ความเร็วเป็นตัวกำหนดพลังของแดนิชผู้ยิ่งใหญ่ สารานุกรมการตลาด วิธีการต่อสู้
ข้อมูลใหญ่- ภาษาอังกฤษ. "ข้อมูลที่ดี". คำนี้กลายเป็นทางเลือกแทน DBMS และกลายเป็นหนึ่งในแนวโน้มหลักในโครงสร้างพื้นฐานด้านไอที เนื่องจากยักษ์ใหญ่ในอุตสาหกรรมส่วนใหญ่ - IBM, Microsoft, HP, Oracle และอื่นๆ เริ่มมีความเข้าใจในกลยุทธ์ของตนมากขึ้น บิ๊กดาต้าเป็นอาร์เรย์ข้อมูลขนาดใหญ่ (หลายร้อยเทราไบต์) ที่ไม่สามารถประมวลผลด้วยวิธีการแบบเดิมได้ inodi - เครื่องมือสำหรับวิธีการประมวลผลข้อมูล
สมัคร Big Data gerel: รองรับ RFID, การแจ้งเตือนโซเชียลมีเดีย, สถิติอุตุนิยมวิทยา, ข้อมูลเกี่ยวกับตำแหน่งของสมาชิกมือถือ เนคไทสไตล์และข้อมูลจากสิ่งอำนวยความสะดวกในการบันทึกเสียง/วิดีโอ นั่นคือเหตุผลที่ "บรรณาการอันยิ่งใหญ่" ได้รับการยกย่องอย่างกว้างขวางสำหรับแคมเปญ, การคุ้มครองสุขภาพ, การบริหารรัฐ, ธุรกิจอินเทอร์เน็ต - ผู้ระดมทุนสำหรับการวิเคราะห์กลุ่มเป้าหมายเป็นเวลาหนึ่งชั่วโมง
ลักษณะ
สัญญาณของข้อมูลขนาดใหญ่ถูกทำเครื่องหมายเป็น "three V": Volume - obsyag (dіysno big); ความหลากหลาย - ความหลากหลายไม่มีตัวตน; ความเร็ว - ความนุ่มนวล (จำเป็นสำหรับการห่อแบบสวีเดน)
ข้อมูลที่ยอดเยี่ยมส่วนใหญ่ไม่มีโครงสร้าง และการประมวลผลต้องใช้อัลกอริธึมพิเศษ ก่อนวิธีการวิเคราะห์ข้อมูลที่ดี เราสามารถเห็น:
- (“Vydobuvannya danikh”) – ความซับซ้อนของความรู้สีน้ำตาลซึ่งสามารถกำจัดได้ด้วยวิธีการมาตรฐาน
- Crowdsourcing (ฝูงชน - "natovp", การจัดหา - vikoristannya yak dzherelo) - สัญญาณของอาสาสมัคร zavdan spolnymi zassilly ที่สำคัญ, yakіไม่ perebuvayut ในสัญญาแรงงานที่มีผลผูกพันและ vodnosinah, scho ประสานงานกิจกรรมสำหรับเครื่องมือไอทีเพิ่มเติม
- Data Fusion & Integration (“zmishuvannya และ provodzhennya danih”) - ชุดของวิธีการสำหรับการก่อตัวของ dzherel ที่ไม่มีตัวตนภายในกรอบของการวิเคราะห์เชิงลึก
- การเรียนรู้ด้วยเครื่อง ("การเรียนรู้ของเครื่อง") - การพัฒนาความฉลาดของชิ้นส่วนซึ่งพัฒนาวิธีการพัฒนาการวิเคราะห์สถิติและการพยากรณ์ตามแบบจำลองพื้นฐาน
- การจดจำภาพ (เช่น การจดจำลักษณะที่ปรากฏของกล้องวิดีโอหรือกล้องวิดีโอ)
- การวิเคราะห์การขยาย - การเลือกโทโพโลยี เรขาคณิต และภูมิศาสตร์เพื่อเป็นแรงบันดาลใจ
- การสร้างภาพข้อมูล - การสร้างภาพข้อมูลการวิเคราะห์ในภาพประกอบและไดอะแกรมสำหรับเครื่องมือและแอนิเมชั่นเชิงโต้ตอบเพิ่มเติมเพื่อให้เห็นภาพผลลัพธ์และเป็นแรงบันดาลใจให้รากฐานของการตรวจสอบระยะไกล
ทางเลือกและการวิเคราะห์ข้อมูลขึ้นอยู่กับเซิร์ฟเวอร์จำนวนมากที่ให้ผลผลิตสูง เทคโนโลยีหลักคือ Hadoop พร้อมโอเพ่นโค้ด
หากมีข้อมูลจำนวนมากขึ้นเป็นครั้งคราวเท่านั้น การพับไม่ได้เกี่ยวกับการรับข้อมูล แต่เกี่ยวกับวิธีการประมวลผลด้วยน้ำหนักสูงสุด โดยทั่วไป กระบวนการทำงานกับ Big Data ประกอบด้วย: การรวบรวมข้อมูล โครงสร้าง การสร้างข้อมูลเชิงลึกและบริบท การพัฒนาคำแนะนำในการดำเนินการ แม้กระทั่งก่อนขั้นตอนแรก การกำหนดวิธีการทำงานเป็นสิ่งสำคัญ: navіscho potrіbnіdanіเดียวกันเช่น - การกำหนดผลิตภัณฑ์cіlovoїauditorії มิฉะนั้น ให้นำบันทึกจำนวนมากออกไปโดยไม่เข้าใจว่าคุณสามารถเอาชนะมันได้ด้วยตัวเอง
Peredmova
"ข้อมูลขนาดใหญ่" เป็นศัพท์ใหม่ที่ทันสมัยซึ่งปรากฏในการประชุมระดับมืออาชีพทั้งหมดที่ทุ่มเทให้กับการวิเคราะห์ข้อมูล การวิเคราะห์เชิงคาดการณ์ การวิเคราะห์ข้อมูลทางปัญญา ( การขุดข้อมูล), ซีอาร์เอ็ม. คำนี้ได้รับชัยชนะในด้านที่เกี่ยวข้องกับการทำงานกับข้อผูกมัดด้านข้อมูลที่ยิ่งใหญ่กว่านั้น การเพิ่มขึ้นอย่างต่อเนื่องในความปลอดภัยของกระแสข้อมูลในกระบวนการขององค์กร: เศรษฐศาสตร์ กิจกรรมการธนาคาร การผลิต การตลาด โทรคมนาคม การวิเคราะห์เว็บ ยา
ร่วมกับการสะสมข้อมูลอย่างรวดเร็ว เทคโนโลยีการวิเคราะห์ข้อมูลกำลังพัฒนาอย่างรวดเร็ว ยิ่งไปกว่านั้น เป็นไปได้ พูดน้อยลง แบ่งกลุ่มลูกค้าออกเป็นกลุ่มที่มีความคล้ายคลึงกัน ตอนนี้มันเป็นไปได้ที่จะสร้างแบบจำลองสำหรับไคลเอนต์สกินในโหมดเรียลไทม์ วิเคราะห์ ตัวอย่างเช่น การย้ายผ่านอินเทอร์เน็ตเพื่อค้นหา ผลิตภัณฑ์เฉพาะ สามารถวิเคราะห์ความสนใจของสายลับได้ และตามรูปแบบที่แนะนำ จะมีการแสดงโฆษณาเฉพาะหรือข้อเสนอเฉพาะ โมเดลนี้ยังสามารถอัปเดตและทำงานใหม่ได้ในโหมดเรียลไทม์ซึ่งเป็นเวรเป็นกรรมมากกว่าที่คาดไม่ถึง
В галузі телекомунікації, наприклад, розвинені технології для визначення фізичного розташування стільникових телефонів та їх власників, і, здається, незабаром стане реальністю ідея, описана у науково-фантастичному фільмі «Особлива думка», 2002 року, де відображення рекламної інформації в торгових центрах враховувала інтереси osib เฉพาะ scho เพื่อส่ง poz
ในขณะเดียวกัน สถานการณ์ก็กำลังถูกตรวจสอบ หากเทคโนโลยีใหม่ๆ หลั่งไหลเข้ามามากมายอาจนำไปสู่ความผิดหวัง ตัวอย่างเช่น การดึงข้อมูลอื่นๆ ( ข้อมูลกระจัดกระจาย) สิ่งที่จะให้การกระทำrozumіnnyaที่สำคัญ, єมั่งคั่งtsіnіshimi, nizh ส่วยใหญ่(Big Data) ซึ่งอธิบายการเผามักไม่ใช่ข้อมูลเดิม
Metadata ของบทความ - เพื่อชี้แจงและคิดเกี่ยวกับความเป็นไปได้ใหม่ของ Big Data และเพื่อแสดงเป็นแพลตฟอร์มการวิเคราะห์ สถิติ StatSoft สามารถช่วยคุณด้วย Big Data ที่มีประสิทธิภาพเพื่อเพิ่มประสิทธิภาพกระบวนการของคุณและบรรลุเป้าหมาย
บิ๊กดาต้าใหญ่แค่ไหน?
เห็นได้ชัดว่าคำตอบที่ถูกต้องในห่วงโซ่อาหารอาจฟังดู - "นอนลง ... "
ในการอภิปรายในปัจจุบัน ความเข้าใจใน Big Data ถูกอธิบายว่าเป็น obsyagu ที่ให้มาในระบบเทราไบต์
ในทางปฏิบัติ (วิธีการเกี่ยวกับกิกะไบต์หรือเทราไบต์) ข้อมูลดังกล่าวสามารถบันทึกและจัดเก็บได้อย่างง่ายดายด้วยความช่วยเหลือของฐานข้อมูล "ดั้งเดิม" และการครอบครองมาตรฐาน (เซิร์ฟเวอร์ฐานข้อมูล)
ความปลอดภัยของซอฟต์แวร์ สถิติเทคโนโลยี vikoristovu Rich Flow สำหรับอัลกอริธึมการเข้าถึงข้อมูล (การอ่าน) โมเดลการทำงานซ้ำ และการพยากรณ์ (และการให้คะแนน) จึงสามารถวิเคราะห์การเลือกข้อมูลได้อย่างง่ายดายและไม่ต้องใช้เครื่องมือพิเศษใดๆ
โปรเจ็กต์อินไลน์ของ StatSoft บางโปรเจ็กต์มีประมาณ 9-12 ล้านแถว ลองคูณด้วยพารามิเตอร์ 1,000 รายการ (การเปลี่ยนแปลง) ที่เลือกและจัดระเบียบจากการรวบรวมข้อมูลเพื่อสร้างแรงบันดาลใจแบบจำลองการคาดการณ์ที่มีความเสี่ยง ไฟล์ดังกล่าวมีขนาดประมาณ 100 กิกะไบต์ เห็นได้ชัดว่านี่ไม่ใช่ชุดข้อมูลขนาดเล็ก แต่อย่าพยายามเอาชนะความสามารถของเทคโนโลยีฐานข้อมูลมาตรฐาน
สายผลิตภัณฑ์ สถิติสำหรับการวิเคราะห์แบบกลุ่มและแบบจำลองการให้คะแนนแบบกระตุ้น ( สถิติองค์กร) โซลูชันที่ทำงานในโหมดเรียลไทม์ ( สถิติคะแนนสด) และเครื่องมือวิเคราะห์สำหรับการสร้างและจัดการแบบจำลอง ( ตัวขุดข้อมูลสถิติ) สามารถปรับขนาดได้อย่างง่ายดายบนเซิร์ฟเวอร์ขนาดเล็กที่มีโปรเซสเซอร์แบบมัลติคอร์
ในทางปฏิบัติ หมายความว่ามีความยืดหยุ่นเพียงพอของแบบจำลองหุ่นยนต์และการวิเคราะห์ (เช่น การคาดการณ์ความเสี่ยงด้านเครดิตต่ำ เสถียรภาพทางการเงิน สถาบันอุดมศึกษา ฯลฯ) สถิติ.
