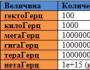
KOI8-Rのコーディング。 KOI8-Rのコーディングとは何ですか? 8文字のコーディングテーブル
-Czampolit(@ComradZampolit) 2017年9月17日
KOI8-Rの練習方法は?
KOI8-Rは8ビットのコードページで、キリル文字のアルファベットをコーディングするために分類されています。 小売業者は、キリル文字の記号の位置が、表の下部にある英語のアルファベットの音声の対応する記号と一致するように、ロシア語のアルファベットの記号を配置しました。 また、このコードで記述されたテキストで、スキンシンボルの8ビットを削除すると、ラテン文字の音訳と同様に、テキストが出力されます。
このような情報交換のためのコードは、ЄСEOMシリーズのコンピューターでは70年間停滞し、18年の半ばに、最初のロシア化バージョンで勝ち始めました。 オペレーティング·システム UNIX。
皮膚のシンボルには、00000000から11111111までの一意のコードが割り当てられていると考えられていました。このようにして、人は十字架のシンボルとコンピューターを区別しました。
Chi vikoristovuetsyaは、同時にChernovをコーディングしていますか?
Ni。 Vaughn bulaは、古い8ビットコンピューターに関連していますが、同時に、さまざまな形式でUnicodeを使用することがより重要です。
こんにちは、ブログサイトの新しい読者。 今日はそれらについてあなたと話します、星はサイトとプログラムで省略形として取られます、テキストをエンコードする方法とそれらを追跡する方法。 基本的なASCIIから始まり、CP866、KOI8-R、Windows 1251の拡張バージョンで始まり、UnicodeコンソーシアムUTF16および8の現在のエンコーディングで終わる開発の歴史について報告します。
誰に家を訪ねることができますが、同じkrakozyabrivを養うために私がどれだけ多く来ることができるかを知っているでしょう(一連の記号を読まないでください)。 これで、すべての記事をテキストに書き留めて、自分のわき柱を独自に調べる機会があります。 さて、情報を拾い上げて、ニュースの広がりを追跡する準備をしてください。
ASCII-ラテン語の基本的なテキストエンコーディング
テキストのコーディングの開発はITギャラリーの成形からすぐに行われ、悪臭は1時間でchimalihの変更の認識を追い越しました。 歴史的に、すべてはEBCDICで始まりました。これは、ラテンアルファベットの文字、アラビア数字、および句読点をケルチ記号でコーディングできるため、ロシア語では甘く聞こえませんでした。
しかし、それでも、wartoでのテキストの現代的なコーディングの開発のための正しいポイントは有名です ASCII(ロシアの鉱山は「空」のように聞こえるので、情報交換のためのアメリカの標準コード)。 Vaughnは、最初の128の記号を、最も頻繁に綴られる英語のkoristuvachs(アラビア数字と記号)で説明しています。
ASCIIで記述されたtsі128記号の詳細では、kshtaltアーチ、ґrat、zirochokにサービスシンボルのdeakを薄く使用していました。 Vlasne、あなた自身がїхїхすることができます:
ASCII cobバリアントの128文字が標準になり、他の方法でそれらの言語でエンコードされているため、この順序で悪臭を放つ価値があります。
その右側のエールは、1バイトの情報の助けを借りて、128ではなく256の異なる値(最高で256に等しい2つ)をエンコードして、次のようにすることができます ベーシックバージョン Askіz'yavivsyatsіli行 ASCIIエンコーディング拡張、国のコーディングのシンボル(たとえば、ロシア語)のコードの128の基本的な記号を作成することが可能です。
ここでは、説明の中で勝利を収めている数の体系について、もう少しだけ言います。 そもそも、ご存知のように、コンピューターは2進法の数値でのみ動作し、それ自体は0と1で動作します(大学や学校に行ったかのように「ブール代数」)。 、スキンはゼロから始まり、ソミーで最大2つのステップで2つあります。

このような設計で可能な0と1のすべての組み合わせが256未満になる可能性があることを理解することは重要ではありません。2つのシステムから10番目のシステムに数値を変換するのは簡単です。 独立するために、2つのステップすべてを単純に折りたたむ必要があります。
私たちのお尻は1(ゼロステップで2)プラス8(3ステップで2)、プラス32(5番目のステップで2)、プラス64(6番目)、プラス128(6番目)で出てきます。 全部まとめて233 10システム数字。 ヤクバカイト、すべてが簡単です。
しかし、ASCII文字を使用してテーブルを見ると、それらが16のコーディングで表示されていることがわかります。 たとえば、「zіrochka」vіdpovіdaєAskі16番目の番号2A。 間違いなく、16番目のシステムには、アラビア数字に加えて勝利した数字があり、A(10を意味する)からF(15を意味する)までのラテン文字が多いことがわかります。
さて、軸、 翻訳 ダブルナンバー 16世紀に攻撃的なシンプルで科学的な方法へのvdayutsya。 上のスクリーンショットに示すように、情報のスキンバイトはビット数に応じて部分に分割されます。 含む スキンハーフバイト ダブルコードエンコードできる値は16個(4番目のステップでは2個)のみで、16番目の数値で簡単に表示できます。
さらに、バイトの左半分では、スクリーンショットに示されているようにではなく、ステップをゼロからリセットする必要があります。 その結果、簡単な計算で、スクリーンショットにE9という数字がエンコードされていることがわかります。 私の誤解とこのパズルの解決策はあなたにとって賢明であることがわかったと確信しています。 さて、さて、テキストのコーディングについて話しましょう。
Askaの拡張バージョン-CP866とKOI8-Rを疑似グラフィックでコーディング
その後、すべての最新コード(Windows 1251、Unicode、UTF 8)の開発の出発点であるASCIIについて話し始めました。
128文字を超えるラテンアルファベット、アラビア数字などがありますが、拡張バージョンには、1バイトの情報にエンコードできる256個の値すべてを選択する機能があります。 トブト。 飛鳥に自分の言語の文字の記号を追加することが可能になりました。
ここで、説明するために、もう一度話す必要があります。 コーディングの新しいニーズテキストとそれがとても重要な理由。 コンピューターの画面上の記号は、2つのスピーチに基づいて形成されます-あらゆる種類の記号のベクトル形式(外観)のセット(悪臭はファイル3にあります)と、同じ記号を使用できるようにするコード適切な場所に挿入する必要があります。
ベクトル形式自体にフォントが使用されており、コーディングの軸は、入力されたプログラムのオペレーティングシステムに基づいていることに気付きました。 トブト。 コンピュータにテキストがある場合、それはバイトのセットになります。スキンエンコーディングには、テキスト自体の1文字が含まれます。
画面にテキストを表示するプログラム(テキストエディタ、ブラウザなど)は、コードを解析するときに、黒文字のエンコーディングを読み取り、必要なフォントファイルで正しいベクトル形式を検索します。与えられたテキストドキュメント。 すべてがとても陳腐です。
したがって、必要な文字をエンコードするために(たとえば、国のアルファベットから)、vikonanoの2つの心しかできません-この文字のベクトル形式は、エンコードされるフォントに責任があり、この文字はでエンコードできます1バイトの拡張ASCIIエンコーディング。 そのため、このようなオプションが不可欠です。 拡張されたAskaのロシア語の元のkilkaの記号のコーディングのみ。
たとえば、穂軸に現れました CP866、ある意味で、ロシア語のアルファベットの記号とASCIIの拡張バージョンを勝利させることができました。
トブト。 її上部は、ホバーされた3つのスクリーンショットに表示されているため、Askaの基本バージョン(ラテン語で128文字、数字、その他のがらくた)と一致しており、軸はすでにCP866コードを含むテーブルの下部にあります。標識(ロシア語の文字とそこにあるあらゆる種類の疑似グラフィック):

バカイト、右側では、数字は8で始まります。 0から7までの数字は、ASCIIベース部分の前に表示されます(div。最初のスクリーンショット)。 含む CP866数学コード9Cのロシア語の文字「M」(9の2行と16番目の記数法の数字Cの網膜にあります)。これは1バイトの情報で書くことができますが、二重の明確さのためです。テキストに問題なく表示されるロシア文字のフォント。
音はそのような量から来ました CP866の疑似グラフィック? ここで、現在のようにグラフィックオペレーティングシステムが拡張されている場合、ロシア語のテキストのコーディングがさらに揮発的に拡張されていることは注目に値します。 Dosiでは、テキスト操作と同様に、疑似グラフィックによってわずかに泌尿器科のテキストのデザインが可能になり、CP866および同じ年齢の他のすべての人がAskの拡張バージョンのカテゴリから除外されました。
CP866はIBMによって開発されましたが、ロシア語の記号の場合、たとえば、同じタイプ(ASCII拡張)まで多くのコードも拡張されました。 KOI8-R:

їїrobotiの原理は、CP866によって以前に説明されたものと同じものが残されました。テキストのスキン文字は1バイトでエンコードされます。 スクリーンショットは、KOI8-Rテーブルの別の半分を示しています。 この記事の最初のスクリーンショットに示されているように、前半の前半は基本的なAskに基づいています。
KOI8-Rコーディングの機能の中で、たとえばCP866が作成されたため、この表のロシア語の文字はアルファベット順ではないことに注意してください。
最初のスクリーンショット(基本部分、すべての拡張コーディングの入力方法)を見ると、KOI8-Rではロシア語の文字が表の同じ中央に並べ替えられており、ラテンアルファベットの文字が表の最初の部分。 合計1ビート(7番目のステップで2つ、つまり128)を与えるために、ロシアのシンボルからラテンの方法への移行を明確にするために全体が分割されました。
Windows1251-ASCIIの現在のバージョン
テキストのコードがさらに発展したのは、グラフィック操作システムの人気が高まっていたためであり、すぐにそれらのシステムで疑似グラフィックを使用する必要が生じました。 その結果、グループの名前は、それ自体のストーリーと同様に、以前と同様に、Askの拡張バージョン(テキスト内の1文字は複数のバイトの情報によってエンコードされます)になりましたが、疑似グラフィックでは記号を使用していませんでした。
悪臭は、米国規格協会によって分割された、いわゆるANSIコードに依存していました。 キリル文字の名前も、ロシア語のサポートを受けてバリアントに選択されました。 この例としては、butiがあります。
Вона вигідно відрізнялася від використовуваних раніше CP866 і KOI8-R тим, що місце символів псевдографіки в ній зайняли символи російської типографіки (крім знака наголосу), а також символи, що використовуються в близьких до російської слов'янських мовах (українській, білоруській і т. d。)。 ):

そのような多様性を通して、フォントの種類と種類の間でのロシア語のコーディング ソフトウェア絶えず頭を非難しました、そして私たちと一緒に、あなたの中で、shovnіchitachі、あなたはしばしばあなた自身の惨めなものをぶらぶらしました krakozyabri、テキストで勝利しているバージョンに迷いがあった場合。
