İnternet arama sistemleri: Yandex, Google, Rambler, Yahoo. Depo, fonksiyonları, çalışma prensibi. Arama sistemi tam olarak ne yapar? 1 Ses sistemi hakkında kısaca anlaşılması gerekenler
Merhaba blog sitesinin sevgili okuyucuları. Hem profesyonel düzeyde (bir kuruş karşılığında ticari projeler satmak) hem de amatör düzeyde () görünüşte sağlam bir optimizasyonla uğraşıyorsanız, kesinlikle bununla başa çıkacaksınız ki bu gerekli. kendilerinin veya bir başkasının sitesini başarılı bir şekilde optimize etmek için genel olarak çalışma ilkeleri.
Görünüşe göre düşmanların şahsen bilinmesi gerekiyor, ancak elbette pis kokular (RuNet ve Yandex i için) bizim için hiç de düşman değil, daha çok ortaktır, çünkü trafiğin bir kısmı çoğu durumda baskın ve ana olan. Ve elbette suçlama ve kokuşma artık bu kuralı doğrulamıyor.
Su çulluğu nedir ve ses sistemlerinin çalışma prensipleri
Ancak burada hemen başlamanız gerekecek ve hala ihtiyaç duyulan çulluk nedir ve optimize edici için neden bu kadar önemlidir? Aramanın sonuçları, aramaya gönderilen belgenin hemen ardından görüntülenir (metni önceden yazılmış olduğundan alınmıştır):
Bu belgenin vikoristovuyutsya zazvichiy shmatki metni nasıl. Tıklamak için ideal seçenek, yazara o tarafa gitmek yerine o taraf hakkında düşünme fırsatı vermektir (aksi takdirde onu bir kenara koyarız, ancak bir daha değil).
Parçacık otomatik olarak oluşturulur ve metnin tüm parçaları yeni sürümde vurgulanır ve daha da önemlisi, aynı web sayfasındaki farklı sorgular için farklı parçacıklar olur.
Açıklama etiketinin kendisi yerine (özellikle Google'da) snippet olarak aranabileceği de doğrudur. Tabii ki hala bayat ve bu yüzden bir tür damar şeklinde ortaya çıkıyor.
Örneğin, Açıklama etiketi yerine, örneğin anahtar kelimeleri ararken, açıklamaya girdiğiniz kelimeleri veya algoritmanın kendisi henüz metninizdeki metin parçalarını bilmiyorsa, sonunda görüntüleyebilirsiniz. sayfanızda eksik olan tüm anahtar kelimeler için Google'da Yandex'i görüyorum.
Bu nedenle lütfen silmeyin ve dış görünüm durumu için Açıklama etiketi yerine onu unutmayın. Açıklamaları vikorize ederek WordPress ile para kazanabilirsiniz (ve vikorist olmanızı öneririm).
Eğer Jumli hayranıysanız bu materyalin keyfini hızla çıkarabilirsiniz.
Ale Snippet'i dönüş dizininden kaldırılamaz çünkü Burada sadece sayfadaki kelimelere ve bunların metin içindeki konumlarına ilişkin bilgiler kaydedilir. Farklı arama motorlarında (farklı sorgular için) aynı belgenin parçacıklarını oluşturmaya yönelik eksenin kendisi, dönüş dizinine ek olarak (doğrudan arama için gereklidir - aşağıda okuyun), favori Yandex ve Google'ımızdır. doğrudan indeks, Daha sonra. web sayfasının bir kopyası.
Belgenin bir kopyasını temel olarak kaydederek, orijinali değiştirmeden gerekli parçacıkları manuel olarak kesebilirsiniz.
O. Arama motorlarının web sayfasının hem ileri hem de geri dizinini veritabanlarında sakladığı ortaya çıktı. Konuşmadan önce, parçacıkların oluşturulması dolaylı olarak entegre edilebilir ve web hikayesinin metni, algoritmanın aklınızdaki metnin aynı parçasını seçeceği şekilde optimize edilebilir. Bunu başka bir yazımızda konuşacağız.
Arama sistemleri nasıl çalıştırılır
Optimizasyonun özü, arama motoru algoritmalarının, ziyaret ettiğiniz sitelerin sayfalarını bu ve diğer sorgular açısından mümkün olan en yüksek konuma yükseltmesine “yardımcı olmaktır”.
"Yardım" kelimesini pençeden ileri önermeden aldım çünkü Optimizasyon eylemlerimizle tamamen yardımcı olmuyoruz, ancak görünümle ilgili bir sorgu (bilmeceler hakkında) oluşturmak için çoğunlukla algoritmaya büyük ölçüde güveniyoruz.
Bu, optimize edicilerin ekmeği ve tereyağıdır ve arama algoritmaları kapsamlı olmayacaktır, bu nedenle, Yandex ve Google'daki konumlarını iyileştirmek için dahili ve harici optimizasyon kullanma olasılığı vardır.
Öncelikle optimizasyon yöntemlerini öğrenmeye geçelim, gelecekte yapılacak tüm çalışmaların bilinçli ve anlaşılır olması için ses sistemlerinin çalışma prensiplerini iyice anlamak gerekir. çok az tepki verdi.
Temel prensipleri yeterince anlamadığımız sürece, açıklanacak yeterli bilgi olmadığından, çalışmalarının tüm mantığını anlamamızın imkansız olduğu açıktır. Hadi bakalım.
Ses sistemleri nasıl çalışır? Şaşırtıcı değil ama çalışmalarının mantığı prensip olarak aynı ve ön plana çıkıyor: Ulaşılabilen, ulaşılabilen tüm web sayfaları hakkında bilgi toplanır, ardından kurnaz bilgelikten gelen bu veriler bir web sitesinde toplanır. bunları kolayca kullanabilmek için bir arama yapın. Eksen, lord ve bu makaledeki her şey tamamlanmış sayılabilir, ancak yine de biraz ayrıntı ekleyin.
Öncelikle sitenin tarafı dediğimiz şeye belge dendiğini açıklığa kavuşturalım. Bu durumda, benzersiz adresinizden () siz sorumlusunuz ve özellikle karma mesajı, yeni bir belge (bunlar hakkında) görünene kadar oluşturulmaz.
Başka bir şekilde, toplanan bir belge veritabanından bilgi aramak için algoritmalara (yöntemlere) odaklanmalısınız.
Doğrudan ve ters indeksler için algoritmalar
Açıkçası, veritabanında saklanan tüm sayfaları basitçe numaralandırma yöntemi optimal olmayacaktır. Bu yönteme algoritma denir doğrudan arama Ve bu yöntem elbette önemli hiçbir şeyi kaçırmadan gerekli bilgileri bulmanıza izin vermesine rağmen, büyük miktarda veriyle çalışmak kesinlikle uygun değildir çünkü arama oldukça bir saat sürecektir.
Bu nedenle, büyük veri çabasıyla verimli çalışma için, ters (ters çevrilmiş) endekslerin bir algoritması geliştirildi. Ve önemli olan dünyadaki tüm harika ses sistemlerine karşı kendisinin galip gelmesidir. Bu nedenle bir sonraki raporumuzda bu çalışmanın ilkelerine bir göz atalım.
Algoritmayı kullanırken getiri endeksleriİçlerinde bulunan tüm kelimelerin bir listesini oluşturmak için belgeleri metin dosyalarından dönüştürmek gerekir.
Bu tür listelerdeki (indeks dosyaları) kelimeler alfabetik sıraya göre düzenlenir ve her birinin sırası, kelimenin bulunduğu web sayfasındaki konum koordinatları görünümünde gösterilir. Her kelimenin belge konumu çevresinde, değerini gösteren diğer parametreler belirtilir.
Tahmin edebileceğiniz gibi birçok kitapta (çoğunlukla teknik veya bilimsel) geri kalan sayfalarda, bu kitapta yer alan kelimelerin belirlenmiş sayfa numaralarından daraltılmış bir listesi bulunmaktadır. Tabii ki, bu liste kitapta yer alan tüm kelimeleri içermez, ancak ek ters çevrilmiş dizinlerin kullanıldığı dizin dosyası için bir örnek olarak hizmet edebilir.
Arama motorlarının bilgi aramasına duyduğunuz saygıyı takdir ediyorum internette değil ve sağladıkları web sitelerinin getiri endeksleri. İsteme ve doğrudan dizinler (orijinal metin) kokuları da kaydedilir, çünkü Bu, pasajlar yazmak için faydalıdır, ancak bu yayının başında bundan zaten bahsetmiştik.
Dönüş indekslerinin algoritması vikoryst sistemleri tarafından kullanılır, çünkü Bu, süreci hızlandırmanıza olanak tanır, aksi takdirde belgenin indeks dosyasına dönüştürülmesi sürecinde kaçınılmaz olarak bilgi kaybı yaşanacaktır. Dönüş dizini dosyalarını kaydetmeyi kolaylaştırmak için bunları sıkıştırmak için kurnaz bir yöntem kullanın.
Sıralama için kullanılan matematiksel bir model.
Portal dizinlerini aramak için, gerekli web sitelerini belirleme sürecini (bir sorgu girerek) ve bulunan tüm belgelerin bu sorguyla ilgisini belirleme sürecini basitleştirmeyi mümkün kılan bir matematiksel model geliştirildi. Belirli bir sorguyla ne kadar çok kanıt tutarlı olursa (ne kadar alakalı olursa), sağlam olarak bulunma olasılığı da o kadar artar.
Bu, matematiksel modelin temel aldığı ana görevin, bu sorguyla ilgili portal dizinleri veritabanındaki sayfaları aramak ve bu sorguyla alaka düzeyini azaltacak şekilde daha fazla sıralamak olduğu anlamına gelir.
Aranan ifade keskinleştirildiğinden, belge bulunursa basit bir mantıksal modelin kullanılması, bu tür web sitelerinin çok sayıda değerli görülmesi nedeniyle bizim için işe yaramayacaktır.
Arama sistemi yalnızca başlığında kelimelerin eksik olduğu tüm web sitelerinin bir listesini sağlamaktan sorumlu değildir. En alakalı belgeler en üstte bulunuyorsa bu listeyi bu forma girebilirsiniz (ilgiye göre sıralayın). Bu görev önemsiz değildir ve bizim açımızdan ideal olamaz.
Konuşmadan önce, formdaki belgeleri sıralamak için bunları ve diğer yöntemleri kullanan optimize ediciler tarafından herhangi bir matematiksel modelin kusurundan da yararlanılır (tabii ki kullandıkları site pahasına). Tüm ses sistemlerinin kullandığı matematiksel model, vektör modeli olarak sınıflandırılır. Belgenin tamamen koristuvach tarafından verildiğine dair bir vikorystvo anlayışı var.
Temel vektör modelinde, belirli bir kelimenin arkasındaki belgenin uzunluğu iki ana parametreye göre hesaplanır: belirli bir kelimenin duyulma sıklığı (TF - terim frekansı) ve bu kelimenin diğer tüm taraflarda ne kadar nadir duyulduğu ka koleksiyonlar (IDF - ters belge sıklığı).
Koleksiyonun altında ses sistemine dahil olan sayfaların tamamı yer almaktadır. İki parametreyi birer birer çarparak belgenin değerini yazılı göreve çıkarıyoruz.
Doğal olarak, TF ve IDF parametrelerine ek olarak, sesin genişlemesi için herhangi bir önemli faktör olmaksızın farklı ses sistemleri kullanılır, ancak özü değişmeden kalır: tarafın değeri daha büyük olacaktır, kelime ne kadar sık \u200b\u200b içindeki ses notasının keskinleştirilmesi (şarkıdan önce, sonra hangi belgenin spam olarak algılanabileceği) ve bu kelimenin bu sistem tarafından indekslenen diğer belgelerde ne kadar erken göründüğü.
Robotik formülün maliyetinin değerlendiriciler tarafından değerlendirilmesi
Böylece bu ve diğer sorgular için veri oluşumunun gerçekleştiği ortaya çıkıyor Formülü takip edeceğim insan katılımı olmadan. Herhangi bir formül özellikle başlangıçta mükemmel çalışmıyorsa, matematiksel modelin işleyişini kontrol etmeniz gerekecektir.
Bu amaçlar doğrultusunda, çeşitli sorgular için verilere (özellikle onları işe alan arama sistemlerine) bakmak ve akış formülünün doğruluğunu değerlendirmek için özel eğitimli kişiler kullanılır.
Hepsi modelin ayarlanmasından sorumlu kişiler tarafından saygıyla destekleniyor. Formülde değişiklik ve eklemeler yapılır ve bunun sonucunda sirenin verimliliği artar. Değerlendiricilerin, algoritmanın geliştiricileri ile sarılığın gerekli bir iyileştirmesi olan koristuvachamileri arasında böyle bir tür ağ geçidi bağlantısının rolü sonucuna vardıkları ortaya çıktı.
Robot formülünün verimliliğini değerlendirmenin ana kriterleri şunlardır:
- Ses sisteminin doğruluğu yüzlerce ilgili belgedir (talebe karşılık gelir). Ne kadar az web sayfası (örneğin, kapı aralıkları) olursa olsun, bu sorularla uğraşmazsınız, orada olmanız daha iyi olacaktır.
- Ses türünün eksiksizliği, koleksiyonun tamamındaki ilgili belgelerin toplam sayısına benzer sorgu (ilgili) web sitelerinin sayısının yüksek olmasıdır. Tobto. Belirli bir sorguya karşılık gelen web sayfalarını arayan tüm belge veritabanının aşağıda arama formunda gösterileceği ortaya çıktı. Bu durumda görünümün tutarsızlığından bahsedebiliriz. İlgili sayfalardan bazılarının filtre altında kaybolması ve örneğin kir veya başka cürufla karıştırılması mümkündür.
- Görünümün alaka düzeyi, İnternet'teki bir sitedeki gerçek bir web sayfasının, arama sonuçlarında kendisi hakkında yazılanlarla alaka düzeyidir. Örneğin, belge artık oluşturulmayabilir veya büyük ölçüde değişecektir, ancak verilen sorgunun türü, belirtilen adresteki fiziksel varlığına veya kimin verilen sorgudan tamamen farklı olduğuna bakılmaksızın mevcut olacaktır. İlgililik, arama robotlarının koleksiyonlarındaki belgeleri tarama sıklığında yatmaktadır.
Yandex ve Google koleksiyonlarını nasıl topluyor?
Web sayfalarını dizine eklemenin basitliğine rağmen (ki öyle görünüyor), kendi sitenizi veya diğer sitelerinizi optimize ederken (SEO) bilmeniz ve kullanmanız gereken birçok nüans vardır. Bir veritabanının indekslenmesi (koleksiyon koleksiyonu), arama robotu (bot) adı verilen özel olarak tasarlanmış bir program tarafından gerçekleştirilir.
Robot, bu sayfaların çıkarılmasından, kopyalanmasından ve daha sonraki işlemler için algoritmaya verilmesinden sorumlu olacağı ilk adres listesini seçer (bunları dönüş dizinlerine dönüştürür).
Robot sadece bu listenin arkasına gitmekle kalmıyor, aynı zamanda bu sayfalardaki mesajlara da giderek bu mesajların arkasında yer alan dokümanları da indeksleyebiliyor. O. Robot, emirlere uymak zorunda olan bir başbakan gibi davranıyor.
Ek bir robotun yardımıyla, sörf için bir tarayıcı olan kullanıcının kullanabileceği her şeyi indeksleyebileceğiniz ortaya çıktı (arama motorları, herhangi bir İnternet kullanıcısı tarafından erişilebilen doğrudan görünürlük belgelerini indeksler).
Belgelerin sınırda indekslenmesiyle ilgili çok az özellik vardır (daha önce tartıştığımız şeyi hatırlıyorum).
Dikkate alınabilecek ilk özellik, zaman zaman içe aktarılan orijinal belgeden oluşturulan dönüş dizinine ek olarak, ses sisteminin başka bir kopyayı kaydetmesidir, aksi takdirde, görünüşe göre ses sistemleri başka bir doğrudan Dizini kaydeder. İhtiyaç duyulan şey? Girilen sorguya göre farklı snippet'ler oluşturmak için neye ihtiyaç duyulacağını biraz önce tahmin etmiştim.
Yandex'in formda ve indekslerde bir sitenin kaç sayfası gösterdiği
Belirli bir istek için her sitede birden fazla belgenin bulunması gibi, Yandex'in çalışmalarının böylesine özel bir özelliğine saygınızı ifade etmek isterim. Bir türün tek bir kaynaktan iki tarafta farklı konumlarda bulunması yakın zamana kadar gerçekleşemezdi.
Bu Yandex'in temel kurallarından biridir. Bir sitede belirli bir sorguyla alakalı yüzlerce sayfa varsa, o zaman yalnızca bir tane (en alakalı sayfa) olacaktır.
Yandex, koristuvach'ın farklı bilgileri seçmesini ve koristuvach'ın bu kişiler için önemsiz görünen aynı sitenin sayfalarından birkaç sayfalık ses türü bilgiyi yakmamasını sağlamayı amaçlamaktadır. Diğer nedenler.
Ancak aceleyle bekliyorum çünkü bu makaleyi tamamlarsam, Yandex'in aynı kaynaktan başka bir belgenin görünmesine izin vermeye başlayacağını yeni bir şey öğrendim, sanki bu taraf "hatta iyi ve doğru" görünüyor (başka bir deyişle) kelimeler, sorguyla oldukça alakalıdır).
Dikkat çekici olan, aynı siteden gelen ek sonuçların da numaralandırılmasıdır ve bu nedenle, bu üst kısım aracılığıyla daha alt konumları işgal eden çeşitli kaynaklar düşecektir. Yeni Yandex sürümünün aks ucu:

