Парсер ключові слова. Працюємо з Yandex Wordstat Парсер ключових слів онлайн яндекс
Парсер ключових слів — це налаштування Datacol, яке автоматично збирає запити зі статистики сервісу Wordstatза заданими користувачем ключовими словами.Таким чином, вам необхідно лише задати базові ключові слова, після чого Datacol самостійно збере інформацію за похідними запитами. Поряд із запитами зберігається частота показів кожного запиту на місяць. При парсингу Datacol відбувається по всіх сторінках видачі Wordstat.
- За допомогою парсеру WordstatВи зможете зібрати запити та частоту показу зі статистики;
- Вам потрібно вказати лише список ключових слів, дані, за якими Вам необхідно зібрати;
- Зберігайте зібрану інформацію у будь-якому зручному форматі ( Excel, TXT, WordPress, MySQLі т.д.).
Парсинг Wordstatпередбачає обробку Javascript, а також необхідність авторизації для збору даних. Таку можливість ми отримуємо завдяки плагіну. Під час запуску кампанії Datacolвідкриє один або більше екземплярів браузера Chromeдля завантаження через них веб-сторінок. Кількість працюючих екземплярів Chromeдорівнює кількості потоків кампанії. Зверніть увагу, що ініціалізація екземплярів браузерів може тривати деякий час.
Ким і для чого використовується парсер ключових слів яндекса
Парсер ключових слів найчастіше використовується фахівцями з пошукового просування сайтів. Зокрема це стосується реалізації завдання складання семантичного ядра сайту. Зазначимо, що нижче йдеться про просування сайтів у рунеті. У цьому контексті більш актуальний парсер ключових слів індекс директа.
Парсер пошукових запитів директа
Для початку опишемо стандартну схему роботи парсера директора.
1.
Користувач задає пошукові запити, похідні яких потрібно зібрати.
2.
Парсер авторизується на яндексі і починає ширяти яндекс вордстат по черзі для кожного запиту.
3.
Для кожного запиту виходять похідні ключові слова з першої сторінки видачі директа, але й усіх наступних.
В результаті на виході ми маємо досить багато варіантів ключових слів, які надалі використовуються для формування семантичного ядра сайту.
Парсер ключовиків та кількості показів - "слизький момент"
Зазначимо, що окрім ключових слів ми отримуємо так звану кількість показів, що «прогнозується» — показник до якого варто ставитися дуже обережно. Для початку розберемося, що про це значення пише сам Яндекс:
У результатах виводиться статистика запитів пошукової системи Яндекс, що містять задане слово або словосполучення, та інших запитів, які здійснювали люди, що шукали його (праворуч).
Цифри поруч із кожним запитом у результатах видачі вордстат дають попередній прогноз кількості показів на місяць, що ви матимете, вибравши даний запит як ключове слово.
Помилка багатьох оптимізаторів полягає в тому, що вони читають лише першу частину опису, і при цьому — читають не зовсім уважно. Йдемо далі:
Цифра поруч із словом «телевізор» означає кількість показів за всіма запитами, що включають слово «телевізор»: «купити телевізор», «плазмовий телевізор», «купити плазмовий телевізор», «купити новий плазмовий телевізор» тощо.
Ви вже здогадалися, на що ми натякаємо? Отже, ви повинні зрозуміти головне — при парсингу похідних запитів Wordstat не варто звертати увагу на показник їх частотності, оскільки це значення підсумовується з частотностей всіх похідних запитів.
Але як у такому разі визначити які ключові слова «жирніші», а які менші? Відразу розвінчуємо помилкову думку, що похідні ключові слова завжди мають менше реальних показів, що основні. Це відверта нісенітниця! Знайти реальні кількості показів ключових слів (з відрахуванням кількості показів похідних) нам дозволить оператори лапки. Таким чином, для пошуку запитів та визначення "жирних" необхідно застосовувати наступну схему:
1.
Запуск парсер ключів для пошуку похідних.
2.
Взяти всі похідні запити та відпарсувати кількість показів кожного, задаючи запит у лапках.
Ми згодні, що це дещо довший і складніший шлях. Однак уявіть ситуацію. Ви маєте близько 500 запитів, за якими ви хочете просунути основний сайт. 30 з них є (на вашу первісну думку, тобто за спочатку спарсенной статистикою Wordstat) найбільш високочастотними. Далі ви витрачаєте 3 місяці часу і кілька тисяч убитих єнотів (та хлопці — якісне просування цей дорогий і тривалий захід) і в результаті виявляється, що пошукового трафіку в кілька разів менше, ніж очікувалося. Ви сильно засмучуєтеся, шукайте професійного фахівця з просування і він вам розплющує очі на те, що ви просували зовсім не ті запити, які наводять трафік (зокрема він показує вам реальну статистику за запитами в лапках).
Тестування парсера запитів
На нашому сайті ви можете безкоштовно скачати парсер ключових слів яндекса і протестувати його. Ми також можемо обговорити налаштування парсера кеїв, яке перевірятиме значення зібраних запитів у лапках.
Тестування парсера Wordstat
Щоб протестувати роботу парсера Wordstat:
Крок 1.Встановіть . Демо-версія програми має всі можливості платної, але зберігає лише перші 25 результатівпарсингу.
Крок 2У дереві кампаній є кампанія seo-parsers/wordstat-keywords-parser.par. Виберіть її та натисніть кнопку Запуск (Play). Перед запуском можна редагувати Вхідні дані, щоб змінити набір базових запитів, за якими збиратиметься статистика