さらに頻繁に、悪臭は圧倒的でオトリマンニを思い出させてたむろしました Eメール、かなり折りたたまれた記録テーブルの作成を引き起こしました、yakі、vlasne、virishiti tsyu問題は基本的にできませんでした、そしてしばしばvikoristovuvaliをリストするためのkoristuvannya、vikoristannіrosіyskihkoduvanipodіbnihCP866でschobnut不幸なkrakozyabrіv、そうでなければ。
実際のところ、ロシア語のテキストを置き換えることになっていたkrakozyabryは、特定の言語の誤ったコーディングの結果であり、そのように聞こえなかったため、コーディングされていました。 テキストメッセージ穂軸自体のように。
CP866の助けを借りてエンコードされた記号が、Windows 1251コードテーブルを模倣しようとするか、または走り書き(ばかげた文字を入力)して悪意を持って通知のテキストをそれ自体に置き換えようとするかのように、許容されます。

同様の状況は、ロシアの恩赦文字を含むテキストがロックのサイトにあるため、間違ったコーディングで使用されている場合、フォーラムやブログで非難されることがよくあります。そうでない場合は、 テキストエディタ、これは、目に見えない目には見えないコードにコードを追加します。
絶えず登る非人称のcoduvansとkrakozyabryのような状況は、豊かなnabridlaであり、新しい普遍的なバリエーションを作成する前に、テキストのルートですべてをそれ自体とvirishila b、nareshtに置き換えるかのように考えを変えるように見えました問題 中国語に似た言語の問題はクリミアに基づいていましたが、言語の記号はより豊かで、256より低くなりました。
Unicode(Unicode)-ユニバーサルエンコーディングUTF 8、16、および32
pvdenno-shidnoy Asiaの現代グループの何千もの文字は、ASCIIの拡張バージョンで文字をコーディングするために見られた1バイトの情報では記述できませんでした。 その結果、コンソーシアムが名前で作成されました Unicode(Unicode-Unicodeコンソーシアム)IT業界のリーダー(ソフトウェアの開発、コードのエンコード、フォントの作成)の豊富な機能を備えており、テキストのユニバーサルコーディングの登場によって求められていました。 。
ユニコードコンソーシアムの下で導入された最初のバリエーションはbulaでした UTF-32。 コーディングのヘッダーにある数字は、1文字をエンコードするのに必要なビット数を意味します。 32ビットは、新しいユニバーサルUTFエンコーディングで1つの文字をエンコードするために必要な最大4バイトの情報を追加します。
その結果、ASCIIの拡張バージョンとUTF-32でのテキスト、エンコーディングを含む同じファイル、残りの場合、拡張(重要度)は4倍になります。 それは悪いことですが、PTFの助けを借りて、他の30ステップで2つより高価な標識の数をエンコードする機会があります( 数十億のシンボル、ヤクpokriyut be-yak巨大な予備から本当に必要な値)。
しかし、ヨーロッパのグループの言語を使用している国では、このような膨大な数の文字がコードにエンコードされているため、必要ありませんでしたが、UTF-32が設定されたとき、悪臭は無意味ではありませんでした テキストドキュメント、その結果、インターネットトラフィックの量とデータの節約量を増やします。 これは金持ちであり、そのようなお金の無駄は誰にも許されませんでした。
Unicodeの開発が登場した後 UTF-16、遠くにあるYakavyyshlanastіlki、私たちvikoristovuyutsyaのように、すべてのシンボルの基本的な広がりとしてumovchannyamのためにとられたschobula。 1文字をコーディングするための2バイトがあります。 私たちがどのように見えるのか疑問に思いましょう。
Windowsオペレーティングシステムでは、「スタート」-「プログラム」-「アクセサリ」-「サービス」-「シンボルテーブル」のパスをたどることができます。 その結果、システムにインストールされているすべてのフォントシステムのベクトル形式を含むテーブルが表示されます。 あなたが取り入れることになるヤクシュチョ 追加のパラメータ»Unicode文字を入力すると、新しい文字まで、文字の全範囲にスキンフォントを使用できます。
スピーチの前に、彼らがそうであるかどうかをクリックして、あなたは2バイトのyogoを歌うことができます UTF-16フォーマットコード、14の16桁で合計されるもの:

16ビットを使用してUTF-16でエンコードできる文字数はいくつですか? 65536(16のステップで2つ)、および数値自体がUnicodeのベーススペースとして使用されました。 Krіmtsgogoは、彼女を助けるためにエンコードする方法と、2つのmilyonіvznіkіvに近いものをエンコードする方法であり、テキスト内の拡張された拡張シンボルである可能性があります。
遠く離れたAlenavittsyaのUnicodeコーディングバージョンは、たとえば、 英語、Bo stink、ASCIIの拡張バージョンからUTF-16に移行した後、多くのドキュメントが2倍になりました(Asciでは1文字に1バイト、UTF-16では同じ文字に2バイト)。
ユニコードコンソーシアムのすべての人とすべての人の満足のために、 人生の変化のコーディング。 ЇїはUTF-8という名前です。 名前のPoprivіsіmkuは、mіnnudovzhina、tobtoではありません。 テキストのスキン文字は、最大6バイトの長さのシーケンスでエンコードできます。
実際には、UTF-8の範囲は1〜4バイトしかないため、数バイトのコードで何かを明らかにすることは理論的に不可能です。 その中のすべてのラテン文字は、古き良きASCIIと同じように、1バイトでエンコードされます。
注目に値するのは、コーディングの時代にはラテン語よりも少ないので、それらのプログラムをnavitし、Unicodeを理解していない場合は、すべて同じように、UTF-8でエンコードされたプログラムを読んでください。 トブト。 Askaのベース部分は、ユニコードコンソーシアムの発案によるものです。
UTF-8のキリル文字は2バイトでエンコードされ、たとえば、グルジア文字は3バイトでエンコードされます。 UTF 16および8の作成後のユニコードコンソーシアムが主な問題を解決しました-現在、 フォントには単一のコードスペースがあります。 そして今、彼らの筆記者は、テキスト内の記号のベクトル形式を埋める彼ら自身の強さと能力しか残されていません。 すぐにNavit。
「記号の表」の上にカーソルを合わせると、さまざまなフォントが文字数を強調していることがわかります。 Unicodeフォントの文字の多くは、きちんとさえ重要になる可能性があります。 しかし、今では悪臭は彼らによって考慮されておらず、異なるコーディングのために作成されていますが、タイプライターがフォントを入力したか、単一のコードスペースにこれらや他のベクトル形式を最後まで入力したかどうかを入力します。
ロシアの手紙のKrakozyabri副。
ここで、それらがkrakozyabriのテキストをどのように置き換えることになっているのか、そうでない場合は、ロシア語のテキストの正しいコーディングをどのように選択するのかを考えてみましょう。 それはそのプログラムで設定されており、テキスト自体を編集するか、さまざまなテキストフラグメントのコードを作成します。
その折り目を編集するため テキストファイル私の意見では、私は特にバイコリストが得意です。 Vіm、vіnは、何百ものプログラミングとレイアウトの構文を変更することができ、追加のプラグインのために拡張する可能性もあります。 読んだ レポートレビュー誘導されたメッセージからの奇跡的なプログラム。
メモ帳++のトップメニューには「コーディング」という項目があり、サイトでロック用に機能しているオプションの既存のオプションを変更できます。

Joomla 1.5以降のサイト、およびWordPressのブログの場合は、ショートカットの外観に従ってオプションを選択してください。 BOMなしのUTF8。 プレフィックスBOMとは何ですか?
右側では、UTF-16コーディングが壊れている場合、直接シーケンス(たとえば、0A15)のようにシンボルにコードを書き込むことができるため、そのようなフレーズをねじ込みました。 (150A)。 そして、プログラムが理解するために、順番にコードを読み、思い付くために BOM(バイトオーダーマーク、つまり署名)、ドキュメントの穂軸に3バイトを追加することで明らかになります。
UTF-8エンコーディングでは、BOMはUnicodeコンソーシアムに転送されませんでした。それに、そのようなプログラムに署名(ドキュメントの穂軸にある最高の3バイト)を追加するだけで、コードを読む価値があります。 したがって、UTFにファイルを保存するために、BOMなし(署名なし)のオプションを選択するのはユーザーの責任です。 このランクでは、あなたは遠くにいます krakozyabrivの形で身を守る.
同じ惨めなWindowsのメモ帳など、Windowsの一部のプログラムがこの作業を実行できない(BOMなしでUTF-8からテキストを保存できない)ことは注目に値します。 VіnはUTF-8からドキュメントを取得しますが、すべて同じように、穂軸に署名(3バイト追加)が追加されます。 さらに、これらのバイトは永久に同じになります—コードを直接シーケンスで読み取ります。 tsyudrіbnitsyuを介してサーバー上のエールは問題を非難することができます-vilіzukrakozyabri。
だからいつでも 素晴らしいWindowsのメモ帳にだまされないでくださいあなたのサイトの文書を編集するために、あなたは不正確さの出現を気にしません。 最高と最高 シンプルなオプションまた、Notepad ++エディターも使用しています。これは、実際には多くの欠点がなく、いくつかの利点で構成されています。
メモ帳++を使用すると、エンコーディングを選択するときに、テキストをUCS-2エンコーディングに変換できます。これは、本質的にUnicode標準に近いものです。 メモ帳はANSIでテキストをエンコードすることもできます。 100%ロシア語は、Windows 1251の3倍の量で説明されます。何か情報はありますか?
ボーンはあなたの手術室のレジスターに登録されています Windowsシステム-ANSIコードのコーディングの選択方法、OEMコードの選択方法(ロシア映画の場合はCP866になります)。 ロックのためにコンピューターに別の言語をインストールすると、コーディングは自分の言語の同じANSIまたはOEMコードに置き換えられます。
さらに、必要なコードからNotepad ++でドキュメントを保存するか、編集のためにサイトからドキュメントを開く場合は、エディターの右下隅に次の名前を追加できます。
Shchob niknut krakozyabriv、上記の説明を除いて、サーバーまたはローカルホストが詐欺師のせいにならないように、サイトのすべての側の出力コードのヘッダーにコーディング自体に関する情報を書き込むのが正しいでしょう。
Vzagali、ハイパーテキストレイアウトのすべてのmovs、Html cremeには、テキストコーディングが示されている特別に音声化されたxmlがあります。
まず、コードを分析すると、ブラウザは、使用されている勝利者のバージョンと、映画の登場人物のコードをどのように解釈する必要があるかを認識します。 ただし、デフォルトのUnicodeからドキュメントを保存する場合は、xmlのあいまいさを省略できます(エンコーディングは、BOMがないことを意味するUTF-8またはBOMєを意味するUTF-16になります)。
文書の時点で 映画のHTMLコーディングをエンコードする メタ要素、カーブして閉じるHeadタグの間に書き込まれます。
... ...
