インターネット検索システム: Yandex、Google、Rambler、Yahoo。 倉庫、機能、動作原理。 検索システムは具体的に何をするのですか? 1 サウンドシステムについて簡単に理解すべきこと
ブログ サイトの読者の皆さん、こんにちは。 プロ レベル (商業プロジェクトを 1 セントで販売する) とアマチュア レベル () の両方で、一見するとサウンドの最適化に取り組んでいる場合、必ずこれを理解することになるでしょう。これは必要なことです。知っておくことが重要です。自分自身または他人のサイトを適切に最適化するための一般的な動作原理。
敵は、どうやら直接知る必要があるようですが、もちろん、悪臭(RuNet と Yandex i にとって)は私たちにとってまったく敵ではなく、むしろパートナーです。トラフィックの一部はほとんどの場合、支配的で主要なもの。 そしてもちろん、非難や悪臭はもはやこの規則を裏付けるものではありません。
スナイプとは何か、そしてサウンドシステムの動作原理
しかし、ここではすぐに開始する必要があります。また、依然として必要なスナイプは何でしょうか。オプティマイザにとってそれがなぜそれほど重要なのでしょうか? 検索結果は、文書が検索に送信された直後に表示されます (文書のテキストは既に作成されたものから取得されます)。
この文書のvikoristovuyutsya zazvichiy shmatkiテキストをどのように監視するか。 クリックの理想的なオプションは、作成者にその側面に行くのではなく、その側面について考える機会を与えることです (そうしないと、その側面をしまいますが、再度考えることはありません)。
スニペットは自動的に生成され、新しいバージョンではテキストのフラグメントが強調表示されます。重要な点として、同じ Web ページ上の異なるクエリには異なるスニペットが存在します。
また、Description タグ自体の代わりに、(特に Google で) スニペットとして検索できることも事実です。 もちろん、それはまだ古いので、ある種の静脈の形で現れます。
たとえば、キーワードを検索するときに、説明タグの代わりに、説明に入力した単語を表示したり、最終的にアルゴリズム自体がテキストの断片をまだ認識していない場合は、説明タグを表示したりできます。あなたのページに欠けているすべてのキーワードのサイト Google の Yandex を参照してください。
そのため、削除せずにスキンステータスのDescriptionタグの代わりに覚えておいてください。 WordPress で説明を活発化することでお金を稼ぐことができます (私は、活発化することをお勧めします)。
Jumli のファンであれば、すぐにこの素材を楽しむことができます。
エール スニペットはリターン インデックスから削除できません。 そこには、ページ上の単語とテキスト内のその位置に関する情報のみが保存されます。 異なる検索エンジン(異なるクエリ用)で同じドキュメントのスニペットを作成するための軸自体は、戻りインデックス(検索に直接必要です - 以下をお読みください)に加えて、私たちのお気に入りのYandexとGoogleです。 直接インデックス、 それから。 Web ページのコピー。
ドキュメントのコピーをベースとして保存すると、オリジナルを変更せずに、そこから必要なスニペットを手動で切り取ることができます。
それ。 検索エンジンは、Web サイトの順方向インデックスと逆方向インデックスの両方をデータベースに保存していることがわかりました。 スピーチの前に、スニペットの形成を間接的に統合し、ユーザーが念頭に置いているのと同じテキストの断片をアルゴリズムが選択するような方法で Web ストーリーのテキストを最適化できます。 それについては別の記事でお話します。
検索システムの操作方法
最適化の本質は、これらのクエリやその他のクエリに関して、訪問したサイトのページを可能な限り最高の位置に上げるように検索エンジンのアルゴリズムを「支援」することです。
私は足からの前方命題から「助けて」という言葉を取りました。 最適化アクションでは、完全に役立つわけではありませんが、ビューに関連するクエリ (謎に関する) を生成するためにアルゴリズムに大きく依存することがよくあります。
これはオプティマイザーの基本であり、検索アルゴリズムが徹底されないため、内部および外部の最適化を使用して Yandex と Google での地位を向上させる可能性があります。
まず第一に、最適化手法の学習に移りましょう、将来のすべての作業を意識して理解できるように、サウンド システムの動作原理を完全に理解する必要があります。反応が少ない。
私たちが基本原理を十分に理解していない限り、明らかにするのに十分な情報がないため、彼らの仕事の論理全体を理解するのは不可能であることは明らかです。 さあ、見てみましょう。
サウンドシステムはどのように機能するのでしょうか? それは驚くべきことではありませんが、彼らの仕事のロジックは原則として同じであり、前面に出てきます。アクセス可能な範囲にあるすべての Web ページに関する情報が収集され、その後、この狡猾な知恵からのデータが収集されます。便利に使用するには、検索を行ってください。 軸、主、およびこの記事に記載されているものはすべて完成していると考えられますが、さらに詳細を追加します。