Yavaş yavaş tüm siteleri dizine eklemeye çalışıyorlar, ancak bu genellikle sayfalardaki sayfa sayısının çok farklı olmasıyla olmuyor (bazılarında on, bazılarında ise on milyon var). Yak buti u tsomu vipadku?
Yandex, indekse tek bir siteden indirilebilecek çok sayıda belgeyi değiştirerek bu durumdan uzaklaşıyor.
Başka seviyedeki alan adlarına sahip projeler için, örneğin bir web sitesi için, Runet aynası tarafından indekslenebilecek maksimum sayfa sayısı yüz ila yüz elli bin arasındadır (belirli bir sayı, atamaya dayanmaktadır). o proje).
Üçüncü seviye alan adlarından elde edilen kaynaklar için – on ila otuz bin sayfa (belgeler).
Başka düzeyde () etki alanına sahip bir web siteniz varsa ve örneğin bir milyon web sitesini dizine eklemeniz gerekiyorsa, bu durumdan çıkmanın tek yolu alt alan adlarının () kişiliksizliğini oluşturmak olacaktır.
Başka düzeydeki bir alan adına ait alt alanlar şu şekilde görünebilir: JOOMLA.site. Diğer ülkeler için Yandex tarafından indekslenebilecek alt alan adlarının sayısı 200'den biraz fazladır (bazen bine kadar), bu nedenle bu basit yolla birkaçını RuNet aynasının indeksine daha fazla web sayfası koyabilirsiniz.
Yandex, Rusya dışındaki alan bölgelerindeki web sitelerinin önüne nasıl yerleştirilir?
Yandex yakın zamana kadar internetin Rusya kısmıyla ilgilendiği için ağırlıklı olarak Rus projelerini indeksliyor.
Rus bölgelerine (RU, SU ve UA) atfedilmesi gereken etki alanı bölgelerinde olmayan bir web sitesi oluşturuyorsanız, indekslemeyi kontrol etmek mümkün değildir, çünkü Her şeyi görmüş olan siz, sizi bir aydan daha erken bir zamanda tanıyamayacaksınız. Endeksleme zaten başlamışsa, Rus etki alanı bölgeleriyle aynı sıklıkta gerçekleşecektir.
Tobto. Etki alanı bölgesi yalnızca bir saat boyunca akar, bu da indekslemenin başlangıcına geçer, ancak frekansına daha fazla akmaz. Konuşmadan önce frekans nedir?
Sayfaların yeniden indekslenmesinden itibaren ses sistemlerinin çalışma mantığı yaklaşık olarak aynıya indirgenmiştir:
- Yeni sayfayı tanıyıp dizine ekleyen robot, ertesi gün bu sayfaya gidecektir.
- Dün ne olduğunu anlayan ve görevlerini bilmeyen robot üç gün sonra tekrar yanına gelecek.
- Hiçbir şey değişmeyecek, on yıl sonra gelecek vs.
O. Dolayısıyla robotun bu tarafa gelme sıklığı, güncelleme sıklığına eşittir veya eşit olacaktır. Üstelik robotun yeniden giriş saati hem Çin'de hem de Rusya'da farklı lokasyonlara göre değişiklik gösterebiliyor.
Bunlar, farklı kaynakların farklı bölümleri için bireysel teslimat programı oluşturan akıllı ses sistemleridir. Ancak ses sistemlerinden bannerlarımızın arkasındaki sayfayı sanki hiçbir şey değişmemiş gibi yeniden indekslemelerini isteyebilirsiniz, ancak bu konuda farklı bir istatistik var.
Arama sistemlerinde ortaya çıkan sorunlara ve nüanslara bakacağımız mevcut durumda arama ilkelerini tanıtmaya devam edelim. Ve elbette başka birçok şey daha var, bu yüzden başka bir şekilde de yardımcı oluyor.
Sana iyi şanslar! Yakında blog sitesinde görüşürüz
Başın dertte olabilir
 Rel Nofollow ve Noindex - sitedeki harici mesajların Yandex ve Google tarafından indekslenmesi nasıl engellenir
Rel Nofollow ve Noindex - sitedeki harici mesajların Yandex ve Google tarafından indekslenmesi nasıl engellenir  Konuşma morfolojisinin ortaya çıkışı ve ses sistemlerinin neden olduğu diğer sorunların yanı sıra yüksek frekans, orta frekans ve düşük frekanslı girişlerin frekansı
Konuşma morfolojisinin ortaya çıkışı ve ses sistemlerinin neden olduğu diğer sorunların yanı sıra yüksek frekans, orta frekans ve düşük frekanslı girişlerin frekansı  Bir siteye güvenin - nedir, XTools'ta nasıl yok olunur, onu ne etkiler ve sitenizin otoritesini nasıl artırırsınız
Bir siteye güvenin - nedir, XTools'ta nasıl yok olunur, onu ne etkiler ve sitenizin otoritesini nasıl artırırsınız  SEO terminolojisi, steno ve jargon
SEO terminolojisi, steno ve jargon  Alaka düzeyi ve sıralama - Sitelerin Yandex ve Google'daki sıralamasını etkileyen bu faktörler nelerdir?
Alaka düzeyi ve sıralama - Sitelerin Yandex ve Google'daki sıralamasını etkileyen bu faktörler nelerdir?  Hangi arama motoru optimizasyonu faktörleri sitenin performansını bu şekilde etkiler?
Hangi arama motoru optimizasyonu faktörleri sitenin performansını bu şekilde etkiler?  Metinlerin arama optimizasyonu - optimum anahtar kelime sıklığı ve ideal doğum gününüz
Metinlerin arama optimizasyonu - optimum anahtar kelime sıklığı ve ideal doğum gününüz  Site içeriği - benzersiz ve benzersiz içeriğin eklenmesi sitelerin günlük gelişimine yardımcı olduğundan
Site içeriği - benzersiz ve benzersiz içeriğin eklenmesi sitelerin günlük gelişimine yardımcı olduğundan  Meta etiketleri başlığı, açıklaması ve anahtar kelimeleri
Meta etiketleri başlığı, açıklaması ve anahtar kelimeleri  Yandex güncellemeleri - ne olur, Göğüsler nasıl takip edilir, ses türleri nasıl değiştirilir ve diğer tüm güncellemeler
Yandex güncellemeleri - ne olur, Göğüsler nasıl takip edilir, ses türleri nasıl değiştirilir ve diğer tüm güncellemeler
Ses sistemleri (PS) artık internetin önemli bir parçası. Bugün, yalnızca gerekli bilgileri bulmak için değil, aynı zamanda iş için sıcak alanlara erişim için de araç olan karmaşık mekanizmalara güveniyorlar.
Çoğu koristuvach, çalışmalarının ilkelerini, koristuvach içeceklerinin işlenme yöntemlerini, bu sistemlerin nasıl yapıldığını ve çalıştığını hiç düşünmemiştir. Bu materyal, ses makinelerinin cihazları ve temel işlevlerini optimize etme ve anlama konusunda çalışan kişilere yardımcı olacaktır.
PS'nin işlevleri ve anlaşılması
Poşukova sistemi– bu, internette arama yapma işlevi için kullanılan ve kullanıcının herhangi bir metin ifadesini (veya daha doğrusu bir arama isteğini) forma girmesini gerektiren isteğine yanıt veren bir donanım-yazılım kompleksidir. Üzerindeki siparişlerin bir listesinin alaka düzeyiyle ilgili bilgi kaynakları. En geniş ve en büyük arama sistemleri: Google, Bing, Yahoo, Baidu. Runet'te Yandex, Mail.Ru, Rambler var.En önemli şeye, sırf eğlence olsun diye, Yandex sistemini örnek alarak daha yakından bakalım.
Soru, aradığınız konuya tamamen benzer bir şekilde, mümkün olduğunca basit ve kısa bir şekilde formüle edilmelidir. Örneğin, bu arama motorundaki bilgileri bilmek istiyoruz: "Kendiniz için nasıl araba seçersiniz?" Bunu yapmak için ana sayfayı açın ve "nasıl araba seçilir" aramasını girin. O zaman bizim görevimiz bu mesajlar için sınırdaki danışma masasına gitmekle sınırlı.

