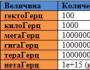
Indirizzi del ragno universale. Risorse informative su Internet. Web in tutto il mondo. Qual è il marciapiede di tutto il mondo
La rete globale di Internet acquisisce le proprie risorse e servizi di informazione, che regolarmente corrodono quasi un miliardo di persone in tutti i paesi del mondo.
Lo sviluppo peloso di Internet, che è il resto di 15 anni, è in anticipo sulle menti dell'emergere dell'All-World's Spider. " Web in tutto il mondo- una corretta traduzione della parola inglese "World Wide Web", spesso indicata come WWW o Web.
La tecnologia del ragno di tutto il mondo. La rete universale della tecnologia vittoriosa dell'ipertesto, in cui i documenti sono collegati a se stessi per chiedere aiuto iperposilano.
Nello yakost vkazivnikiv posilan sui lati web si possono presentare frammenti del testo, che si vedono a colori e sotto le poltrone, oltre a immagini grafiche, che sono visti dalla cornice. L'attivazione sul lato Web di uscita dell'indicatore della richiesta (ad esempio cliccando con il mouse) prevede il passaggio al lato Web richiesto (piccolo 6.10).
Web in tutto il mondo- ci sono centinaia di milioni di server Web su Internet, che vendicano centinaia di miliardi di siti Web, che vincono la tecnologia ipertestuale.
Il lato web può essere multimedia, in modo da poter utilizzare vari oggetti multimediali: immagini grafiche, animazioni, suoni e video.
Il lato web può essere interattivo, in modo da poter compilare i campi richiesti durante la registrazione alla posta elettronica gratuita, durante gli acquisti nei negozi online, ecc.
Tematicamente correlato ai lati Web, è possibile visualizzare le rappresentazioni del modulo sito web, Cioè, un intero sistema di documenti, legati insieme in un tutto per chiedere aiuto.
Indirizzi di siti web. In un'ora data sui server Web di Internet, viene salvato un gran numero di lati Web. È possibile trovare un sito Web su Internet utilizzando l'indirizzo del sito Web.
Indirizzi di siti webabilitare il metodo di accesso al documento e il nome del server Internet su cui si trova il documento.
Per accedere ai lati Web, è stato stabilito il protocollo di trasferimento ipertestuale HTTP (Hyper Text Transfer Protocol). Quando scrivi il protocollo dopo il tuo nome, c'è un riso doppio e due morti: http: //
A titolo di esempio, annotiamo l'indirizzo del frontespizio del sito Web "Informatics and Information Technologies". L'account è stato risolto sul server iit.metodist.ru e gli indirizzi sembrano:
http://iit.methodist.ru
WWW-informazione web: sistema di denominazione su Internet, nome del dominio e indirizzi IP.
Web in tutto il mondo(ingl. World Wide Web) - è stato implementato un sistema che dà accesso a documenti collegati tra loro, elaborati su computer diversi, collegati a Internet. Per il riconoscimento dei Pawutini di Tutto il Mondo, la parola ragnatela(ingl. ragnatela"pavutinnya") quell'abbreviazione www.
Il web in tutto il mondo è approvato da centinaia di milioni di server web. La maggior parte delle risorse dell'All-World's Web sono basate sulla tecnologia dell'ipertesto. I documenti ipertestuali ospitati da All-World Merazh sono chiamati pagine web. Un dekilka di pagine web, unite da un tema, un design comune e anche legate insieme da forze e suoni sullo stesso server web, è chiamato sito web. Per la revisione delle pagine web vengono utilizzati appositi programmi - browser (ing. browser).
La ragnatela tutta leggera ha richiamato la giusta rivoluzione Tecnologie informatiche quella vibrazione per lo sviluppo di Internet. La gente comune, parlando di Internet, pensa spesso al web di All-World. Tuttavia, è importante capire che non sono la stessa cosa.
I Web di tutto il mondo sono approvati da milioni di server Web in Internet, sparsi in tutto il mondo. Server web - ce programma per computer che viene eseguito su un computer connesso e utilizza il protocollo HTTP per trasferire i dati. Nel modo più semplice, un tale programma rimuove la richiesta HTTP alla risorsa, trova il file di origine sul disco rigido locale e lo gestisce sul computer. Server Web pieghevoli più grandi creati per consentire alle richieste HTTP di generare dinamicamente documenti per modelli e scenari aggiuntivi.
Per rivedere le informazioni prelevate dal server web, computer client ristagnare programma speciale- Programma di navigazione in rete. La funzione principale di un browser web è la visualizzazione dell'ipertesto. L'onnipotente ragnatela è indissolubilmente legata ai concetti dell'ipertesto e di quell'iperspazio. La maggior parte delle informazioni su Internet è l'ipertesto stesso.
Per la creazione, la selezione dell'ipertesto nel web di All-World, è tradizionalmente vittoriosa mov html(ingl. Hyper Text Markup Language"Ipertesto Mova razmіtki"). Il lavoro di creazione (rendering) di documenti ipertestuali si chiama layout, diventa un webmaster o lo chiamiamo designer di layout - un designer di layout. Dopo la strutturazione HTML, il documento, che viene visualizzato, viene salvato in un file, quindi i file HTML sono il tipo principale di risorsa nel World Wide Web. Una volta che il file HTML diventa disponibile per il server web, può essere chiamato pagina web. Le pagine web di composizione costituiscono un sito web.