клацніть на зображенні для збільшення
Після запуску кампанії відкривається вікно браузера, в якому необхідно ввести авторизаційні дані для доступу до статистики Wordstat.
Якщо у вас великий проект із семантичним ядром на кілька сотень або тисяч запитів, погодьтеся, сидіти у Вордстаті і підбирати їх вручну здасться витонченим тортуром. Добре, що є програми-помічники, здатні взяти основну частину рутинної роботи на себе. Одна з таких програм називається Словоїб.
Що таке Словоєб
Словоїб (Slovoeb)- Безкоштовна (і значно урізана за функціоналом) версія програми, що полюбилася професійним оптимізаторам. Більшість функцій КейКоллетора звичайному користувачеві навряд чи знадобиться, тому можна обійтися Словом для вирішення головного завдання - підбору ключових слів.
До речі, платний KeyCollector дозволяє парсити слова і з Google AdWords – це особливо корисно, якщо ваш сайт орієнтований насамперед на країни, де основний трафік дає саме Google. Безкоштовний Slovoeb обмежений лише Яндексом.
Для початку потрібно завантажити програму Словоїб. Зробити це можна за посиланням у блозі SEOM.info.
Програма не потребує встановлення. Просто розпакуйте архів у будь-яке зручне місце на комп'ютері та запустіть Slovoeb.exe. Надалі всі ваші налаштування зберігатимуться у вибраній папці. Перед початком роботи не забудьте прочитати матеріал – інформація в статті актуальна і для цієї програми.
Налаштування Slovoeb
Ось що ми побачимо після запуску:
Перш ніж розпочати роботу, необхідно виконати ряд налаштувань. Перше – вказати облікові записи Яндекса для парсингу ключових слів. Нагадую, що працювати у Вордстаті можна лише після авторизації. Тому раджу штук п'ять акаунтів, спеціально призначених для Словоеба. Не використовуйте спецсимволи впаролях цих облікових записів!
Не раджу використовувати свій справжній обліковий запис, оскільки програма робить дуже багато запитів до Яндекса за одиницю часу, за що можна отримати санкції.
Натисніть значок шестерні у верхній лівій частині вікна програми та перейдіть до налаштувань.
Виберіть вкладку Yandex.Direct і введіть дані облікових записів у форматі Логін: Пароль. За бажанням можна вказати і проксі. Обов'язково прочитайте пам'ятку у вікні опцій!