Eğer bu şekilde çalışırsanız ihtiyacımız olan bilgiyi reddedebilirsiniz ve reddetmeyeceksiniz. Böyle olumsuz bir sonuç aldıysak, yalnızca talebimizi yeniden biçimlendirmemiz gerekir, aksi takdirde arama veritabanında bu tür taleple ilgili herhangi bir yararlı bilgi yoktur (bu, talebin "üniversite" parametrelerini belirlerken tamamen mümkündür, örneğin: örneğin, “Anadyri'de araba nasıl seçilir”).
Kutanöz işitme sisteminin en önemli görevi insanlara ihtiyaç duydukları bilgiyi sağlamaktır. Ve öğrencilere ses sistemlerine "doğru" türde çağrılar yapma alışkanlığını kazandırmak, dolayısıyla çalışma prensipleriyle tutarlı ifadeler kullanmak neredeyse imkansızdır.
Bu yüzden şaka spekülatörleri, sanki tüccarlara kendileri için neyin yararlı olduğunu bildirecekmiş gibi, robotlarının bu tür ilkelerini ve algoritmalarını yıkmaya çalışıyorlar. Bu, sistemin, internette gerekli bilgileri ararken kişinin düşündüğü gibi "düşünmesinden" sorumlu olduğu anlamına gelir.
Aramanızı bir arama makinesine girdiğinizde ihtiyacınız olanı en basit ve en hızlı şekilde bulabilirsiniz. Sonucu aldıktan sonra uzman, robotik sistemi bir takım kriterlere göre değerlendirmeye başlar. İhtiyacınız olan bilgiyi bulmayı başardınız mı? Neyse, bir sorgunun metnini bilmek için kaç kez yeniden biçimlendirmeniz gerekti? İlgili bilgilerin ne kadarı kaybedildi? Shvidko Poshuk'un sistemi bunu nasıl işledi? Arama sonuçları ne kadar kolaydı? İstediğiniz sonucu ilk olarak mı aldınız yoksa 30. ayda mı yaşadınız? Arka planda aynı anda ne kadar “şey” (gereksiz bilgi) bulundu? İlgili bilgileri saate, saate, yıla, aya göre buluyor musunuz?