まず、サイト側と呼ばれるものをドキュメントと呼ぶことを明確にしましょう。 この場合、あなたは自分の一意のアドレス () について責任を負い、特に、新しい文書 (それらに関する文書) が出現するまでハッシュ メッセージは生成されません。
別の言い方をすれば、収集された文書データベースから情報を検索するためのアルゴリズム (方法) に焦点を当てる必要があります。
直接インデックスと逆インデックスのアルゴリズム
明らかに、データベースに保存されているすべてのページを単純に列挙する方法は最適ではありません。 この方法をアルゴリズムといいます 直接検索もちろん、この方法を使用すると、重要なものを見逃さずに必要な情報を見つけることができますが、検索にはかなりの時間がかかるため、大量のデータを扱う場合にはまったく適していません。
したがって、効率的な作業のために、データに多大な労力を費やして、逆 (逆) インデックスのアルゴリズムが開発されました。 そして重要なことは、彼自身が世界中のすべての素晴らしいサウンドシステムで勝利を収めているということです。 そこで次回は、本作の原理について見ていきましょう。
アルゴリズムを使用する場合 インデックスを返すドキュメントをテキスト ファイルから変換して、ドキュメントに含まれるすべての単語のリストを作成する必要があります。
このようなリスト (インデックス ファイル) 内の単語はアルファベット順に配置されており、各単語の順序は、単語が表示される Web ページ内の位置座標のビューに示されます。 各単語の文書位置の周囲に、その値を示す他のパラメーターが指定されます。
ご想像のとおり、多くの本(主に専門書や科学書)の残りのページには、指定されたページ番号から、この本に含まれる単語が絞り込まれたリストが表示されます。 もちろん、このリストには書籍に登場するすべての単語が含まれているわけではありませんが、追加の逆索引を使用する索引ファイルの例として役立ちます。
検索エンジンが情報を検索することに敬意を表します インターネット上ではない、およびそれらが提供する Web サイトのリターン インデックス。 欲しいと直接のインデックス(原文)も保存されます。 これはスニペットを作成する場合に便利ですが、これについてはこの出版物の冒頭ですでに説明しました。
戻りインデックスのアルゴリズムは vikoryst システムで使用されます。 これにより、プロセスを高速化できます。そうしないと、ドキュメントをインデックス ファイルに変換するプロセスで情報の損失が避けられなくなります。 返されたインデックス ファイルを保存しやすくするには、巧妙な方法を使用してファイルを圧縮します。
ランキングに使用される数学的モデル。
ポータル インデックスを検索するために、数学的モデルが開発されます。これにより、(クエリを入力することで) 必要な Web サイトを特定するプロセスと、そのクエリに対して見つかったすべてのドキュメントの関連性を判断するプロセスが簡素化されます。 特定のクエリと一致する証拠が多いほど (関連性が高いほど)、音声で見つかる可能性が高くなります。
これは、数学的モデルの基礎となる主なタスクは、このクエリに関連するポータル インデックスのデータベース内のページを検索し、このクエリとの関連性が高い順にページをさらに並べ替えることであることを意味します。
探しているフレーズが鮮明になるにつれて文書が見つかった場合に、単純な論理モデルを使用することは、一目でわかるそのような Web サイトが多数あるため、機能しません。
検索システムは、タイトルに単語が含まれていないすべての Web サイトのリストを提供するだけではありません。 最も関連性の高いドキュメントが先頭にある場合は、このリストをこのフォームに入力できます (関連性に従って並べ替えます)。 この課題は簡単ではなく、私たちの考えでは理想的なものではありません。
話す前に、オプティマイザーは数学的モデルの不完全性を利用して、フォーム内のドキュメントをランク付けするためにこれらの方法やその他の方法を使用します (もちろん、オプティマイザーが使用するサイトを犠牲にして)。 すべてのサウンド システムで使用される数学的モデルは、ベクトル モデルとして分類されます。 彼女は、文書が完全にコリストヴァッハによって与えられたものであることをヴィコリストヴォに理解しています。
基本的なベクトル モデルでは、特定の単語の後ろにある文書の長さは 2 つの主なパラメーターに基づいて計算されます。1 つは特定の単語が聞こえる頻度 (TF - 用語頻度)、もう 1 つはその単語が他のすべての側面で聞かれる頻度です。コレクション (IDF - 逆ドキュメント頻度 )。
コレクションの下には、サウンド システムに含まれるページのセット全体が表示されます。 2 つのパラメータを 1 つずつ乗算することにより、ドキュメントの値が書かれたタスクから減算されます。
当然のことながら、TF パラメータと IDF パラメータに加えて、音声を拡張するための重要な要素なしで、さまざまなサウンド システムが使用されますが、本質は変わりません。側面の値は大きくなり、単語がより頻繁に使用されるようになります。サウンドノートはその中でシャープ化され(曲の間の、その後文書がスパムとして検出される可能性がある)、このシステムによってインデックス付けされた他の文書にこの単語が出現するまでの時間を示します。
評価者によるロボットフォーミュラのコスト評価