Раджу вивчити та змінити інші налаштування софту.
Автоматичне розпізнавання капчі
Наступним кроком є автоматизація розпізнавання капчі. Погодьтеся, який сенс у програмі, якщо вона щоразу вимагає від вас вручну вводити капчу, що видається Яндексом. Оскільки Словоїб багато разів надсилатиме запити до Яндекса за короткий проміжок часу, капчі неминучі.
Я користуюсь сервісом Antigate. За бажанням ви можете скористатися й іншими програмами. Slovoeb підтримує такі:
- Antigate
- CaptchaBot
- RIPCaptcha
- ruCaptcha
- SocialLink
Про багатьох із них я раніше ніколи не чув.
У випадку з Антигейтом є нюанс: вони переїхали на новий сайт (хоча старий все ще доступний). Вони використовують спільну базу, тому на обох сайтах єдиний обліковий запис. На якому реєструватись – вирішувати вам. Перший класичний, спартанський, більш звичний для веб-майстрів зі стажем. Другий сучасніший.
Врахуйте, що Antigate платний. Але недорогий. Мені вистачає 1 долар на 2 місяці роботи (а то й більше).
Перейдіть на сторінку налаштувань антикапчі, натиснувши вкладку в лівій частині вікна налаштувань.
В полі Antigate Keyвведіть ключ антикапчі. Отримати його можна у налаштуваннях профілю Antigate.

На цьому базове налаштування Словоєба завершено.
Підбір ключових слів за допомогою Словооб
Настав час приступити безпосередньо до підбору запитів. Для цього необхідно створити новий проект. Усі дані зберігаються у файл. Таких файлів може бути необмежену кількість, так що ви легко зможете перемикатися між проектами.
Натисніть на кнопку "Створити проект":
У вікні виберіть, куди зберегти файл і як його назвати. Я зазвичай називаю файли на ім'я сайту і зберігаю в папку проекту (там, де лежать всі інші дані щодо нього). Хтось тримає всі файли Словоєба у єдиній папці. Кому як зручніше.
Наступний крок після створення проекту – налаштування регіону. Якщо ваш сайт орієнтований лише на певний регіон (або регіони), вам потрібна статистика пошукових запитів саме по ньому, а не по всьому світу. Натисніть кнопку вибору регіону та встановіть потрібні вам галочки.
Тут так само, як в інтерфейсі Вордстата:

Настав час підбору ключових слів!
Для початку підбору запитів натисніть на кнопку “ Пакетний збір запитів із лівої колонки Yandex.WordstatЯк показано на скріншоті.
У вікні, введіть ключові слова, на основі яких ви хочете підібрати запити. Все так само, як в інтерфейсі Вордстату. Головна відмінність – у програмі ви можете ввести відразу кілька слів, і програма працюватиме з ними по черзі, а у Вордстаті потрібно працювати з кожним словом по черзі, вручну, що значно збільшує час роботи.