このエントリは、で採用されたとおりに強くレビューされますが、徐々に導入されている新しいHtml 5標準に再送信し、現在勝利しているブラウザによって正しく理解されます。
アイデアとして、ドキュメントのHtmlエンコーディングのMeta要素は短くなります ヤコモガはドキュメントヘッダーの上位にあります、そのため、最初の文字のテキストを書いている時点では、基本のANSI(常に正しく、どのようなバリエーションでも正しく読み取られます)ではないため、ブラウザーは、これらの文字のコードを解釈する方法に関する母親の情報に罪を犯します。
頑張って! ブログサイトの側面でzustrіchesを速くするために
あなたはtsikavoをbutiすることができます
 サイトのメッセージの絶対的な有効性を決定するURLアドレスは何ですか
サイトのメッセージの絶対的な有効性を決定するURLアドレスは何ですか  OpenServer-現在 ローカルサーバーコンピューターにWordPressをインストールするためのこのヨガウィキアプリケーション
OpenServer-現在 ローカルサーバーコンピューターにWordPressをインストールするためのこのヨガウィキアプリケーション  Chmodはどうですか、ファイルとフォルダ(777、755、666)およびPHPを介してアクセス権を割り当てる方法
Chmodはどうですか、ファイルとフォルダ(777、755、666)およびPHPを介してアクセス権を割り当てる方法  Yandexがサイトとオンラインストアを検索
Yandexがサイトとオンラインストアを検索
コーディングKOI8-R
ISO8859-5コーディング
ISO 8859-5
代替コーディング
「代替コーディング」-CP437コード側に基づいて、残りの半分のすべての特定のヨーロッパ文字はキリル文字に置き換えられ、疑似グラフィック文字は未使用のままになります。 また、ロボットテキストの勝利を収めるプログラムを確認する必要はなく、キリル文字の勝利を確実にする必要もありません。
歴史的に、代替コーディングには多くのオプションがありましたが、他のすべての機能は領域0xF0〜0xFF(240〜255)に制限されています。 残りの標準は、MS-DOSバージョン6.22で導入されたIBMCP866コーディングでした。 ファイルシステム太い。 WindowsNTファミリのロシア化システムのコンソールにあるCP866dosivikoristovuetsya。
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
| 8. | 410 | B 411 | 412 | G 413 | D 414 | E 415 | F 416 | W 417 | I 418 | Y 419 | 41Aまで | L 41B | M 41C | H 41D | Pro 41E | P 41F |
| 9. | R 420 | Z 421 | T 422 | 423 | F 424 | X 425 | C 426 | Ch 427 | SH 428 | Shch 429 | b 42A | S 42B | b 42c | E 42D | P 42E | 私は42Fです |
| A。 | 430 | b 431 | 432 | g 433 | d 434 | e 435 | f 436 | s 437 | その438 | 439 | 43Aまで | l 43B | m 43C | n 43D | プロ43E | n 43F |
| b。 | ░ 2591 | ▒ 2592 | ▓ 2593 | │ 2502 | ┤ 2524 | ╡ 2561 | ╢ 2562 | ╖ 2556 | ╕ 2555 | ╣ 2563 | ║ 2551 | ╗ 2557 | No.255D | ╜255C | ╛255B | ┐ 2510 |
| C。 | └ 2514 | ┴2534 | ┬252C | ├251C | ─ 2500 | ┼253C | No.255E | ╟255F | ╚255A | ╔ 2554 | ╩ 2569 | ╦ 2566 | ╠ 2560 | ═ 2550 | ╬256C | ╧ 2567 |
| D。 | ╨ 2568 | ╤ 2564 | ╥ 2565 | ╙ 2559 | ╘ 2558 | ╒ 2552 | ╓ 2553 | No.256B | No.256A | ┘ 2518 | ┌250C | █ 2588 | ▄ 2584 | ▌258C | ▐ 2590 | ▀ 2580 |
| E。 | p 440 | s 441 | t 442 | 443で | f 444 | x 445 | c 446 | 447年 | sh 448 | w 449 | b 44A | 44B | b 44C | e 44D | ゆう44E | i 44F |
| F。 | E 401 | e 451 | Є404 | 454ドル | £407 | 457 | 40Eで | 45Eで | °B0 | ∙ 2219 | B7 | √221A | № 2116 | ¤A4 | ■25A0 | A0 |
SO 8859-5-キリル文字を書き込むためのISO-8859シリーズの8ビットエンコーディング。 ロシアでは、Mayzheは慣れていません。 一般に、ISO 8859-5は単純なコーディングにすぎず、新しい日のシャードには、ダッシュ(-)、足-ヤリンカ( "")、度(°)などの必要な記号が豊富に含まれています。
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
| 8. | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 8A | 8B | 8C | 8D | 8E | 8F |
| 9. | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 9A | 9B | 9C | 9D | 9E | 9F |
| A。 | A0 | E 401 | 402 | 403 | Є404 | 405 | I 406 | £407 | £408 | 409まで | M 40A | プロ40B | N40C | 広告 | 40Eで | P 40F |
| b。 | 410 | B 411 | 412 | G 413 | D 414 | E 415 | F 416 | W 417 | I 418 | Y 419 | 41Aまで | L 41B | M 41C | H 41D | Pro 41E | P 41F |
| C。 | R 420 | Z 421 | T 422 | 423 | F 424 | X 425 | C 426 | Ch 427 | SH 428 | Shch 429 | b 42A | S 42B | b 42c | E 42D | P 42E | 私は42Fです |
| D。 | 430 | b 431 | 432 | g 433 | d 434 | e 435 | f 436 | s 437 | その438 | 439 | 43Aまで | l 43B | m 43C | n 43D | プロ43E | n 43F |
| E。 | p 440 | s 441 | t 442 | 443で | f 444 | x 445 | c 446 | 447年 | sh 448 | w 449 | b 44A | 44B | b 44C | e 44D | ゆう44E | i 44F |
| F。 | № 2116 | e 451 | R 452 | -453 | 454ドル | * 455 | i 456 | 457 | 458ドル | 459 | 45A | ћ45B | ќ45C | §A7 | 45Eで | 私は45Fです |
KOI-8(情報交換コード、8ビット)、KOI8-コンピュータサイエンスのシンボルをコーディングするための8ビット標準。 キリル文字の文字をコーディングするために分類されました。 コーディングの7ビットバージョンであるKOI-7もあります。 KOI-7とKOI-8はGOST19768-74(今のところ)で説明されています。
KOI-8の小売業者は、キリル文字の記号の位置が表の下部にある英語のアルファベットの対応する音声に対応するように、拡張ASCIIテーブルの上部にロシア語のアルファベットの記号を配置しました。 Tseは、KOI-8で書かれたテキストで、スキンシンボルの8ビットを削除すると、ラテン文字で書きたい場合は「読み」のテキストが表示されることを意味します。 たとえば、「ロシア語のテキスト」という単語は「rUSSKIJtEKST」に変わりました。 ちなみに、キリル文字はアルファベット順に並べ替えられています。
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
| 8. | ─ 2500 | │ 2502 | ┌250C | ┐ 2510 | └ 2514 | ┘ 2518 | ├251C | ┤ 2524 | ┬252C | ┴2534 | ┼253C | ▀ 2580 | ▄ 2584 | █ 2588 | ▌258C | ▐ 2590 |
| 9. | ░ 2591 | ▒ 2592 | ▓ 2593 | ⌠ 2320 | ■25A0 | ∙ 2219 | √221A | ≈ 2248 | ≤ 2264 | ≥ 2265 | A0 | ⌡ 2321 | °B0 | ²B2 | B7 | ÷F7 |
| A。 | ═ 2550 | ║ 2551 | ╒ 2552 | e 451 | ╓ 2553 | ╔ 2554 | ╕ 2555 | ╖ 2556 | ╗ 2557 | ╘ 2558 | ╙ 2559 | ╚255A | ╛255B | ╜255C | No.255D | No.255E |
| b。 | ╟255F | ╠ 2560 | ╡ 2561 | E 401 | ╢ 2562 | ╣ 2563 | ╤ 2564 | ╥ 2565 | ╦ 2566 | ╧ 2567 | ╨ 2568 | ╩ 2569 | No.256A | No.256B | ╬256C | ©A9 |
| C。 | ゆう44E | 430 | b 431 | c 446 | d 434 | e 435 | f 444 | g 433 | x 445 | その438 | 439 | 43Aまで | l 43B | m 43C | n 43D | プロ43E |
| D。 | n 43F | i 44F | p 440 | s 441 | t 442 | 443で | f 436 | 432 | b 44C | 44B | s 437 | sh 448 | e 44D | w 449 | 447年 | b 44A |