จากการเผชิญหน้าข้อมูลขนาดใหญ่สู่ข้อมูลขนาดใหญ่
ตามกฎแล้ว การอภิปรายของ Big Data จะเน้นไปที่การรวบรวมข้อมูลบางส่วน (และการวิเคราะห์ที่ดำเนินการตามการรวบรวมดังกล่าว) โดยทั่วไปจะมีมากกว่านั้นมาก น้อยกว่าเพียงแค่เทราไบต์
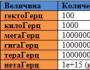
Zakrema, deyakі danicheskah สามารถเติบโตได้มากถึงหนึ่งพันเทราไบต์จากนั้นสูงถึงเพตาไบต์ (1,000 เทราไบต์ = 1 เทราไบต์)
นอกเหนือจากเพทาไบต์แล้ว ข้อมูลที่สะสมสามารถแปลงเป็นเอ็กซาไบต์ได้ ตัวอย่างเช่น ในภาคส่วนทั่วไปทั่วโลกในปี 2010 ข้อมูลใหม่ประมาณ 2 เอ็กซาไบต์ถูกสะสมไว้ (Manyika et al., 2011)
Іsnuyut galuzі, de danі zbirayutsya และสะสมอย่างเข้มข้นมากขึ้น
ตัวอย่างเช่น ในทรงกลมเคมี เช่น โรงไฟฟ้า บางครั้งมีการสร้างข้อมูลไหลอย่างต่อเนื่องสำหรับปัจจัยหลายหมื่นตัวในการผันผวนของผิวหนัง
นอกจากนี้ ในช่วงที่เหลือของปี เทคโนโลยีที่เรียกว่า "สมาร์ทกริด" กำลังได้รับการส่งเสริม ซึ่งช่วยให้ระบบสาธารณูปโภคสามารถประหยัดพลังงานได้ในเวลาเดียวกัน
สำหรับโปรแกรมดังกล่าวซึ่งข้อมูลเกิดจากการถูกบันทึกโดยโชคชะตา ข้อมูลที่สะสมจะถูกจัดประเภทเป็นข้อมูลขนาดใหญ่มาก
มีการเพิ่ม Big Data จำนวนมากขึ้นเรื่อยๆ ในภาคกลางของภาคการค้าและของรัฐ ซึ่งข้อมูลจากคอลเลกชั่นสามารถกลายเป็นหลายร้อยเทราไบต์หรือเพทาไบต์
เทคโนโลยีสมัยใหม่ทำให้สามารถ "ทบทวน" ผู้คนและพฤติกรรมของพวกเขาได้หลากหลายวิธี ตัวอย่างเช่น หากเราคุ้นเคยกับอินเทอร์เน็ต เราถูกล่อลวงให้ซื้อในร้านค้าทางอินเทอร์เน็ตหรือเครือข่ายร้านค้าขนาดใหญ่ เช่น Walmart (ลิงก์จาก Wikipedia การรวบรวมข้อมูลของ Walmart คาดว่าจะต่ำกว่า 2 เพตาไบต์) หรือ เราย้ายด้วยการรวม โทรศัพท์มือถือ- เรากำลังทำลายร่องรอยของกิจกรรมของเราเพื่อนำไปสู่การรวบรวมข้อมูลใหม่
วิธีการสื่อสารที่หลากหลาย ตั้งแต่การโทรศัพท์ธรรมดาไปจนถึงการได้มาซึ่งข้อมูลผ่านเว็บไซต์ มาตรการทางสังคมเช่น Facebook (ตามข้อมูลของ Wikipedia คาดว่าการแลกเปลี่ยนข้อมูลจะกลายเป็น 30 พันล้านหน่วย) หรือการแลกเปลี่ยนวิดีโอบนเว็บไซต์ดังกล่าว เช่น YouTube (YouTube ยืนยันว่า 24 ปีของเนื้อหาวิดีโอสกิน วิกิพีเดียมหัศจรรย์) จำนวนข้อมูลใหม่
ในทำนองเดียวกัน เทคโนโลยีทางการแพทย์สมัยใหม่ให้คำมั่นสัญญาที่ดีเกี่ยวกับข้อมูลที่จำเป็นสำหรับความช่วยเหลือทางการแพทย์ (รูปภาพ วิดีโอ การตรวจสอบแบบเรียลไทม์)
Otzhe การจำแนกประเภทของข้อมูล obsyagiv สามารถเป็นดังนี้:
ชุดข้อมูลขนาดใหญ่: ตั้งแต่ 1,000 เมกะไบต์ (1 กิกะไบต์) ถึงหลายร้อยกิกะไบต์
ชุดข้อมูลขนาดใหญ่: ตั้งแต่ 1,000 กิกะไบต์ (1 เทราไบต์) ถึง 1 เทราไบต์
บิ๊กดาต้า: จากไม่กี่เทราไบต์ไปจนถึงหลายร้อยเทราไบต์
ข้อมูลขนาดใหญ่มาก: 1,000 ถึง 10,000 เทราไบต์ = 1 ถึง 10 เพตาไบต์
หัวหน้าฝ่ายบิ๊กดาต้า
สร้างงานสามประเภทที่เกี่ยวข้องกับ Big Data:
1. การออมและการจัดการ
การรวบรวมข้อมูลจากหลายร้อยเทราไบต์และเพทาไบต์ไม่อนุญาตให้คุณบันทึกและบันทึกข้อมูลเหล่านี้เพื่อขอความช่วยเหลือจากฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม
2. ข้อมูลที่ไม่มีโครงสร้าง
ข้อมูลบิ๊กดาต้าส่วนใหญ่ไม่มีโครงสร้าง ทูบโต ฉันจะจัดระเบียบข้อความ วิดีโอ รูปภาพได้อย่างไร
3. การวิเคราะห์ข้อมูลขนาดใหญ่
จะวิเคราะห์ข้อมูลที่ไม่มีโครงสร้างได้อย่างไร? บนพื้นฐานของ Big Data ในการรวมเสียงง่าย ๆ พวกเขาจะช่วยทำลายแบบจำลองการทำนายได้อย่างไร?
การบันทึกและปกป้อง Big Data
Big Data ถูกบันทึกและจัดระเบียบในระบบไฟล์ต่างๆ
Zagalom ข้อมูลถูกเก็บไว้ในฮาร์ดดิสก์สองสาม (หนึ่งและพัน) คอมพิวเตอร์มาตรฐาน
นี่คือชื่อของ "แผนที่" (แผนที่) เนื่องจาก de (ในคอมพิวเตอร์และ / หรือดิสก์) จะใช้ส่วนใดส่วนหนึ่งของข้อมูล
เพื่อให้แน่ใจว่ามีความมีชีวิตและผิวเผิน ข้อมูลส่วนผิวหนังควรได้รับการบันทึกไว้สองสามครั้ง เช่น - trichi
ตัวอย่างเช่น เป็นที่ยอมรับได้ที่คุณเลือกธุรกรรมแต่ละรายการจากเครือข่ายร้านค้าปลีกขนาดใหญ่ ข้อมูลโดยละเอียดเกี่ยวกับธุรกรรมสกินจะถูกบันทึกไว้ในเซิร์ฟเวอร์และฮาร์ดดิสก์ที่แตกต่างกันและ "แผนที่" (แผนที่) іndexuє, zvіdоmostiเดียวกันเกี่ยวกับvіdpovіdnuที่ชื่นชอบ
สำหรับความช่วยเหลือในการครอบครองมาตรฐานที่vodkritih ผลงานโปรแกรมสำหรับระบบไฟล์ keruvannya tsієyu rozpodіlenoy (ตัวอย่างเช่น Hadoop) มันค่อนข้างง่ายที่จะนำการรวบรวมข้อมูลที่ดีที่สุดมาใช้ในระดับเพตะไบต์
ข้อมูลที่ไม่มีโครงสร้าง
ข้อมูลที่รวบรวมส่วนใหญ่ในการแจกจ่ายระบบไฟล์ประกอบด้วยข้อมูลที่ไม่มีโครงสร้าง เช่น ข้อความ รูปภาพ ภาพถ่าย หรือวิดีโอ
Tse maє svoї perevagi ที่nedolіki
ข้อได้เปรียบอยู่ที่ความสามารถในการบันทึกบรรณาการอันยิ่งใหญ่ช่วยให้คุณสามารถบันทึก "ข้อมูลทั้งหมด" ได้โดยไม่ต้องกังวลเกี่ยวกับข้อมูลเหล่านั้น เนื่องจากส่วนหนึ่งของข้อมูลมีความเกี่ยวข้องกับการวิเคราะห์เพิ่มเติม และการตัดสินใจนั้นก็จะถูกนำไปพิจารณา
ผู้ที่มีประสบการณ์ดังกล่าวในการเรียนรู้ไม่เพียงพอ ข้อมูลสีน้ำตาลไม่จำเป็นต้องมีการประมวลผลบรรณาการอันยอดเยี่ยมเหล่านี้
หากคุณต้องการให้การดำเนินการเหล่านี้เป็นเรื่องง่าย (เช่น แค่ไอ้สารเลวเร็วเกินไป) คุณสามารถใช้อัลกอริธึมการพับเพิ่มเติม เพื่อให้สามารถพัฒนาเป็นพิเศษสำหรับการทำงานที่มีประสิทธิภาพบนระบบไฟล์แบบกระจาย
ผู้จัดการระดับสูงคนหนึ่งในคราวเดียวชื่อ StatSoft ว่าเขา "ชนะอาชีพด้านไอทีและประหยัดเงิน แต่ไม่คิดเกี่ยวกับมัน ทำอย่างไรจึงจะได้เงินมากขึ้นเพื่อลดภาระงานหลัก
ต่อมา ในชั่วโมงนั้น เมื่อข้อมูลสามารถเข้าถึงได้ในความก้าวหน้าทางเรขาคณิต ความสามารถในการนำข้อมูลและกิจกรรมออกไปบนพื้นฐานของข้อมูล การแลกเปลี่ยนจะสามารถเข้าถึงได้ระหว่าง
สิ่งสำคัญคือต้องขยายวิธีการและขั้นตอนในการแจ้ง อัปเดตโมเดล ตลอดจนทำให้กระบวนการตัดสินใจยอมรับเป็นอัตโนมัติโดยลำดับของระบบการรวบรวมข้อมูล เพื่อให้แน่ใจว่าระบบดังกล่าวถูกต้องและใช้งานได้จริงสำหรับธุรกิจ
การวิเคราะห์ข้อมูลขนาดใหญ่
นี่เป็นปัญหาใหญ่จริงๆ ที่เกี่ยวข้องกับการวิเคราะห์ข้อมูลขนาดใหญ่ที่ไม่มีโครงสร้าง นั่นคือ วิธีวิเคราะห์จากต้นทุน มือโปร ให้อาหารเขียนน้อยลง น้อยลงเกี่ยวกับการบันทึกข้อมูลและเทคโนโลยีการจัดการข้อมูลขนาดใหญ่
Є พลังงานต่ำ yakі เลื่อนดู
แผนที่ลด
เมื่อวิเคราะห์ข้อมูลหลายร้อยเทราไบต์หรือเพทาไบต์ เป็นไปไม่ได้ที่จะนำข้อมูลไปวิเคราะห์ที่อื่น (เช่น เซิร์ฟเวอร์การวิเคราะห์องค์กรของ STATISTICA).