Ipertesto delle pagine web Iperpotere per aiutare i coristuvaches del Web di tutto il mondo a spostarsi facilmente tra le risorse (file) indipendentemente dal fatto che ci siano risorse su computer locale o su un server distante. Per determinare l'ubicazione delle risorse, All-World Meri ha scelto gli stessi URL di localizzazione delle risorse (ing. Localizzatore di risorse uniforme). Ad esempio, di nuovo URL lato testa La sezione russa di Wikipedia si presenta così: http://ru.wikipedia.org/wiki/Headline_page. Localizzatori URL simili utilizzano la propria tecnologia di identificazione URI (eng. Identificatore di risorsa uniforme"identificatore di risorsa single-simile") e il sistema dei nomi di dominio DNS (ing. Domain Name System). Nome di dominio (a a questo particolare tipo ru.wikipedia.org) all'URL del magazzino indica un computer (più precisamente - una delle interfacce di terze parti), che rappresenta il codice del server web richiesto. URL lato streaming riga di indirizzo browser, volendo che molti browser attuali mostrino solo il nome di dominio del sito di streaming per le promozioni.
All-Sveta Pavutinnya (corto World Wide Web o WWW) - l'unità delle risorse informative, collegate tra loro per mezzo di telecomunicazioni e basate su dati ipertestuali, sparse in tutto il mondo.
La Roccia del Popolo di Pavutini di tutto il mondo è vvazhetsya 1989 r_k. Al destino stesso di Tim Berners-Lee, che ha propagato un progetto ipertestuale congiunto, che ha portato via il nome di All-World's Spider.
Творець «павутини» Тім Бернес-Лі, працюючи в лабораторії фізики елементарних частинок європейського центру ядерних досліджень «CERN» У Женеві (Швейцарія), спільно з партнером Робертом Кайо займалися проблемами застосування ідей гіпертексту для побудови інформаційного середовища, яке спростило б обмін інформацією між фізиками .
Come una sub-bag del robot, diventando un documento, per il quale era possibile capire, avere un significato importante per “pavutini” nel mondo moderno, e si proponevano l'identificatore URI, il protocollo HTTP e il linguaggio dell'HTML . Senza queste tecnologie, non è più possibile rivelare internet attuale.
Berners-Lee ha creato il primo server web al mondo e il primo browser web ipertestuale al mondo. Nella prima pagina del mondo del sito web dei vini, dopo aver descritto cos'è il web All-World, come installare un web server, come hackerare il proprio browser. Questo sito è stato il primo catalogo Internet al mondo.
A partire dal 1994, il destino del leader più globale nello sviluppo dell'All-World's Web è stato assunto dal Consortium of the All-World's Web. World Wide Web Consortium, W3C), quale organizzatore e dossi ocholuє Kim Bernes-Li. Il consorzio sviluppa e promuove standard tecnologici per Internet e il World Wide Web. Mіsіya WZS: "Riscoprirò il potenziale dell'All-World's Pavement attraverso la creazione di protocolli e principi che garantiscono lo sviluppo a lungo termine di Merezhya" . Il W3C distribuisce "Raccomandazioni" al fine di raggiungere la totalità dei prodotti software e delle apparecchiature di varie aziende, al fine di costruire i confini dell'All-World in modo più completo, universale e pratico.
Sistemi Poshukovі: magazzino, funzioni, principi di lavoro.
sistema Poshukov - tutto il complesso software e hardware, incarichi per la ricerca in Internet e per rispondere alla richiesta del koristuvach, che è impostato alla vista della frase di testo (possibile richiesta), il visualizzatore dell'elenco viene inviato alla dzherela delle informazioni , in ordine di rilevanza (a seconda della richiesta). I più grandi sistemi di ricerca internazionali: Google, "Yahoo", "MSN". Per Internet russo - "Yandex", Rambler, "Aporto".
Descrivere principali caratteristiche dei sistemi sonori :
Povnota
La frequenza è una delle caratteristiche principali del sistema per-shook, che consente alla quantità di conoscenza di richiedere documenti a un numero enorme di documenti in Internet, il che soddisfa questa richiesta. Ad esempio, se ci sono 100 pagine su Internet, se riesci a trovare la frase "come scegliere un'auto" e solo 60 di esse sono state trovate per la ricerca, il numero totale di ricerche sarà 0,6. Ovviamente, ciò che è più interessante, è meno ovvio che il koristuvach non conosca il documento richiesto, per la mente, che la colpa si trova su Internet.
Precisione
La precisione è un'altra caratteristica principale di una macchina di ricerca, poiché è determinata dall'affidabilità mondiale dei documenti trovati sulla base del codice. Ad esempio, se dietro la richiesta “come scegliere un'auto” ci sono 100 documenti, 50 di essi riportano la frase “come scegliere un'auto”, e in altri ci sono solo poche parole (“come scegliere un nastro radiofonico registratore correttamente e installarlo in un'auto"), quindi l'accuratezza della ricerca è importante 50/100 (=0,5). Più accurata è la ricerca, più smaliziati avrai bisogno di conoscere i documenti, meno "smite" nel mezzo di essi sarà cesellato, più i documenti familiari non saranno validi per la richiesta.
Rilevanza
Rilevanza - non meno importante ricerca di magazzino, che è caratterizzata da un'ora, che passa dal momento della pubblicazione dei documenti su Internet, fino al loro inserimento nella base dell'indice del sistema di ricerca. Ad esempio, il giorno successivo, dopo la comparsa di nuove notizie, un gran numero di coristuvach è tornato ai sistemi di ricerca con voucher. Oggettivamente, dalla pubblicazione delle notizie sull'argomento, si sono registrati meno doby, e i principali documenti erano già indicizzati e disponibili per la ricerca, e i grandi sistemi di ricerca della cosiddetta “base svedese”, in quanto aggiornati una volta giorno.