Bu tür gıdalar için doğru gıda türlerini seçebilmek amacıyla üreticiler, sıralama ilkelerini ve algoritmalarını kademeli olarak iyileştirmenin, bunlara yeni yetenekler ve işlevler eklemenin ve herhangi bir şekilde daha iyi çalışan sistemler yaratmanın yollarını arıyor.
Ses sistemlerinin temel özellikleri
Aramanın önemli ölçüde ana parametreleri:Povnota.
Tekrarlama, aramanın en önemli özelliklerinden biridir ve bir aramada bulunan bilgi dokümanlarının sayısı ile bunların internette aranabilecek sayısı ile ilgilidir. Örneğin bir satırda “araba nasıl seçilir” kelimesini içeren 100 sayfa var ve aynı arama sonrasında toplam sayıdan toplam 60 adet seçildiğinde bu durumda arama sıklığı 0,6 olur. Aramanın kendisi ne kadar yüksek olursa, öğrencinin özellikle uyuduğu için ihtiyaç duyduğu belgeyi bulma ihtimalinin de o kadar yüksek olduğu açıktır.Kesinlik.
Ses sisteminin bir diğer temel işlevi doğruluktur. Vaughn, müşterinin Merezha'da belirlenen sayfalara yazışma düzeyini gösterir. Örneğin, "bir araba nasıl seçilir" anahtar ifadesi yüz belge içerdiğinden, bunların yarısı ifadeler içerdiğinden ve diğerleri sadece kelimeler içerdiğinden (bir araba radyosunun doğru şekilde nasıl seçileceği ve bir arabaya nasıl kurulacağı), Poshkov'un noktası en fazla 50/100 = 0,5.Arama ne kadar doğru olursa, ihtiyacınız olan bilgi o kadar doğru olur, sonuçlar arasında “öneriler” ne kadar az çeşitlilik gösterirse, o kadar az bulunan belgeler sorunun yerini almaya uygun olmaz.
Alaka düzeyi.
Önemli olan, bilginin internette yayınlandığı andan arama motorunun indeks veri tabanına girildiği ana kadar geçen saati karakterize eden saklama süresidir.Örneğin ertesi gün, yeni iPad'in piyasaya sürülmesiyle ilgili bilgiler ortaya çıktıktan sonra birçok kişi benzer türde sorular sormaya başladı. Çoğu durumda, bu yeni ürünle ilgili bilgiler, ortaya çıkışından bu yana zaman geçmesine rağmen zaten çevrimiçi olarak mevcuttur. Bu, İsveç üssünün günde birkaç kez güncellenen harika ses sistemlerinden her zaman açıktır.
Şaka gibi geliyor.
Esneklik gibi bu işlev, "üstünlük direnci" olarak adlandırılan şeyle yakından ilgilidir. Arama yaparken çok sayıda insan var, böyle bir hayranlık, bir sorunun işlenmesi saatinde önemli bir azalma gerektiriyor. Burada hem ses sisteminin hem de kullanıcının çıkarları tamamen önlenir: sonuçları mümkün olan en kısa sürede kaldırmak istersiniz ve ses sistemi, yaklaşan işlemleri aşırı işlememek için bu isteği mümkün olduğu kadar hızlı işlemekten sorumludur. istekler.Tamlık.
Başlangıçta sonuçların ortaya konması, aramanın başarısındaki en önemli unsurdur. Perde arkasında, arama sistemi binlerce ve bazı durumlarda milyonlarca farklı belgeyi içeriyor. Aramaya yönelik anahtar ifadelerin bileşiminin belirsizliği veya yanlışlığı nedeniyle, aramanın ana sonuçları her zaman gerekli bilgilerden yoksun olmayacaktır.Bu, insanların genellikle verilen sonuçların ortasında düşüncelerini gerçekleştirmek zorunda oldukları anlamına gelir. PS türündeki sayfaların çeşitli bileşenleri, ses sonuçlarında gezinmeye yardımcı olur.
Ses sistemlerinin gelişim tarihi
İnternet gelişmeye başladığında kalıcı tüccarların sayısı azdı ve erişime açık bilgi miktarı hala azdı. Bu alana daha fazla erişim, bilimsel ve araştırma alanlarındakilerle sınırlıdır. O zamanlar bilgi birikimi şimdiki kadar alakalı değildi.Bilgi kaynaklarına geniş erişimi organize etmenin ilk yöntemlerinden biri, site dizinlerinin oluşturulmasıydı ve üzerlerindeki mesajlar konuya göre gruplandırılmaya başlandı. 1994 baharında ortaya çıkan kaynak Yahoo.com böyle bir ilk proje oldu. Bu yıl Yahoo kataloğundaki sitelerin sayısı önemli ölçüde arttığından, katalogda gerekli bilgileri arama seçeneği eklendi. Dünyada henüz tam bir arama sistemi mevcut değildir, çünkü bu tür bir aramanın alanı İnternet'teki tüm kaynaklarla değil, yalnızca bu dizinde yer alan sitelerle sınırlandırılmıştır. Büyük kişilere gönderilen kataloglar geçmişte yaygın olarak kullanılıyordu ancak artık popülerliğini neredeyse tamamen kaybetmiş durumda.
Günümüzün harika katalogları bile internetteki az sayıda site hakkında bilgi içermektedir. Dünyanın en popüler ve en büyük kataloğu, Google veritabanı 25 milyardan fazla site hakkında bilgi içeriyorsa, beş milyon site hakkında bilgi içerir.