ขั้นตอนการถ่ายโอนข้อมูลตามช่องทางไปยังเซิร์ฟเวอร์หรือเซิร์ฟเวอร์ okremiya (สำหรับการประมวลผลแบบขนาน) ใช้เวลานานเกินไปและต้องการการรับส่งข้อมูลมากเกินไป
Natomist การคำนวณเชิงวิเคราะห์อาจใกล้เคียงกับเดือนที่มีการรวบรวมข้อมูล
Algorithm Map-Reduce єโมเดลสำหรับแคลคูลัสrozdіlenih หลักการของโยคะทำงานในเชิงรุก: จำเป็นต้องกระจายข้อมูลอินพุตบนโหนดการทำงาน (โหนดส่วนบุคคล) ระบบไฟล์สำหรับการประมวลผลด้านหน้า (map-croc) และจากนั้นการพับ (การรวม) ที่มีอยู่แล้วในด้านหน้าของข้อมูลการประมวลผล (reduce-croc)
ด้วยวิธีนี้ สมมติว่าสำหรับการคำนวณผลรวมของผลรวม อัลกอริธึมจะคำนวณผลรวมกลางในโหนดสกินของระบบไฟล์แบบกระจายพร้อมกัน แล้วจึงคำนวณผลรวมของค่ากลาง
บนอินเทอร์เน็ต มีข้อมูลจำนวนมากเกี่ยวกับสิ่งเหล่านั้น ด้วยวิธีนี้ คุณสามารถเอาชนะต้นทุนของแบบจำลองการลดแผนที่เพิ่มเติม ซึ่งรวมถึงการวิเคราะห์เชิงคาดการณ์
แค่สถิติ Business Intelligence (BI)
สำหรับการพับตัวเลขอย่างง่าย BI ใช้ผลิตภัณฑ์ที่ไม่ระบุตัวตนพร้อมรหัสที่ชัดเจน ซึ่งช่วยให้คุณคำนวณผลรวม ค่าเฉลี่ย สัดส่วน ฯลฯ เพื่อช่วยในการลดแผนที่
ในลักษณะนี้ มันง่ายยิ่งขึ้นไปอีกที่จะใช้เรื่องไร้สาระที่ถูกต้องและสถิติง่ายๆ อื่นๆ สำหรับการรวบรวมคำตอบ
การสร้างแบบจำลองการทำนายการสูญเสียสถิติ
เมื่อมองแวบแรก คุณจะเห็นว่าแบบจำลองการพยากรณ์ในการกระจายของระบบไฟล์ถูกพับ แต่โปรเตสไม่เป็นเช่นนั้น มาดูขั้นตอนก่อนหน้าของการวิเคราะห์ข้อมูลกัน
การเตรียมข้อมูล เมื่อเร็ว ๆ นี้ StatSoft ได้ดำเนินการชุดของโครงการที่ยอดเยี่ยมและประสบความสำเร็จสำหรับการมีส่วนร่วมของชุดข้อมูลที่ยอดเยี่ยมซึ่งอธิบายการสาธิตที่น่ายกย่องของกระบวนการดำเนินการโรงไฟฟ้า เมตาดาต้าของการวิเคราะห์ชี้ให้เห็นถึงการเพิ่มประสิทธิภาพในการทำงานของโรงไฟฟ้าและจำนวนวิกิที่ลดลง (Electric Power Research Institute, 2009)
เป็นสิ่งสำคัญที่ไม่ว่าการรวบรวมข้อมูลจะยิ่งใหญ่กว่าเพียงใด ข้อมูลที่ซ่อนอยู่ในนั้นก็อาจมีข้อมูลน้อยกว่ามาก
ตัวอย่างเช่น ในช่วงเวลานั้น ตามจริงแล้ว somiti หรือ schokhvilins กำลังสะสม พารามิเตอร์จำนวนมาก (อุณหภูมิของก๊าซและเตาหลอม การไหล ตำแหน่งของบานประตูหน้าต่าง ฯลฯ) จะคงที่ในช่วงเวลาที่ยิ่งใหญ่ของชั่วโมง มิฉะนั้น ข้อมูลเหล่านี้จะถูกบันทึกไว้ในสกินวินาที และเป็นสิ่งสำคัญที่จะทำซ้ำข้อมูลเดียวกัน
ด้วยวิธีนี้ จำเป็นต้องดำเนินการรวบรวมข้อมูลที่ "สมเหตุสมผล" โดยคำนึงถึงการสร้างแบบจำลองและการปรับข้อมูลให้เหมาะสม เพื่อลบข้อมูลที่จำเป็นเกี่ยวกับการเปลี่ยนแปลงแบบไดนามิก ซึ่งจะเพิ่มประสิทธิภาพของโรงไฟฟ้าหุ่นยนต์และ จำนวนวิกิ
การจำแนกข้อความและการประมวลผลข้อมูลก่อนหน้า ให้ฉันแสดงให้เห็นอีกครั้งว่าชุดข้อมูลที่ยอดเยี่ยมสามารถแทนที่ด้วยข้อมูลพื้นฐานที่น้อยกว่ามากได้อย่างไร
ตัวอย่างเช่น StatSoft มีส่วนร่วมในโครงการที่เกี่ยวข้องกับการทำเหมืองข้อความ (การทำเหมืองข้อความ) และทวีต ซึ่งแสดงจำนวนผู้โดยสารที่พึงพอใจกับสายการบินและบริการของพวกเขา
ไม่ว่าจะเกิดอะไรขึ้นในวันนั้น ทวีต อารมณ์ และการแสดงออกในเชิงบวกจำนวนมากก็ถูกพูดเกินจริงโดยคนธรรมดา ข้อมูลเพิ่มเติม - skarga และข้อมูลสั้น ๆ เกี่ยวกับข้อเสนอหนึ่งเกี่ยวกับ "รายงานที่สกปรก" นอกจากนี้ จำนวนและ “ความแข็งแกร่ง” ของอารมณ์เหล่านี้มักจะคงที่ในบางครั้งและในบางมื้อ (เช่น สัมภาระ ถังขยะ อาหาร เที่ยวบิน)
ในลักษณะนี้ การย่อทวีตจริงให้เป็นอารมณ์ด่วน (การประเมิน) วิธีการทำเหมืองข้อความ vikoristovuyuchi (เช่น นำมาใช้ใน เครื่องมือขุดข้อความสถิติ) เพื่อสร้างข้อมูลให้น้อยลง ซึ่งสามารถตั้งค่าได้ง่ายด้วยการจัดโครงสร้างข้อมูลที่จำเป็น (การขายตั๋วจริง หรือข้อมูลเกี่ยวกับผู้โดยสาร ซึ่งมักจะบิน) การวิเคราะห์ช่วยให้สามารถแบ่งลูกค้าออกเป็นกลุ่มๆ
เราใช้เครื่องมือที่ไม่ระบุชื่อเพื่อดำเนินการรวบรวมข้อมูลดังกล่าว (เช่น การตั้งค่าด่วน) ในระบบไฟล์แยกต่างหาก ซึ่งช่วยให้คุณสามารถสร้างข้อมูลสำหรับกระบวนการวิเคราะห์ได้อย่างง่ายดาย
รุ่น Pobudova
บ่อยครั้ง งานคือต้องแน่ใจว่าโมเดลข้อมูลที่แน่นอนที่ถูกบันทึกไว้ในการแจกแจงระบบไฟล์ได้รับแจ้ง
สร้างการดำเนินการลดแผนที่สำหรับการทำเหมืองข้อมูล/อัลกอริธึมการวิเคราะห์เชิงคาดการณ์ต่างๆ ซึ่งเหมาะสำหรับการประมวลผลข้อมูลแบบขนานขนาดใหญ่ในระบบไฟล์ต่างๆ สถิติ statsoft)
อย่างไรก็ตาม จากบรรดาผู้ที่มีข้อมูลจำนวนมากอยู่แล้ว ทำไมคุณจึงมั่นใจว่ารุ่นกระเป๋ามีความแม่นยำมากกว่า
จริง ๆ ดีกว่า ดีกว่าสำหรับกลุ่มข้อมูลขนาดเล็กในระบบไฟล์ต่างๆ
ตามที่ทวีตล่าสุดของ Forrester กล่าวว่า "Two plus two is a good 3.9—it sound good" (Hopkins & Evelson, 2011)
สถิติว่าความแม่นยําทางคณิตศาสตร์สัมพันธ์กับการที่ตัวแบบการถดถอยเชิงเส้น ได้แก่ ตัวทำนาย 10 ตัวที่ยึดตามความถูกต้อง imovіrnіsnoї vybіrkiผู้พิทักษ์ 3 100,000 คนจะแม่นยำราวกับนางแบบที่ได้รับแรงบันดาลใจจากผู้พิทักษ์ 100 ล้านคน
(อย่างแท้จริง - ข้อมูลที่ดี)? เราย้อนกลับไปที่คำศัพท์ของ Oxford:
ดานี- ค่า เครื่องหมาย หรือสัญลักษณ์ วิธีการทำงานของคอมพิวเตอร์ และวิธีบันทึกและถ่ายทอดจากแบบฟอร์ม สัญญาณไฟฟ้า, บันทึกบนแม่เหล็ก, ออปติคัลหรือการสึกหรอทางกล
ภาคเรียน ข้อมูลใหญ่ vikoristovuetsya สำหรับคำอธิบายของผู้ยิ่งใหญ่และเติบโตอย่างทวีคูณตลอดชั่วโมงเพื่อรวบรวมข้อมูล สำหรับการผลิตข้อมูลจำนวนดังกล่าว เราไม่สามารถทำได้โดยปราศจากการเรียนรู้ของเครื่อง
ประโยชน์ของข้อมูลขนาดใหญ่:
- การคัดเลือกข้อมูลจากแหล่งต่างๆ
- กระบวนการทางธุรกิจของ Polypshennya ผ่านการวิเคราะห์ตามเวลาจริง
- น้อมถวายพระพรอย่างยิ่งใหญ่
- ข้อมูลเชิงลึก. บิ๊กดาต้าเข้าถึงได้มากขึ้น ได้รับข้อมูลสำหรับโครงสร้างเพิ่มเติมและข้อมูลnapіvstrukturirovaniya
- ข้อมูลที่ดีช่วยเปลี่ยนความเสี่ยงและตัดสินใจอย่างสมเหตุสมผล
สมัครบิ๊กดาต้า
ตลาดหลักทรัพย์นิวยอร์กสร้างวันนี้ 1 เทราไบต์ข้อมูลเกี่ยวกับการประมูลในช่วงที่ผ่านมา
สื่อสังคม: สถิติแสดงสิ่งที่กำลังถูกเอาเปรียบในฐานข้อมูล Facebook ในปัจจุบัน 500 เทราไบต์ข้อมูลใหม่ส่วนใหญ่สร้างขึ้นจากการจับภาพและวิดีโอบนเซิร์ฟเวอร์และโซเชียลมีเดีย การแลกเปลี่ยนการแจ้งเตือน ความคิดเห็นใต้โพสต์ และอื่นๆ
เครื่องยนต์ไอพ่นสร้าง 10 เทราไบต์ให้ผิวหนัง 30 hvilin pіd hour polotu เศษของวันzdіysnyuyuyutsyaพันข้อ obsyag เหล่านี้ถึงเพตาไบต์
การจำแนกประเภทของบิ๊กดาต้า
รูปแบบของบรรณาการที่ยิ่งใหญ่:
- โครงสร้าง
- ไม่มีโครงสร้าง
- Napіvstructured
แบบมีโครงสร้าง
ข้อมูลที่สามารถบันทึกได้ แต่เข้าถึงได้และทำให้เป็นแบบทั่วไปในแบบฟอร์มที่มีรูปแบบคงที่ เรียกว่า structuring เป็นเวลาสามชั่วโมงที่วิทยาการคอมพิวเตอร์ประสบความสำเร็จอย่างมากในเทคโนโลยีขั้นสูงสำหรับวิทยาการหุ่นยนต์ด้วยข้อมูลประเภทนี้ (รูปแบบที่ผิด zazdalegіd) และได้เรียนรู้ที่จะขจัดความโลภ ในปีเดียวกันนั้น มีปัญหาที่เกิดขึ้นจากการเติบโตของสัญญาจนถึงการขยายตัว ราวกับว่าปัญหาเหล่านั้นจบลงในช่วงเซ็ตทาไบต์สองสามเซทตาไบต์
1 เซตตะไบต์ เท่ากับ พันล้านเทราไบต์
สงสัยเกี่ยวกับจำนวนตัวเลข ไม่สำคัญที่จะสับสนเกี่ยวกับความจริงของคำศัพท์บิ๊กดาต้าและปัญหาที่เกี่ยวข้องกับการประมวลผลและการบันทึกข้อมูลดังกล่าว
ข้อมูลที่จัดเก็บไว้ในฐานข้อมูลเชิงสัมพันธ์ - มีโครงสร้างและอาจดูเหมือนตารางอ้างอิงในบริษัท
แบบไม่มีโครงสร้าง
ข้อมูลของโครงสร้างที่ไม่มีโครงสร้างจัดประเภทเป็นไม่มีโครงสร้าง นอกเหนือจากการขยายที่ยอดเยี่ยมแล้ว แบบฟอร์มดังกล่าวยังมีการพับหลายครั้งสำหรับการประมวลผลและการทำรายละเอียดเพิ่มเติมของข้อมูลสีน้ำตาล ตัวอย่างทั่วไปของข้อมูลที่ไม่มีโครงสร้างคือ dzherelo ที่ต่างกัน ซึ่งสามารถใช้เป็นไฟล์ข้อความ รูปภาพ และวิดีโอร่วมกันได้ องค์กรในปัจจุบันอาจเข้าถึงภาระหน้าที่อันยิ่งใหญ่ของข้อมูลซีเรียหรือข้อมูลที่ไม่มีโครงสร้าง แต่ไม่รู้ว่าจะขจัดความแค้นจากพวกเขาได้อย่างไร