Натисніть на кнопку " Почати збір“. Ура, тепер можна піти зробити каву або перейти на інші завдання. Словоєбу знадобиться час, щоб зібрати запити.
Стоп-слова
Після того як програма відпарсила ключові слова, необхідно відфільтрувати їх, відкинувши поєднання і формулювання, що нас не цікавлять. Це можна зробити за допомогою стоп-слів. Натисніть на велику кнопку “ Стоп-слова” із зображенням щита. У вікні, клікніть по кнопці “ Додати списком“. У ще одному вікні перерахуйте стоп-слова (кожне з нового рядка), яких не повинно бути у вашому пошуковому запиті. Наприклад, нас не цікавлять запити зі словами "завантажити", "торрент", "нова версія", "остання версія" і т. д., оскільки ми розповсюджуємо не саму програму, а лише її опис.
Після введення стоп-слів натисніть кнопку “ Відзначити фрази у таблиці” у нижньому лівому куті вікна стоп-слів.
Робота з частотністю в Словоїб
Залишився один аспект: частотність запитів, що відображається в колонці, - це базова частотність, тобто фраза з усіма словоформами. Щоб визначити частотності за допомогою операторів, клацніть по кнопці із зображенням лупи та виберіть “ Зібрати частотність виду ” ” “.
Один із найбільш популярних модулів у Rush Analytics – парсер Яндекс Вордстат, і це не випадково. При зборі семантичного ядра необхідно точно знати частотність зібраних запитів, щоб правильно розставити пріоритети просування і позбудеться «сміттєвих» і нульових запитів. Часто стоїть завдання пробити кілька десятків тисяч запитів на частотність в Яндексі, але це не зовсім просте завдання для самописних парсерів Вордстату та десктопних програм, і ось чому:
- Yandex Wordstat має гарний захист від парсингу, наприклад бан IP-адрес з яких здійснюється парсинг і викидання капчі у відповідь на запити від ботів. Щоб ефективно збирати дані з Wordstat, потрібен ефективний алгоритм підключення IP-адрес та інші хитрощі
- Для парсингу великої кількості даних за допомогою десктопних програм знадобиться багато IP-адрес (проксі), які Яндекс з легкістю банить при неоптимальному алгоритмі підключення, а проксі – недешеве задоволення
- Також для парсингу знадобиться автоматичне введення великої кількості капчі (наприклад підключення Antigate для цього завдання). Цей фактор, при неоптимальному алгоритмі парсингу, може зробити сам парсинг нерентабельним, тому що вартість капчі буде надмірно високою.
- Більшість десктопних програм немає захисту від втрати даних під час збору. Так, наприклад, зібравши половину даних і витративши на це гроші, при збої в парсері, ви ризикуєте не тільки не отримати дані, але й втратити вже зібрані
Парсинг Яндекс Вордстат у Rush Analytics
Враховуючи всі труднощі, які можуть виникнути при парсингу Вордстата, ми зробили свій парсер Wordstat максимально швидким, зручним і стійким до максимальної кількості проблем, пов'язаних з парсингом:
- Жодних проксі та капчі! Вам більше не потрібно думати про лазню ваших проксі або величезну кількість капчі, яку видає Яндекс. Просто створіть проект, завантажте ключові слова та чекайте на готовий файл з результатом
- Висока швидкість парсингу. Наші алгоритми використовують оптимальну схему підключення IP-адрес та інші хитрощі, щоб зробити швидкість парсингу феноменально високою – ви й не помітите, як ваш проект буде виконано!
- Збереження даних. Створюючи проект у нашому парсері, ви можете бути впевнені, що він буде успішно завершений та доступний для скачування у будь-який час та з будь-якої точки світу – усі дані зберігаються у хмарі!
- Підтримка всіх регіонів Яндекса. Багато користувачів мають потребу визначати частотність запитів в Яндексі не тільки по регіону «Москва» або «Росія», але й по інших, включаючи «Україну» та «Білорусь». У Rush Analytics ви зможете визначити частотність запитів у будь-якому регіоні, який підтримує Яндекс на даний момент.
- Збір усіх частотностей. За допомогою нашого парсера ви зможете зібрати всі частотності: пошуковий запит, пошуковий запит, пошуковий запит.

