = 2 THEN "bb" END
WHERE news_id IN (1, 2)Наші тести показують, що такий запит виконується в 2-3 рази швидше ніж кілька окремих запитів.
- Виконання операцій над проіндексованими полями
SELECT user_id FROM users WHERE blogs_count * 2 = $valueУ такому запиті індекс не використовуватиметься, навіть якщо стовпець blogs_count проіндексований. Щоб індекс використовувався, над проіндексованим полем у запиті не повинно виконуватися перетворень. Для таких запитів виносите функції перетворення на іншу частину:
SELECT user_id FROM users WHERE blogs_count = $value / 2;Аналогічний приклад:
SELECT user_id FROM users WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(registered)<= 10;Не буде використовувати індекс по полю registered, тоді як
SELECT user_id FROM users WHERE registered >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
буде. - Вибір рядків тільки для підрахунку їх кількості
$result = mysql_query("SELECT * FROM table", $link);
$num_rows = mysql_num_rows($result);
Якщо вам потрібно вибрати кількість рядків, які відповідають певній умові, використовуйте запит SELECT COUNT(*) FROM table, а не вибирайте всі рядки лише для того, щоб підрахувати їх кількість. - Вибірка зайвих рядків
$result = mysql_query("SELECT * FROM table1", $link);
while($row = mysql_fetch_assoc($result) && $i< 20) {
…
}
Якщо вам потрібні лише n рядків вибірки, використовуйте LIMIT замість того, щоб відкидати зайві рядки в програмі. - Використання ORDER BY RAND()
SELECT * FROM table ORDER BY RAND() LIMIT 1;Якщо таблиці більше, ніж 4-5 тисяч рядків, то ORDER BY RAND() працюватиме дуже повільно. Набагато ефективніше виконати два запити:
Якщо в таблиці auto_increment"ний первинний ключ і немає перепусток:
$rnd = rand(1, query("SELECT MAX(id) FROM table"));
$row = query("SELECT * FROM table WHERE id = ".$rnd);Або:
$cnt = query("SELECT COUNT(*) FROM table");
$row = query("SELECT * FROM table LIMIT ".$cnt.", 1");
що, однак, може бути повільним при дуже велику кількість рядків у таблиці. - Використання великої кількості JOIN
SELECT
v.video_id
a.name,
g.genre
FROM
videos AS v
LEFT JOIN
link_actors_videos AS la ON la.video_id = v.video_id
LEFT JOIN
actors AS a ON a.actor_id = la.actor_id
LEFT JOIN
link_genre_video AS lg ON lg.video_id = v.video_id
LEFT JOIN
genres AS g ON g.genre_id = lg.genre_idПотрібно пам'ятати, що при зв'язку таблиць кількість рядків у вибірці зростатиме при кожному черговому JOIN'е. Для подібних випадків швидшим буває розбити подібний запит на кілька простих.
- Використання LIMIT
SELECT… FROM table LIMIT $start, $per_pageБагато хто думає, що подібний запит поверне $per_page записів (зазвичай 10-20) і тому спрацює швидко. Він і спрацює швидко для перших кількох сторінок. Але якщо кількість записів велика, і потрібно виконати запит SELECT ... FROM table LIMIT 1000000, 1000020, то для виконання такого запиту MySQL спочатку вибере 1000020 записів, відкине перший мільйон і поверне 20. Це може бути зовсім не швидко. Тривіальних шляхів вирішення проблеми немає. Багато хто просто обмежує кількість доступних сторінок розумним числом. Також можна прискорити подібні запити використанням індексів, що покривають, або сторонніх рішень (наприклад sphinx).
- Невикористання ON DUPLICATE KEY UPDATE
$row = query("SELECT * FROM table WHERE id=1");If($row)
query("UPDATE table SET column = column + 1 WHERE id=1")
else
query("INSERT INTO table SET column = 1, id=1");Подібну конструкцію можна замінити одним запитом за умови наявності первинного або унікального ключа по полю id:
INSERT INTO table SET column = 1, id=1 ON DUPLICATE KEY UPDATE column = column + 1
Я вже писав про найрізноманітніші SQL-запитах, але настав час поговорити і про складніші речі, наприклад, SQL-запит на вибірку записів з кількох таблиць.
Коли ми з Вами робили вибірку з однієї таблиці, все було дуже просто:
SELECT назви_потрібних_полів FROM назва_таблиці WHERE умова_вибірки
Все дуже просто і тривіально, але при вибірці відразу з кількох таблицьстає дещо складніше. Одна з труднощів – це збіг імен полів. Наприклад, у кожній таблиці є поле id.
Давайте розглянемо такий запит:
SELECT * FROM table_1, table_2 WHERE table_1.id > table_2.user_id
Багатьом, хто не займався подібними запитами, здасться, що все дуже просто, подумавши, що тут додалися лише назви таблиць перед назвами полів. Фактично це дозволяє уникнути протиріч між однаковими іменами полів. Однак, складність не в цьому, а в алгоритм роботи подібного SQL-запиту.
Алгоритм роботи наступний: береться перший запис з table_1. Береться idцього запису з table_1. Далі повністю виглядає таблиця table_2. І додаються всі записи, де значення поля user_idменше idвибраного запису в table_1. Таким чином, після першої ітерації може з'явитися від 0 до нескінченної кількостірезультуючих записів. На наступній ітерації береться наступний запис таблиці table_1. Знову проглядається вся таблиця table_2, і знову спрацьовує умову вибірки table_1.id > table_2.user_id. Всі записи, що задовольнили цю умову, додаються до результату. На виході може вийти дуже багато записів, у багато разів перевищують сумарний обсяг обох таблиць.
Якщо Ви зрозуміли, як це працює після першого разу, то дуже здорово, а якщо ні, то читайте доти, доки не вникнете остаточно. Якщо Ви це зрозумієте, далі буде простіше.
Попередній SQL-запитяк такий, рідко використовується. Він був просто дано для пояснення алгоритму вибірки з кількох таблиць. А тепер же розберемо більш присадкуватий SQL-запит. Допустимо, у нас є дві таблиці: з товарами (є поле owner_id, відповідального за idвласника товару) та з користувачами (є поле id). Ми хочемо одним SQL-запитомотримати всі записи, причому щоб у кожній була інформація про користувача та його один товар. У наступному записі була інформація про того ж користувача і наступний його товар. Коли товари цього користувача закінчаться, переходити до наступного користувача. Таким чином, ми повинні з'єднати дві таблиці та отримати результат, в якому кожен запис містить інформацію про користувача та про один його товар.
Подібний запит замінить 2 SQL-запити: на вибірку окремо з таблиці з товарами та з таблиці з користувачами. До того ж, такий запит одразу поставить у відповідність користувача та його товар.
Сам запит дуже простий (якщо Ви зрозуміли попередній):
SELECT * FROM users, products WHERE users.id = products.owner_id
Алгоритм тут вже нескладний: береться перший запис таблиці users. Далі береться її idта аналізуються всі записи з таблиці products, додаючи в результат ті, у яких owner_idдорівнює idз таблиці users. Таким чином, на першій ітерації збираються усі товари у першого користувача. На другій ітерації збираються всі товари другого користувача і таке інше.
Як бачите, SQL-запити на вибірку з кількох таблицьне найпростіші, але користь від них буває колосальна, тому знати та вміти використовувати подібні запити дуже бажано.