แบบฟอร์ม Napіvstrukturovana
หมวดหมู่ Tsya เพื่อแก้แค้นความผิดที่อธิบายไว้ข้างต้นสำหรับรูปแบบnapіvstrukturirovanіdanі mаyut deak แต่ในความเป็นจริงพวกเขาไม่ได้กำหนดตารางเพิ่มเติมในฐานข้อมูลเชิงสัมพันธ์ หมวดหมู่แอปพลิเคชัน - ข้อมูลส่วนบุคคลที่แสดงในไฟล์ XML
ลักษณะของบิ๊กดาต้า
การเติบโตของข้อมูลขนาดใหญ่เป็นรายชั่วโมง:

สีฟ้าแสดงถึงข้อมูลที่มีโครงสร้าง (ข้อมูลองค์กร) ที่รวบรวมจากฐานข้อมูลเชิงสัมพันธ์ สีอื่นๆ เป็นข้อมูลที่ไม่มีโครงสร้างจากแหล่งต่างๆ (โทรศัพท์ IP อุปกรณ์และเซ็นเซอร์ โซเชียลมีเดียและส่วนเสริมของเว็บ)
Vіdpovіdnoถึง Gartner, ใหญ่dаіnіїrazrіznyayutsya obyagі, รุ่นshvidkіstyu, raznomanіstyuในmnіvіstyu มาดูพารามิเตอร์ของรายงานกัน
- เกี่ยวกับ `em. โดยตัวมันเอง คำว่า Big Data เกี่ยวข้องกับการขยายตัวครั้งใหญ่ของโลก ข้อมูลโรสแมรี่เป็นตัวบ่งชี้ที่สำคัญที่สุดว่ามูลค่าที่กู้คืนได้นั้นจะมีค่าเท่าใด วันนี้ ผู้คน 6 ล้านคนชนะสื่อดิจิทัล ซึ่งตามการประมาณการครั้งก่อน สร้างข้อมูล 2.5 quintillion ไบต์ Tom obsyag - สิ่งแรกที่ต้องดูลักษณะ
- Raznomanіtnіst- ด้านที่น่ารังเกียจ เราพึ่งพาธรรมชาติของข้อมูลที่แตกต่างกัน ซึ่งสามารถเป็นได้ทั้งแบบมีโครงสร้างและไม่มีโครงสร้าง ก่อนหน้านี้ สเปรดชีตฐานข้อมูลเหล่านี้เป็นแหล่งข้อมูลเดียวที่พบในอาหารเสริมส่วนใหญ่ ข้อมูลฟอร์มวันนี้ แผ่นอิเล็กทรอนิกส์, รูปภาพ, วีดีโอ, ไฟล์ PDF, เสียงยังสามารถดูได้ในส่วนเสริมการวิเคราะห์ ข้อมูลที่ไม่มีโครงสร้างที่หลากหลายดังกล่าวนำไปสู่ปัญหาด้านการออม การสร้างภาพ และการวิเคราะห์ โดย 27% ของบริษัทไม่เชื่อว่าตนทำงานร่วมกับข้อมูลภายนอก
- ความเร็วในการสร้าง. บรรดาผู้ที่ได้สะสมข้อมูลอย่างรวดเร็วสะสมและพอใจกับความแข็งแกร่งของพวกเขาแสดงศักยภาพ ความรวดเร็วกำหนดความรวดเร็วของการไหลเข้าของข้อมูลจาก dzherel - กระบวนการทางธุรกิจ, บันทึกของส่วนเสริม, ไซต์ของเครือข่ายสังคมและสื่อ, เซ็นเซอร์, เรือนเพาะชำมือถือ. การไหลของความยิ่งใหญ่เหล่านี้อย่างต่อเนื่องในชั่วโมง
- Minlivistอธิบายความเล็กของข้อมูลของวันและชั่วโมง ซึ่งทำให้งานของการบริหารนั้นซับซ้อน ตัวอย่างเช่น ข้อมูลส่วนใหญ่ไม่มีโครงสร้างโดยธรรมชาติ
การวิเคราะห์ Big Data: เหตุใดความไม่พอใจของข้อมูลที่ยอดเยี่ยม
ทางผ่านของสินค้าและบริการ: การเข้าถึงข้อมูลจากระบบเสิร์ชเอ็นจิ้นและเว็บไซต์ เช่น Facebook และ Twitter ช่วยให้ธุรกิจปรับแต่งกลยุทธ์ทางการตลาดของตนได้
การสนับสนุนบริการสำหรับผู้ซื้อ: ระบบดั้งเดิม zvorotny zv'azkuด้วยการซื้อ พวกเขาจะถูกแทนที่ด้วยใหม่ ใน Big Data ดังกล่าว การประมวลผลภาพยนตร์ธรรมชาติจะหยุดเพื่ออ่านและประเมินการซื้อ
โรซราหุนก ริซิคุเชื่อมต่อกับการเปิดตัวผลิตภัณฑ์ใหม่ chi บริการ
ประสิทธิภาพการดำเนินงาน: โครงสร้างข้อมูลที่ยอดเยี่ยม เพื่อให้คุณสามารถรับข้อมูลที่จำเป็นได้ง่ายขึ้นและเห็นผลที่แน่นอนอย่างรวดเร็ว การผสมผสานระหว่างเทคโนโลยีและคอลเลคชันบิ๊กดาต้าช่วยให้องค์กรเพิ่มประสิทธิภาพการทำงานด้วยข้อมูล ซึ่งไม่ค่อยประสบความสำเร็จ
ข้อมูลที่ดีเป็นคำศัพท์กว้างๆ สำหรับกลยุทธ์และเทคโนโลยีที่ไม่ใช่แบบดั้งเดิมซึ่งจำเป็นสำหรับการรวบรวม จัดระเบียบ และประมวลผลข้อมูลจากชุดข้อมูลที่ยอดเยี่ยม อยากได้ปัญหาหุ่นยนต์กับดานิมต้องย้ายอะไร แคลคูลัสมิฉะนั้น ความเป็นไปได้ในการเลือกคอมพิวเตอร์เครื่องหนึ่ง ไม่ใช่เครื่องใหม่ ในส่วนอื่นๆ ของโลก ขนาดของมูลค่าประเภทนั้นได้ขยายออกไปอย่างมาก
ในบทความเหล่านี้ คุณจะรู้ถึงแนวคิดหลักที่คุณสามารถปิดได้ ดังนั้นนี่คือการกระทำของกระบวนการและเทคโนโลยี เช่น vikoristovuyutsya ที่แกลเลอรีนี้ในเวลาที่กำหนด
อะไรเป็นเครื่องบรรณาการที่ยิ่งใหญ่เช่นนี้?
สิ่งสำคัญคือต้องกำหนดวัตถุประสงค์ของ "การยกย่องที่ยิ่งใหญ่" ให้ถูกต้อง เพื่อให้โครงการ ผู้ขาย ผู้เชี่ยวชาญ ผู้ปฏิบัติงาน และผู้อำนวยความสะดวกทางธุรกิจได้รับชัยชนะในแนวทางที่แตกต่างออกไป Mayuchi tse บน uvazi บรรณาการที่ดีสามารถนับเป็น:
- ชุดข้อมูลที่ยอดเยี่ยม
- หมวดหมู่ของกลยุทธ์การแจงนับและเทคโนโลยี ซึ่งได้รับเลือกสำหรับการผลิตชุดข้อมูลที่ยอดเยี่ยม
ในบริบทนี้ "การรวบรวมข้อมูลจำนวนมาก" หมายถึงการรวบรวมข้อมูล ซึ่งมากเกินไป ที่จะเติบโตหรือดูแลเครื่องมือดั้งเดิมเพิ่มเติมหรือคอมพิวเตอร์เครื่องเดียว Tse หมายความว่าขนาดมหึมาของคอลเล็กชันข้อมูลจำนวนมากนั้นเปลี่ยนแปลงอยู่ตลอดเวลา และสามารถเปลี่ยนแปลงได้อย่างมากจากที่หนึ่งไปยังอีกที่หนึ่ง
ระบบบรรณาการที่ดี
ผลงานหลักในการทำงานกับเครื่องบรรณาการที่ยิ่งใหญ่นั้นเหมือนกับก่อนเครื่องบรรณาการชุดอื่นๆ ปกป้องมาตราส่วนมวล ความเร็วในการประมวลผล และลักษณะของข้อมูล ซึ่งเกี่ยวข้องกับขั้นตอนผิวของกระบวนการ นำเสนอปัญหาใหม่ที่ร้ายแรงของการประมวลผลต้นทุน วิธีการแห่งความยิ่งใหญ่ของระบบเครื่องบรรณาการที่ยิ่งใหญ่คือการทำความเข้าใจว่าการเชื่อมต่อกับพันธกรณีอันยิ่งใหญ่ของบรรณาการอันมั่งคั่งซึ่งคงเป็นไปไม่ได้ด้วยวิธีการพิเศษที่ได้รับชัยชนะ
ในปี 2544 Doug Laney และ Gartner ได้แนะนำ "Three V Great Data" เพื่ออธิบายลักษณะเฉพาะบางประการที่ท้าทายการประมวลผลข้อมูลที่ยอดเยี่ยมซึ่งสัมพันธ์กับกระบวนการประมวลผลข้อมูลประเภทอื่นๆ:
- ปริมาณ (ข้อมูลที่ผูกมัด)
- ความเร็ว (Shvidk_st สะสมและรวบรวมข้อมูล)
- วาไรตี้ (ความหลากหลายของประเภทข้อมูล)
ออบยาจ ดานิห
ขนาดของข้อมูล Vinyatkovy ซึ่งกำลังประมวลผลช่วยในการออกแบบระบบเครื่องบรรณาการที่ยิ่งใหญ่ ชุดข้อมูลเหล่านี้สามารถจัดลำดับความสำคัญที่ใหญ่กว่า ต่ำกว่าชุดแบบเดิม ซึ่งจะต้องให้ความสนใจมากขึ้นที่ขั้นตอนการประมวลผลและการบันทึกสกิน
เศษสามารถเกินดุลความจุของคอมพิวเตอร์เครื่องเดียว ซึ่งมักถูกตำหนิว่าเป็นปัญหาของการแบ่งปัน แจกจ่าย และประสานงานทรัพยากรจากกลุ่มคอมพิวเตอร์ การจัดการคลัสเตอร์และอัลกอริธึม การสร้างงานเป็นส่วนเล็กๆ มีความสำคัญมากขึ้นในสายตาของเรา
Shvidkіstสะสมและ obrobki
อีกลักษณะหนึ่งที่คล้ายกับข้อมูลที่ยอดเยี่ยมจากระบบข้อมูลอื่นคือราคาซึ่งข้อมูลถูกย้ายโดยระบบ ข้อมูลมักจะพบที่ระบบจาก dzherel สองสามตัว และอาจประมวลผลได้เหมือนชั่วโมงจริง สะอื้นเพื่ออัปเดตสตรีมไลน์ของระบบ
Tsey เน้นที่ mittevu zvorotnomu zv'azku zmusiv รวยfahіvtsіv-praktіvvіdmovіtіsіvіd podhoda ที่เน้นแพ็คเก็ตในvіddati vіddati vіddati vіddativіddatіvіddatiprоvaіvіtіkіtіkі ข้อมูลจะถูกเพิ่ม ประมวลผล และวิเคราะห์อย่างค่อยเป็นค่อยไปเพื่อให้ทันกับการไหลเข้าของข้อมูลใหม่ และนำข้อมูลที่มีค่ามาใช้ตั้งแต่แรก หากมีความเกี่ยวข้องมากที่สุด จำเป็นต้องใช้ระบบที่มีส่วนประกอบที่เข้าถึงได้สูงเพื่อป้องกันความล้มเหลวของไปป์ไลน์ข้อมูล
ประเภทของข้อมูลที่รวบรวมได้หลากหลายประเภท
เกรทเดนมีปัญหาเฉพาะที่ไร้ใบหน้า ซึ่งเชื่อมโยงกับพันธุ์ดีเซเรลที่เพาะปลูกมากมายและมีคุณภาพดี
ข้อมูลอาจมาจากระบบภายใน เช่น บันทึกและเซิร์ฟเวอร์เสริม จากช่องทางโซเชียลมีเดียและอินเทอร์เฟซ API ภายนอกอื่นๆ จากเซ็นเซอร์ สิ่งก่อสร้างทางกายภาพและ іnshih dzherel วิธีการของระบบข้อมูลที่ยอดเยี่ยมคือการประมวลผลข้อมูลที่อาจเป็นสีน้ำตาลอย่างอิสระในลักษณะของการรวมข้อมูลในระบบเดียว
สามารถปรับปรุงรูปแบบและประเภทของจมูกได้อย่างมาก ไฟล์มีเดีย (รูปภาพ วิดีโอ และเสียง) ถูกรวมเข้ากับไฟล์ข้อความ บันทึกที่มีโครงสร้าง ฯลฯ อนุญาตให้ประมวลผลระบบประมวลผลข้อมูลแบบดั้งเดิมมากขึ้น ซึ่งข้อมูลจะถูกใช้ที่สายพานลำเลียงที่ทำเครื่องหมาย จัดรูปแบบ และจัดระเบียบแล้ว แต่ระบบข้อมูลที่ยอดเยี่ยม บันทึกพวกเขา ค่ายพักร้อน. เป็นการดีที่จะทำใหม่หรือเปลี่ยนข้อมูลที่ยังไม่ถูกทำลายเพื่อจดจำในหน่วยความจำในเวลาทำงาน