したがって、これらのクエリおよび他のクエリのデータの形成が行われることがわかります。 公式に従います人間の参加なしで。 式が完全に機能しない場合、特に最初は、数学モデルの動作を制御する必要があります。
これらの目的のために、特別な訓練を受けた人材がさまざまなクエリのデータ (具体的には彼らを雇用した検索システム) を調べ、フロー式の精度を評価するために使用されます。
それらはすべて、モデルの調整を担当する人々によって丁寧にサポートされています。 式に変更や追加が加えられ、その結果、測深機の効率が向上します。 評価者らは、アルゴリズムの開発者と黄疸の増強に必要なコリストヴァチャミとの間のそのような種類のゲートウェイ接続の役割を結論付けていることが判明した。
ロボット式の効率を評価するための主な基準は次のとおりです。
- サウンド システムの精度は、(要求に対応する)数百の関連文書に基づいています。 ウェブページ (出入り口など) が少ないほど、質問に煩わされることがなくなり、その場にいた方が良いでしょう。
- サウンド タイプの完全性は、コレクション全体に含まれる関連ドキュメントの総数に対して、類似したクエリ (関連) Web サイトの数が多いことです。 トブト。 特定のクエリに対応する Web ページを検索しているドキュメントのデータベース全体が、検索フォームで以下に表示されることがわかります。 この場合、外観の不一致について話すことができます。 関連するページの一部がフィルターの下で失われ、たとえば、汚れや他のスラグと間違えられた可能性があります。
- ビューの関連性とは、インターネット上のサイト上の実際の Web ページと、検索結果にその Web ページについて書かれている内容の関連性のレベルです。 たとえば、ドキュメントは作成されなくなったり、大幅に変更されたりする可能性がありますが、指定されたアドレスに物理的に存在するかどうか、または指定されたクエリとはまったく異なる人物であるかどうかに関係なく、指定されたクエリのタイプは存在します。 関連性は、検索ロボットがコレクションから文書をスキャンする頻度にあります。
Yandex と Google がコレクションを収集する方法
Web ページのインデックス作成は簡単であるように見えますが、自分のサイトや他のサイトを最適化 (SEO) する際には、知っておく必要があるニュアンスがたくさんあります。 データベースのインデックス作成(コレクション収集)は、検索ロボット(ボット)と呼ばれる特別に設計されたプログラムによって実行されます。
ロボットは、これらのページの抽出、コピーを担当するアドレスの初期リストを選択し、それをアルゴリズムに渡してさらに処理します (返されるインデックスに変換します)。
ロボットは、このリストの背後にあるだけでなく、これらのページのメッセージにアクセスし、これらのメッセージの背後にあるドキュメントのインデックスを作成することもできます。 それ。 このロボットは、命令に従わなければならない首相と同じように動作します。
追加のロボットの助けを借りて、ユーザーが利用できるすべてのものにインデックスを付けることができることがわかりました。これは、サーフィン用のブラウザです (検索エンジンは、インターネット ユーザーがアクセスできる直接可視ドキュメントにインデックスを付けます)。
境界でのドキュメントのインデックス作成に関連する機能はほとんどありません (すでに説明したことを覚えています)。
考慮できる最初の機能は、インポートされた元のドキュメントから時々作成されるリターン インデックスに加えて、サウンド システムが別のコピーを保存するか、そうでない場合は、明らかにサウンド システムが別の直接インデックスを保存することです。 何が必要とされているか? 私は、入力されたクエリに基づいてさまざまなスニペットを作成するために何が必要か、少し前に推測していました。
Yandex がフォームとインデックスに表示する 1 つのサイトのページ数
特定のリクエストに対して各サイトに複数のドキュメントが存在するなど、Yandex の仕事の特別な特徴に敬意を表したいと思います。 ある種が 1 つの資源から両側の異なる位置に存在するということは、最近まで起こり得なかったことです。
これは Yandex の基本ルールの 1 つです。 1 つのサイトに特定のクエリに関連するページが数百ある場合、存在するのは 1 つだけ (最も関連性の高いページ) になります。
Yandex は、koristuvach が異なる情報を選択し、同じサイトのページから同じ種類のサウンドの多数のページが焼き尽くされないようにすることを目的としています。その他の理由により、koristuvach は重要ではないと思われます。
ただし、この記事を完了すると、何か新しいことを学んだので、急いで待ちます。つまり、Yandexは、あたかもこの側が「良くて正しい」ように見えるかのように、同じリソースからの別のドキュメントの出現を許可し始めることを意味します(言い換えれば、クエリとの関連性が高いということです)。
注目すべき点は、同じサイトからの追加の結果にも番号が付けられているため、この上部を介して、下位の位置を占めるさまざまなリソースが落ちてくることです。 新しい Yandex バージョンのアクスルバット:

彼らはすべてのサイトを段階的にインデックス付けしようとしますが、多くの場合、これは単にサイト上のページ数が大きく異なるだけでは起こりません (10 あるサイトもあれば、1,000 万のページもあります)。 ヤク・ブティ・ウ・ツォム・ヴィパドク?