Scherzo shvidkista
Shvidkіst pohuku strettamente legato allo yoga stіykіstyu al navantage. Ad esempio, per i dati di "Rambler Internet Holding" LLC, in questo giorno di lavoro, sono necessarie circa 60 richieste al secondo per la macchina di ricerca Rambler. Tale interesse richiederà poco tempo per elaborare il denaro. Qui funzionano gli interessi del coristuvacha e del sistema poshukovoi: è necessario prendere i risultati del più ovvio e la macchina poshukov è responsabile del riempimento del conto il più rapidamente possibile, in modo da non manomettere il calcolo del richieste imminenti.
Precisione
L'accuratezza dei risultati ottenuti è una componente importante di una buona ricerca. Per più zapitiv, la macchina Poshukov conosce centinaia o addirittura migliaia di documenti. A causa della vaghezza dell'ordine della bevanda, o delle imprecisioni della ricerca, ricorda i primi lati della visuale, non chiedere ulteriori informazioni. Tse significa che i koristuvachev devono spesso controllare la ricerca delle autorità nel mezzo dell'elenco dei trovati. Diversi elementi del lato motore di ricerca del sistema di ricerca aiutano a orientarsi nei risultati di ricerca. http://help.yandex.ru/search/?id=481937.
Una breve storia dello sviluppo dei sistemi poke
Durante il primo periodo, lo sviluppo di Internet, il numero di yogi coristuvach era piccolo e la quantità di informazioni disponibili era relativamente piccola. Il miglior accesso a Internet è inferiore a quello degli specialisti della sfera scientifica e scientifica. A quell'ora, la ricerca di informazioni su Internet non era così rilevante come a quest'ora.
Uno dei primi modi per organizzare l'accesso alle risorse informative sul territorio è stata la creazione di cataloghi critici dei siti, affiggendo le risorse in cui sono raggruppati per argomento. Il primo di questi progetti è stato Yahoo.com, iniziato nel 1994. Poiché il numero di siti nel catalogo di Yahoo è notevolmente aumentato, è stato possibile cercare le informazioni richieste dal catalogo. Sensitse aveva ancora un sistema poshuk, ma l'area di oskelka poshuk era circondata solo dalle risorse presenti in catalosi e non da tutte le risorse Internet.
I cataloghi Posilan sono stati ampiamente promossi in precedenza, ma hanno praticamente perso la loro popolarità in passato. Quindi, come creare cataloghi moderni e fantastici per il tuo bene, per vendicare informazioni solo su una piccola parte di Internet. La più grande directory DMOZ (chiamata anche Open Directory Project) contiene informazioni su circa 5 milioni di risorse, proprio come il database del sistema dei motori di ricerca di Google è composto da oltre 8 milioni di documenti.
Il progetto WebCrawler è diventato il primo sistema di poke a tutti gli effetti, amico del 1994.
Nel 1995 sono comparsi i sistemi di rilevamento di Lycos e AltaVista. Il resto dell'anno è stato il leader nel campo della ricerca di informazioni in Internet.
Nel 1997, Sergey Brin e Larry Page hanno creato la macchina di ricerca di Google come parte di un successivo progetto presso la Stanford University. A momento presente Google è il sistema di spoofing più popolare al mondo!
Nella primavera del 1997 è stato ufficialmente annunciato il sistema Poshukov Yandex, che è il più popolare su Internet russo.
Oggi vengono sviluppati tre principali sistemi di ricerca internazionali: Google, Yahoo e MSN, che si basano su algoritmi di ricerca. La maggior parte degli altri sistemi per-sound (ce ne sono un gran numero) vince i risultati di tre trasferimenti. Ad esempio, la ricerca di AOL (search.aol.com) è la base di ricerca di Google e AltaVista, Lycos e AllTheWeb è la base di Yahoo.
Magazzino e sistema robotico principale
In Russia, il sistema di ricerca principale è Yandex, inoltre - Rambler.ru, Google.ru, Aport.ru, Mail.ru. Inoltre, allo stesso tempo, Mail.ru vince il meccanismo e il database di ricerca Yandex.
Possano tutti i grandi sistemi di ricerca creare una buona struttura, anche in questo caso. Tuttavia, è possibile vedere i componenti principali di tutte le granigliatrici. Le distinzioni della struttura possono essere minori in termini di attuazione dei meccanismi di interazione tra queste componenti.
Modulo di indicizzazione
Il modulo di indicizzazione è composto da tre programmi aggiuntivi (robot):
Ragno (ragno) - un programma riconosciuto per siti web coinvolgenti. "Pavuk" garantisce la sicurezza del lato e vince tutte le forze interne dal lato. Viene acquisito il codice HTML del lato skin. Per catturare i lati del robot, usa i protocolli HTTP. Pratica "ragno" in questo modo. Il robot invia "get/percorso/documento" e altri comandi alla richiesta HTTP al server. Il robot sottrae il flusso di testo all'invio, che vendicherà le informazioni di servizio e il documento stesso.
URL laterale
data, se la parte è stata rilevata
http-header della vista del server
corpo laterale (codice html)
Crawler (ragno "mandrivny") - un programma che segue automaticamente tutti i messaggi conosciuti a lato. Vedo tutti i messaggi a lato. Yogo zavdannya - indica dove può andare lontano il ragno, a spirale sul messaggio o lasciando l'indirizzo dalla lista data. Il crawler, seguendo i messaggi conosciuti, ricerca nuovi documenti non ancora conosciuti dal sistema di ricerca.