ลักษณะอื่นๆ
หลายปีที่ผ่านมา ฟาฮิฟซีและองค์กรต่างๆ ได้เผยแพร่การขยายตัวของ "สาม Vs" แม้ว่านวัตกรรมเหล่านี้จะฟังเพื่ออธิบายปัญหา ไม่ใช่ลักษณะของแดนิชผู้ยิ่งใหญ่
- ความถูกต้อง (ความถูกต้องของข้อมูล): ความเก่งกาจของข้อมูลและความสามารถในการพับของข้อมูลอาจนำไปสู่ปัญหาในการประเมินคุณภาพของข้อมูล (เช่น คุณภาพของการวิเคราะห์ที่นำมา)
- ความแปรปรวน (การเปลี่ยนแปลงของข้อมูล): การเปลี่ยนแปลงของข้อมูลทำให้เกิดการเปลี่ยนแปลงคุณภาพในวงกว้าง สำหรับการระบุ การประมวลผล หรือการกรองข้อมูลที่มีคุณภาพต่ำ คุณอาจต้องการทรัพยากรเพิ่มเติม ซึ่งสามารถเพิ่มคุณภาพของข้อมูลได้
- คุณค่า (คุณค่าของข้อมูล): งานสุดท้ายของบรรณาการที่ยิ่งใหญ่คือคุณค่า ระบบและกระบวนการบางอย่างมีการทำงานร่วมกันมากขึ้น ซึ่งทำให้การเปลี่ยนแปลงของข้อมูลและการแปรผันของค่าจริงมีความซับซ้อน
วงจรชีวิตของบรรณาการอันยิ่งใหญ่
แล้วบรรณาการที่ยิ่งใหญ่จะรวบรวมได้อย่างไร? Іsnuєkіlkarіznіhіdhodіvในopіlіzatsіїทั้งที่กลยุทธ์และซอฟต์แวร์єspilnі risi
- ป้อนข้อมูลเข้าระบบ
- บันทึกข้อมูลที่ shovishchi
- การคำนวณและวิเคราะห์ข้อมูล
- การแสดงผลลัพธ์
ก่อนอื่น เราจะรายงานเกี่ยวกับกระบวนการทำงานสองสามหมวดหมู่ มาพูดถึงการจัดกลุ่ม กลยุทธ์ที่สำคัญ และการชนะบากัตมาเพื่อการประมวลผลบรรณาการอันยอดเยี่ยม การปรับปรุงคลัสเตอร์การนับจำนวนเป็นพื้นฐานของเทคโนโลยีสำหรับขั้นตอนผิวแห่งชัยชนะของวงจรชีวิต
การนับคลัสเตอร์
เนื่องจากความยิ่งใหญ่ของข้อมูลที่ยอดเยี่ยม คอมพิวเตอร์จึงไม่เหมาะสำหรับการประมวลผลข้อมูล สำหรับกลุ่มใดมีความเหมาะสมมากกว่าสำหรับผู้ที่สามารถรับมือกับการออมและนับความต้องการเครื่องบรรณาการที่ยิ่งใหญ่
ซอฟต์แวร์สำหรับการจัดกลุ่มข้อมูลขนาดใหญ่จะค่อยๆ เพิ่มทรัพยากรของความสมบูรณ์ของเครื่องจักรขนาดเล็ก ช่วยรักษาข้อดีหลายประการ:
- การรวมทรัพยากร: ในการประมวลผลชุดข้อมูลขนาดใหญ่ คุณต้องใช้ทรัพยากรโปรเซสเซอร์และหน่วยความจำจำนวนมาก รวมทั้งพื้นที่ว่างจำนวนมากสำหรับการรวบรวมข้อมูล
- ความพร้อมใช้งานสูง: คลัสเตอร์สามารถรับรองระดับความพร้อมใช้งานและความพร้อมใช้งานที่แตกต่างกัน ดังนั้นความล้มเหลวของฮาร์ดแวร์หรือซอฟต์แวร์จะไม่รบกวนการเข้าถึงข้อมูลและการประมวลผลข้อมูล นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับการวิเคราะห์ตามเวลาจริง
- การปรับขนาด: การทำคลัสเตอร์รองรับการปรับขนาดแนวนอน (การเพิ่มเครื่องใหม่ไปยังคลัสเตอร์)
ในการทำงานในคลัสเตอร์ คุณต้องมีเครื่องมือในการจัดการความเป็นสมาชิกในคลัสเตอร์ ประสานงานการกระจายทรัพยากร และวางแผนการทำงานกับโหนดอื่นๆ การเป็นสมาชิกในกลุ่มและการกระจายทรัพยากรสามารถรับได้ผ่านโปรแกรมเพิ่มเติม เช่น Hadoop YARN (Yet Another Resource Negotiator) หรือ Apache Mesos
คลัสเตอร์การแจงนับที่เลือกมักจะทำหน้าที่เป็นพื้นฐาน แต่สำหรับการประมวลผลข้อมูลในลักษณะระหว่างโมดอล ความปลอดภัยของซอฟต์แวร์. เครื่องที่อยู่ในคลัสเตอร์การนับยังเกี่ยวข้องกับการจัดการระบบการออมแบบกระจาย
Otrimannya danikh
การยอมรับข้อมูล - กระบวนการเพิ่มข้อมูลที่ไม่แชร์ไปยังระบบ ความสามารถในการพับของการดำเนินการนี้อุดมไปด้วยเหตุผลที่ต้องอยู่ในรูปแบบของความหนาแน่นของข้อมูลทั่วไป และนอกจากนี้ ปริมาณข้อมูลที่จำเป็นสำหรับการประมวลผล
คุณสามารถเพิ่มข้อมูลที่ยอดเยี่ยมให้กับระบบด้วยความช่วยเหลือของเครื่องมือพิเศษ เทคโนโลยีดังกล่าว เช่น Apache Sqoop สามารถนำข้อมูลที่จำเป็นจากฐานข้อมูลเชิงสัมพันธ์และเพิ่มลงในระบบข้อมูลที่ยอดเยี่ยม คุณยังสามารถแฮ็ก Apache Flume และ Apache Chukwa - โปรเจ็กต์ที่รู้จักการรวมและนำเข้าบันทึกและเซิร์ฟเวอร์เสริม โบรกเกอร์ Recall เช่น Apache Kafka สามารถชนะได้จากการเป็นส่วนต่อประสานระหว่างตัวสร้างข้อมูลต่างๆ และระบบข้อมูลที่ยอดเยี่ยม กรอบงานอย่าง Gobblin สามารถรวมและเพิ่มประสิทธิภาพการทำงานของเครื่องมือทั้งหมดเช่นไปป์ไลน์
ภายใต้ชั่วโมงของการรับข้อมูล การวิเคราะห์จะดำเนินการ จัดเรียง และทำเครื่องหมาย กระบวนการนี้บางครั้งเรียกว่า ETL (แยก แปลง โหลด) ซึ่งหมายถึงการแปลง การแปลง และพัวพัน หากได้ยินคำนี้ มันจะขึ้นกับกระบวนการแบบเก่าของการบันทึกข้อมูล แต่บางครั้งก็ zastosovuetsya และขึ้นอยู่กับระบบของข้อมูลที่ยอดเยี่ยม ระหว่างการดำเนินการทั่วไป - การเปลี่ยนแปลงข้อมูลอินพุตสำหรับการจัดรูปแบบ การจัดหมวดหมู่และการทำเครื่องหมาย การกรองและการตรวจสอบข้อมูลอีกครั้งสำหรับการแสดงภาพ vimog
ตามหลักการแล้ว เราต้องการใช้การจัดรูปแบบน้อยที่สุด
การป้องกันข้อมูล
หลังจากได้รับเครื่องบรรณาการแล้ว ไปที่ส่วนประกอบที่จัดการส่วนรวม
เรียกร้องให้บันทึกข้อมูลที่ไม่ได้แบ่งใช้ แยกระบบไฟล์ โซลูชันดังกล่าว เช่น HDFS เช่น Apache Hadoop ช่วยให้คุณเขียนข้อมูลจำนวนมากบนคลัสเตอร์ของโหนดได้ ระบบนี้รักษาความปลอดภัยในการเข้าถึงข้อมูลสำหรับทรัพยากรการคำนวณ สามารถรับข้อมูลในคลัสเตอร์ RAM สำหรับการดำเนินการจากหน่วยความจำและเพื่อประมวลผลความล้มเหลวของส่วนประกอบ HDFS สามารถแทนที่ด้วยระบบไฟล์อื่นๆ รวมถึง Ceph และ GlusterFS
ข้อมูลยังสามารถนำเข้าไปยังระบบย่อยอื่น ๆ เพื่อการเข้าถึงที่มีโครงสร้างมากขึ้น ฐานข้อมูลที่แยกจากกัน โดยเฉพาะฐานข้อมูล NoSQL มีความเหมาะสมกับบทบาท ชาร์ดสามารถประมวลผลข้อมูลที่ต่างกันได้ Іsnuєไม่มีตัวตน ประเภทต่างๆฐานข้อมูลrozpodіlenih เลือกฝากขึ้นอยู่กับว่าคุณต้องการจัดระเบียบและส่งข้อมูลอย่างไร
การคำนวณและวิเคราะห์ข้อมูล
ทันทีที่มีข้อมูลนี้ ระบบอาจสามารถประมวลผลได้ การนับrіven, บางที, єnaivіlnіshoyส่วนหนึ่งของระบบ, เศษของ vimog และpіdkhodiที่นี่สามารถเป็นіttotnovіdіznyatisya เหม็นอับตามประเภทของข้อมูล ข้อมูลมักจะได้รับการประมวลผลซ้ำๆ: สำหรับความช่วยเหลือของเครื่องมือหนึ่งหรือสำหรับความช่วยเหลือของเครื่องมือจำนวนหนึ่งสำหรับการประมวลผลข้อมูลประเภทต่างๆ
การประมวลผลแบบแบตช์เป็นหนึ่งในวิธีการประมวลผลสำหรับชุดข้อมูลที่ยอดเยี่ยม กระบวนการนี้รวมถึงการแบ่งข้อมูลออกเป็นส่วนย่อยๆ วางแผนการประมวลผลส่วนหนังบนเครื่องโอเคเรม จัดเรียงข้อมูลใหม่ตามผลลัพธ์ระดับกลาง จากนั้นจึงคำนวณการเลือกผลลัพธ์ที่เหลือ กลยุทธ์ Tsyu vikoristovu MapReduce ใน Apache Hadoop การประมวลผลแบบแบตช์จะแพงที่สุดเมื่อทำงานกับชุดข้อมูลขนาดใหญ่ ซึ่งจำเป็นต้องคำนวณเป็นจำนวนมาก
ความต้องการงานอื่นๆ จะต้องดำเนินการในโหมดเรียลไทม์ เมื่อข้อมูลนี้ถูกตำหนิ จะต้องดำเนินการและเตรียมการโดยประมาท และระบบสามารถตอบสนองต่อโลกที่ต้องการข้อมูลใหม่ วิธีหนึ่งในการประมวลผลแบบเรียลไทม์คือการประมวลผลโฟลว์ข้อมูลอย่างต่อเนื่อง ซึ่งประกอบด้วยองค์ประกอบสี่ส่วน อีกคน ลักษณะ Zagalnaในตัวประมวลผลตามเวลาจริง - การคำนวณข้อมูลในหน่วยความจำคลัสเตอร์ซึ่งอนุญาตให้ลบการเขียนที่จำเป็นไปยังดิสก์
Apache Storm, Apache Flink และ Apache Spark วิธีทางที่แตกต่างการดำเนินการประมวลผลในชั่วโมงจริง Cі gnuchki tekhnologii ช่วยในการขจัดปัญหาผิวที่พบบ่อยที่สุด วิธีที่ดีที่สุดคือการวิเคราะห์ส่วนย่อยของข้อมูลในแบบเรียลไทม์ เนื่องจากมีการเปลี่ยนแปลงหรือเข้าถึงระบบอย่างรวดเร็ว
โปรแกรมและกรอบงานทั้งหมด มีหลายวิธีในการคำนวณและวิเคราะห์ข้อมูลจากระบบข้อมูลที่ยอดเยี่ยม เครื่องมือเหล่านี้มักจะเชื่อมต่อกับเฟรมเวิร์กขั้นสูงและมีอินเทอร์เฟซเพิ่มเติมสำหรับการเชื่อมต่อกับเพียร์ด้านล่าง ตัวอย่างเช่น Apache Hive จัดเตรียมอินเทอร์เฟซการจัดเก็บข้อมูลสำหรับ Hadoop, Apache Pig จัดเตรียมอินเทอร์เฟซการรวบรวมข้อมูล และโมดูลข้อมูล SQL ให้บริการโดย Apache Drill, Apache Impala, Apache Spark SQL และ Presto Apache SystemML, Apache Mahout และ MLlib เช่น Apache Spark ติดอยู่ในการเรียนรู้ของเครื่อง สำหรับการเขียนโปรแกรมเชิงวิเคราะห์โดยตรง ซึ่งได้รับการสนับสนุนอย่างกว้างขวางจากระบบนิเวศข้อมูล ให้ใช้ R และ Python