Yandex は、1 つのサイトからインデックスにダウンロードできる多数のドキュメントを交換することで、この状況から脱却しようとしています。
別のレベルのドメイン名を持つプロジェクト (Web サイトなど) の場合、Runet ミラーによってインデックスを作成できるページの最大数は 100 ~ 150,000 の範囲になります (具体的な数は、への割り当てに基づいています)。そのプロジェクト)。
第 3 レベルのドメイン名からのリソースの場合 - 10 ~ 30,000 ページ (ドキュメント)。
別のレベルのドメイン () を持つ Web サイトがあり、たとえば 100 万件の Web サイトのインデックスを作成する必要がある場合、この状況から抜け出す唯一の方法は、サブドメイン () の非人格性を作成することです。
別のレベルのドメインのサブドメインは、JOOMLA.site のようになります。 Yandex によってインデックスを作成できる他の国のサブドメインの数は 200 を少し超える (場合によっては最大 1,000) ため、この簡単な方法でいくつかのサブドメインを RuNet ミラーの Web ページのインデックスに追加できます。
Yandex がロシア以外のドメイン ゾーンの Web サイトの前に配置される方法
Yandex は最近までインターネットのロシア部分に関心を持っていたため、主にロシアのプロジェクトをインデックスに登録しています。
ロシアのドメイン ゾーン (RU、SU、UA) に帰属するはずのドメイン ゾーンにない Web サイトを作成している場合、スウェーデンのインデックス付けをチェックすることはできません。 すべてを見てきたあなたは、早ければ一か月前にはあなたを知ることになるでしょう。 インデックス作成がすでに開始されている場合は、ロシアのドメイン ゾーンと同じ頻度でインデックス作成が行われます。
トブト。 ドメイン ゾーンは 1 時間だけ流れ、インデックス付けの開始までに移行しますが、それ以降はその頻度まで流れません。 話す前に、周波数はどれくらいですか?
ページの再インデックス作成によるサウンド システムの動作ロジックは、ほぼ同じになります。
- 新しいページを認識してインデックスを作成すると、ロボットは翌日そのページに移動します
- 昨日何が起こったかを理解していて、任務も知らないので、ロボットは3日後にまた彼女のところに来るでしょう
- 何も変わらないとすぐに、10年後にそれが来るでしょう。
それ。 したがって、ロボットがこの側に到着する頻度は、ロボットの更新頻度と等しいか、今後も同じになります。 さらに、ロボットが再突入する時間は、中国でもロシアでもサイトによって異なる場合があります。
これらは、さまざまなリソースのさまざまな部分に対して個別の配信スケジュールを作成するインテリジェントなサウンド システムです。 ただし、バナーの背後にあるページのインデックスを再作成するようにサウンド システムに依頼することもできます。これについては、何も変更がないかのようにしますが、これについては別の統計で説明します。
引き続き現在の状況における検索の原則を紹介し、検索システムで生じる問題とそのニュアンスを見てみましょう。 もちろん、他にもたくさんのことがあり、別の意味で役に立ちます。
頑張って! ブログサイトでお会いしましょう
困っているかもしれない
 Rel Nofollow と Noindex - Yandex と Google によるサイト上の外部メッセージのインデックス作成をブロックする方法
Rel Nofollow と Noindex - Yandex と Google によるサイト上の外部メッセージのインデックス作成をブロックする方法  サウンドシステム、高周波、中周波、低周波入力の周波数によって引き起こされる音声形態の出現やその他の問題
サウンドシステム、高周波、中周波、低周波入力の周波数によって引き起こされる音声形態の出現やその他の問題  サイトの信頼 - それは何か、XTools で消滅する方法、サイトに与える影響、およびサイトの権威を高める方法
サイトの信頼 - それは何か、XTools で消滅する方法、サイトに与える影響、およびサイトの権威を高める方法  SEO 用語、略語、専門用語
SEO 用語、略語、専門用語  関連性とランキング - Yandex と Google でのサイトのランキングに影響を与える要因は何ですか?
関連性とランキング - Yandex と Google でのサイトのランキングに影響を与える要因は何ですか?  どのような検索エンジン最適化要素がサイトのパフォーマンスにこのように影響を与えるのでしょうか?
どのような検索エンジン最適化要素がサイトのパフォーマンスにこのように影響を与えるのでしょうか?  テキストの検索の最適化 - キーワードの最適な頻度と理想的な誕生日
テキストの検索の最適化 - キーワードの最適な頻度と理想的な誕生日  サイトのコンテンツ - 独自のコンテンツを追加すると、サイトの日々の開発に役立ちます
サイトのコンテンツ - 独自のコンテンツを追加すると、サイトの日々の開発に役立ちます  メタタグのタイトル、説明、キーワード
メタタグのタイトル、説明、キーワード  Yandex アップデート - 何が起こるか、おっぱいを追跡する方法、サウンドタイプの変更、その他すべてのアップデート
Yandex アップデート - 何が起こるか、おっぱいを追跡する方法、サウンドタイプの変更、その他すべてのアップデート
サウンド システム (PS) は現在、インターネットの重要な部分です。 今日、彼らは必要な情報を見つけるためのツールであるだけでなく、ビジネス上注目の領域にアクセスするためのツールとしても機能する複雑なメカニズムに依存しています。