Indicizzatore (indicizzatore robot) - un programma che analizza le pagine web occupate dagli spider. L'indicizzatore ordina il lato del magazzino e li analizza, algoritmi lessicali e morfologici zastosovuyuchi. Analizza diversi elementi della pagina, come testo, intestazioni, caratteristiche strutturali e di stile, servizi speciali, tag html, ecc.
In questo modo, il modulo di indicizzazione consente di aggirare l'assegnazione di risorse impersonali, sfruttare le pagine che vengono indicizzate, sfruttare le nuove pagine dei documenti di contenuto e condurre una nuova analisi di questi documenti.
Banca dati
Il data base, o l'indice del sistema di ricerca, è il sistema di raccolta dei dati, l'array di informazioni, da cui vengono salvati i parametri di tutte le acquisizioni ed elaborate dal modulo di indicizzazione dei documenti tramite un'apposita procedura.
server Poshuk
Il server poshukovy è l'elemento più importante del sistema del sistema, a causa degli algoritmi che stanno alla base del suo funzionamento, senza intermediari giacciono la qualità e la velocità dello scherzo.
Il poke server funziona in un ordine offensivo:
La rimozione del tipo di coristuvach richiede la conoscenza dell'analisi morfologica. Le informazioni vengono generate sul documento skin, che viene archiviato nel database informazioni di testo oltre a vedere i risultati della ricerca.
I dati rimossi vengono passati come parametri di input a un modulo di classificazione speciale. Viene effettuato il trattamento dei dati per tutti i documenti, dopodiché viene assegnato il rating autorevole per il documento skin, che caratterizza la rilevanza dei dati inseriti dal corrispondente, e gli altri documenti di magazzino che vengono salvati nell'indice del sistema di ricerca.
Maggese nella scelta di un koristuvach, la cui valutazione può essere corretta da menti aggiuntive (ad esempio, i titoli di "estensioni delle ricerche").
Successivamente, viene generato uno snippet, in modo che per il documento trovato skin dalla tabella dei documenti, il titolo, una breve istruzione, le informazioni più importanti e la richiesta per il documento stesso e le parole trovate siano abbinate.
I risultati della ricerca sui prelievi vengono trasmessi come SERP (Search Engine Result Page) - una vista laterale dei risultati dei motori di ricerca.
Come puoi vedere, tutti questi componenti sono strettamente correlati uno a uno e lavorano insieme, rendendo possibile completare con precisione il meccanismo di piegatura del sistema robotico, il che significa una grande quantità di risorse.
Il sistema Poshukov non accumula tutte le risorse di Internet.
Il sistema skin-poor raccoglie informazioni sulle risorse di Internet, utilizzando i propri metodi unici e formando una base di dati che viene periodicamente aggiornata. L'accesso al centro della base è auspicato da Koristuvachev.
I sistemi di ricerca implementano due modi per cercare una risorsa:
Cerca tematico cataloghi - informazioni appare come una struttura gerarchica. Al livello superiore - categorie globali ("Internet", "Business", "Ministero", "Istruzione", ecc.), Al livello offensivo, le categorie sono divise in distribuzioni, ecc. Il prezzo più basso viene inviato a siti Web specifici o altre risorse informative.
Ricerca per parole chiave (ricerca per indice o ricerca dettagliata) - koristuvach prevale sul sistema di ricerca Chiedi, Cosa è composto da parole chiave. Sistema giro koristuvachevі trasferimento di conoscenze per la richiesta di risorse.
Più sistemi poshukovyh insulti poednuyut e modi per poshuk.
I sistemi Poshukovі possono essere locali, globali, regionali e speciali.
La parte russa di Internet (Runet) ha i sistemi di ricerca più popolari al momento Rambler (www.rambler.ru), Yandex (www.yandex.ru), Aport (www.aport.ru), Google (www.google .ru).
La maggior parte dei sistemi di pokeimplementato guardando i portali.
Portale (tipo ing.)portale- ingresso di testa, cancello) è un sito web che integra vari servizi di Internet: ottenere una ricerca, posta, notizie, dizionari, ecc.
I portali possono essere specializzati (come,www. Museo. it) che appariscente (per esempio,www. km. it).
Cerca parole chiave
Un insieme di parole chiave, per le quali esiste una ricerca, chiamano il criterio della ricerca o l'argomento della ricerca.
La richiesta può essere piegata come da una parola, e dalle stesse parole, unite da operatori - simboli, che il sistema designa, in quanto è necessario per produrla. Ad esempio: chiedi a "Mosca Peter" di vendicare l'operatore I (è così che viene preso), che indica che sono richiesti documenti, in cui ci sono parole offensive: Mosca e Peter.
Affinché la ricerca sia pertinente (in inglese rilevante - pre-rivoluzionaria, cosa dovrebbe essere fatto correttamente), è necessario correggere le seguenti regole:
Indipendentemente da cosa, quale forma è stata impiantata nella parola, cerca il vrakhovuє tutte le forme di parole yogo secondo le regole del russo. Ad esempio, dopo la richiesta "scontrino" si troveranno le parole "scontrino", "scontrino", ecc.
Le grandi lettere dovrebbero essere celebrate solo con buoni nomi, per non guardare oltre le lettere della lettera. Ad esempio, i documenti si troveranno dietro la richiesta di "kovalіv", dove ci sono anche su kovalіv e sui Kuznetsov.
Bazhano suona come uno scherzo, spratto vicario di parole chiave.