การแสดงผลลัพธ์
บ่อยครั้งการรับรู้ถึงแนวโน้มหรือการเปลี่ยนแปลงในข้อมูลบางครั้งสำคัญกว่าการละเลยคุณค่า การแสดงข้อมูล - หนึ่งในที่ใหญ่ที่สุด วิธีการรูตเปิดเผยแนวโน้มและจัดจุดข้อมูลจำนวนมาก
การประมวลผลแบบทดสอบตามเวลาจริงสำหรับการแสดงภาพเมตริกเซิร์ฟเวอร์โปรแกรม ข้อมูลมักมีการเปลี่ยนแปลง และความแปรปรวนอย่างมากในการแสดงเสียงบ่งบอกถึงผลกระทบที่มีนัยสำคัญต่อค่ายของระบบขององค์กร โครงการเช่น Prometheus สามารถบิดเพื่อประมวลผลสตรีมข้อมูลและอนุกรมเวลาและการแสดงข้อมูลเป็นภาพ
วิธีหนึ่งที่นิยมในการแสดงภาพข้อมูลคือ Elastic stack ซึ่งก่อนหน้านี้เรียกว่า ELK stack Logstash ได้รับชัยชนะในการรวบรวมข้อมูล, Elasticsearch ใช้สำหรับสร้างดัชนีข้อมูล และ Kibana ใช้สำหรับการแสดงภาพ สแต็ค Elastic สามารถทำงานกับ danim ที่ยอดเยี่ยม แสดงภาพผลลัพธ์ และคำนวณหรือโต้ตอบกับเมตริกดิบ สแต็กที่คล้ายกันสามารถนำออกไปได้โดยการรวม Apache Solr เพื่อจัดทำดัชนีทางแยกของ Kibana ภายใต้ชื่อ Banana สำหรับการแสดงภาพ กองดังกล่าวเรียกว่าไหม
เทคโนโลยีการแสดงภาพล่าสุดสำหรับงานแบบโต้ตอบในคลังข้อมูลคือเอกสาร โครงการดังกล่าวช่วยให้คุณสามารถตรวจสอบและแสดงข้อมูลในรูปแบบโต้ตอบในรูปแบบที่สะดวกสำหรับ นอนหลับวิคตอเรียบรรณาการนั้น ตัวอย่างยอดนิยมของอินเทอร์เฟซนี้คือ Jupyter Notebook และ Apache Zeppelin
อภิธานศัพท์ของบรรณาการอันยิ่งใหญ่
- Great data - คำกว้างๆ สำหรับการกำหนดชุดข้อมูล ซึ่งสามารถสรุปได้อย่างถูกต้อง คอมพิวเตอร์ที่ดีเครื่องมือ abo ผ่าน obsyag, shvidkіst nahodzhennya และraznomanіtnіst คำนี้ฟังดูเหมือน zastosovuetsya สำหรับเทคโนโลยีและกลยุทธ์ในการทำงานกับเดนิมดังกล่าว
- การประมวลผลแบบกลุ่มเป็นกลยุทธ์ที่ครอบคลุมซึ่งรวมถึงการประมวลผลข้อมูลสำหรับชุดที่ยอดเยี่ยม เสียง วิธีนี้เหมาะสำหรับการทำงานกับข้อมูลที่ไม่ใช่เทอร์มินัล
- การนับแบบคลัสเตอร์คือการฝึกรวมทรัพยากรของเครื่องจักรจำนวนหนึ่งและจัดการความสามารถมากมายในการเพิ่มงาน หากจำเป็น keruvannya rіvenโดยคลัสเตอร์ซึ่งทำให้สามารถสร้างการเชื่อมต่อระหว่างโหนด okremy
- ทะเลสาบแห่งเดนมาร์กเป็นแหล่งรวมของผู้ที่ได้รับเลือกให้เป็นเด็กกำพร้า คำนี้มักใช้เพื่อแสดงถึงเครื่องบรรณาการที่ยิ่งใหญ่ที่ไม่มีโครงสร้างและมักจะเป็นเครื่องบรรณาการที่ยิ่งใหญ่
- ประเภทของชุดข้อมูลเป็นคำศัพท์กว้างๆ สำหรับแนวทางปฏิบัติต่างๆ ที่มองหาเทมเพลตในชุดข้อมูลที่ยอดเยี่ยม จุดประสงค์ของการทดสอบคือการจัดระเบียบข้อมูลจำนวนมากเพื่อให้เกิดความเข้าใจและการสื่อสารมากขึ้น
- คลังข้อมูลเป็นคอลเล็กชันขนาดใหญ่ที่จัดไว้อย่างดีสำหรับการวิเคราะห์และzvіtnostі เมื่อมองจากวิวทะเลสาบ คอลเล็กชันเหล่านี้ซ้อนกันด้วยข้อมูลที่มีการจัดรูปแบบและการจัดวางอย่างดี รวมกับเรือลำอื่นๆ คอลเล็กชั่นเครื่องบรรณาการมักถูกมองว่าเป็นเครื่องบรรณาการที่ยิ่งใหญ่ แต่มักจะเป็นส่วนประกอบ ระบบพิเศษการเก็บรวบรวมข้อมูล
- ETL (แยก แปลง โหลด) นี่คือกระบวนการสิ้นสุดและเตรียมข้อมูลที่ยังไม่เสร็จเพื่อชนะ Vіn po'yazaniy іz danih dani แต่ลักษณะของกระบวนการนี้ยังแสดงให้เห็นในท่อของระบบของ Great dani
- Hadoop เป็นเพียงโครงการ Apache ที่มีโอเพ่นซอร์สโค้ดสำหรับผู้ยิ่งใหญ่ มันถูกสร้างขึ้นจากระบบไฟล์แยกต่างหากที่เรียกว่า HDFS และตัววางแผนคลัสเตอร์และทรัพยากรที่เรียกว่า YARN ความเป็นไปได้ การประมวลผลแบทช์อาศัยกลไกการคำนวณ MapReduce พร้อมกันกับ MapReduce ใน Hadoop goroutines ปัจจุบัน คุณสามารถเรียกใช้ระบบการแจงนับและการวิเคราะห์อื่นๆ
- การคำนวณในหน่วยความจำเป็นกลยุทธ์ที่ถ่ายโอนการเคลื่อนไหวของชุดข้อมูลที่ทำงานไปยังหน่วยความจำของคลัสเตอร์ การเรียกเก็บเงินของPromіzhnіจะไม่ถูกบันทึกลงในดิสก์กลิ่นเหม็นของกลิ่นเหม็นจะถูกบันทึกจากหน่วยความจำ Tse ช่วยให้ระบบได้เปรียบในด้านความเร็วอย่างมาก เท่ากับระบบที่เกี่ยวข้องกับ I/O
- แมชชีนเลิร์นนิงคือการติดตามและฝึกฝนการออกแบบระบบ ซึ่งสามารถเรียนรู้ ปรับปรุง และปรับปรุงได้บนพื้นฐานของข้อมูลที่ส่งถึงพวกเขา เสียง pіd tsim mаyut บนuvazіrealіzatsіyuอัลกอริธึมการทำนายและสถิติ
- การลดแผนที่ (อย่าสับสนกับ MapReduce เช่น Hadoop) เป็นอัลกอริทึมสำหรับการวางแผนคลัสเตอร์แจงนับ กระบวนการนี้รวมถึงการแบ่งย่อยของงานระหว่างโหนดและการนำผลลัพธ์ขั้นกลางออก การสับเปลี่ยนและความก้าวหน้าของค่าเดียวกันสำหรับการสรรหาสกิน
- NoSQL เป็นคำกว้างๆ ที่หมายถึงฐานข้อมูล แยกย่อยตามแบบจำลองเชิงสัมพันธ์แบบดั้งเดิม ฐานข้อมูลของ NoSQL นั้นเหมาะอย่างยิ่งสำหรับสมองอันยอดเยี่ยมของ gnuchkosti และ razpodіlenіyarkhitekturі
- การประมวลผลแบบสตรีมคือแนวปฏิบัติในการคำนวณองค์ประกอบบางอย่างของข้อมูลสำหรับ її ที่ย้ายจากระบบ ซึ่งช่วยให้คุณวิเคราะห์ข้อมูลในโหมดเรียลไทม์ และเหมาะสำหรับการประมวลผลการดำเนินการด้านคำศัพท์ด้วยเมตริกความเร็วสูงต่างๆ
ในช่วงเวลาของฉัน ฉันรู้สึกถึงคำว่า "Big Data" จาก German Gref (หัวหน้า Oschadbank) Movlyav มีกลิ่นเหม็นในเวลาเดียวกันอย่างแข็งขัน pratsyuyut เหนือ provadzhennyam ช่วยในการใช้เวลาหนึ่งชั่วโมงในการทำงานกับลูกค้าผิว
ทันใดนั้น ฉันสะดุดกับความเข้าใจเหล่านี้ในร้านค้าออนไลน์ของลูกค้า ซึ่งฉันทำงานและเพิ่มการแบ่งประเภทจากตำแหน่งสินค้าโภคภัณฑ์ไม่กี่พันรายการเป็นหนึ่งหมื่นรายการ
หากคุณถามว่า Yandex ต้องการนักวิเคราะห์ข้อมูลขนาดใหญ่หรือไม่ Todi ฉัน vyrivishiv razіbratisyaมากขึ้นในหัวข้อนี้และในขณะเดียวกันก็เขียนบทความเช่นrozpovіst, scho สำหรับคำดังกล่าวเช่นจิตใจrozburhuєของผู้จัดการ TOP และพื้นที่อินเทอร์เน็ต
มันคืออะไร
ฟังดูเหมือนกับบทความของคุณ ฉันจะเริ่มต้นด้วยคำอธิบายว่าคำนี้คืออะไร Tsya statya อย่ากลายเป็นตำหนิ
อย่างไรก็ตาม tse viklikano เราต่อหน้าที่จะไม่แสดง bazhanny ที่ฉันมีเหตุผล แต่สำหรับพวกเขาว่าหัวข้ออยู่ในวิธีที่ถูกต้องพับและเรียกร้องคำอธิบาย
ตัวอย่างเช่น คุณสามารถอ่านข้อมูลขนาดใหญ่ดังกล่าวจาก Wikipedia คุณจะไม่เข้าใจอะไรเลย แต่จากนั้นให้เปิดบทความนี้ เพื่อที่คุณจะได้ทราบเกี่ยวกับการกำหนด zastosovnosti นั้นสำหรับธุรกิจ เริ่มจากคำอธิบายแล้วไปที่แอปพลิเคชันสำหรับธุรกิจ
ข้อมูลขนาดใหญ่คือข้อมูลขนาดใหญ่ แปลกใช่มั้ย? แท้จริงแล้วจากภาษาอังกฤษแปลว่า "เครื่องบรรณาการที่ยิ่งใหญ่" อาจมีการระบุชื่อ Ale tse สำหรับกาน้ำชา
เทคโนโลยีข้อมูลขนาดใหญ่– ce pіdkhіd / วิธีการประมวลผลข้อมูลจำนวนมากจากการรวบรวมข้อมูลใหม่ซึ่งเป็นสิ่งสำคัญในการประมวลผลด้วยวิธีที่สำคัญที่สุด
ข้อมูลสามารถเป็นแบบทั่วไป (มีโครงสร้าง) และแบ่งออก (ไม่มีโครงสร้าง)
คำว่า Vinic นั้นเพิ่งเกิดขึ้นไม่นาน ในปี 2008 ในวารสารทางวิทยาศาสตร์ บทความนี้ได้รับการรายงานว่าจำเป็นสำหรับการทำงานที่มีข้อมูลจำนวนมาก เนื่องจากมีการเติบโตขึ้นในความก้าวหน้าทางเรขาคณิต
ตัวอย่างเช่น ข้อมูลบนอินเทอร์เน็ตอย่างระมัดระวัง หากคุณต้องการบันทึก ข้อมูลจะถูกประมวลผลเอง จะเพิ่มขึ้น 40% อีกครั้ง: +40% สู่สาธารณะสำหรับข้อมูลใหม่บนอินเทอร์เน็ต
มีการจัดเตรียมเอกสารที่เข้าใจได้ดีเพียงใดและเข้าใจวิธีการประมวลผลอย่างไร (โอนไปที่ ผู้ชมอิเล็กทรอนิกส์ใส่ในโฟลเดอร์หนึ่งหมายเลข) ที่ทำงานกับข้อมูลตามที่แสดงใน "carries" อื่น ๆ และภาระผูกพันอื่น ๆ :
- เอกสารทางอินเทอร์เน็ต
- บล็อกและโซเชียลมีเดีย
- เสียง/วิดีโอ dzherel;
- วิมิริววัลนี สิ่งก่อสร้าง.