ほとんどのコリストヴァッハは、自分たちの仕事の原則や、コリストヴァッハの飲み物の加工方法、これらのシステムがどのように作られ機能するかについて考えたこともありません。 この資料は、サウンド マシンのデバイスと基本機能の最適化と理解に携わる人々に役立ちます。
PSの機能と理解
ポシュコバシステム– これは、インターネット上での検索機能に使用されるハードウェアとソフトウェアの複合体であり、任意のテキスト フレーズ (より正確には検索要求) を入力する必要があるユーザーの要求に応答します。関連性に関する情報源。 最も幅広く最大の検索システム: Google、Bing、Yahoo、Baidu。 RunetにはYandex、Mail.Ru、Ramblerがあります。楽しみのために、Yandex システムを例として使用して、最も重要なことを詳しく見てみましょう。
質問は、検索の主題と完全に類似した方法で、できるだけ単純かつ簡潔に作成する必要があります。 たとえば、この検索エンジンでは「自分に合った車の選び方」という情報が知りたいと考えています。 これを行うには、メインページを開いて「車の選び方」を検索します。 その場合、私たちの機能は、これらのメッセージを求めて国境にある情報デスクに行くことに限定されます。

この方法で作業すれば、必要な情報を拒否することができますし、拒否することもありません。 このような否定的な結果を受け取った場合は、リクエストを再フォーマットするだけで済みます。そうでない場合、検索データベースにはこのタイプのリクエストに関する有用な情報がありません (これは、リクエストの「大学」パラメータを指定する場合に完全に可能です。例: 「アナディリでの車の選び方」)。
皮膚聴覚系の最も重要な役割は、人々に必要な情報を提供することです。 そして、生徒にサウンド システムへの「正しい」種類の呼び出し、つまり生徒の作業原則と一致するフレーズを行う習慣を身に付けることは事実上不可能です。
だからこそ、ジョークのファキフツィー投機家たちは、自分たちにとって何が有益かをトレーダーたちに知らせるかのように、ロボットのそのような原則やアルゴリズムを破壊しようとしているのです。 これは、人間がインターネットで必要な情報を検索するときと同じように、システムが「考える」責任を負っていることを意味します。
検索マシンに検索内容を入力すると、最も簡単かつ迅速な方法で必要なものを見つけることができます。 結果を受け取った専門家は、いくつかの基準に基づいてロボット システムを評価し始めます。 必要な情報を見つけることができましたか? とにかく、クエリのテキストを知るために何度そのテキストを再フォーマットしなければならなかったでしょうか? 関連情報はどれくらい失われましたか? Shvidko Poshuk のシステムはこれをどのように処理したのでしょうか? 検索結果はどれくらい簡単でしたか? 望ましい結果が最初に得られましたか、それとも 30 か月目にそれを経験しましたか? 背景から一度にどれだけの「もの」(不要な情報)が見つかったのでしょうか? 時間ごと、時間ごと、年ごと、月ごとに関連する情報は見つかりますか?

そのような食品に適した種類の食品を選択するために、メーカーはランキングの原則とそのアルゴリズムを徐々に改善し、新しい能力や機能を追加し、何らかの方法でより適切に機能するシステムを作成しようとしています。
サウンドシステムの主な特徴
重要な検索の主なパラメータは次のとおりです。ポヴノタ。
繰り返しは検索の最も重要な特性の 1 つであり、検索で見つかる情報ドキュメントの数と、インターネット上で検索できる情報ドキュメントの数に関係します。 たとえば、「車の選び方」という単語が含まれる行が 100 ページあり、同じ検索を行った後、合計数から合計 60 が選択された場合、この場合、検索頻度は 0.6 になります。 検索自体の精度が高くなるほど、学生が必要な文書を見つけられる可能性が高くなるのは明らかです。特に学生は寝ているためです。正確さ。
サウンド システムのもう 1 つの主な機能は精度です。 Vaughn は、Merezha で特定されたページの顧客の対応レベルを示します。 たとえば、「車の選び方」というキーワードには 100 個の文書が含まれており、そのうちの半分にはフレーズが含まれており、残りは単なる単語 (カーラジオの正しい選び方と車への取り付け方) を含むものであれば、それ以上は必要ありません。 50/100 = 0.5 よりも大きくなります。検索の精度が高ければ高いほど、必要な情報の精度も高くなりますが、結果に含まれる「提案」の種類が少なくなり、質問の置き換えに適さない文書が見つかることも少なくなります。
関連性。
重要なのは保存時間です。これは、情報がインターネット上に公開された瞬間から検索エンジンのインデックス データベースに入力されるまでの時間を特徴づけます。たとえば、翌日、新しい iPad のリリースに関する情報が公開された後、多くの人が同様の種類の質問をし始めました。 ほとんどの場合、この新製品に関する情報は、発売されてから時間が経過していますが、すでにオンラインで入手できます。 これは、1 日に数回更新されるスウェーデン拠点の優れたサウンド システムを見れば明らかです。
冗談のようですね。
この弾力性などの機能は、いわゆる「対バンテージ」と密接に関係しています。 検索する場合、膨大な数の人がいるため、1 つの質問を処理するのにかかる時間を大幅に短縮する必要があります。 ここでは、サウンド システムとユーザーの両方の利益が完全に回避されます。ユーザーはできるだけ早く結果を削除したいと考えており、サウンド システムは、今後のリクエストを過剰に処理しないように、このリクエストをできるだけ早く処理する責任があります。リクエスト。完全。