Non c'è bisogno di un indirizzo tra i primi venti indirizzi conosciuti, poi cambia la richiesta.
Il sistema di Leather Poshukov vikoristovuє la tua lingua di zapitіv. Per conoscerlo, salutati con la messa a punto avanzata del sistema poshuk
Grandi siti possono costruire sistemi per cercare informazioni tra i loro siti web.
Iniziare uno scherzo in sistemi simili, di regola, seguirà le stesse regole, che sono le stesse per i sistemi di scherzo globali, non saremo in grado di conoscere la prova qui.
Estensioni Poshook
I sistemi Poshukovі possono premere il meccanismo di koristuvach, che consente di formare richieste di piegatura. Attraversando per chiedere aiuto Estensioni Poshook dà la possibilità di modificare i parametri della ricerca, specificare parametri aggiuntivi e scegliere il modulo più conveniente per visualizzare i risultati della ricerca. Di seguito vengono descritti i parametri che possono essere impostati per una ricerca estesa nei sistemi Yanxex e Rambler.
|
Descrizione del parametro |
Nome in Yandex |
Nome dentroRambler |
|
De Shukati parole chiave(titolo del documento, solo corpo del testo) |
Filtro di parole |
Cerca testo... |
|
Come le parole sono colpevoli o non colpevoli ma sono presenti nel documento e quanto possono essere accurate |
Filtro di parole |
Shukati parole da chiedere ... Accendi i documenti, come per vendicare le parole in arrivo ... |
|
Allo stesso tempo, un tipo è responsabile delle parole chiave roztashovuvatisya |
Filtro di parole |
Le parole di Vіdstan mi chiedono ... |
|
Cambio alla data del documento |
Data del documento... |
|
|
Scambia la ricerca tra uno o più siti |
Sito/Inizio |
Shukati documenta meno sui prossimi siti... |
|
Cerca un documento di film |
Documento in lingua... |
|
|
Ricerca di documenti, cosa posso fare con la foto con il nome della canzone o con una firma |
Immagine | |
|
Ricerca laterale, cosa vendicare gli oggetti |
Oggetti speciali | |
|
Il modulo per presentare i risultati di una ricerca |
Formato visualizzatore |
Visualizzazione dei risultati della ricerca |
I sistemi di ricerca attivi (ad esempio Yandex) ti consentono di entrare in acqua con il linguaggio naturale. Scrivi quello che devi sapere (ad esempio: acquistare i biglietti per un treno da Mosca a San Pietroburgo). Il sistema analizza e vede il risultato. Se non hai potere laggiù, vai alla lingua del bere.
È facile inviare il tuo harn al robot alle basi. Forma Vikoristovy, raztastovanu sotto
Studenti, dottorandi, giovani adulti, come la base vittoriosa della conoscenza nei loro robot addestrati, saranno i tuoi migliori amici.
Documenti simili
Fondamenti teorici delle tecnologie Internet e dei servizi di base di Internet. Familiarizzare con le possibilità di connessione a Internet. I principali servizi della città. Principi di ricerca di informazioni dal WWW. Una panoramica degli attuali browser Internet. Programmi per splkuvannya al merezhі.
lavoro corso, donazioni 18/06/2010
Cos'è Internet? Internet come raccolta di informazioni di massa. Servizi di Internet. Stampa Merezheva. struttura Polit.ru. Statistiche. Valutazione. Da cosa è composta Internet? ICQ- nuova opportunità interrogatorio. Dispositivi di amministrazione di Internet.
abstract, integrazioni 10.05.2003
Internet è una rete informativa globale, le sue estensioni, i principali servizi, la storia dell'enologia. Accesso alle informazioni. Server, provider, router. Il concetto di protocolli su Internet. Formattazione HTML Mova. Browser dei programmi. URL del protocollo.
abstract, integrazioni 23.10.2011
Caratteristiche e significato delle tecnologie Internet nell'istruzione contemporanea. La possibilità delle moderne tecnologie Internet è positiva. I principali vantaggi dell'apprendimento elettronico, analisi dei programmi di base, caratteristiche delle tecnologie di telecomunicazione.
lavoro di tesi, donazioni 23/06/2012
Il ruolo e il significato di Internet nella vita della società. Tendenze nello sviluppo di Internet in Russia: problemi e prospettive, caratteristiche della struttura del mercato. Le sfere di servizio realizzano servizi tramite Internet. Collegamento alle tecnologie Internet in ambito socio-culturale.
lavoro corso, donazioni 04.02.2011
Il concetto di "informazione". Interattività. Ricerca informazioni. Internet come principale fonte di ricerca interattiva di informazioni. Storia della creazione di Internet. Accesso ad Internet. Cerca risorse. Tipi poshukovyh sistemi. E-mail.
lavoro corso, donazioni 15.02.2007
I fatti principali della storia di Internet, i principi chiave delle prospettive di ulteriore sviluppo. Sfere moderne di Internet, terra di mezzo russa misura universale(Runet). Vedere i browser per rivedere le pagine web. Gamma di servizi e servizi di Internet.
controllo del robot, integrazioni 25.02.2012
Insieme a. uno
Scuola di Informatica e Informatica
astratto
Sull'argomento: pavutinnya in tutto il mondo.
Il robot è stato picchiato da uno studente 190(1)
Grigor'eva Anastasia
Il lavoro è recensito dall'insegnante Isaeva I.A.