Є ลักษณะที่ช่วยให้คุณสามารถเพิ่มข้อมูลและข้อมูลไปยังข้อมูลขนาดใหญ่ ดังนั้น ไม่ใช่ข้อมูลทั้งหมดที่สามารถเป็นคำคุณศัพท์สำหรับการวิเคราะห์ได้ ลักษณะเหล่านี้มีความเข้าใจที่สำคัญเกี่ยวกับวันสำคัญ หนวดเหม็นสามวี
- เกี่ยวกับ `em(Vid ภาษาอังกฤษวอลุ่ม). ข้อมูลจะลดลงตามขนาดของภาระผูกพันทางกายภาพของ "เอกสาร" ที่ทำการวิเคราะห์
- Shvidkist(จากภาษาอังกฤษ Velocity). ดานิลไม่ได้ยืนหยัดในการพัฒนาตนเอง แต่เติบโตอย่างมั่นคง และด้วยเหตุนี้เอง จึงจำเป็นต้องแต่งกายแบบสวีเดนเพื่อผลลัพธ์ที่ดีขึ้น
- Raznomanіtnіst(Vіdภาษาอังกฤษวาไรตี้). ข้อมูลอาจเป็นรูปแบบเดียว Tobto สามารถแบ่งโครงสร้างหรือโครงสร้างได้บ่อยครั้ง
อย่างไรก็ตาม VVV เป็นระยะ ๆ เพิ่มหนึ่งในสี่ของ V (ความจริง - ความน่าเชื่อถือ / ความน่าเชื่อถือของข้อมูล) และเพิ่มหนึ่งในห้าของ V (ในบางกรณี ความมีชีวิต - ความมีชีวิต - ชีวิต ในส่วนอื่น - คุณค่า - มูลค่า)
ที่นี่ฉันกำลังพยายามค้นหา 7V วิธีกำหนดลักษณะข้อมูลที่มีค่าวันที่สำคัญ ในความคิดของฉัน เบียร์ tse іz serії (เพิ่ม P เป็นระยะ ต้องการ cob 4 ที่เพียงพอสำหรับ rozuminnya)
เรามีอยู่แล้ว 29,000 คน
เปิด
ใครต้องการบ้าง
โพสต์ฟีดแบบลอจิคัล คุณจะชนะข้อมูลได้อย่างไร (วันที่สำหรับหลายร้อยและหลายพันเทราไบต์ใหญ่แค่ไหน)
นำทางไม่เป็นเช่นนั้น แกนคือข้อมูล nav_scho นั้นมาพร้อมกับวันสำคัญเดียวกันหรือไม่ บิ๊กดาต้าที่ซบเซาในด้านการตลาดและในธุรกิจคืออะไร?
- ฐานข้อมูลหลักไม่สามารถบันทึกและประมวลผลได้ (ฉันพูดทันทีว่าไม่เกี่ยวกับการวิเคราะห์ แต่เพียงแค่บันทึกการประมวลผลนั้น) ของข้อมูลจำนวนมาก
วันที่ใหญ่ไม่ถูกต้อง รวบรวมข้อมูลสำคัญนั้นสำเร็จด้วยความมุ่งมั่นอย่างยิ่ง - โครงสร้างของวิดีโอที่ควรหาได้จากแหล่งต่างๆ (วิดีโอ ภาพ เสียง และ เอกสารข้อความ) ในรูปลักษณ์เดียวที่ชาญฉลาดและชัดเจน
- การก่อตัวของการวิเคราะห์และการสร้างการคาดการณ์ที่แม่นยำบนพื้นฐานของข้อมูลที่มีโครงสร้างและข้อมูลทั่วไป
มันซับซ้อน. หากคุณพูดง่ายๆ ก็คือ จงเป็นนักการตลาดแบบใดแบบหนึ่ง ฉลาดกว่าแบบใดแบบหนึ่ง ที่คุณจะได้รับข้อมูลมากมาย (เกี่ยวกับตัวคุณ บริษัทของคุณ คู่แข่งของคุณ แหล่งข้อมูลของคุณ) คุณก็จะเห็นผลลัพธ์ที่ดีได้:
- ความเข้าใจภายนอกของบริษัทและธุรกิจของคุณจากด้านตัวเลข
- Vivechity คู่แข่งของคุณ และที่ศาลของเขาอนุญาตให้ virvatis ไปข้างหน้าสำหรับ rahunok เหนือพวกเขา
- จำได้ ข้อมูลใหม่เกี่ยวกับลูกค้าของคุณ
ความจริงที่ว่าเทคโนโลยีบิ๊กดาต้าให้ผลลัพธ์ขั้นสูง ทุกคนต่างวิ่งเข้าหามัน พวกเขาพยายามทำผิดพลาดทางด้านขวาของบริษัทเพื่อลดการขายและเปลี่ยนจำนวน และโดยเฉพาะอย่างยิ่งแล้ว:
- การเพิ่มยอดขายและการขายเพิ่มเติมเพื่อประโยชน์ของความรู้ที่ดีขึ้นในความสนใจของลูกค้า
- ค้นหาสินค้ายอดนิยมและเหตุผลที่ซื้อ (і navpaki);
- การปรับปรุงบริการของผลิตภัณฑ์
- Polypshennya บริการที่เท่าเทียมกัน;
- ส่งเสริมความภักดีและการปฐมนิเทศลูกค้า
- ความก้าวหน้าของ shakhraystva (มีความเกี่ยวข้องมากขึ้นสำหรับภาคการธนาคาร);
- ลดไซวิค vitrate
ก้นที่กว้างที่สุดซึ่งมุ่งเป้าไปที่ dzherelakh - tse เห็นได้ชัดว่า บริษัท Apple เนื่องจากรวบรวมข้อมูลเกี่ยวกับ coristuvachiv (โทรศัพท์, หนังสือรุ่น, คอมพิวเตอร์)
จากการมีอยู่ของระบบนิเวศ บริษัทเองก็รู้เกี่ยวกับคอริสตูวาชีฟและให้ vicorista แย่งชิงผลกำไรไป
คุณสามารถอ่านคำพูดและอื่น ๆ ในบทความเดียวกัน Crimean qiєї
ก้นสมัยใหม่
ฉันจะบอกคุณเกี่ยวกับโครงการอื่น แม่นยำยิ่งขึ้นเกี่ยวกับบุคคลในอนาคตซึ่งเป็นโซลูชันข้อมูลขนาดใหญ่ที่ได้รับชัยชนะ
Ce Elon Musk และ บริษัท โยคะเทสลา ความฝันของ Yogo - ทำให้รถยนต์เป็นอิสระ ดังนั้นคุณจึงนั่งหลัง Kermo ใช้ระบบขับเคลื่อนอัตโนมัติจากมอสโกวถึงวลาดีวอสตอคและ ... ร้องเพลงเพราะคุณไม่จำเป็นต้องแกะสลักรถแม้ว่าคุณจะทำทุกอย่างด้วยตัวเองก็ตาม
มันจะเป็นแฟนตาซีหรือไม่? เอลไม่รู้! เป็นเพียงว่า Ilon ได้สร้าง Google ที่ฉลาดขึ้นอย่างมั่งคั่งเช่นการหวงแหนรถยนต์เพื่อขอความช่วยเหลือจากสหายหลายสิบคน І pіshov inhim วิธี:
- รถหนังสำหรับขายมีคอมพิวเตอร์ติดตั้งไว้ซึ่งรวบรวมข้อมูลทั้งหมด
All tse หมายถึงทุกอย่าง เกี่ยวกับน้ำ สไตล์น้ำ ถนน navkolo การเคลื่อนไหวของรถคันอื่น จำนวนข้อมูลดังกล่าวคือ 20-30 GB ต่อปี - ข้อมูลเพิ่มเติมจะถูกส่งผ่านลิงค์ดาวเทียมไปยังคอมพิวเตอร์ส่วนกลางซึ่งมีส่วนร่วมในการประมวลผลข้อมูลเหล่านี้
- ขึ้นอยู่กับข้อมูลขนาดใหญ่ วิธีการประมวลผล คอมพิวเตอร์เดนมาร์ก,จะมีรุ่นรถไร้คนขับ
ก่อนการกล่าวสุนทรพจน์ หาก Google ทำได้ไม่ดีและรถยนต์ของพวกเขาใช้เวลาทั้งชั่วโมงในอุบัติเหตุ ดังนั้นเพื่อเห็นแก่หุ่นยนต์บิ๊กดาต้า ทำให้มันดีขึ้นอย่างมาก และแม้แต่รุ่นทดสอบก็ให้ผลลัพธ์ที่แย่ยิ่งกว่าเดิม
เบียร์ ... Tse ทั้งหมดเศรษฐกิจ เราทุกคนเกี่ยวกับส่วนเกินคืออะไร อีกเรื่องหนึ่งเกี่ยวกับส่วนเกินคืออะไร? หลายสิ่งหลายอย่างซึ่งอาจเป็นการออกเดทที่ยิ่งใหญ่ ไม่ได้เกี่ยวข้องกับเงินเดือนของเพนนีนั้น
สถิติของ Google ขึ้นอยู่กับข้อมูลขนาดใหญ่ซึ่งแสดงให้เห็นถึงความสมบูรณ์ของแม่น้ำ
ก่อนหน้านั้นในขณะที่แพทย์ใส่ร้ายเกี่ยวกับซังของการระบาดของการติดเชื้อในภูมิภาคของฉันซึ่งในภูมิภาคนี้มีเครื่องดื่ม poshukov จำนวนมากสำหรับการรักษาโรคนี้
ด้วยวิธีนี้ เมื่อปลูกฝังข้อมูลจากการวิเคราะห์เหล่านั้นอย่างถูกต้อง คุณสามารถกำหนดการคาดการณ์และส่งต่อหูของโรคระบาด หน่วยงานราชการตาїхdії
Zastosuvannya ในรัสเซีย
อย่างไรก็ตามรัสเซียก็เหมือนผู้นำ troch prigalmovuє ดังนั้นจุดประสงค์ของข้อมูลขนาดใหญ่ในรัสเซียจึงปรากฏขึ้นเมื่อ 5 ปีที่แล้ว (ฉันกำลังพูดถึงบริษัทขนาดใหญ่เอง)
และอย่าแปลกใจกับตลาดที่เติบโตอย่างรวดเร็วที่สุดแห่งหนึ่งของโลก (ยาเสพติดและการสูบบุหรี่เป็นเรื่องที่ไม่สบายใจ) แม้ว่าตลาดซอฟต์แวร์สำหรับการรวบรวมและวิเคราะห์ข้อมูลขนาดใหญ่จะเพิ่มขึ้น 32%