- Збір лівої колонки Wordstat. Крім перевірки частотності запитів, доступний збір ключових слів з лівої колонки Wordstat з налаштуванням глибини парсингу від однієї сторінки до збору всіх сторінок, що мають у лівій колонці.
- Збір правої колонки Wordstat. Доступний збір ключових слів із правої колонки Wordstat.
Якщо вам потрібний швидкісний збір частотностей Яндекс Wordstat - Rush Analytics найкраще рішення, особливо якщо вам потрібно збирати великі обсяги даних. Для користувачів з потребою збору понад 100 000 запитів на місяць передбачені індивідуальні умови, просто напишіть на нашу підтримку на
Яндекс Вордстат – це сервіс компанії Яндекс, який використовується для підбору ключових слів шляхом аналізу запитів користувачів.
Навіщо потрібний Вордстат
В основному він застосовується для складання семантичного ядра. Wordstat безкоштовний, він є багатофункціональним інструментом, але настільки простим, що розібратися зможе навіть новачок. За допомогою Вордстату можна дізнатися докладну статистику запитів у системі Яндекс за останній місяць, та скласти не лише структуру цілого сайту, а й окремих його сторінок. У практиці сервіс застосовується на вирішення наступних проблем:
- Збір найповнішої семантики за рахунок розширень запитів;
- Перевірка частотності запитів, у тому числі регіональної;
- Перевірка сезонності запитів.
Це найголовніше, але є звичайно і більш дрібні завдання, які допомагають вирішити Wordstat.
Як правильно користуватись Вордстатом
Спершу там треба зареєструватися. Ось посилання на сервіс, ви можете і без реєстрації вводити в ньому слова, але результати дізнаватися зможете тільки після реєстрації. Інакше спливатиме така херня:
Також важливо, щоб у вашому профілі в Яндексі був вказаний ваш регіон, за яким ви збираєтеся дивитися статистику запиту. Інакше, якщо ви шукатимете, скільки клієнтів для вашого бізнесу вводять у ваших Нижніх Васюках слово «вудочки», а у вас стоїть регіон Москва, то вам може видати, що сотні тисяч людей шукають вудки. Ви накупите їх сотню тисяч, а в Нижніх Васюках їх шукають лише пара калік.
Після того, як зареготаєтеся, вводите там слово і натисніть кнопку «Підібрати». Ви отримаєте такі результати:

Як бачите, ми ввели слово «браток», і в лівій колонці будуть запити, в яких є фраза «браток». Ці запити вводяться реальні користувачі. У правій колонці схожі запити. Цифри поруч із кожним запитом — це їх частотність (тобто як часто їх вводять). Але це точна частотність, а приблизна. Тобто саму фразу «браток» саме в такій формі може вводити раз 20 всього (тобто точна частотність у неї 20 тоді), але разом із фразами «братки», «братки 90», «давай браток» та іншими у неї частотність 27 080. Точну частотність ми навчимося визначати далі.
В основному з Вордстат працюють через спеціальні сервіси і програми. Тисячі їх! Найвідоміша - Кей Колектор. Всі ці програми підвищують зручність роботи з цим інструментом у рази.
Безпосередньо з Вордстат працюють дуже рідко, проте я чув офігенні історії, що в студії Ашманова, однієї з найкрутіших SEO-студій, сидять мавпи, які кожен запит вводять в Вордстат руками і копіюють видачу в.txt-файл. Я одразу представив сотню рабів, які за день роботи виконують такий самий обсяг, як один сеошник із Кей Колектором.
Давайте тепер дивитися інші функції інтерфейсу:
У блоці 1— Переключення між типом пристроїв. Я особисто не використовую. Я роблю свої сайти зручними для всіх типів пристроїв.
У блоці 2- Дуже корисний перемикач. З його допомогою можна подивитися, по-перше, регіональність запиту (у якому регіоні його вводять частіше, у якому рідше). Можна серйозно залипнути на цьому інструменті. А по-друге, тут можна подивитися «Історію запиту» — і це дійсно іноді дуже потрібно для визначення сезонності запиту і для відстеження тренду.
У блоці 3— дата, коли востаннє Яндекс оновлював статистику на запити. Найчастіше нам це не потрібно.
У блоці 4- Вибираємо регіон/регіони.
По регіонах
Можна подивитися, де шукають. Смішна штука. Тут, наприклад, можна з'ясувати, що блатні пісні в середньому на душу населення найбільше шукають зовсім на РФ, а в Греції і в Ізраїлі:

А якщо ви натиснете на Росію, то побачите, що блатняк затребуваний скрізь, але особливо — в Дагестані:

Історія запиту
В історії запиту можна визначати сезонні запити та тренди, як я вже казав. Наприклад, ми можемо лише заздрити тим вебмайстрам, хто встиг написати статті про Трампа, тому що зараз (кінець 2016) у них почалося зростання трафіку:

Але найпрофесійніше починається, коли ви працюєте з операторами.
Які оператори корисні при роботі з Wordstat
Потрібно знати, як користуватися операторами Яндекс Вордстату, щоб найефективніше працювати в інтерфейсі.
Базові оператори
Два базові оператори — слово оклику і лапки. Це ази азів.
Дивіться, без них у нас 25655 показів. Це покази всіх фраз зі словом «браток».