まず、結果を明らかにすることが、検索を成功させるための最も重要な要素です。 舞台裏では、検索システムには数千、場合によっては数百万もの異なるドキュメントが含まれています。 検索のキー フレーズの構成が曖昧であったり、不正確であったりするため、検索の主な結果に必要な情報が含まれていない場合があります。これは、人は与えられた結果の中で自分の考えを実行しなければならないことが多いことを意味します。 PS タイプのページのさまざまなコンポーネントは、サウンド結果をナビゲートするのに役立ちます。
サウンドシステム開発の歴史
インターネットが発達し始めると、常駐のトレーダーの数は少なく、アクセスできる情報の量もまだ少なかった。 この領域へのアクセスは、科学および研究分野の人々に限定されています。 当時は情報に関する知識が今ほど重要ではありませんでした。情報リソースへの幅広いアクセスを組織する最初の方法の 1 つは、サイトのディレクトリの作成であり、サイト上のメッセージがトピックごとにグループ化され始めました。 1994 年の春に登場した Yahoo.com というリソースは、そのような最初のプロジェクトとなりました。 今年、Yahoo カタログに掲載されるサイトの数が大幅に増加したため、必要な情報をカタログから検索するオプションが追加されました。 このような検索の範囲は、インターネット上のすべてのリソースではなく、このディレクトリに含まれるサイトによってのみ制限されているため、世界にはまだ完全な検索システムは存在しません。 偉人に送られるカタログは、かつてはよく使われていましたが、今ではほとんど見られなくなりました。
今日の優れたカタログにも、インターネット上の少数のサイトに関する情報が含まれています。 世界で最も人気があり最大のカタログには、約 500 万のサイトの情報が含まれています。Google データベースには 250 億を超えるサイトの情報が含まれています。

世界で最も人気のある検索エンジンは WebCrawler で、その歴史は 1994 年に遡ります。
来たる運命に現れたのはAltaVistaとLycos。 さらに、ペルシャは非常に困難な時期に情報探索のリーダーでした。

1997 年、セルギー ブリンはラリー ペイジとともに、スタンフォード大学のフォローアップ プロジェクトとして Google 検索エンジンを作成しました。 現在、Google は世界で最も人気のある検索エンジンです。

1997 年の春に、Yandex PS が (公式に) 発表され、Runet で最も人気のある検索システムになりました。

追悼の意を表して 2015年春 ロク, 世界中のサウンド システムの部品は次の順序で分類されます。
- Google – 69.24%;
- ビング – 12.26%;
- ヤフー! - 9.19%;
- 百度 – 6.48%;
- AOL – 1.11%;
- 尋ねる - 0.23%;
- エキサイト - 0.00%

追悼の意を表して ブレスト2016 ロク、Runet 上のサウンド システムの一部:
- ヤンデックス - 48.40%
- グーグル – 45.10%
- Search.Mail.ru - 5.70%
- ランブラー – 0.40%
- ビング – 0.30%
- ヤフー - 0.10%

ロボットサウンドシステムの原理
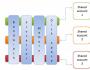
ロシアの主な検索システムは Yandex、次に Google、そして [email protected] です。 すべての優れたシステムは、他のシステムから分岐するにつれて、その構造を模索しています。 ただし、すべてのサウンド システムに不可欠な基本要素はまだわかります。インデックス作成モジュール。
このコンポーネントは 3 つのソフトウェア ロボットで構成されます。クモ(英語では pavuk) は、Web ページを引き付けるように設計されたプログラムです。 「Pavuk」はこの曲の歌を魅了し、そこからすべてのメッセージを瞬時に引き出します。 HTML コードは実質的にスキン側からエンチャントされます。 この目的のために、HTTP プロトコルを使用します。

「Pavuk」はこんな感じで機能します。 ロボットは、HTTP を使用してサーバー「get/path/document」およびその他のコマンドにリクエストを送信します。 それに応じて、ロボット プログラムはテキスト フローを選択し、情報をサービス ビューに、そしてもちろんドキュメントに配置します。
- 目的のページの URL。
- サイトが作成された日付。
- サーバーの http-video ヘッダー。
- HTMLコード、ページの「本文」。
インデクサ(ロボット インデクサー) は、スパイダーがダウンロードしたページを分析するプログラムです。

インデクサーはウェアハウス要素を徹底的に分析し、独自の形態学的および語彙的なタイプのアルゴリズムを使用して分析を実行します。
分析は、見出し、テキスト、メッセージ、スタイルと構造の特徴、HTML タグなど、ページのさまざまな部分に対して実行されます。
したがって、インデックス作成モジュールを使用すると、指定された数のリソースを調べ、ページをキャプチャし、押収されたドキュメントから新しいページへのメッセージを抽出し、それらのレポート分析を実行できます。
データベース
データベース(または検索エンジンインデックス) - データ保存の複合体、インデックスモジュールによって取得されたスキンのパラメータと保存されたドキュメントを再処理する最初のステップによって保存される情報の配列。サウンドサーバー
これは、このシステムの最も重要な要素です。その機能の中核にあるアルゴリズムのタイプには、流動性、特に酸性が直接含まれているためです。サウンド サーバーは通常どおりに動作します。