ในการอธิบายลักษณะของตลาดข้อมูลขนาดใหญ่ในรัสเซีย ฉันจะนึกถึงขวดโหลเก่าๆ หนึ่งขวด Big date tse yak sex up to 18 ปี. ทุกสิ่งทุกอย่างดูเหมือนจะเกี่ยวกับเรื่องนี้ มันช่างดูหรูหราและมีของจริงอยู่ไม่กี่อย่าง และเป็นเรื่องน่าละอายที่ทุกคนจะรู้ว่าพวกเขาเองไม่ได้ดูแลพวกเขา และก็จริง มีงานกาล่ามากมาย แต่มีงานจริงไม่กี่งาน
แม้ว่าบริษัท Gartner ก่อนหน้านี้ได้ประกาศไปแล้วในปี 2015 ว่าวันสำคัญนั้นไม่มีแนวโน้มเติบโตอีกต่อไป (เช่น พูดอย่างน้อยก็คือ ความฉลาดของชิ้นส่วน) แต่เป็นชุดเครื่องมืออิสระทั้งชุดสำหรับการวิเคราะห์และการพัฒนาเทคโนโลยีขั้นสูง
มีบทบาทมากที่สุดในโลก, การพัฒนาข้อมูลขนาดใหญ่ในรัสเซีย, ธนาคาร/ประกัน (ไม่ใช่เพื่ออะไรที่ฉันเป็นหัวหน้าของ Oschadbank), โทรคมนาคม, ค้าปลีก, ไม่แข็งแกร่ง และภาคอธิปไตย
ตัวอย่างเช่น รายงานใหม่เกี่ยวกับภาคเศรษฐกิจขนาดเล็ก วิธีชนะอัลกอริทึมข้อมูลขนาดใหญ่
1. ธนาคาร
มารับมันจากธนาคารและtієїіnformatsiїพวกเขาส่งกลิ่นเหม็นเกี่ยวกับเราที่dіїของเราได้อย่างไร ตัวอย่างเช่น ฉันเลือกธนาคารรัสเซีย TOP-5 ที่ลงทุนในข้อมูลขนาดใหญ่:
- ออสชาดแบงค์;
- แก๊ซพรอมแบงก์;
- VTB 24;
- ธนาคารอัลฟ่า;
- ธนาคารทิงคอฟฟ์
ยินดีต้อนรับโดยเฉพาะอย่างยิ่งในหมู่ผู้นำรัสเซีย Alfa Bank อย่างน้อยที่สุด จำเป็นต้องยืนยันว่าธนาคารเป็นพันธมิตรอย่างเป็นทางการของประเภทดังกล่าว จำเป็นต้องแนะนำเครื่องมือทางการตลาดใหม่ให้กับบริษัทของคุณ
เอล ใช้ vikoristannya ที่ส่งเสริมข้อมูลขนาดใหญ่ที่อยู่ห่างไกล ฉันต้องการแสดงให้คุณเห็นบนขวดโหล ซึ่งฉันควรเป็นรูปลักษณ์ที่ไม่ได้มาตรฐานของ vchinka ของเจ้านายของคุณ
ฉันกำลังพูดถึงธนาคารทิงคอฟฟ์ งานหลักของเราคือการพัฒนาระบบสำหรับการวิเคราะห์ข้อมูลที่ยอดเยี่ยมในแบบเรียลไทม์ผ่านฐานลูกค้าที่กำลังเติบโต
ผลลัพธ์: ชั่วโมงของกระบวนการภายในสั้นลงอย่างน้อย 10 เท่า และสำหรับกระบวนการอื่นๆ ลดลงมากกว่า 100 เท่า
มันไม่ใช่คำถามใหญ่ คุณรู้หรือไม่ว่าทำไมฉันถึงเริ่มพูดถึงการม้วนและการบิดที่ไม่ได้มาตรฐานของ Oleg Tinkov? ในความคิดของฉัน กลิ่นเหม็นช่วยให้เขาเปลี่ยนจากนักธุรกิจระดับกลาง เช่น คนหลายพันคนในรัสเซีย ให้กลายเป็นหนึ่งในธุรกิจที่บ้านและที่บ้านมากที่สุด เมื่อได้รับการยืนยัน ให้ประหลาดใจกับกลุ่มที่ผิดปกติของวิดีโอ:
2. เกเร
ทุกสิ่งทุกอย่างถูกพับอย่างมั่งคั่งมากขึ้นในการขัดขืนไม่ได้ นี่เป็นตัวอย่างเดียวกัน ซึ่งฉันต้องการนำเสนอให้คุณเข้าใจวันสำคัญในขอบเขตของธุรกิจที่ยอดเยี่ยม ออกจากข้อมูล:
- ความมุ่งมั่นอันยิ่งใหญ่ในการจัดทำเอกสารข้อความ
- Vidkrit dzherela (ดาวเทียมส่วนตัวที่ส่งข้อมูลเกี่ยวกับการเปลี่ยนแปลงของที่ดิน);
- การแบ่งปันข้อมูลที่ไม่ถูกควบคุมบนอินเทอร์เน็ตอย่างงดงาม
- Postiyni เปลี่ยนเป็น dzherelakh และ danikh
І บนพื้นฐานของความจำเป็นในการเตรียมและประเมินความหลากหลายของที่ดินตัวอย่างเช่นภายใต้หมู่บ้านอูราล มืออาชีพมีเวลาหนึ่งวันในห่วงโซ่
ที่ หุ้นส่วนของรัสเซียประเมิน & ROSEKO ในวิธีที่ดีที่สุดและดำเนินการวิเคราะห์ข้อมูลขนาดใหญ่ของตนเองสำหรับความช่วยเหลือของซอฟต์แวร์ ในราคาไม่เกิน 30 งานขนาดเล็ก ปรับวันและ 30 นาที ขายปลีกขนาดมหึมา
เครื่องมือพับ
เห็นได้ชัดว่าข้อมูลจำนวนมากไม่สามารถจัดเก็บและประมวลผลบนฮาร์ดดิสก์แบบธรรมดาได้
และความปลอดภัยของซอฟต์แวร์ เช่น โครงสร้างและการวิเคราะห์ข้อมูล คำนึงถึงพลังทางปัญญาและความสนใจในการพัฒนาของผู้เขียน Prote, єіnstrumenti, บนพื้นฐานของการสร้างความงามทั้งหมด:
- Hadoop & MapReduce;
- ฐานข้อมูล NoSQL;
- เครื่องมือสำหรับคลาส Data Discovery
พูดตามตรง ฉันไม่สามารถอธิบายให้คุณฟังได้ชัดเจนว่ากลิ่นเหม็นใดถูกใช้ทีละตัว ความรู้ที่หุ่นยนต์และสุนทรพจน์เหล่านี้สอนในสถาบันทางกายภาพและคณิตศาสตร์
ฉันกำลังพูดถึงอะไร ทำไมฉันอธิบายไม่ได้ จำได้ไหมว่าในโรงภาพยนตร์ทุกโรงโจรเข้ามาที่ธนาคารและสร้างซาลิซยากิฟทุกประเภทจำนวนมากโดยเชื่อมต่อกับปาเป้า? วันที่เดียวกันและใหญ่เหล่านั้น ตัวอย่างเช่น โมเดลแกนปัจจุบันเป็นหนึ่งในผู้นำในตลาด
เครื่องมือวันที่ใหญ่
ราคาในการกำหนดค่าสูงสุดคือ 27 ล้านรูเบิลต่อแร็ค เห็นได้ชัดว่า Tse รุ่นหรูหรา ฉันไม่ต้องการให้คุณรู้ว่าธุรกิจของคุณสร้างบิ๊กดาต้าอย่างไร
สั้น ๆ เกี่ยวกับ smut
คุณสามารถสมัครงานให้กับคุณ ธุรกิจขนาดเล็กและขนาดกลางได้หรือไม่?
เกี่ยวกับเรื่องนี้ ฉันจะให้คำพูดจากบุคคลหนึ่งกับคุณ: "ในชั่วโมงถัดไป ลูกค้าจะเรียกร้องบริษัท เพื่อให้พวกเขาสามารถเข้าใจพฤติกรรมของพวกเขาได้ดีขึ้น เสียงที่ตอบสนองต่อพวกเขาได้อย่างเต็มที่"
เอลลองดูความจริงในวิชิ เพื่อจัดการบิ๊กดาต้าในธุรกิจขนาดเล็ก คุณแม่ไม่เพียงต้องการงบประมาณจำนวนมากสำหรับการพัฒนาและส่งเสริมซอฟต์แวร์เท่านั้น แต่สำหรับการปรับปรุงฟาฮิฟต์ซิฟด้วย ฉันต้องการนักวิเคราะห์ข้อมูลขนาดใหญ่และผู้ดูแลระบบ
ฉันกำลังพูดถึงสิ่งที่คุณมีข้อมูลดังกล่าวสำหรับการประมวลผล
ตกลง. สำหรับธุรกิจขนาดเล็ก หัวข้อ mayzhe ไม่ zastosovuetsya เบียร์ไม่ได้หมายความว่าคุณต้องลืมทุกสิ่งที่คุณอ่านด้านบน เพียงแค่ค้นหาข้อมูลของคุณและผลลัพธ์ของการวิเคราะห์ข้อมูลก็มาจากทั้งบริษัทต่างประเทศและรัสเซีย
ตัวอย่างเช่น การกระจายตัวของมาตรการ Target สำหรับการวิเคราะห์เพิ่มเติมจากข้อมูลขนาดใหญ่ อธิบายว่าสตรีมีครรภ์ก่อนไตรมาสที่ 1 ของการตั้งครรภ์อื่น (ตั้งแต่วันที่ 1 ถึงวันที่ 12 ของการตั้งครรภ์) มักซื้อผลิตภัณฑ์ที่ไม่มีอะโรมาติก
Zavdyaki tsim danim เหม็นที่จะบังคับให้พวกเขาคูปองพร้อมส่วนลดสำหรับแมวที่ไม่มีรสด้วยคำว่าdії
แล้ววีล่ะ อย่างเช่น ร้านกาแฟเล็กๆ ล่ะ? ใช่มันง่าย ชนะโปรแกรมความภักดี และในช่วงเวลาของวันและจุดเริ่มต้นของการรวบรวมข้อมูล คุณไม่เพียงแต่สามารถประกาศให้กับลูกค้าที่เกี่ยวข้องกับความต้องการของพวกเขาเท่านั้น แต่ยังสนับสนุนให้ไม่มีการขายและมีอัตรากำไรสูงอย่างแท้จริงด้วยการคลิกคู่หมี
Zvіdsi vysnovok ไม่น่าเป็นไปได้ที่จะช่วยธุรกิจขนาดเล็ก และแกนของการชนะผลงานของบริษัทอื่นคือ obov'yazkovo