З лапками ж всього 832. Лапки фіксують фразу. Це означає, що 832 покази — у фраз «браток», «братка», «братку», разом узятих, тобто у цієї фрази з різним порядком слів та закінченнями, але без додавання до цієї фрази інших слів. Тобто сюди не включаються покази фраз ми братки, завалили братка і так далі.

З знаком оклику — 7409 показів. Він фіксує словоформу. Тобто сюди включаються покази фраз «браток», «ніштяк браток», «тримайся браток» та інших із таким самим закінченням. А покази фраз «зателефонувати браткові», «завантажити пісню про братка» тощо — не включаються.

А тут ми маємо лише 152 покази. Це тому, що зі знаком оклику і лапками враховуються покази тільки цієї фрази і тільки в цій формі. Але з різним порядком слів у фразі. Тобто якщо ми введемо «ніштяк браток», то Вордстат нам покаже суму показів «ніштяк браток» та «браток ніштяк».

Допоміжні оператори
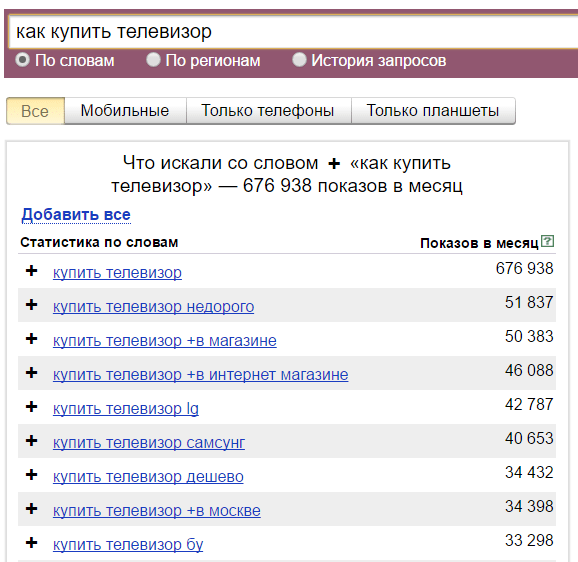
Плюс. Символ "+" примусово враховує стоп-слова. За промовчанням Вордстат не враховує прийменники, і за запитом «як придбати телевізор» покаже вам в основному комерційні запити:
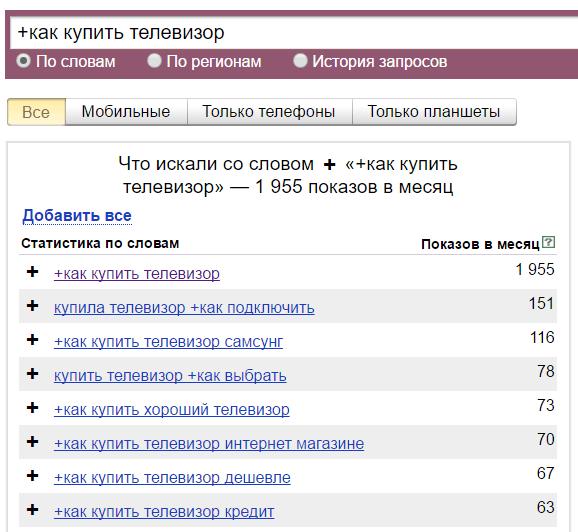
Якщо вам важлива частка «як», то зафіксуйте її плюсом і Wordstat дасть такі дані:
Оператор "АБО". Прямий слеш «|» - Якщо дві фрази розділити цим оператором, він покаже всі варіації з цими двома фразами.

Він, до речі, дозволяє провести порівняння двох запитів, для цього я його в основному і використовую.
Мінус. Символ "-" виключає конкретне слово із запиту. Приклад: "купити машину в Москві -бу". Буде показано запити без вживання слова «бу».