Dünyanın en popüler arama motoru, geçmişi 1994 yılına dayanan WebCrawler'dı.
AltaVista ve Lycos yaklaşan kader için ortaya çıktı. Üstelik Persha çok zor bir dönemde bilgi arayışında lider olmuştur.

1997 yılında Sergiy Brin, Larry Page ile birlikte Stanford Üniversitesi'nde bir takip projesi olarak Google arama motorunu yarattı. Bugün Google'ın kendisi dünyanın en popüler arama motorudur.

1997 baharında, Runet'teki en popüler arama sistemi haline gelen Yandex PS duyuruldu (resmi olarak).

anma töreni için 2015 baharı roku, dünya çapındaki ses sistemlerinin parçaları aşağıdaki sıraya göre bölünmüştür:
- Google – %69,24;
- Bing – %12,26;
- Yahoo! - %9,19;
- Baidu – %6,48;
- AOL – %1,11;
- Sor - %0,23;
- Heyecan - %0,00

anma töreni için meme 2016 roku, Runet'teki ses sistemlerinin parçaları:
- Yandex-%48,40
- Google – %45,10
- Search.Mail.ru - %5,70
- Rambler – %0,40
- Bing – %0,30
- Yahoo-%0,10

Robotik ses sisteminin prensipleri
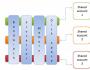
Rusya'nın ana arama sistemi Yandex, ardından Google ve ardından [email protected]'dur. Bütün büyük sistemler diğerlerinden farklılaştıkça kendi yapılarını ararlar. Ancak yine de tüm ses sistemleri için gerekli olan temel unsurları görebilirsiniz.İndeksleme modülü.
Bu bileşen üç yazılım robotundan oluşur:Örümcek(İngilizce pavuk) web sayfalarını çekmek için tasarlanmış bir programdır. “Pavuk” şarkının şarkısını büyülüyor ve içindeki tüm mesajları anında ortaya çıkarıyor. Html kodu pratik olarak dış görünüm tarafından büyülenmiştir. Bu amaçla HTTP protokollerini kullanıyoruz.

“Pavuk” bu şekilde çalışıyor. Robot, isteği sunucuya "get/path/document" ve diğer komutlara HTTP kullanarak gönderir. Buna yanıt olarak robot programı, bilgileri servis görünümüne ve tabii ki belgeye yerleştiren metin akışını seçer.
- İstenilen sayfanın URL'si;
- sitenin oluşturulduğu tarih;
- sunucu http-video başlığı;
- html kodu, sayfanın "gövdesi".
Dizin oluşturucu(Robot indeksleyici), örümceklerin indirdiği sayfaları analiz eden bir programdır.