| E。 | P 42E | 410 | B 411 | C 426 | D 414 | E 415 | F 424 | G 413 | X 425 | I 418 | Y 419 | 41Aまで | L 41B | M 41C | H 41D | Pro 41E |
| F。 | P 41F | 私は42Fです | R 420 | Z 421 | T 422 | 423 | F 416 | 412 | b 42c | S 42B | W 417 | SH 428 | E 42D | Shch 429 | Ch 427 | b 42A |
コーディングKOI8-U(ウクライナ語)
KOI-8は、インターネット上で最初のロシアの標準化されたコーディングになりました。
IETFは、KOI-8エンコーディングオプションのRFCを承認しました。
- RFC 1489-KOI8-R(ロシア語のアルファベットの文字);
- RFC 2319-KOI8-U(ウクライナ語のアルファベットの文字);
- RFC 1345-ISO-IR-111(メイン範囲の指定はご容赦ください)。
ホバーテーブルでは、文字の下の数字はUnicodeの文字の16番目のコードを示します。
コーディングKOI8-R(ロシア語)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
─
2500 |
│
2502 |
┌
250C |
┐
2510 |
└
2514 |
┘
2518 |
├
251C |
┤
2524 |
┬
252C |
┴
2534 |
┼
253C |
▀
2580 |
▄
2584 |
█
2588 |
▌
258C |
▐
2590 |
| 9. |
░
2591 |
▒
2592 |
▓
2593 |
⌠
2320 |
■
25A0 |
∙
2219 |
√
221A |
≈
2248 |
≤
2264 |
≥
2265 |
A0 |
⌡
2321 |
°
B0 |
²
B2 |
·
B7 |
÷
F7 |
| A。 |
═
2550 |
║
2551 |
╒
2552 |
e 451 |
╓
2553 |
╔
2554 |
╕
2555 |
╖
2556 |
╗
2557 |
╘
2558 |
╙
2559 |
╚
255A |
╛
255B |
╜
255C |
╝
255D |
╞
255E |
| b。 |
╟
255F |
╠
2560 |
╡
2561 |
ヨ 401 |
╢
2562 |
╣
2563 |
╤
2564 |
╥
2565 |
╦
2566 |
╧
2567 |
╨
2568 |
╩
2569 |
╪
256A |
╫
256B |
╬
256C |
©
A9 |
| C。 |
ゆう 44E |
a 430 |
b 431 |
c 446 |
d 434 |
e 435 |
f 444 |
G 433 |
バツ 445 |
і 438 |
th 439 |
前 43A |
l 43B |
m 43C |
n 43D |
約 43E |
| D。 |
P 43F |
私 44F |
R 440 |
h 441 |
t 442 |
で 443 |
と 436 |
の 432 |
b 44C |
s 44B |
h 437 |
sh 448 |
e 44D |
sch 449 |
年 447 |
b 44A |
| E。 |
YU 42E |
しかし 410 |
B 411 |
C 426 |
D 414 |
E 415 |
F 424 |
G 413 |
バツ 425 |
І 418 |
Y 419 |
前 41A |
L 41B |
M 41C |
H 41D |
プロ 41E |
| F。 |
P 41F |
私 42F |
R 420 |
W 421 |
T 422 |
で 423 |
と 416 |
で 412 |
b 42C |
S 42B |
W 417 |
W 428 |
E 42D |
SCH 429 |
H 427 |
コメルサント 42A |
その他のオプション
実行されないテーブルの行のみが表示され、シャードは引き続き実行されます。
コーディングKOI8-U(ロシア語-ウクライナ語)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A。 |
═
2550 |
║
2551 |
╒
2552 |
e 451 |
є
454 |
╔
2554 |
і
456 |
ї
457 |
╗
2557 |
╘
2558 |
╙
2559 |
╚
255A |
╛
255B |
ґ
491 |
╝
255D |
╞
255E |
| b。 |
╟
255F |
╠
2560 |
╡
2561 |
ヨ 401 |
Є
404 |
╣
2563 |
І
406 |
Ї
407 |
╦
2566 |
╧
2567 |
╨
2568 |
╩
2569 |
╪
256A |
Ґ
490 |
╬
256C |
©
A9 |
コーディングKOI8-RU(ロシア語-ベラルーシ語-ウクライナ語)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A。 |
═
2550 |
║
2551 |
╒
2552 |
e 451 |
є
454 |
╔
2554 |
і
456 |
ї
457 |
╗
2557 |
╘
2558 |
╙
2559 |
╚
255A |
╛
255B |
ґ
491 |
ў
45E |
╞
255E |
| b。 |
╟
255F |
╠
2560 |
╡
2561 |
ヨ 401 |
Є
404 |
╣
2563 |
І
406 |
Ї
407 |
╦
2566 |
╧
2567 |
╨
2568 |
╩
2569 |
╪
256A |
Ґ
490 |
Ў
40E |
©
A9 |
コードKOI8-C(中央アジア)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | ғ 493 |
җ 497 |
қ 49B |
ҝ 49D |
ң 4A3 |
ү 4AF |
ұ 4B1 |
ҳ 4B3 |
ҷ 4B7 |
ҹ 4B9 |
һ 4BB |
▀ 2580 |
ә 4D9 |
ӣ 4E3 |
ө 4E9 |
ӯ 4EF |
| 9. | Ғ 492 |
Җ 496 |
Қ 49A |
Ҝ 49C |
Ң 4A2 |
Ү 4AE |
Ұ 4B0 |
Ҳ 4B2 |
Ҷ 4B6 |
Ҹ 4B8 |
Һ 4BA |
⌡ 2321 |
Ә 4D8 |
Ӣ 4E2 |
Ө 4E8 |
Ӯ 4EE |
| A。 | A0 |
ђ 452 |
ѓ 453 |
e 451 |
є 454 |
ѕ 455 |
і 456 |
ї 457 |
ј 458 |
љ 459 |
њ 45A |
ћ 45B |
ќ 45C |
ґ 491 |
ў 45E |
џ 45F |
| b。 | № 2116 |
Ђ 402 |
Ѓ 403 |
ヨ 401 |
Є 404 |
Ѕ 405 |
І 406 |
Ї 407 |
Ј 408 |
Љ 409 |
Њ 40A |
Ћ 40B |
Ќ 40C |
Ґ 490 |
Ў 40E |
Џ 40F |
コーディングKOI8-T(タジク語)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. | қ 49B |
ғ 493 |
‚ 201A |
Ғ 492 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
‰ 2030 |
ҳ 4B3 |
‹ 2039 |
Ҳ 4B2 |
ҷ 4B7 |
Ҷ 4B6 |
||
| 9. | Қ 49A |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
2022 |
– 2013 |
- 2014 |
™ 2122 |
› 203A |
||||||
| A。 | ӯ 4EF |
Ӯ 4EE |
e 451 |
¤ A4 |
ӣ 4E3 |
¦ A6 |
§ A7 |
« AB |
¬ 交流 |
広告 |
® AE |
|||||
| b。 | ° B0 |
± B1 |
² B2 |
ヨ 401 |
Ӣ 4E2 |
¶ B6 |
· B7 |
№ 2116 |
» BB |
© A9 |
コーディングKOI8-O、KOI8-S(slovyanska、古いスペル)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ
0402 |
Ѓ
0403 |
¸
00B8 |
ѓ
0453 |
„
201E |
…
2026 |
†
2020 |
§
00A7 |
€
20AC |
¨
00A8 |
Љ
0409 |
‹
2039 |
Њ
040A |
Ќ
040C |
Ћ
040B |
Џ
040F |
| 9. |
ђ
0452 |
‘
2018 |
’
2019 |
“
201C |
”
201D |
2022 |
–
2013 |
—
2014 |
£
00A3 |
·
00B7 |
љ
0459 |
›
203A |
њ
045A |
ќ
045C |
ћ
045B |
џ
045F |
| A。 |
00A0 |
ѵ
0475 |
ѣ
0463 |
e 0451 |
є
0454 |
ѕ
0455 |
і
0456 |
ї
0457 |
ј
0458 |
®
00AE |
™
2122 |
«
00AB |
ѳ
0473 |
ґ
0491 |
ў
045E |
´
00B4 |
| b。 |
°
00B0 |
Ѵ
0474 |
Ѣ
0462 |
ヨ 0401 |
Є
0404 |
Ѕ
0405 |
І
0406 |
Ї
0407 |
Ј
0408 |
№
2116 |
¢
00A2 |
»
00BB |
Ѳ
0472 |
Ґ
0490 |
Ў
040E |
©
00A9 |
コーディングISO-IR-111、KOI8-E
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A。 |
00A0 |
ђ
0452 |
ѓ
0453 |
e 0451 |
є
0454 |
ѕ
0455 |
і
0456 |
ї
0457 |
ј
0458 |
љ
0459 |
њ
045A |
ћ
045B |
ќ
045C |
00AD |
ў
045E |
џ
045F |
| b。 |
№
2116 |
Ђ
0402 |
Ѓ
0403 |
ヨ 0401 |
Є
0404 |
Ѕ
0405 |
І
0406 |
Ї
0407 |
Ј
0408 |
Љ
0409 |
Њ
040A |
Ћ
040B |
Ќ
040C |
¤
00A4 |
Ў
040E |
Џ
040F |
コーディングKOI8-統合、KOI8-F