Круглі дужки "()" - групує використання декількох операторів.

Квадратні дужки «» – фіксує послідовність слів у пошуковій фразі. Цей оператор запровадили нещодавно. Тобто ми отримуємо можливість дізнатися, з яким порядком слів фразу вводять найчастіше:

Як бачимо, із неправильним порядком фразу майже ніхто не вводить:

Плагіни
Працювати з голим Яндекс Wordstat загалом незручно. Щоб полегшити свою працю, можна встановити собі в браузер спеціальний плагін, призначений для роботи з Wordstat. Плагіни для браузерів Хроміума (Яндекса, Мейла, Аміго, Опери та Гугл Хрома) однакові, а ось для Мозили йде окремий плагін, всі є безкоштовними та доступними для скачування, встановлювати їх можна відразу з браузера. Найбільш популярні - плагіни Wordstat Assistant та Yandex Wordstat Helper.
Yandex Wordstat Assistant
Мабуть, найкращий плагін для wordstat.yandex.ru. Я сам ним користуюся. Він зручний у використанні, практичний та не заважає, коли ви працюєте на інших сайтах. Встановлений wordstat assistant запускається лише у разі переходу на сторінку Вордстату. Шляхом натискання на плюсики, потрібне ключове слово можна додати до списку (він знаходиться ліворуч). У помічник є можливість відсортувати обрані ключові слова, а непотрібні видалити. Список, що вийшов, просто скопіюйте в буфер обміну, і перенесіть в Excel для подальшої обробки. До речі, зручність використання плагіна ще й у тому, що коли ви додаєте до списку фрази, що вже знаходяться там, дублі автоматично видаляються, що істотно скорочує роботу.
Yandex Wordstat Helper
Цей плагін простіше, ніж попередній, але не менш популярний, його можна встановлювати прямо з браузера. Хелпер зроблений у вигляді віджету, який додається на сторінку вордстату відразу після установки, потрібно просто оновити сторінку і можна розпочинати роботу. Його функції:
- Можливість автоматичного сортування за абеткою;
- Перевіряє наявність дублів, видаляючи останні;
- Є можливість обробки різних запитів у кількох вкладках браузера. Потрібні слова додаються в той самий список;
- Є лічильник слів;
- Можливість копіювання вже готового списку в Excel, зібравши все докупи за початковими фразами.
Перш ніж вирішити, який плагін використовувати, спробуйте в дії і той, і інший, це дозволить вам зробити правильний вибір.
Парсери Вордстату
Для економії часу під час підбору ключових слів часто користуються спеціально призначеними для цього автоматичними програмами – парсерами, які можуть бути як платними, так і безкоштовними.
Деякі пацани замовляють парсери та чисто під свої потреби.
Найкращий платний парсер Wordstat - KeyCollector. Використовують його переважно ті, хто професійно займається складанням семантики. Безкоштовним аналогом КейКоллектора є програма Словоїб. Функції його урізані, але становити невеликі ядра з його допомогою цілком реально.
Магадан теж досить популярний парсер Вордстат, який також можна безкоштовно скачати. Підбирає та аналізує запити, є підтримка регіонів, призначений для парсингу фраз Яндекс Директа.
Під кінець хочу відзначити, що Вордстат дає тільки ті дані, які має Яндекс. Тому наприклад частотність у Гуглі та інших пошукових системах може бути зовсім інша.
Найперше, що потрібно з'ясувати: що таке парсить. Можливо, Ви знаєте це визначення, і навіть якщо ні, зрозуміти буде легко. Парсіті (Parsing)– означає збирати інформацію з якогось джерела з подальшою обробкою даних. Якщо говорити про окремі випадки, парсинг у seo (по-іншому парсинг пошукової видачі) – це збір та аналіз статистики запитів користувачів.
Пошукові системи також використовують парсинг. Так, пошукові роботи парсят, аналізуючи веб-сторінки і заносячи інформацію про них до бази даних пошукових систем.
Яндекс.Вордстат – сервіс дуже корисний у SEO. Але працювати з ним можна тільки за наявності облікового запису Яндекс. Він дозволяє підбирати ключові слова на основі запитів користувачів, щоб скласти з них семантичне ядро.
Насамперед, необхідно визначити тематику. Що ви продаєте? Які послуги Ви надаєте? Визначивши свою тематику і що будете вимагати, можна починати користуватися Вордстат.
Введіть свій запит у рядок пошуку. І розширюєте його з допомогою виданих результатів.
Результати формуються у дві колонки. Цифра поруч із запитом – прогнозована кількість показів на місяць, яку можна отримати, вибравши запит, що сподобався, ключовою фразою. Прогноз триває за останні 30 днів до дати оновлення статистики.
Можна налаштувати, щоб видача відображалась у регіонах. Якщо Ви надаєте послуги тільки в Москві, виберіть вкладку «Всі регіони» (вона знаходиться трохи нижче за пошуковий рядок) і налаштуйте під себе.
У лівій колонці всі фрази зі словами Вашого запиту, і слова в ній відсортовані за зменшенням частоти показів. Вам важливо відразу виділити варіанти розширених ключів, які будуть для вашого проекту цільовими. Цільові - це запити, за якими користувач, який вводить запит до пошукової системи, може знайти потрібне йому на Вашому сайті. Цільові фрази будуть більш низькочастотними, і користувачі, які прийшли за ними з видачі, зможуть знайти те, що хотіли, а отже, не залишать Ваш сайт відразу. Вам важливі ці відвідувачі, адже саме вони можуть вчинити цільову дію – купити товар чи замовити послугу.
Перевірте вибрані фрази – виключіть ті, у яких частота близька до нуля. Для цього скористайтесь оператором “ “ (Кивачки).