Tallinn 2010
Entrata 3
La struttura e i principi di All-World's Spider 4
Storia dell'All-World's Spider 5
Viaggia lungo il web di tutto il mondo 7
Collegamento dei lati all'ipertesto 8
Prospettive per lo sviluppo di All-World Spider 9
Fig.1.1
La struttura ei principi dell'All-World's Spider
I Web di tutto il mondo sono approvati da milioni di server Web in Internet, sparsi in tutto il mondo. Un server web è un programma che viene eseguito su un computer connesso a una rete e utilizza il protocollo HTTP per trasferire i dati. Nel modo più semplice, un tale programma rimuove la richiesta HTTP alla risorsa, trova il file di origine sul disco rigido locale e lo gestisce sul computer. Server Web più comprimibili e costruzione distribuiscono dinamicamente le risorse in risposta alle richieste HTTP. Per identificare le risorse (per lo più file o parti), gli stessi identificatori di risorse URI (eng. Uniforme risorsa Identificatore). Per determinare l'ubicazione delle risorse in un'azienda, utilizzare l'URL dei localizzatori di risorse a mandato singolo (eng. Uniforme risorsa localizzatore). Quindi i localizzatori URL utilizzeranno la propria tecnologia di identificazione URI e il sistema dei nomi di dominio DNS (eng. dominio Nome Sistema) - nome a dominio (o senza l'indirizzo IP intermedio in notazione numerica) per entrare nell'URL warehouse di identificazione del computer (più precisamente - una delle interfacce di terze parti), che conterrà il codice del web server richiesto.
Per esaminare le informazioni prelevate dal server Web, sul computer del client viene installato un programma speciale: un browser Web. La funzione principale di un browser web è la visualizzazione dell'ipertesto. L'onnipotente ragnatela è indissolubilmente legata ai concetti dell'ipertesto e di quell'iperspazio. La maggior parte delle informazioni su Internet è l'ipertesto stesso. Per facilitare la creazione, il salvataggio e la visualizzazione dell'ipertesto nell'All-World's Web, il linguaggio dell'HTML (eng. ipertesto
markup
linguaggio), layout mov per ipertesto. Il lavoro con layout per ipertesto si chiama layout, il master con layout si chiama webmaster o webmaster (senza trattino). Se l'ipertesto che delinea l'HTML, che vedete, è inserito in un file, tale file HTML è la risorsa più ampia del World Wide Web. Una volta che il file HTML diventa disponibile per il server web, può essere chiamato pagina web. Le pagine web di composizione costituiscono un sito web. L'ipertesto delle pagine web è dotato di iperspazio. Hyper-power aiuta i nativi di All-World's Web a spostarsi facilmente tra le risorse (file) indipendentemente dal fatto che le risorse si trovino sul computer locale o su un server remoto. Internet iperpotente basato sulla tecnologia URL. (2 messaggi)
Storia del ragno di tutto il mondo
Tim Berners-Lee e il mondo minore Robert Cailliau sono rispettati dai colpevoli del ragno di tutto il mondo. Tim Berners-Lee è l'autore delle tecnologie HTTP, URI/URL e HTML. Nel 1980, roci vin pratsyuvav presso l'European Radiation of Nuclear Research (fr. Consiglio europeo per la ricerca nucleare, CERN) consulente Software. Lui stesso lì, vicino a Ginevra (Svizzera), per i bisogni delle autorità, dopo aver scritto il programma Enquirer (ing. « Chiedere informazioni» , puoi tradurlo liberamente come "Diznavach"), come associazione vittoriosa per la raccolta di dati e ha gettato le basi concettuali per Pawutin di All-World.
Nel 1989, lavorando al CERN sulla rete interna dell'organizzazione, Tim Berners-Lee, dopo aver propagato un progetto ipertestuale globale, ora lavora come un Web All-World. Il progetto mira alla pubblicazione di documenti ipertestuali collegati tra loro dall'iperspazio, che semplificherebbero la ricerca e il consolidamento delle informazioni per gli scienziati del CERN. Per l'attuazione del progetto, Tim Berners-Lee (insieme ai suoi assistenti) ha trovato identificatori URI, protocollo HTTP e HTML. Queste tecnologie, senza le quali non è più possibile scoprire l'attuale Internet. Nel periodo dal 1991 al 1993, Rick Berners-Lee ha migliorato le specifiche tecniche di questi standard e li ha pubblicati. Ma lo stesso, il destino ufficiale della gente del Pawutin del mondo intero deve essere vvazhat 1989 r_k.
Nell'ambito del progetto Berners-Lee, ha scritto il primo server web httpd al mondo e il primo browser web ipertestuale al mondo chiamato WorldWideWeb. Questo browser è anche un editor WYSIWYG (versione inglese breve) Che cosa Voi Vedere È Che cosa Voi Ottenere- scho bachish, te y otrimash), yogo rozrobka rozpochato zhovtnі 1990 roku, e completato nel petto tsgo roku. Il programma è stato lanciato nel mezzo di "NeXTStep" e ha iniziato ad espandersi su Internet nel 1991. (2)
Il primo sito web al mondo
P  Dopo aver creato il sito web di Berners-Lee all'indirizzo http://info.cern.ch/, il sito è ora in fase di archiviazione. Questo sito è apparso online su Internet il 6 aprile 1991. In questo sito è stato descritto cos'è il Web All-World, come installare un server Web, come hackerare un browser e così via. siti.