Dizin oluşturucu, depo öğelerini kapsamlı bir şekilde analiz eder ve kendi morfolojik ve sözcüksel algoritma türlerini kullanarak analizlerini gerçekleştirir.
Analiz, sayfanın başlıklar, metin, mesaj, stil ve yapısal özellikler, html etiketleri vb. gibi çeşitli bölümleri üzerinde gerçekleştirilir.
Böylece indeksleme modülü, belirli sayıda kaynağı gözden geçirmenize, sayfaları yakalamanıza, ele geçirilen belgelerden yeni sayfalara mesaj çıkarmanıza ve bunların rapor analizini yapmanıza olanak tanır.
Veri tabanı
Veri tabanı(veya arama motoru dizini) - bir veri kaydetme kompleksi, indeksleme modülü ve saklanan belge tarafından elde edilen dış görünüm parametrelerinin işlenmesinin ilk adımında kaydedilen bir bilgi dizisi.Ses sunucusu
Bu, bu sistemin en önemli unsurudur, çünkü işlevselliğinin merkezinde yer alan algoritma türleri, şakanın akışkanlığını ve özellikle de asiditesini doğrudan içerir.Ses sunucusu her zamanki gibi çalışır:
- Ağızdan çıktığında morfolojik incelemeye tabi tutulur. Veritabanındaki herhangi bir belgeye özel bilgi oluşturulur (daha sonra bu sorguya karşılık gelen metnin bilgi alanı olan bir snippet olarak görüntülenecektir).
- Çıkarılan veriler, giriş parametreleri olarak özel bir sıralama modülüne aktarılır. Tüm belgeler gözden geçirilir ve bu tür her belgenin sonucuna, böyle bir belgenin tüccar ve diğer depolarla alaka düzeyini karakterize eden kendi derecelendirmesi atanır.
- Muhabirin atadığı akıllara göre bu derecelendirme, ek akıllarla tamamen düzeltilebilir.
- Daha sonra çulluğun kendisi üretilir. Özet tablosunda bulunan herhangi bir belge için, sorguya en çok benzeyen başlığı, özeti ve bu belge için sözcük formunun bulunduğu ve sözcüklerin vurgulandığı mesajı seçin.
- Arama sonuçları, arama sonuçlarının göründüğü sayfada (SERP) onları oluşturan kişilerle paylaşılır.
Zengin yatırımcıların girdi ve girdileri seçebilmeleri için İnternet gereklidir.
Sanki hiçbir arama sistemi yokmuş gibi, koristuvach'lar bağımsız olarak gerekli siteleri aramak, ezberlemek ve kaydetmek zorundaydı. Bu gibi durumlarda, neye ihtiyacınız olduğunu "manuel olarak" bilmek daha da zor ve çoğu zaman imkansız olacaktır.
Bizim için tüm bu rutin işler web sitelerindeki bilgilerin aranması, kaydedilmesi ve sıralanmasıyla yapılıyor.
Runet'in bilinen arama sistemlerinden bahsedelim.
Rus İnternet'teki arama sistemleri
1) Jambon ses sistemiyle başlayalım. Yandex sadece Rusya'da değil, Belarus ve Kazakistan, Ukrayna ve Türkiye'de de faaliyet gösteriyor. Ayrıca Yandex İngilizce dili.
2) Google arama motoru bize Amerika'dan geldi ve Rusça yerelleştirmesine sahip:
3) Mail.ru ve diğer projelerde görülebilen VKontakte, Odnoklassniki sosyal ağının yanı sıra My World'ü aynı anda temsil eden popüler arama motoru Mail ru.
4) Akıllı arama sistemi
Nigma (Nigma) http://www.nigma.ru/
19 Haziran 2017'de entelektüel zenci çalışmıyor. Yaratıcıları için finansal bir çıkarı temsil etmekten vazgeçip CocCoc adında farklı bir arama sistemine geçtiler.
5) Rostelecom şirketi evde Suputnik arama sistemini oluşturdu.
Ve özellikle çocuklar için yazdığım şakacı Saputnik.
6) Rambler ilk popüler arama motorlarından biriydi:
Dünyada başka türde ses sistemleri de vardır:
- Bing,
- yahoo!,
- Baidu,
- Ekosia,
Arama sisteminin nasıl çalıştığını ve sitelerin nasıl dizine eklendiğini anlamaya çalışalım, dizine ekleme sonuçlarını analiz edelim ve arama sonuçlarını formüle edelim. Ses sistemlerinin çalışma prensipleri yaklaşık olarak aynıdır: Müşterilerden ilgili bilgileri elde etmek amacıyla internette bilgi aramak, kaydetmek ve sıralamak. Ses sistemlerinin arkasında çalıştığı algoritmalar da büyük ölçüde farklılık gösterebilir. Bu algoritmalar karanlıkta tutulur ve uyumsuzlukları korunur.
Aynı sinyali bir dizi farklı ses sistemine yerleştirerek farklı türleri seçebilirsiniz. Bunun nedeni tüm arama motorlarının güçlü algoritmalar kullanmasıdır.
Ses sistemlerinin metası
Öncelikle ses sistemlerinin ticari bir kuruluş olduğunu bilmemiz gerekiyor. Bu meta - otrimannaya karı. İçeriksel reklamlardan, diğer reklam türlerinden ve gereksiz sitelerin üst sıralara yerleştirilmesinden kar elde edilebilir. Pek çok yol var.
Hedef kitlenin büyüklüğüne ve bu arama sistemini kaç kişinin kullandığına bağlıdır. Hedef kitle ne kadar büyük olursa reklam o kadar çok kişiye gösterilir. Görünüşe göre daha fazla reklam olacak. Arama motorları, reklam maliyetini azaltarak arama motorlarının hedef kitlesini artırabileceği gibi, hizmetlerinin kapasitesini, algoritmasını ve aramaların güvenilirliğini azaltarak arama motorlarının karlılığını artırabilir.
Buradaki en gelişmiş ve karmaşık şey, daha fazla müşteri sorgusu için alakalı sonuçlar üretecek tamamen işlevsel bir arama algoritmasının geliştirilmesidir.
Arama motorunun ve web yöneticilerinin çalışmaları
Deri iğneleme sisteminin, bilgileri analiz ederken çok sayıda farklı faktörü ve doktorun isteğine verilen karmaşık yanıtları birleştirmekten sorumlu olan kendi güçlü algoritması vardır:
- şu ya da bu sitenin yüzyılı,
- web sitesi alan adı özellikleri,
- sitenin içeriği açıktır,
- navigasyonun özellikleri ve sitenin yapısı,
- kullanılabilirlik (işletme sahipleri için yararlılık),
- davranışsal görevliler (arama motoru, sitenin cevabını bilenler tarafından belirlenebilir ve arama sistemine geri dönüp orada tekrar aynı sorunun cevabını arayan kişi tarafından belirlenebilir)
- vesaire.
Tüm bunlar, içtiğiniz içeceğin sizi tatmin etmesi için mümkün olduğunca alakalı olmasını sağlamak için gereklidir. Bunun sonucunda ses sistemlerinin algoritmaları giderek değişmekte ve iyileştirilmektedir. Göründüğü gibi, titizlik eksikliği yok.
Öte yandan, web yöneticileri ve optimize ediciler, sitelerini tanıtmak için sürekli olarak yeni yollar buluyorlar ve bu yöntemler her zaman adil değil. Arama motorlarının algoritmasına yönelik talimatlar - dürüst olmayan optimize edicilerin "pis" sitelerinin ÜST'te listelenmesine izin vermemek için bir sonraki değişiklikten önce değişiklikler yapın.
Arama sistemi nasıl çalışıyor?
Şimdi ses sisteminin sorunsuz bir şekilde nasıl çalıştığından bahsedelim. En az üç aşamadan oluşur:
- tarama,
- indeksleme,
- sıralama.
İnternetteki sitelerin sayısı astronomiktir. Ve cilt sitesi bilgidir, okuyucular (yaşayan insanlar) tarafından oluşturulan bilgi içeriğidir.
Skanuvannya
Bu, yeni bilgiler toplamak, mesajı analiz etmek ve sorunuza yanıt almak amacıyla aranabilecek yeni içeriği aramak için İnternet'te arama yapmak anlamına gelir. Tarama için ses sistemlerinde ses robotu veya örümcek adı verilen özel robotlar bulunur.
Arama robotları, web sitelerinde otomatik olarak gezinen ve onlardan bilgi toplayan programlardır. Skanuvannya mozhe buti pervinnim (önce robot yeni siteye gider). Siteden ilk bilgi toplanması ve arama motoru veri tabanına girilmesinin ardından robot, sitenin sayfalarını düzenli bir şekilde ziyaret etmeye başlar. Herhangi bir değişiklik yapılmışsa (yeni içerik eklenmiş, eski içerik kaldırılmışsa), tüm bu değişiklikler arama motoru tarafından kaydedilecektir.
Arama motorunun ana görevi, yeni bilgi bulmak ve bunu bir sonraki işleme aşaması ve ardından indeksleme için arama motoruna sağlamaktır.
İndeksleme
Arama motoru, yalnızca veritabanında zaten listelenmiş olan (kendi tarafından indekslenmiş) siteler arasında bilgi arayabilir. Tarama, başka bir siteden bilgi arama ve toplama işlemi olduğu gibi, indeksleme de bu bilginin arama motorunun veritabanına girilmesi işlemidir. Bu aşamada arama motoru bu ve diğer bilgilerin kendi veri tabanına nasıl girileceğine, nereye, veri tabanının hangi bölümüne girileceğine ilişkin kararları otomatik olarak verir. Örneğin Google, robotlarının internette bulduğu bilgilerin neredeyse tamamını dizine eklerken, Yandex daha güçlüdür ve her şeyi dizine eklemez.
Yeni siteler için indeksleme aşaması daha uzun olabilir, bu da arama motorları sayesinde yeni sitelerin daha uzun süre taranabileceği anlamına gelir. Ve eski, çarpıtılmamış sitelerde görünen yeni bilgiler mümkün olan en kısa sürede indekslenebilir ve neredeyse anında bir "indekse", ardından arama motorlarının veri tabanına yerleştirilebilir.
Ranjuvannya
Sıralama, arama motorunun muhabirlerine önceden hangi bilgileri göstereceği ve hangi bilgilerin gönderileceği için daha önce indekslenmiş ve bir veya başka bir arama motorunun veritabanına girilmiş, sıralamayı takip eden bir bilgi seçimidir. daha düşük bir “sıralama” arıyoruz. Sıralama müşterinizin yani müşterinizin ses sistemine hizmet verme aşamasına getirilebilir.
Arama sisteminin sunucularında veriler çok çeşitli farklı sorgular için işlenir ve işlenir. Robotun şaka algoritmalarını kullanmaya başladığı yer burasıdır. Tüm siteler veritabanına girilir ve konulara göre sınıflandırılır, konular sorgu gruplarına ayrılır. Uygulama gruplarının cildine göre ön görünüm buna göre ayarlanacağı için katlanabilir.
Merhaba blog sitesinin sevgili okuyucuları. , o zaman sayısız koristuvach'ın yeterli güç yer imleri vardı. Ancak, hatırladığınız gibi, geometrik bir ilerleme içinde olduğumuz için, onun tüm çeşitliliğinde gezinmek daha da zorlaştı.
Daha sonra yazarlarının çeşitli siteleri ekleyip kategorilere ayırdığı kataloglar (Yahoo, Dmoz ve diğerleri) ortaya çıktı. Bu, küresel ölçekte vurguncuların sayısı hâlâ sayıca geride olanların hayatını anında kolaylaştırdı. Çok sayıda canlı katalog var.
Yalnızca bir saat sonra, veritabanlarının boyutu o kadar büyüdü ki, geliştiriciler hemen aralarında bir arama yapmayı ve ardından İnternet'teki her şeyi indekslemek için otomatik bir sistem oluşturmayı, böylece herkesin erişebilmesini sağlamaya başladılar. onlardan korkuyorum.
Rus İnternet segmentinin ana ses sistemleri
Tahmin edebileceğiniz gibi, bu fikir büyük bir başarıyla uygulandı, ancak internette hayatta kalmayı başaran yalnızca bir avuç şirket için her şey yolunda gitti. Belki de ilk baskıda ortaya çıkan tüm ses sistemleri ya ortaya çıktı ya da hala hayattaydı ya da uzak rakipler tarafından satın alınmıştı.
Ses sistemi çok karmaşık ve daha da önemlisi kaynak yoğun bir mekanizmadır (sadece maddi kaynaklar değil, aynı zamanda insan kaynakları da tehlikededir). Çağrının veya Google'ın münzevi benzerinin arkasında, bu makinenin çalışmaya devam etmesi için gerekli olan binlerce casus yazılım, yüzbinlerce sunucu ve milyarlarca dolarlık mevduat var ve rekabet avantajını kaybetti.
Bu pazara bir anda girmek ve sıfırdan başlamak gerçek bir iş projesinden çok bir ütopyadır. Örneğin, dünyanın en büyük şirketlerinden biri olan Microsoft, onlarca yıldır arama pazarında kendine yer edinmeye çalışıyor ve şimdi arama motoru Bing yavaş yavaş içgörülerini doğrulamaya başlıyor. O zamana kadar çok az başarısızlık ve başarısızlık yaşandı.
Özel finansal girişler olmadan bu pazara girmesi gerekenler hakkında ne söyleyebiliriz? Örneğin ev yapımı ses sistemimiz Nigma'nın cephaneliğinde pek çok değer ve yenilik var ve bunların ilerlemeleri Rusya pazarının liderlerine binlerce kez veriliyor. Örneğin Yandex hedef kitlesine bir göz atın:

Bununla bağlantılı olarak, RuNet'in ve tüm İnternet'in ana (en kısa ve en başarılı) arama motorlarının listesinin zaten oluşturulduğunu ve tüm entrikanın esas olarak kimin öldürüldüğüne ve neyin öldürüldüğüne bağlı olduğunu hesaba katabilirsiniz. onları bölmek için yüzde değil, çünkü tüm kokular gitti. ve yüzerken kaybedersiniz.
Rusya'da ses sistemleri pazarı Gerçekten çok güzel görünüyor ve burada melodik bir şekilde iki veya üç ana çakılı ve birkaç tane daha görebilirsiniz. RuNet'te, anladığım kadarıyla dünyada yalnızca iki ülkede tekrarlanan benzersiz bir durum gelişti.
2004 yılında Rusya'ya gelen Google arama motorunun henüz liderliğe ulaşmayı başaramadığı kişilerden bahsediyorum. Aslında bu dönemde kokular çıkmaya başladı, Yandex'i satın alın ama orada işe yaramadı ve aynı zamanda Çek Cumhuriyeti ve Çin ile birlikte “Rusya'mız” ve bu yerlerle birlikte yüce Google, tanımadı Hasarı kabul et, ciddi bir op ir var.
Gerçekten, üretim tesisini tam ortasında iyileştirin RuNet'teki en iyi şakacılar belki birisi. Tek yapmanız gereken bu URL'yi tarayıcınızın adres çubuğuna yapıştırmak:
http://www.liveinternet.ru/stat/ru/searches.html?period=month;total=yes
Sağda vikoristlerin çoğunun kendi sitelerinde olduğu görülüyor ve bu URL, çeşitli arama motorlarından gelen reklamların RU etki alanı bölgesine giren tüm sitelere erişimine ilişkin istatistikler almanızı sağlar.
Belirtilen URL'yi girdikten sonra, çok çekici ve prezentabl olmayacaksınız, ancak resmin özünü daha iyi temsil edeceksiniz. Dikkatinizi Rus sitelerinin trafiği kaldırdığı ilk beş arama motoruna çevirin:

Yani elbette Rus içerikli kaynakların tümü bu bölgede yer almıyor. Ayrıca SU ve RF'nin yanı sıra COM veya NET gibi gizli bölgelerde de RuNet'e yönelik İnternet projeleri vardır, ancak yine de seçim hala oldukça temsilidir.
Bu içerik, örneğin sunumunuz için şu önlemi alarak daha hızlı bir şekilde düzenlenebilir:

Öz değişmez. Birkaç lider ve bir dizi yüksek ses sistemi. Konuşmadan önce birçoğu hakkında zaten yazdım. Bazen başarının geçmişini araştırmak veya belki de gelecek vaat eden ses sistemlerinin başarısızlıklarının nedenlerini araştırmak zordur.
Peki, bunlar Rusya ve bir bütün olarak RuNet için önemli olduğundan, onların sözünü kesip onlara kısa bir gösteri yapacağım:
Google aramaları, gezegenin zengin sakinleri için - bunun uğruna okuyabilecekleriniz hakkında - modası geçmiş hale geldi. Bu arama sisteminde, dünyanın her yerinden ve ayrıca kendi ailenizden sinyalleri topladıysanız “sonuç aktarımı” seçeneğine ihtiyaç vardır ancak maalesef mevcut değildir (google.ru'da kabul edilmektedir) .

Böylece kalan süre daha az tasarruflu ve türlerinin parlaklığı (Arama Motoru Sonuç Sayfası) olur. Özellikle RuNet aynasının arama sistemini en baştan başlatıyorum (işte, ondan önce bahsettiğim ses) ve orada mantıklı bir yol bilmeden Google'a gidiyorum.
Görünüşlerine bakın, beni mutlu etti ama geri kalan zamanlarda sadece uykulu, bir saat takılmak çok çıldırtıcı. SEO tanıtımını itibarsızlaştırmanın bir yolu olarak içeriğe dayalı reklamcılıktan ve sürekli yeniden karıştırmadan elde edilen geliri artırmaya yönelik mevcut mücadelenin bir dönüm noktasına yol açması mümkündür. RuNet'te arama motoru böyle olan tanınmış bir rakip var.
Runet'te arama yapmak için özellikle Go.mail.ru'ya gitmenizin pek mümkün olmadığını düşünüyorum. Bu nedenle, arama sistemini kullanan önemli projelerin trafiği çok daha yüksek, en az on yüz olabilir. Bu tür projelerin sahiplerinin sisteme olan saygısını artırması gerekiyor.
Bununla birlikte, İnternet'in Rusya segmentindeki arama motorları pazarındaki liderlerin açık ifadelerine ek olarak, bazıları düşük olan çok sayıda tüccar da var ve onların varlığına rağmen, onlar hakkında birkaç söz söylemek zor.
Başka bir kademeden RuNet sistemlerini arayın

İnternetin tamamı için ses sistemleri
Büyük rakhunko'nun arkasında, tüm İnternet ölçeğinde yalnızca bir ciddi mezar var. Google. Bu çılgın bir lider ama hâlâ rekabeti var.
Öncelikle hala aynı BingÖrneğin Amerika pazarında çok iyi bir konuma sahip, özellikle de motorunun tüm Yahoo hizmetlerinde aynı şekilde galip geldiğine inanılıyor (ABD'ye göre belki de tüm pazarın üçte biri).

Farklı bir şekilde, dünyanın büyük bir bölümünde, Çin'den gelen koristuvach'ların internetteki koristuvach'ların büyük çoğunluğuna koyduğu ana ses sistemi budur. Baiduışık Olympus'un merkezinde sıkışmış durumda. 2000 kişi arasında doğmuş olan bu şarkının payı şu anda Çin'deki toplam ulusal izleyicinin yaklaşık %80'ini oluşturuyor.
Bunu Baida hakkında açıkça söylemek önemlidir, ancak internette bu Top'daki yerin yalnızca en alakalı siteler tarafından değil, aynı zamanda bunun için ödeme yapanlar tarafından da (ortasında değil) işgal edildiğine dair büyüyen bir eğilim var. arama motoru) , SEO ofisi değil). Tabii ticari açıdan önce sıkıntıdayız.