- キストゥヴァッハから出た種子は形態学的分析の対象となります。 データベース内にあるドキュメントに固有の情報が生成されます (情報は後でスニペット、つまりこのクエリに対応するテキストの情報フィールドとして表示されます)。
- 抽出されたデータは、入力パラメータとして専用のランキング モジュールに渡されます。 すべての文書がレビューされ、そのような各文書の結果には独自の評価が割り当てられます。これは、そのような文書と販売者および他の倉庫との関連性を特徴づけます。
- 特派員によって割り当てられた評価に基づいて、この評価は追加の評価によって完全に修正できます。
- そうすれば、シギ自体が生成されます。 概要テーブルで見つかった文書について、クエリに最もよく似たタイトル、要約、およびこの文書のメッセージ (語形が見つかり、語が強調表示されている) を選択します。
- 検索結果は、検索結果が表示されるページ (SERP) で検索結果を作成したユーザーと共有されます。
裕福なトレーダーにとって、インプットとインプットを選択するためにインターネットは必要です。
あたかも検索システムがなかったかのように、コリストヴァッハたちは必要な場所を独自に検索し、記憶し、記録しなければなりませんでした。 このような状況では、何が必要かを「手動で」知ることはさらに困難であり、多くの場合、単純に不可能です。
私たちの場合、これらすべての日常的な作業は、Web サイト上の情報を検索、保存、分類することで行われます。
Runet の既知の検索システムについて話しましょう。
ロシアのインターネット上の検索システム
1) ハムサウンドシステムから始めましょう。 Yandex はロシアだけでなく、ベラルーシ、カザフスタン、ウクライナ、トルコでも事業を展開しています。 Yandexの英語版も。
2) Google 検索エンジンはアメリカから提供され、ロシア語にローカライズされています。
3) 人気の検索エンジン Mail ru。Mail.ru やその他のプロジェクトで見られるソーシャル ネットワーク VKontakte、Odnoklassniki、および My World を同時に表します。
4) インテリジェントな検索システム
ニグマ(ニグマ) http://www.nigma.ru/
2017 年 6 月 19 日、知的ニグマは機能しません。 作成者にとって金銭的な利益を表すことはなくなり、CocCoc と呼ばれる別の検索システムに切り替えました。
5) 国内では、ロステレコム社がスプートニク検索システムを作成しました。
そして、特に子供向けのジョーカー「サプトニク」については、私が書きました。
6) Rambler は、最初に人気のある検索エンジンの 1 つでした。
世界には他にも次のような種類のサウンド システムがあります。
- ビング、
- ヤフー、
- 百度、
- エコシア、
検索システムがどのように機能するのか、サイトがどのようにインデックス付けされるのかを理解し、インデックス付けの結果を分析し、検索結果を定式化してみましょう。 サウンド システムの動作原理はほぼ同じです。顧客から関連情報を取得するために、インターネット上で情報を検索し、保存し、分類します。 また、サウンド システムが動作するアルゴリズムは大きく異なる場合があります。 これらのアルゴリズムは秘密にされ、その不一致は保護されています。
同じ信号を異なるサウンド システムの列に挿入することで、異なるタイプを選択できます。 その理由は、すべての検索エンジンが強力なアルゴリズムを使用しているためです。
サウンドシステムのメタ
まず、サウンドシステムは営利組織であることを知る必要があります。 それはメタオトリマナヤ利益です。 利益は、コンテキスト広告やその他の種類の広告、および不要なサイトを上位行に配置することで収集できます。 方法はたくさんあります。
それは視聴者の規模と、この検索システムを使用する人の数によって異なります。 視聴者数が多いほど、より多くの人に広告が表示されます。 どうやら、広告が増えるようです。 検索エンジンは、広告コストを削減することで検索エンジンの視聴者を増やすことができ、また、サービスの容量、アルゴリズム、検索の信頼性を削減することで検索エンジンの収益性を高めることができます。
ここで最も高度かつ複雑なことは、より多くの顧客のクエリに対して関連する結果を生成する、完全に機能する検索アルゴリズムの開発です。
検索エンジンとウェブマスターの仕事
皮膚穿刺システムには独自の強力なアルゴリズムがあり、情報を分析する際に多数のさまざまな要素を組み込み、医師の要求に対する複雑な種類の応答を行います。
- あちこちのサイトの世紀、
- Webサイトのドメイン特性、
- サイトの内容が明確なので、
- ナビゲーションとサイトの構造の特殊性、
- ユーザビリティ(経営者にとっての有用性)、
- 行動関係者 (検索エンジンは、サイトに対する答えを知っている人、および検索システムに戻ってそこで同じ質問に対する答えを再度検索する人によって特定されます)
- 等
これらすべては、飲む飲み物が可能な限り関連性があり、飲む飲み物があなたを満足させるために必要です。 その結果、サウンドシステムのアルゴリズムは徐々に変化し、洗練されています。 どうやら、徹底的さが欠けているわけではありません。
その一方で、ウェブマスターやオプティマイザーはサイトを宣伝するための新しい方法を常に考え出していますが、それは常に公平であるとは限りません。 検索エンジンのアルゴリズムへの指示 - 不正なオプティマイザーの「汚い」サイトがトップに表示されないように、次の変更の前に変更を加えてください。
検索システムはどのように機能しますか?