KOI8-統合(KOI8-F)コーディングは、FingertipSoftwareによって伝播されます。
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
─
2500 |
│
2502 |
┌
250C |
┐
2510 |
└
2514 |
┘
2518 |
├
251C |
┤
2524 |
┬
252C |
┴
2534 |
┼
253C |
▀
2580 |
▄
2584 |
█
2588 |
▌
258C |
▐
2590 |
| 9. |
░
2591 |
‘
2018 |
’
2019 |
“
201C |
”
201D |
2022 |
–
2013 |
—
2014 |
©
00A9 |
™
2122 |
00A0 |
»
00BB |
®
00AE |
«
00AB |
·
00B7 |
¤
00A4 |
| A。 |
00A0 |
ђ
0452 |
ѓ
0453 |
e 0451 |
є
0454 |
ѕ
0455 |
і
0456 |
ї
0457 |
ј
0458 |
љ
0459 |
њ
045A |
ћ
045B |
ќ
045C |
ґ
0491 |
ў
045E |
џ
045F |
| b。 |
№
2116 |
Ђ
0402 |
Ѓ
0403 |
ヨ 0401 |
Є
0404 |
Ѕ
0405 |
І
0406 |
Ї
0407 |
Ј
0408 |
Љ
0409 |
Њ
040A |
Ћ
040B |
Ќ
040C |
Ґ
0490 |
Ў
040E |
Џ
040F |
KOI-8の非キリル文字バリアント
REVの一部の国では、ラテン語の国内版用にKOI-8の変更が作成されました。 基本的な考え方は同じでした。8番目のビットが「zip形式」になっていると、テキストは多かれ少なかれ理解できるという罪を犯します。
-さて、始めましょう! -ドーロホフと言います。
-ええと-P'єrと言ったら、あなたはそのように笑います。 -怖かったです。 右側にあり、簡単に始められたのは明らかでしたが、何も救うことができず、すでに人々の意志から独立していて、それだけでは十分ではありませんでした。 デニソフは、bar'eruと声の前の最初のviyshov:
--Oskіlkiの対戦相手が邪魔にならないように移動したので、始めるのは良くありません。ピストルを持って一言で言えば、収束し始めます。
--G ... "az!Two!T" i! ...-怒ってDenisovとvіdіyshovubіkを叫びます。 不快なことに、彼らは、霧の中でお互いを知って、踏みつけられた道をどんどん近づいていきました。 対戦相手はマリの権利を持ち、必要に応じて、bar'eruに行き、撃ちます。 ドーロホフは、ピストルを持ち上げることなく、敵を装って明るく輝く黒い目に驚かされました。 夢のように、ヨゴの口は笑いのように自分で大騒ぎします。
-それなら私が望むなら-私は撃つことができます! -P'єrと言ったが、その言葉で、3つの派手なクロックムッシュが前にピショフし、踏みつけられた小道と雪の雪から急いでいた。 P'єrはピストルをトリマブし、右手で前に引っ張って、おそらく、ピストルのビジネスが自分自身に当たらないことを恐れています。 右手を持ち上げたかったので、Vinの左手を熱心に戻し、Vinができないことを知りました。 丘を通り過ぎ、雪の中へと小道を駆け下りると、ペールは足元を見回し、再びドーロホフを鋭く見つめ、ヨーゴのように指を引っ張った。 そのような強い音に反応することなく、P'erは彼のショットに身震いし、それから彼自身の敗北にニヤリと笑い、唸りました。 薄暗い、特に霧の中で濃い、pershameteのzadavayyoma bachiti; でも、ワインチェックのようなものは何も撮りませんでした。 ほんの少しだけドーロホフの子供たちを泣かせていました、そしてディマのためにポストするようになりました。 片方の手でレビのくちばしに震え、もう片方の手でピストルを絞った。 ヨガの装いは曇っていた。 ロストフpіdbіg私はあなたに言っているschos。
-いいえ...e... t、-ドロキフは歯を磨きました-いいえ、皮を剥がれていません-そして、彼女の雪の上に落ちて、まさにテンプレートに岩をシャントし、落下のスプラットをさらにかき回しました。 ヨーゴの左手は血にまみれていて、彼はシュールダットでワインを拭いて隠した。 ヨガの見た目は青白く、暗く、震えていました。
--Mabut ... --pochav Dolohov、しかし思い出す瞬間ではありません...-親切にしてください、住居のvinzzusillyam。 P'єrは、少なくとも乗り心地を楽にして、ドーロホフに走りました、そしてすでにドーロホフのように叫んで、バー'єriを構築する広がりを越えたいと思っていました:-バー'єruに! -そして、スピーチが何であるかを理解したP'єrは、彼のテンプレートのzupinivsya白。 10krokiv未満がそれらを取りました。 ドーロホフは頭を雪に降ろし、貪欲に雪を味わい、再び頭を持ち上げ、撫で、足を持ち上げ、そして重心を上げた。 鍛造された冷たい雪とsmoktavヨガ; ヨガのトレムティリを破壊しますが、誰もが笑います。 目は残りの選ばれた力のズシリスと悪意で輝いていました。 Vіnpіdnyavpіstolet私はcіlityになります。
「横に、ピストルで身を閉じてください」とネスビツキーは言いました。
-3ak「待って!」-見せびらかすことなく、デニソフに相手に叫びました。
陰険な笑みを浮かべて、私は後悔して悔い改め、恥知らずに彼の足と腕を広げ、ドーロホフの前で彼の広い胸をまっすぐに立て、新しいものに驚嘆しました。 デニソフ、ロストフ、ネスビツキーは結婚しました。 すぐに悪臭が感じられ、ドーロホフの怒りの叫びが聞こえました。
- 過去! -ドーロホフを叫び、どうしようもなく雪の上に横たわりました。 P'єrは頭の後ろに群がり、振り返って、キツネをピショフし、たくさんの雪で鳴き、不当な言葉を言った。
-愚かな...愚かな! 死…でたらめ…–しかめっ面を続ける。 NesvitskyZupinyヨガとpovіzの家。
ロストフはデニソフから負傷したドーロホフに連れて行かれた。
ドーロホフ、movchki、そりのそばに横たわり、食べ物に一言も言わずに、平らな目から、彼らは彼のように彼を奪った。 エールは、モスクワに行って、ラプトムを持ってあなたのところにやって来ました。そして、重要なことに、頭を上げて、ロストフを手に取って、あなたは自分でそこに座っていました。 ロストフは、ドーロホフの装いの下のビラズによって完全に変化し、持続不可能なほど窒息死したことに驚いた。
-まあ、何? どうやって自分を認識しますか? -ロストフに聞いた。
- これは悪いです! しかし、それほど金持ちではありません。 私の友人、-ドーロホフは声で言った、なぜあなたは邪魔をしているのですか、-デミ? 私たちはモスクワにいます、私は知っています。 私は何もありませんが、私はїїで運転しました、運転しました...私はそれに耐えることができません。 ボーンはそれを我慢できない...
- 誰? -ロストフに聞いた。
- 私の母。 私の母、私の天使、私の最愛の天使、母、-ドーロホフはロストフの手を握りしめながら泣きました。 少し落ち着いたら、ロストフに、母親と一緒に住んでいること、死にゆくのを助けるために母親として耐えられないことを説明しました。 彼女の前でロストフїhatiを祝福し、їїを準備します。
ロストフは、勝つために前もって行っていましたが、驚いたことに、ドーロホフ、ツェイ・バフーン、兄弟のドーロホフは、古い母親と背の低い妹、そして末っ子の息子と兄弟と一緒にモスクワで生きています。
残りの時間、私は従者のvech-na-vichでスパーリングをすることはめったにありませんでした。 Іサンクトペテルブルクとモスクワでは、budinokїkhzavzhdbvpovnyのゲスト。 ワインの決闘の後の次の夜は、しばしば臆病で、寝室には行かず、ベズヒ伯爵が亡くなったのとまったく同じ場所にある彼の荘厳な父の事務所にとどまりました。
ヴィンはソファに横になり、彼と一緒にいたすべてのものを忘れるために眠りに落ちたいと思ったが、ヴィンは少しも成長しなかった。 そのような感情、思考の嵐があなたの魂に激しく沈み、あなたはただ一瞬眠っただけでなく、床に座ってソファから集まってスウェーデンのかぎ針編みで部屋を歩き回ることさえしませんでした。 それから彼女は友情を持って彼に友情を持って現れ、肩を開いて、だらしなく偏った表情をし、すぐにハープを見て、ドーロホフの装いをあたかもそれが従順であるかのように生意気でしっかりと嘲笑するように指示しました。ドーロホフ、荒涼とした、トレムティアックの同じ装い。 それが振り返って雪に落ちたとき、いわば苦しみました。
"それが何だった? -自分にワインを頼む。 -私はコハントを運転したので、私のチームのコハントを殺しました。 そうでした。 何が見えますか? どうやって何に行くの? -彼女と友達になった方へ-内なる声が聞こえてきました。
「私は何の罪を犯していますか? -ワインを飲む。 -愛情のないїїと友達になった人、そのїїをだましていた人、そしてあなたにとって、そのhvilinaは、Vasil王子での夜の後に想像されました、彼が言葉を言った場合、彼らは出てこなかった:「Jevousaime」。 [私はあなたを愛しています。]すべて! 私はそれについて考えました、それについて考えました、私はそれについて考えました、それは私が権利を持っていないものではないということです。 そして、それは起こりました。」 幸運を祈って新婚旅行とchervonіvを推測します。 特に歯ごたえがあり、比喩的で嫌なことに、新しい友達にとっては、かつてのように、チームメートの後に問題なく、その日の12周年のワイン、寝室からオフィス、そして頭の頭の前哨基地は、まるで身をかがめて、P'erの装いに驚嘆し、彼のローブに驚嘆し、少し笑いながら、彼の校長のニビ・ヴィスロヴリュユチ・ツシユ・ニヤリ・シャノーブル・スヴィヴチュティアの幸福。
「そして、私はそれを何回書いたのか、素晴らしい美しさでそれを書いた、世俗的なタクト、ワインを考えた。 彼女がピーターズバーグのすべてを取り、その難攻不落の美しさで書いている彼女のブディンカで書いています。 だから私は何について書いているのですか?! わからないと思っただけです。 何度も、їїの性格について考えて、私は自分が罪を犯していること、私が理解していないこと、日常の落ち着き、満足、日常生活がバザンに例えられることを理解していなかったことを自分自身に示しました、そして全体の解決策はその中にありましたひどい言葉、彼女は無差別な女性だということ:あなた自身にひどい言葉を言った、そして誰もが理解した!