İstatistiklere bakarsanız, Google'ın içeriğe dayalı reklamcılıktan daha fazla gelir elde etmek karşılığında neden verilerini kolayca kaybetmeye istekli olduğu anlaşılır. Aslında paralı askerlerin akışından korkmuyorlar çünkü çoğu durumda gidecek hiçbir yerleri yok. Bu durum sizi biraz sıkacak ama sonrasında ne olacağını merak edeceksiniz.
Konuşmadan önce, optimize edicilerin hayatını daha da zorlaştırmak ve belki de arama motorunun sakinliğini teşvik etmek için Google, yakın zamanda tarayıcıdan arama motoruna istek iletirken durgun şifrelemeyi uygulamaya koydu. Yakında insanların Google'dan ne tür sorgular geldiğini doktorların ve doktorların istatistiklerinde görmek artık mümkün olmayacak.
Tabii ki, bu yayında bahsedilen ses sistemlerine ek olarak, bölgesel, özel, egzotik vb. binlerce ses sistemi daha var. Bunları bir yazı içerisinde gereğinden fazla anlatmak ve anlatmak mümkün olmayacaktır ve açıkçası buna da gerek yoktur. Bunlar hakkında kısaca birkaç söz söyleyelim Şaka yapmak kolay değil Ve onu güncel tutmak kolay ya da ucuz değil.
Müşterilere tedarikleri konusunda geri bildirim vermek için çoğu sistemin benzer prensipler üzerinde çalışması (bunlar hakkında ve hakkında bilgi edinin) ve aynı kriterleri takip etmesi önemlidir. Ayrıca, kanıtlar ilgili (beslenmeyle ilgili), kapsamlı ve hiç de önemsiz olmayan bir şekilde ilgili (birincil tazelik) olabilir.
Bu sorunu bulmak artık o kadar kolay değil, özellikle doktorlar için, çünkü arama sisteminin milyarlarca İnternet sayfasını, uygulama türünü ve bir liste oluşturma yeteneğini kaybetmiş olanları (görünüşe göre) analiz etmesi gerekecek. beslenmeye en uygun çeşitler koristuvacha olacaktır.
Bu gereksiz görev, diğer sayfalara ek olarak bu sayfalardan bilgilerin ileriye doğru toplanmasına dayanmaktadır. indeksleme robotları. Daha önce yayınlanmış sayfalardan mesajları toplarlar ve bilgileri arama sistemi veritabanına aktarırlar. Metni indeksleyen robotlar vardır (birincil ve akıcı, yeni ve sıklıkla güncellenen kaynaklarda yayındadır, böylece her zaman en son veriler sunulur).
Buna ek olarak, robotlar görüntüleri görüntülemek (daha fazla görüntülenmek üzere), favicon'ları, ayna sitelerini (daha fazla hizalama ve olası yapıştırma için) görüntülemek için dizin oluşturucuları kullanır; robotlar, web yöneticilerine yönelik araçlar aracılığıyla (burada şunları yapabilirsiniz) çekirdek gibi İnternet sayfalarının işlevselliğini kontrol eder. ve ) hakkında bilgi edinin.
Kendisini indeksleme süreci ve ardından indeks veritabanlarını güncelleme süreci saatler alır. Google rakipleriyle çok daha fazla rekabet etmek istiyorsa, bir veya iki hafta değerinde olan Yandex'i işe alın (hakkında bilgi edinin).
İnternet sayfası yerine metni çağırın, ses motoru kelimeleri temel prensiplere göre ayırır, böylece farklı morfolojik formlarda verilen kelimelere doğru cevapları verebilirsiniz. Tüm harika şeyler Html etiketlerine ve açıklıklara benziyor. konuşmalar silinir, eksik olan kelimeler alfabeye göre sıralanır ve bu belgedeki yerleri onlarla belirtilir.
Bu araca ağ geçidi dizini denir ve web sitelerini değil, arama sisteminin sunucularında bulunan yapılandırılmış verileri aramanıza olanak tanır.
Yandex'de (çoğunlukla Rus sitelerine ve birkaç Ukraynalı ve Türk sitesine dayanan) bu tür sunucuların sayısı on, hatta yüzbinlerce ve Google'da (yüzlerce kelimeye dayanan) milyonlarcadır.
Birçok sunucu, belgeleri kaydetmenin bir yolu olarak hizmet veren ve veri işleme hızını artırmaya yardımcı olan (ek veri işlemenin yardımıyla) kopyalar oluşturur. Herkesin egemenliğini desteklemek için yapılacak harcamaları tahmin edin.
Zapit koristuvach nadsilatimetsya balansuvalnik navantazhennya, aynı anda en az navantazhennya olan sunucu segmentinde. Daha sonra bölgenin analizi yapılır, talebiniz iletilerek ses sisteminden veriler alınır ve morfolojik analiz gerçekleştirilir. Arama sırasına yakın zamanda benzer bir komut eklendiyse, sunucuya müdahale etmemek için önbellekten veri eklemeniz gerekir.
Talep henüz önbelleğe alınmamışsa bölgeye aktarılır, arama motorunun indeks veri tabanı ayrıştırılır. Sormadan önce iletişim kurmak isteyebileceğiniz mevcut tüm İnternet sitelerinin bir listesini göreceksiniz. Doğrudan giriş ve diğer morfolojik formlar vb. olarak sigortalayın. konuşmalar.
Ix yenilenmesi gerekiyor Hangi aşamada sağ tarafa algoritma (parça zekası) giriyor. Aslında, muhabirin talebi, yorumunun tüm olası varyantlarının aralığı için çarpılır ve sorguların yokluğunda hemen aranır (başkalarının erişebileceği arama sorgularının farklı operatörleri aralığı için koristuvacham).
Kural olarak, her türün cilt bölgesinin bir tarafı (bazen daha fazlası) vardır. Bugün çok sayıda memura sigorta sağlamak daha da zor. Ek olarak, bunların düzeltilmesi için referans sitelerini manuel olarak değerlendirmeleri gerekir, bu da robotun algoritmayı bir bütün olarak düzeltmesine olanak tanır.
Zagalom, berrak nehir, sağda karanlık olan. Süreçten uzun süre bahsedebiliriz ancak ses sisteminden memnun kalmanın kolay olmadığı o kadar açık ki. Ve gelecekte sizin ve benim gibi bunun ait olmadığı kişiler de olacaktır sevgili okurlar.
Sana iyi şanslar! Yakında blog sitesinde görüşürüz
Başın dertte olabilir
Yandex Kişileri - sosyal ağlarda insanlara nasıl şaka yapılır Apometr - ses sistemlerinde değişiklik, tür ve güncelleme desteği sağlayan ücretsiz hizmet DuckDuckGo - sizi takip etmeyecek bir arama sistemi  İnternetin hızı nasıl kontrol edilir (Spidtest, Yandex'den İnternetometre)
İnternetin hızı nasıl kontrol edilir (Spidtest, Yandex'den İnternetometre)  Yandex widget'ları - ana sayfayı nasıl kişiselleştirip sizin için daha bilgilendirici ve kullanışlı hale getirebilirsiniz
Yandex widget'ları - ana sayfayı nasıl kişiselleştirip sizin için daha bilgilendirici ve kullanışlı hale getirebilirsiniz  Yandex ve Google görsellerinin yanı sıra görsel dosyasını Tineye ve Google'da arayın Satın alma gönderildikten sonra potansiyel bağışçıların ücretsiz analizi için SEObuilding.RU'daki sitelerin güncellenmesi Google Alerts - nasıl bir şey ve nasıl bir şey?
Yandex ve Google görsellerinin yanı sıra görsel dosyasını Tineye ve Google'da arayın Satın alma gönderildikten sonra potansiyel bağışçıların ücretsiz analizi için SEObuilding.RU'daki sitelerin güncellenmesi Google Alerts - nasıl bir şey ve nasıl bir şey?  Sağdaki benimki, İnternet üzerinden çevrimiçi muhasebeye veya elektronik belge yönetimine bir bakış
Sağdaki benimki, İnternet üzerinden çevrimiçi muhasebeye veya elektronik belge yönetimine bir bakış  Ücretsiz dosya paylaşım hizmetleri - fotoğraf nasıl yüklenir ve resimdeki mesaj nasıl kaldırılır
Ücretsiz dosya paylaşım hizmetleri - fotoğraf nasıl yüklenir ve resimdeki mesaj nasıl kaldırılır