Dopo aver creato il sito web di Berners-Lee all'indirizzo http://info.cern.ch/, il sito è ora in fase di archiviazione. Questo sito è apparso online su Internet il 6 aprile 1991. In questo sito è stato descritto cos'è il Web All-World, come installare un server Web, come hackerare un browser e così via. siti.
e la prima foto di All-World's Web era di un gruppo folk parodia Les Horribles Cernettes. Tim Bernes-Lee ha chiesto al leader del gruppo dopo il CERN Hardronic Festival le loro immagini scansionate. (2)
Viaggia lungo il web di tutto il mondo
Il più semplice è più costoso
La ragnatela tutta luminosa inizia con l'introduzione di qualsiasi indirizzo e-mail di fila
Posizione (luogo di espansione) e dopo aver premuto il pulsante Invio, il sistema ti trasferirà a
luce virtuale. Tecnologicamente, quando il browser installa il
rivnіv storіnok - questo è uno dei principali, da esso - inviato a kіlka
intermedi o altri lati dell'altro uguale, e da loro - ai lati dell'offensiva
pari. Organizzazione lineare trasferendo la visibilità dei lati dello stesso uguale,
spratto di altre parti. І ragnatela є impersonale

Fig.8.1
Prospettive per lo sviluppo dell'All-World Spider
In quest'ora sono emerse due tendenze nello sviluppo del web di All-World: un web semantico e un web sociale.
Il web semantico trasmette la molteplicità dei collegamenti e la rilevanza delle informazioni nel web All-World attraverso l'introduzione di nuovi formati di metadati.
Le ragnatele sociali si basano sul lavoro di ordinare l'ovvio nelle informazioni della ragnatela, che viene consumato dai coristuvac delle ragnatele stesse. Nell'ambito di un altro, direttamente, che fa parte del web semantico, attivamente come strumenti di hacking (RSS e altri formati di canali web, OPML, microformati XHTML). alla sottocategoria, non forniscono alcun supporto per l'ampliamento di tali casi. Se sei interessato, puoi provare la piegatura dell'Atlante della Conoscenza.
 È anche la comprensione più popolare del Web 2.0, che ha un rapporto diretto con lo sviluppo dell'All-World Web. (2)
È anche la comprensione più popolare del Web 2.0, che ha un rapporto diretto con lo sviluppo dell'All-World Web. (2)
9.1
Modi di fermentazione attiva di informazioni in All-World's Spider
Le informazioni su Internet possono essere visualizzate sia passivamente (in modo che il koristuvach possa leggere di meno), sia così attivamente: lo stesso koristuvach può aggiungere informazioni e rimodulare її. Prima che i metodi di fermentazione attiva delle informazioni nel pavone di All-World siano:
libri degli ospiti,
forum,
loquace,
blog,
progetti wiki,
servizi sociali,
sistema di gestione dei contenuti. (2)

Fig.10.1
Visnovok
Per rahunok perevag in presenza dell'ipertesto del World Wide Web, avendo creato uno spazio informativo precedente sconosciuto e un conforto per i corystuvach. Nin praticamente tutti i grandi e medi, e più altre aziende, università, istituzioni, associazioni pubbliche e solo persone enormi in tutto il mondo, hanno il potere dei siti web, sui quali pubblicano informazioni sulle loro attività, danno per il loro aiuto . Lo sviluppo del WWW è già stato sviluppato prima dell'emergere di una nuova professione di webmaster, il compito di creare web-side con un gran numero di effetti grafici, video e audio.
In questo ordine, il web universale o il follemente WWW, nayyaskravisha, a portata di mano che parte di Internet è popolare. Oggi, attraverso i "lati" del WWW, possiamo leggere e-mail, rimuovere l'accesso agli archivi di file, gestire i gruppi di notizie e rimuovere l'anonimato nuova informazione. Per cui dobbiamo inserire l'indirizzo del sito in fila, basta chiedere e premere Invio.
Elenco della letteratura vittoriosa
Leontiev VP Enciclopedia informatica di uno scolaro, OLMA-PRES Osvita, 2005
http://www.wikipedia.org
http://www.cssblok.ru/istori/index2.html
Insieme a. uno
Con lo sviluppo di Internet, il suo fatturato è diventato sempre più diffuso e l'orientamento su Internet è diventato più complicato. Quindi è diventato necessario creare un modo semplice e intelligente per organizzare le informazioni che vengono pubblicate sui nodi Internet. Da questo punto di vista, un nuovo servizio www (world wide web - All-world web) è entrato in contatto con il grande pubblico.
All-world web (world wide web)- l'intero sistema di documenti con testo informazioni grafiche, posizionamenti sui nodi Internet e collegati tra loro da iperpossesso. Forse, il servizio stesso è il più popolare e riccamente corystuvachiv, sinonimo della stessa parola INTERNET. Spesso pochatkіvtsі si allontana da due comprensivi: Internet e WWW (abo Web). Immaginiamo che WWW sia solo uno dei numerosi servizi (servizi) su cui fanno affidamento le persone esperte di Internet.
L'idea principale, come una vikoristan bula per lo sviluppo del sistema www, L'idea di accedere alle informazioni per ulteriori messaggi ipertestuali. L'essenza di її polagaє ha incluso nel testo del documento l'invio di altri documenti, yakі può roztashovuvatisya come nello stesso e su altri server di informazioni.
Istorіya www è in quel momento, se nel 1989, il Rotsi SPIVROTHKOMACHOKOCARYARYARYACAI CERN Berners-Li, che doveva essere immagazzinato nella Vihoghformation del Merezhny, fosse stato rubato dallo Yaku e il sama sama, quindi Tali documenti non sono altro che ipertesti.
Un'altra possibilità, yak vygіdno vіdіznyaє www vіd іnshih vidіv servіsu, polyagaє infatti, attraverso questo sistema puoi praticamente accedere a tutti gli altri tipi di servizi Internet, come FTP, Gopher, Telnet.