「アナトールは彼女の前に行き、ペニーで構え、裸の肩にキスをしました。 ボーンは彼にペニーを与えなかったが、彼自身にキスをすることを許した。 Batko、zhartom、zbudzhuvavїї嫉妬; 彼女は落ち着いた笑顔で、嫉妬するほど悪くはなかったと言いました。あなたが望むものを遠慮なく遠ざけてください、と彼女は私について言いました。 私はそれを急冷しました、chiはそれを虚栄心の兆候として見ていません。 ボーンは軽蔑して笑い、彼女はばかではない、子供を持つべきである、そして子供を母親にしないと言った。
それから私たちは、より大きな貴族の賭けに揺れることを尊重せずに、無礼、思考の明晰さ、そして強力なものであるvirazіvの卑劣さを推測しました。 「私は愚かではありません...自分で試してみてください...allezvouspromener」[入りなさい]と彼女は言った。 多くの場合、老若男女の目には成功に驚かされ、P'єrはなぜ彼がワインを好きではなかったのか理解できませんでした。 私は自分自身にP'єrを見せて、決してїїを愛していないこと。 彼女が自分の罪悪感を繰り返して、毅然とした女性であることを私は知っていましたが、私はそれを自分自身で見ませんでした。
今日はそれらについてあなたと話します、星はサイトとプログラムで省略形として取られます、テキストをエンコードする方法とそれらを追跡する方法。 基本的なASCIIから始まり、CP866、KOI8-R、Windows 1251の拡張バージョンで始まり、UnicodeコンソーシアムUTF 16および8の現在のエンコーディングで終わる、それらの開発の歴史について報告します。編集: 誰に家を訪ねることができますが、同じkrakozyabrivを養うために私がどれだけ多く来ることができるかを知っているでしょう(一連の記号を読まないでください)。 これで、すべての記事をテキストに書き留めて、自分のわき柱を独自に調べる機会があります。 さて、情報を拾い上げて、ニュースの広がりを追跡する準備をしてください。
ASCII-ラテン語の基本的なテキストエンコーディング
テキストのコーディングの開発はITギャラリーの成形からすぐに行われ、悪臭は1時間でchimalihの変更の認識を追い越しました。 歴史的に、すべてはEBCDICで始まりました。これは、ラテンアルファベットの文字、アラビア数字、および句読点をケルチ記号でコーディングできるため、ロシア語では甘く聞こえませんでした。 しかし、それでも、wartoでのテキストの現代的なコーディングの開発のための正しいポイントは有名です ASCII(ロシアの鉱山は「空」のように聞こえるので、情報交換のためのアメリカの標準コード)。 Vaughnは、最初の128の記号を、最も頻繁に書かれる英語の文字(ラテン文字、アラビア数字、さまざまな記号)で説明しています。 ASCIIで記述されたtsі128記号の詳細では、kshtaltアーチ、ґrat、zirochokにサービスシンボルのdeakを薄く使用していました。 Vlasne、あなた自身がїхїхすることができます: ASCII cobバリアントの128文字が標準になり、他の方法でそれらの言語でエンコードされているため、この順序で悪臭を放つ価値があります。 その右側のエールは、1バイトの情報の助けを借りて、128ではなく256の異なる値(最高で256に等しい2つ)をAskaの基本バージョンの背後にあるものにエンコードすることが可能です、行全体が表示されました ASCIIエンコーディング拡張、国のコーディングのシンボル(たとえば、ロシア語)のコードの128の基本的な記号を作成することが可能です。 ここでは、説明の中で勝利を収めている数の体系について、もう少しだけ言います。 そもそも、ご存知のように、コンピューターは2進法の数値でのみ動作し、それ自体は0と1で動作します(大学や学校に行ったかのように「ブール代数」)。 1バイトは8ビットで構成され、各ビットはゼロから始まり、somyで最大2つのステップで2を表します。
ASCII cobバリアントの128文字が標準になり、他の方法でそれらの言語でエンコードされているため、この順序で悪臭を放つ価値があります。 その右側のエールは、1バイトの情報の助けを借りて、128ではなく256の異なる値(最高で256に等しい2つ)をAskaの基本バージョンの背後にあるものにエンコードすることが可能です、行全体が表示されました ASCIIエンコーディング拡張、国のコーディングのシンボル(たとえば、ロシア語)のコードの128の基本的な記号を作成することが可能です。 ここでは、説明の中で勝利を収めている数の体系について、もう少しだけ言います。 そもそも、ご存知のように、コンピューターは2進法の数値でのみ動作し、それ自体は0と1で動作します(大学や学校に行ったかのように「ブール代数」)。 1バイトは8ビットで構成され、各ビットはゼロから始まり、somyで最大2つのステップで2を表します。  このような設計で可能な0と1のすべての組み合わせが256未満になる可能性があることを理解することは重要ではありません。2つのシステムから10番目のシステムに数値を変換するのは簡単です。 独立するために、2つのステップすべてを単純に折りたたむ必要があります。 私たちのお尻は1(ゼロステップで2)プラス8(3ステップで2)、プラス32(5番目のステップで2)、プラス64(6番目)、プラス128(6番目)で出てきます。 すぐに私は10番目の数体系から233を取ります。 ヤクバカイト、すべてが簡単です。 しかし、ASCII文字を使用してテーブルを見ると、それらが16のコーディングで表示されていることがわかります。 たとえば、「zіrochka」vіdpovіdaєAskі16番目の番号2A。 間違いなく、16番目のシステムには、アラビア数字に加えて勝利した数字があり、A(10を意味する)からF(15を意味する)までのラテン文字が多いことがわかります。 さて、軸、 2つの数値を16に変換する攻撃的なシンプルで科学的な方法へのvdayutsya。 上のスクリーンショットに示すように、情報のスキンバイトはビット数に応じて部分に分割されます。 含む バイトのスキンの半分では、2つのコードは16の値(4番目のステップでは2つ)のみをエンコードできます。これは、16の数値で簡単に明らかにできます。 さらに、バイトの左半分では、スクリーンショットに示されているようにではなく、ステップをゼロからリセットする必要があります。 その結果、簡単な計算で、スクリーンショットにE9という数字がエンコードされていることがわかります。 私の誤解とこのパズルの解決策はあなたにとって賢明であることがわかったと確信しています。 さて、さて、テキストのコーディングについて話しましょう。
このような設計で可能な0と1のすべての組み合わせが256未満になる可能性があることを理解することは重要ではありません。2つのシステムから10番目のシステムに数値を変換するのは簡単です。 独立するために、2つのステップすべてを単純に折りたたむ必要があります。 私たちのお尻は1(ゼロステップで2)プラス8(3ステップで2)、プラス32(5番目のステップで2)、プラス64(6番目)、プラス128(6番目)で出てきます。 すぐに私は10番目の数体系から233を取ります。 ヤクバカイト、すべてが簡単です。 しかし、ASCII文字を使用してテーブルを見ると、それらが16のコーディングで表示されていることがわかります。 たとえば、「zіrochka」vіdpovіdaєAskі16番目の番号2A。 間違いなく、16番目のシステムには、アラビア数字に加えて勝利した数字があり、A(10を意味する)からF(15を意味する)までのラテン文字が多いことがわかります。 さて、軸、 2つの数値を16に変換する攻撃的なシンプルで科学的な方法へのvdayutsya。 上のスクリーンショットに示すように、情報のスキンバイトはビット数に応じて部分に分割されます。 含む バイトのスキンの半分では、2つのコードは16の値(4番目のステップでは2つ)のみをエンコードできます。これは、16の数値で簡単に明らかにできます。 さらに、バイトの左半分では、スクリーンショットに示されているようにではなく、ステップをゼロからリセットする必要があります。 その結果、簡単な計算で、スクリーンショットにE9という数字がエンコードされていることがわかります。 私の誤解とこのパズルの解決策はあなたにとって賢明であることがわかったと確信しています。 さて、さて、テキストのコーディングについて話しましょう。 Askaの拡張バージョン-CP866とKOI8-Rを疑似グラフィックでコーディング
その後、すべての最新コード(Windows 1251、Unicode、UTF 8)の開発の出発点であるASCIIについて話し始めました。 128文字を超えるラテンアルファベット、アラビア数字などがありますが、拡張バージョンには、1バイトの情報にエンコードできる256個の値すべてを選択する機能があります。 トブト。 飛鳥に自分の言語の文字の記号を追加することが可能になりました。 ここで、説明するために、もう一度話す必要があります テキストをコーディングするための新しいニーズそして、なぜそれがとても重要なのですか。 コンピューターの画面上の記号は、2つのスピーチに基づいて形成されます-強い記号のベクトル形式(外観)のセット(コンピューターにインストールされているフォントのファイルに悪臭があります)フォント)必要な同じ記号必要なスペースに挿入します。 ベクトル形式自体にフォントが使用されており、コーディングの軸は、入力されたプログラムのオペレーティングシステムに基づいていることに気付きました。 トブト。 コンピュータにテキストがある場合、それはバイトのセットになります。スキンエンコーディングには、テキスト自体の1文字が含まれます。 画面にテキストを表示するプログラム(テキストエディタ、ブラウザなど)は、コードを解析するときに、黒文字のエンコーディングを読み取り、必要なフォントファイルで正しいベクトル形式を検索します。与えられたテキストドキュメント。 すべてがとても陳腐です。 したがって、必要な文字をエンコードするために(たとえば、国のアルファベットから)、考え直すことができるのは2回だけです。この文字のベクトル形式はカスタムフォントによるものであり、この文字は拡張ASCIIエンコードでエンコードできます。 1バイト。 そのため、このようなオプションが不可欠です。 拡張されたAskaのロシア語の元のkilkaの記号のコーディングのみ。 たとえば、穂軸に現れました CP866、ある意味で、ロシア語のアルファベットの記号とASCIIの拡張バージョンを勝利させることができました。 トブト。 її上部は、ホバーされた3つのスクリーンショットに表示されているため、Askaの基本バージョン(ラテン語で128文字、数字、その他のがらくた)と一致しており、軸はすでにCP866コードを含むテーブルの下部にあります。標識(ロシア語の文字とそこにあるあらゆる種類の疑似グラフィック): バカイト、右側では、数字は8で始まります。 0から7までの数字は、ASCIIベース部分の前に表示されます(div。最初のスクリーンショット)。 含む CP866数学コード9Cのロシア語の文字「M」(9の2行と16番目の記数法の数字Cの網膜にあります)。これは1バイトの情報で書くことができますが、二重の明確さのためです。テキストに問題なく表示されるロシア文字のフォント。 音はそのような量から来ました CP866の疑似グラフィック? ここで、現在のようにグラフィックオペレーティングシステムが拡張されている場合、ロシア語のテキストのコーディングがさらに揮発的に拡張されていることは注目に値します。 Dosiでは、テキスト操作と同様に、疑似グラフィックによってわずかに泌尿器科のテキストのデザインが可能になり、CP866および同じ年齢の他のすべての人がAskの拡張バージョンのカテゴリから除外されました。 CP866はIBMによって開発されましたが、ロシア語の記号の場合、たとえば、同じタイプ(ASCII拡張)まで多くのコードも拡張されました。 KOI8-R:
バカイト、右側では、数字は8で始まります。 0から7までの数字は、ASCIIベース部分の前に表示されます(div。最初のスクリーンショット)。 含む CP866数学コード9Cのロシア語の文字「M」(9の2行と16番目の記数法の数字Cの網膜にあります)。これは1バイトの情報で書くことができますが、二重の明確さのためです。テキストに問題なく表示されるロシア文字のフォント。 音はそのような量から来ました CP866の疑似グラフィック? ここで、現在のようにグラフィックオペレーティングシステムが拡張されている場合、ロシア語のテキストのコーディングがさらに揮発的に拡張されていることは注目に値します。 Dosiでは、テキスト操作と同様に、疑似グラフィックによってわずかに泌尿器科のテキストのデザインが可能になり、CP866および同じ年齢の他のすべての人がAskの拡張バージョンのカテゴリから除外されました。 CP866はIBMによって開発されましたが、ロシア語の記号の場合、たとえば、同じタイプ(ASCII拡張)まで多くのコードも拡張されました。 KOI8-R:
 作業の原則は、前述のtrohiの以前のCP866の原則と同じです。つまり、テキストのスキン文字は1バイトでエンコードされます。 スクリーンショットは、KOI8-Rテーブルの別の半分を示しています。 この記事の最初のスクリーンショットに示されているように、前半の前半は基本的なAskに基づいています。 KOI8-Rコーディングの機能の中で、たとえばCP866が作成されたため、この表のロシア語の文字はアルファベット順ではないことに注意してください。 最初のスクリーンショット(基本部分、すべての拡張コーディングの入力方法)を見ると、KOI8-Rではロシア語の文字が表の同じ中央に並べ替えられており、ラテンアルファベットの文字が表の最初の部分。 合計1ビート(7番目のステップで2つ、つまり128)を与えるために、ロシアのシンボルからラテンの方法への移行を明確にするために全体が分割されました。
作業の原則は、前述のtrohiの以前のCP866の原則と同じです。つまり、テキストのスキン文字は1バイトでエンコードされます。 スクリーンショットは、KOI8-Rテーブルの別の半分を示しています。 この記事の最初のスクリーンショットに示されているように、前半の前半は基本的なAskに基づいています。 KOI8-Rコーディングの機能の中で、たとえばCP866が作成されたため、この表のロシア語の文字はアルファベット順ではないことに注意してください。 最初のスクリーンショット(基本部分、すべての拡張コーディングの入力方法)を見ると、KOI8-Rではロシア語の文字が表の同じ中央に並べ替えられており、ラテンアルファベットの文字が表の最初の部分。 合計1ビート(7番目のステップで2つ、つまり128)を与えるために、ロシアのシンボルからラテンの方法への移行を明確にするために全体が分割されました。 Windows1251-ASCIIの現在のバージョン
テキストのコードがさらに発展したのは、グラフィック操作システムの人気が高まっていたためであり、すぐにそれらのシステムで疑似グラフィックを使用する必要が生じました。 その結果、グループの名前は、それ自体のストーリーと同様に、以前と同様に、Askの拡張バージョン(テキスト内の1文字は複数のバイトの情報によってエンコードされます)になりましたが、疑似グラフィックでは記号を使用していませんでした。 悪臭は、米国規格協会によって分割された、いわゆるANSIコードに依存していました。 キリル文字の名前も、ロシア語のサポートを受けてバリアントに選択されました。 このお尻はブティすることができます Windows 1251。 Вона вигідно відрізнялася від використовуваних раніше CP866 і KOI8-R тим, що місце символів псевдографіки в ній зайняли символи російської типографіки (крім знака наголосу), а також символи, що використовуються в близьких до російської слов'янських мовах (українській, білоруській і т. d。)。 ): ロシア語のこのようなさまざまなコーディングを通じて、フォントのフォントやソフトウェアのプログラマーは、徐々に頭を非難しました。私たちと一緒に、読者の聖歌は、しばしばあなた自身の苦味を使用しました krakozyabri、テキストで勝利しているバージョンに迷いがあった場合。 Дуже часто вони вилазили при надсиланні та отриманні повідомлень електронною поштою, що спричинило створення дуже складних перекодувальних таблиць, які, власне, вирішити цю проблему докорінно не змогли, і найчастіше користувачі для листування використовували трансліт латинських літер, щоб уникнути горезвісних кракозябрів при використання російських кодувань подібних CP866、KOI8-R、またはWindows 1251に準拠。実際、ロシア語のテキストを置き換えるために使用されたバグは、テキストメッセージがエンコードされたこの映画が表示されなかったため、誤ったコーディングの結果でした。 CP866の助けを借りてエンコードされた記号が、Windows 1251コードテーブルを模倣しようとするか、または走り書き(ばかげた文字を入力)して悪意を持って通知のテキストをそれ自体に置き換えようとするかのように、許容されます。
ロシア語のこのようなさまざまなコーディングを通じて、フォントのフォントやソフトウェアのプログラマーは、徐々に頭を非難しました。私たちと一緒に、読者の聖歌は、しばしばあなた自身の苦味を使用しました krakozyabri、テキストで勝利しているバージョンに迷いがあった場合。 Дуже часто вони вилазили при надсиланні та отриманні повідомлень електронною поштою, що спричинило створення дуже складних перекодувальних таблиць, які, власне, вирішити цю проблему докорінно не змогли, і найчастіше користувачі для листування використовували трансліт латинських літер, щоб уникнути горезвісних кракозябрів при використання російських кодувань подібних CP866、KOI8-R、またはWindows 1251に準拠。実際、ロシア語のテキストを置き換えるために使用されたバグは、テキストメッセージがエンコードされたこの映画が表示されなかったため、誤ったコーディングの結果でした。 CP866の助けを借りてエンコードされた記号が、Windows 1251コードテーブルを模倣しようとするか、または走り書き(ばかげた文字を入力)して悪意を持って通知のテキストをそれ自体に置き換えようとするかのように、許容されます。  ロシア語の文字を含むテキストが、zamochuvannyamのサイトでハッキングされたかのように、間違ったコーディングで許可された場合、または間違ったテキストエディタで、サイト、フォーラム、またはブログの作成とカスタマイズについて同様の状況がしばしば非難されます。私が不屈の目で見るいくつかの非難。 絶えず登る非人称のcoduvansとkrakozyabryのような状況は、豊かなnabridlaであり、新しい普遍的なバリエーションを作成する前に、テキストのルートですべてをそれ自体とvirishila b、nareshtに置き換えるかのように考えを変えるように見えました問題 中国語に似た言語の問題はクリミアに基づいていましたが、言語の記号はより豊かで、256より低くなりました。
ロシア語の文字を含むテキストが、zamochuvannyamのサイトでハッキングされたかのように、間違ったコーディングで許可された場合、または間違ったテキストエディタで、サイト、フォーラム、またはブログの作成とカスタマイズについて同様の状況がしばしば非難されます。私が不屈の目で見るいくつかの非難。 絶えず登る非人称のcoduvansとkrakozyabryのような状況は、豊かなnabridlaであり、新しい普遍的なバリエーションを作成する前に、テキストのルートですべてをそれ自体とvirishila b、nareshtに置き換えるかのように考えを変えるように見えました問題 中国語に似た言語の問題はクリミアに基づいていましたが、言語の記号はより豊かで、256より低くなりました。 Unicode(Unicode)-ユニバーサルエンコーディングUTF 8、16、および32
pvdenno-shidnoy Asiaの現代グループの何千もの文字は、ASCIIの拡張バージョンで文字をコーディングするために見られた1バイトの情報では記述できませんでした。 その結果、コンソーシアムが名前で作成されました Unicode(Unicode-Unicodeコンソーシアム)IT業界のリーダー(ソフトウェアの開発、コードのエンコード、フォントの作成)の豊富な機能を備えており、テキストのユニバーサルコーディングの登場によって求められていました。 。 ユニコードコンソーシアムの下で導入された最初のバリエーションはbulaでした UTF-32。 コーディングのヘッダーにある数字は、1文字をエンコードするのに必要なビット数を意味します。 32ビットは、新しいユニバーサルUTFエンコーディングで1つの文字をエンコードするために必要な最大4バイトの情報を追加します。 その結果、ASCIIの拡張バージョンとUTF-32でのテキスト、エンコーディングを含む同じファイル、残りの場合、拡張(重要度)は4倍になります。 それは悪いことですが、PTFの助けを借りて、他の30ステップで2つより高価な標識の数をエンコードする機会があります( 数十億のシンボル、ヤクpokriyut be-yak巨大な予備から本当に必要な値)。 偉大なモヴァリグループの国であるエールバガンは、私が非ノミを焼かなかったコドバニムの偉大なキルキストのサインVikoristovatiであり、国のプロテであるニカタグタグであり、結果として保存されています。 これは金持ちであり、そのようなお金の無駄は誰にも許されませんでした。 Unicodeの開発が登場した後 UTF-16、遠くにあるYakavyyshlanastіlki、私たちvikoristovuyutsyaのように、すべてのシンボルの基本的な広がりとしてumovchannyamのためにとられたschobula。 1文字をコーディングするための2バイトがあります。 私たちがどのように見えるのか疑問に思いましょう。 Windowsオペレーティングシステムでは、「スタート」-「プログラム」-「アクセサリ」-「サービス」-「シンボルテーブル」のパスをたどることができます。 その結果、システムにインストールされているすべてのフォントシステムのベクトル形式を含むテーブルが表示されます。 「追加オプション」でUnicode文字を選択すると、新しいフォントまで、スキンフォントの文字範囲全体を使用できます。 スピーチの前に、彼らがそうであるかどうかをクリックして、あなたは2バイトのyogoを歌うことができます UTF-16フォーマットコード、14の16桁で合計されるもの: 16ビットを使用してUTF-16でエンコードできる文字数はいくつですか? 65536(16のステップで2つ)、および数値自体がUnicodeのベーススペースとして使用されました。 Krіmtsgogoは、彼女を助けるためにエンコードする方法と、2つのmilyonіvznіkіvに近いものをエンコードする方法であり、テキスト内の拡張された拡張シンボルである可能性があります。 残念ながら、Unicodeエンコーディングのバージョンは、たとえば英語のみでプログラムを作成した人にはあまり満足しませんでした。ASCIIの拡張バージョンをUTF-16に切り替えた後、ドキュメントが2倍になりました(1バイトあたり1バイト)。バイト単位の1文字からUTF-16の同じ文字へ)。 ユニコードコンソーシアムのすべての人とすべての人の満足のために、それはキャンセルされました コードを思い付く人生の変化。 ЇїはUTF-8という名前です。 名前のPoprivіsіmkuは、mіnnudovzhina、tobtoではありません。 テキストのスキン文字は、最大6バイトの長さのシーケンスでエンコードできます。 実際には、UTF-8の範囲は1〜4バイトしかないため、数バイトのコードで何かを明らかにすることは理論的に不可能です。 その中のすべてのラテン文字は、古き良きASCIIと同じように、1バイトでエンコードされます。 注目に値するのは、コーディングの時代にはラテン語よりも少ないので、それらのプログラムをnavitし、Unicodeを理解していない場合は、すべて同じように、UTF-8でエンコードされたプログラムを読んでください。 トブト。 Askaのベース部分は、ユニコードコンソーシアムの発案によるものです。 UTF-8のキリル文字は2バイトでエンコードされ、たとえば、グルジア文字は3バイトでエンコードされます。 UTF 16および8の作成後のユニコードコンソーシアムが主な問題を解決しました-現在、 フォントは単一のコードスペースを使用します。 そして今、彼らの筆記者は、テキスト内の記号のベクトル形式を埋める彼ら自身の強さと能力しか残されていません。 「記号の表」の上にカーソルを合わせると、さまざまなフォントが文字数を強調していることがわかります。 Unicodeフォントの文字の多くは、きちんとさえ重要になる可能性があります。 しかし、今では悪臭は彼らによって考慮されておらず、異なるコーディングのために作成されていますが、タイプライターがフォントを入力したか、単一のコードスペースにこれらや他のベクトル形式を最後まで入力したかどうかを入力します。