Після цього переходьте до правої колонки.
У правій колонці відображаються запити, схожі на Ваші. Зібравши потрібне, не забудьте перевірити фрази оператором " " (Кивачки).

Набравши достатньо ключових фраз, Ви приступаєте до наступного етапу: діліть фрази за частотністю. На цьому Вашу роботу з Вордстатом завершено.
За деякими ключовими словами, Вордстат видає неправильну інформацію. Як її перевірити? Перейдіть на вкладку «Історія запитів» та зверніть увагу на статистику.
Показання статистики представлені у 2-х графіках: абсолютне та відносне.

Абсолютний показник- Це фактичне значення показів у різні періоди часу. А відносний показник – це відношення показів за запитом, що цікавить, до загальної кількості показів у мережі. Він демонструє популярність запиту серед усіх інших.
Якщо графік відносного значення вище абсолютного, то, можливо, йде автоматична накрутка запиту, або інтерес до запиту вище за норму. Можливо, це пов'язано із сезоном. Так попит на лижі вищий узимку.
Процес парсингу можна автоматизувати. В цьому випадку можливе використання не лише платних та безкоштовних програм, але й розширень для браузера.
1. Розширення браузера Yandex Wordstat Assistant.Встановлюєте його в браузер, і при роботі з Яндекс.Вордстат зліва з'явиться панель, в яку ви зможете зібрати ключові слова, що сподобалися.

2. Key Collector- Програма платна, але високофункціональна.
- У налаштуваннях є вкладка Yandex.Wordstat. Перейшовши на неї, Ви можете встановити глибину парсингу. Так можна зібрати більше ключів. Але рекомендується ставити 0 щоб не збільшувати час. А ключі можна розширити й іншим способом, а часу на їхнє збирання піде менше. Максимальна кількість сторінок для парсингу в Yandex.Wordstat дорівнює 40. На кожній сторінці знаходиться до 50 фраз. Таким чином, максимальна кількість результатів за однією фразою в Вордстат – 2000. І якщо Ви хочете зібрати більше даних, Вам потрібно розширити список слів, додавши уточнюючі слова. Наприклад, не просто "капуста", а "цвітна капуста", "виробництво капусти" і т.д.;