WWW є sistema multimediale. Tse significa che per aiuto www puoi, ad esempio, guardare un video su rievocazioni storiche o scoprire informazioni sul campionato del mondo di calcio. Possibilità di accesso alle informazioni della biblioteca ea fotografie fresche del cortile terrestre, cinque volte di più di quelle dei compagni meteorologici, subito s.
L'idea di organizzare le informazioni come l'ipertesto non è nuova. L'ipertesto è "vivo" molto prima dell'avvento dei computer. L'esempio più semplice di ipertesto non informatico è l'enciclopedia dei prezzi. Le parole effettive negli articoli sono indicate in corsivo. Ciò significa che puoi rivolgerti allo statuto pertinente e rimuovere le informazioni del rapporto. E proprio come in un ipertesto non informatico devi avere una manciata di lati, quindi sullo schermo del monitor andrai a cercare i messaggi degli hypertext mittievs. È meglio fare clic con il mouse sulle parole inviate.
Il merito principale del già concepito visionario Tim Berners-Lee è che non ha appeso fuori l'idea della creazione sistema informativo sulla base di ipertesto, ale e proponuvav una serie di metodi che hanno costituito la base del futuro servizio www.
Nel 1991, le idee che hanno avuto origine al CERN hanno iniziato a sviluppare attivamente il Center for Supercomputer Appliances (NCSA). La stessa NCSA crea documenti ipertestuali mov html, così come il programma Mosaic, è riconosciuto per la revisione. Mosaic, sviluppato da Mark Andersen, è diventato il primo browser a lanciare una nuova classe di prodotti software.
Nel 1994, il numero di www-server ha cominciato a crescere rapidamente e un nuovo servizio Internet, in quanto porta via la luce della conoscenza, e il numero di nuovi coristuvachivs sale su Internet.
Ora la signora dell'appuntamento principale.
www- Tse web-side anonime, ospitate sui nodi Internet e collegate tra loro da iper-poteri (o semplicemente da power-up).
lato web- la stessa unità strutturale www, in quanto comprende tutte le informazioni (testuali e grafiche) che vengono inviate all'altro lato.
sito web- Tutti i siti Web che si trovano fisicamente su un sito Internet.
Il sistema di hyperposilan www si basa sul fatto che le viste di un documento di un documento (che possono essere parti di un testo o un'illustrazione) agiscono come una forza su altri documenti, ad essi logicamente correlati.
Per chi hai documenti, dove lavorare sodo, puoi essere come uno locale e così via computer remoto. Inoltre, è possibile e tradizionali messaggi ipertestuali - tse messaggio nel mezzo dello stesso documento.
I documenti, sulla base dei quali sono stati installati, possono, a propria discrezione, incrociare la forza dell'una e dell'altra risorse informative. In questo grado, puoi raccogliere in uno spazio informativo documenti su argomenti simili. (Ad esempio, documenti che trattano informazioni da medicinali.)
Architettura www
L'architettura del www, così come l'architettura della ricchezza di altri tipi di servizi Internet, è stata ispirata dal principio client-server.
Compiti principali del programma serverє organizzazione dell'accesso alle informazioni salvate sul computer su cui è in esecuzione il programma. Dopo l'avvio del server del programma, funziona nella modalità di acquisizione delle richieste dai client del programma. Sembra che i browser web agiscano come client di programma, che vengono utilizzati da un certo numero di www koristuvachs. Se un tale programma ha bisogno di rimuovere informazioni dal server (richiamare tutti i documenti che sono salvati lì), invierà una richiesta al server. Con sufficienti diritti di accesso tra i programmi, viene stabilita una richiesta e il programma server invia una richiesta al programma client. Dopo ciò che è stato installato tra di loro, si apre la giornata.
Per la trasmissione tra programmi viene utilizzato il protocollo HTTP (Hypertext Transfer Protocol, Hypertext Transfer Protocol).
www-funzioni del server
server www- Questo è il programma che viene eseguito sul computer host ed elabora le richieste disponibili da www-clients. Quando annulli la richiesta dal www-client, il programma stabilirà una connessione basata sul protocollo di trasporto TCP/IP e scambierà informazioni per protocollo HTTP. Okrim tsgogo server vyznaє diritti di accesso ai documenti, yakі su nyu lo sai.
Per l'accesso a informazioni che non possono essere elaborate dal server senza intermediari, vinci sistema di gateway. Utilizzando una speciale interfaccia CGI (Common Gateway Interface, Global Gateway Interface) per lo scambio di informazioni con i gateway, il server www potrebbe essere in grado di ricevere informazioni dal server, che sarebbero inaccessibili ad altri tipi di servizi Internet. Con chi, per kіntsevogo koristuvach, il robot dei gateway di "clearance", in modo che, guardando le risorse web nel tuo browser preferito, non dovresti ricordare la mancanza di informazioni che le informazioni ti sono state presentate per l'assistenza del sistema di gateway
www-funzioni client
Puoi vedere due tipi principali di client www: browser web e utilità.
browser web vykoristovuyutsya per besperednoy lavora da www e otrimannya zvіdti іinformatsії.
Servizi aggiuntivi Web può comunicare con il server, sia per recuperare alcuni dati statistici, sia per indicizzare le informazioni ivi memorizzate. (Allo stesso modo, porto le informazioni nei database dei database dei sistemi di poke.) Krym tsgogo, oltre all'uso dei servizi di client web, il robot di qualche tipo è collegato al lato tecnico della raccolta di informazioni su questo server.