16ビットを使用してUTF-16でエンコードできる文字数はいくつですか? 65536(16のステップで2つ)、および数値自体がUnicodeのベーススペースとして使用されました。 Krіmtsgogoは、彼女を助けるためにエンコードする方法と、2つのmilyonіvznіkіvに近いものをエンコードする方法であり、テキスト内の拡張された拡張シンボルである可能性があります。 残念ながら、Unicodeエンコーディングのバージョンは、たとえば英語のみでプログラムを作成した人にはあまり満足しませんでした。ASCIIの拡張バージョンをUTF-16に切り替えた後、ドキュメントが2倍になりました(1バイトあたり1バイト)。バイト単位の1文字からUTF-16の同じ文字へ)。 ユニコードコンソーシアムのすべての人とすべての人の満足のために、それはキャンセルされました コードを思い付く人生の変化。 ЇїはUTF-8という名前です。 名前のPoprivіsіmkuは、mіnnudovzhina、tobtoではありません。 テキストのスキン文字は、最大6バイトの長さのシーケンスでエンコードできます。 実際には、UTF-8の範囲は1〜4バイトしかないため、数バイトのコードで何かを明らかにすることは理論的に不可能です。 その中のすべてのラテン文字は、古き良きASCIIと同じように、1バイトでエンコードされます。 注目に値するのは、コーディングの時代にはラテン語よりも少ないので、それらのプログラムをnavitし、Unicodeを理解していない場合は、すべて同じように、UTF-8でエンコードされたプログラムを読んでください。 トブト。 Askaのベース部分は、ユニコードコンソーシアムの発案によるものです。 UTF-8のキリル文字は2バイトでエンコードされ、たとえば、グルジア文字は3バイトでエンコードされます。 UTF 16および8の作成後のユニコードコンソーシアムが主な問題を解決しました-現在、 フォントは単一のコードスペースを使用します。 そして今、彼らの筆記者は、テキスト内の記号のベクトル形式を埋める彼ら自身の強さと能力しか残されていません。 「記号の表」の上にカーソルを合わせると、さまざまなフォントが文字数を強調していることがわかります。 Unicodeフォントの文字の多くは、きちんとさえ重要になる可能性があります。 しかし、今では悪臭は彼らによって考慮されておらず、異なるコーディングのために作成されていますが、タイプライターがフォントを入力したか、単一のコードスペースにこれらや他のベクトル形式を最後まで入力したかどうかを入力します。 ロシアの手紙のKrakozyabri副。
ここで、それらがkrakozyabriのテキストをどのように置き換えることになっているのか、そうでない場合は、ロシア語のテキストの正しいコーディングをどのように選択するのかを考えてみましょう。 それはそのプログラムで設定されており、テキスト自体を編集するか、さまざまなテキストフラグメントのコードを作成します。 私の意見では、テキストファイルの作成を編集するには、HtmlおよびPHPエディターのメモ帳++が特に適しています。 Vіm、vіnは、何百ものプログラミングとレイアウトの構文を変更することができ、追加のプラグインのために拡張する可能性もあります。 奇跡的なプログラムのレポートレビューを読んで助けを求めてください。 メモ帳++のトップメニューには「コーディング」という項目があり、サイトでロック用に機能しているオプションの既存のオプションを変更できます。 Joomla 1.5以降のサイト、およびWordPressのブログの場合は、ショートカットの外観に従ってオプションを選択してください。 BOMなしのUTF8。 プレフィックスBOMとは何ですか? 右側では、UTF-16コーディングが壊れている場合、直接シーケンス(たとえば、0A15)のようにシンボルにコードを書き込むことができるため、そのようなフレーズをねじ込みました。 (150A)。 そして、プログラムが理解するために、順番にコードを読み、思い付くために BOM(バイトオーダーマーク、つまり署名)、ドキュメントの穂軸に3バイトを追加することで明らかになります。 UTF-8エンコーディングでは、BOMはUnicodeコンソーシアムに転送されませんでした。それに、そのようなプログラムに署名(ドキュメントの穂軸にある最高の3バイト)を追加するだけで、コードを読む価値があります。 したがって、UTFにファイルを保存するために、BOMなし(署名なし)のオプションを選択するのはユーザーの責任です。 このランクでは、あなたは遠くにいます krakozyabrivの形で身を守る。 同じ惨めなWindowsのメモ帳など、Windowsの一部のプログラムがこの作業を実行できない(BOMなしでUTF-8からテキストを保存できない)ことは注目に値します。 VіnはUTF-8からドキュメントを取得しますが、すべて同じように、穂軸に署名(3バイト追加)が追加されます。 さらに、これらのバイト自体が唯一のものになります-直接シーケンスでコードを読み取ります。 tsyudrіbnitsyuを介してサーバー上のエールは問題を非難することができます-vilіzukrakozyabri。 だからいつでも 素晴らしいWindowsのメモ帳にだまされないでくださいあなたのサイトの文書を編集するために、あなたは不正確さの出現を気にしません。 最良かつ最も単純なオプションとして、私はメモ帳++エディターを使用します。これは、実際には短命ではなく、いくつかの利点があります。 メモ帳++を使用すると、エンコーディングを選択するときに、テキストをUCS-2エンコーディングに変換できます。これは、本質的にUnicode標準に近いものです。 メモ帳はANSIでテキストをエンコードすることもできます。 100%ロシア語は、Windows 1251の3倍の量で説明されます。何か情報はありますか? これは、Windowsオペレーティングシステムのレジストリに登録されています。たとえば、ANSI時間からの選択のコーディング、OEM時間からの選択のように(ロシア映画の場合はCP866になります)。 ロックのためにコンピューターに別の言語をインストールすると、コーディングは自分の言語の同じANSIまたはOEMコードに置き換えられます。 さらに、必要なコードからNotepad ++でドキュメントを保存するか、編集のためにサイトからドキュメントを開く場合は、エディターの右下隅に次の名前を追加できます。 Shchob niknut krakozyabriv、上記の説明を除いて、サーバーまたはローカルホストが詐欺師のせいにならないように、サイトのすべての側の出力コードのヘッダーにコーディング自体に関する情報を書き込むのが正しいでしょう。 Vzagali、ハイパーテキストレイアウトのすべてのmovs、Html cremeには、テキストコーディングが示されている特別に音声化されたxmlがあります。<
?
xml version=
"1.0"
encoding=
"windows-1251"
?
>まず、コードを分析すると、ブラウザは、使用されている勝利者のバージョンと、映画の登場人物のコードをどのように解釈する必要があるかを認識します。 ただし、デフォルトのUnicodeからドキュメントを保存する場合は、xmlのあいまいさを省略できます(エンコーディングは、BOMがないことを意味するUTF-8またはBOMєを意味するUTF-16になります)。 挿入用のHTMLムービードキュメントの時点で、コーディングが変更されています メタ要素、カーブして閉じるHeadタグの間に書き込まれます。 <
head>
.
.
.
<
meta charset=
"utf-8"
>
.
.
.
<
/
head>このエントリは、Html 4.01標準で採用されているように大幅に改訂されていますが、徐々に導入されている新しいHtml 5標準に再送信され、現在勝利しているブラウザかどうかが正しく理解されます。 アイデアとして、ドキュメントのHtmlエンコーディングのMeta要素は短くなります ヤコモガはドキュメントヘッダーの上位にあります、そのため、最初の文字のテキストを書いている時点では、基本のANSI(常に正しく、どのようなバリエーションでも正しく読み取られます)ではないため、ブラウザーは、これらの文字のコードを解釈する方法に関する母親の情報に罪を犯します。 最も遠いPosilannya
Joomla 1.5以降のサイト、およびWordPressのブログの場合は、ショートカットの外観に従ってオプションを選択してください。 BOMなしのUTF8。 プレフィックスBOMとは何ですか? 右側では、UTF-16コーディングが壊れている場合、直接シーケンス(たとえば、0A15)のようにシンボルにコードを書き込むことができるため、そのようなフレーズをねじ込みました。 (150A)。 そして、プログラムが理解するために、順番にコードを読み、思い付くために BOM(バイトオーダーマーク、つまり署名)、ドキュメントの穂軸に3バイトを追加することで明らかになります。 UTF-8エンコーディングでは、BOMはUnicodeコンソーシアムに転送されませんでした。それに、そのようなプログラムに署名(ドキュメントの穂軸にある最高の3バイト)を追加するだけで、コードを読む価値があります。 したがって、UTFにファイルを保存するために、BOMなし(署名なし)のオプションを選択するのはユーザーの責任です。 このランクでは、あなたは遠くにいます krakozyabrivの形で身を守る。 同じ惨めなWindowsのメモ帳など、Windowsの一部のプログラムがこの作業を実行できない(BOMなしでUTF-8からテキストを保存できない)ことは注目に値します。 VіnはUTF-8からドキュメントを取得しますが、すべて同じように、穂軸に署名(3バイト追加)が追加されます。 さらに、これらのバイト自体が唯一のものになります-直接シーケンスでコードを読み取ります。 tsyudrіbnitsyuを介してサーバー上のエールは問題を非難することができます-vilіzukrakozyabri。 だからいつでも 素晴らしいWindowsのメモ帳にだまされないでくださいあなたのサイトの文書を編集するために、あなたは不正確さの出現を気にしません。 最良かつ最も単純なオプションとして、私はメモ帳++エディターを使用します。これは、実際には短命ではなく、いくつかの利点があります。 メモ帳++を使用すると、エンコーディングを選択するときに、テキストをUCS-2エンコーディングに変換できます。これは、本質的にUnicode標準に近いものです。 メモ帳はANSIでテキストをエンコードすることもできます。 100%ロシア語は、Windows 1251の3倍の量で説明されます。何か情報はありますか? これは、Windowsオペレーティングシステムのレジストリに登録されています。たとえば、ANSI時間からの選択のコーディング、OEM時間からの選択のように(ロシア映画の場合はCP866になります)。 ロックのためにコンピューターに別の言語をインストールすると、コーディングは自分の言語の同じANSIまたはOEMコードに置き換えられます。 さらに、必要なコードからNotepad ++でドキュメントを保存するか、編集のためにサイトからドキュメントを開く場合は、エディターの右下隅に次の名前を追加できます。 Shchob niknut krakozyabriv、上記の説明を除いて、サーバーまたはローカルホストが詐欺師のせいにならないように、サイトのすべての側の出力コードのヘッダーにコーディング自体に関する情報を書き込むのが正しいでしょう。 Vzagali、ハイパーテキストレイアウトのすべてのmovs、Html cremeには、テキストコーディングが示されている特別に音声化されたxmlがあります。<
?
xml version=
"1.0"
encoding=
"windows-1251"
?
>まず、コードを分析すると、ブラウザは、使用されている勝利者のバージョンと、映画の登場人物のコードをどのように解釈する必要があるかを認識します。 ただし、デフォルトのUnicodeからドキュメントを保存する場合は、xmlのあいまいさを省略できます(エンコーディングは、BOMがないことを意味するUTF-8またはBOMєを意味するUTF-16になります)。 挿入用のHTMLムービードキュメントの時点で、コーディングが変更されています メタ要素、カーブして閉じるHeadタグの間に書き込まれます。 <
head>
.
.
.
<
meta charset=
"utf-8"
>
.
.
.
<
/
head>このエントリは、Html 4.01標準で採用されているように大幅に改訂されていますが、徐々に導入されている新しいHtml 5標準に再送信され、現在勝利しているブラウザかどうかが正しく理解されます。 アイデアとして、ドキュメントのHtmlエンコーディングのMeta要素は短くなります ヤコモガはドキュメントヘッダーの上位にあります、そのため、最初の文字のテキストを書いている時点では、基本のANSI(常に正しく、どのようなバリエーションでも正しく読み取られます)ではないため、ブラウザーは、これらの文字のコードを解釈する方法に関する母親の情報に罪を犯します。 最も遠いPosilannya