次に、サウンドシステムがどのように問題なく動作するかについて話しましょう。 これは少なくとも 3 つの段階で構成されます。
- 走査、
- インデックス作成、
- ランキング。
インターネット上のサイトの数はまさに天文学的です。 そしてスキンサイトとは、読者(生きている人)によって生み出される情報、情報コンテンツです。
スカヌヴァンニャ
これは、インターネットを検索して新しい情報を収集し、メッセージを分析し、質問に対する回答を得るために検索できる新しいコンテンツを検索することを意味します。 スキャンのために、サウンド システムにはサウンド ロボットまたはスパイダーと呼ばれる特別なロボットが搭載されています。
検索ロボットは、Web サイトを自動的に移動し、Web サイトから情報を収集するプログラムです。 Skanuvannya mozhe buti pervinnim (ロボットは最初に新しいサイトに行きます)。 サイトから最初に情報を収集し、検索エンジンのデータベースに入力した後、ロボットは定期的にそのページにアクセスし始めます。 何らかの変更が加えられた場合 (新しいコンテンツが追加され、古いコンテンツが削除された場合)、これらすべての変更は検索エンジンによって記録されます。
検索エンジンの主なタスクは、新しい情報を検索し、それを次の処理段階、つまりインデックス作成のために検索エンジンに提供することです。
インデックス作成
検索エンジンは、データベースに既にリストされている (データベースによってインデックス付けされている) サイトからの情報のみを検索できます。 クロールが別のサイトから情報を検索して収集するプロセスであるのと同様、インデックス作成はこの情報を検索エンジンのデータベースに入力するプロセスです。 この段階で、検索エンジンは、この情報やその他の情報をデータベースに入力する方法と、データベースのどのセクションに入力するかを自動的に決定します。 たとえば、Google は、自社のロボットがインターネット上で見つけたほぼすべての情報をインデックス化しますが、Yandex はより強力であり、すべてをインデックス化するわけではありません。
新しいサイトの場合、インデックス作成の段階が長くなる可能性があります。つまり、検索エンジンのせいで、新しいサイトのスキャンに長時間かかる可能性があります。 そして、古い、ねじれていないサイトに表示される新しい情報は、できるだけ早くインデックス付けされ、ほぼ即座に「インデックス」に登録され、検索エンジンのデータベースに登録されます。
ランジュヴァンニャ
ランキングとは、事前にインデックス付けされ、ランクに従って検索エンジンのデータベースに入力された情報の選択であり、検索エンジンが対応者にどのような情報を事前に表示し、どの情報が送信されるかを決定します。より低い「ランク」を探しています。 ランキングは、クライアント、つまり顧客のサウンド システムをサービスする段階に持ち込むことができます。
検索システムのサーバー上では、さまざまなクエリに対してデータが処理されます。 ここでロボットはジョーク アルゴリズムを使い始めます。 すべてのサイトはデータベースに入力され、トピックに従って分類され、トピックはクエリのグループに分割されます。 アプリケーションのグループのスキンに応じて、正面図を折りたたむことができ、それに応じて調整されます。
ブログ サイトの読者の皆さん、こんにちは。 、その後、無数のkoristuvachsが十分なパワーブックマークを持っていました。 しかし、ご記憶のとおり、等比級数の進歩を経て、その多様性のすべてをナビゲートすることがより困難になってきました。
その後、作成者がさまざまなサイトを追加してカテゴリに分類したカタログ (Yahoo、Dmoz など) が登場しました。 これにより、世界規模で利益を得ている人の数よりもまだ数が多い人々の生活がすぐに楽になりました。 ライブカタログもたくさんあります。
わずか 1 時間後、データベースのサイズが非常に大きくなったため、開発者はすぐにデータベース間の検索を作成し、インターネット上のあらゆるものにインデックスを付ける自動システムを作成して、誰でもアクセスできるようにすることを考え始めました。彼らが怖いんだ。
ロシアのインターネットセグメントの主要なサウンドシステム
ご想像のとおり、このアイデアは実装されて大成功を収めましたが、すべてがうまくいったのは、インターネット上で生き残ることができたほんの一握りの企業だけでした。 おそらく、初版に登場したすべてのサウンド システムは、登場したか、まだ生きているか、遠く離れた競合他社に購入されたかのいずれかです。
サウンド システムは非常に複雑で、重要なことに、リソースを大量に消費するメカニズムです (危険にさらされているのは物質的なリソースだけでなく、人間のリソースも含まれます)。 この呼び出し、またはその禁欲的な Google の類似物の背後には、数千のスパイウェア、数十万のサーバー、そしてこのマシンが動作し続けるために必要な数十億ドルの預金があり、競争上の優位性を失いました。
この市場に一気に参入し、ゼロから始めることは、実際のビジネスプロジェクトというよりも、理想郷のようなものです。 たとえば、世界最大手の企業の 1 つである Microsoft は、何十年にもわたって検索市場での足場を築こうとしてきましたが、現在、同社の検索エンジン Bing がその洞察を徐々に証明し始めています。 それまで失敗や失敗はほとんどありませんでした。
特別な資金流入なしにこの市場に参入する必要がある人々については何が言えるでしょうか。 たとえば、当社の自家製サウンド システム Nigma には多くの価値と革新性があり、その進歩はロシア市場のリーダーに何千回も提供されています。 たとえば、Yandex のオーディエンスを見てみましょう。

これに関連して、RuNet とインターネット全体の主要な (最短かつ最も成功した) 検索エンジンのリストがすでに作成されており、全体の陰謀は主に誰が、何で殺害されたかにあることを考慮することができます。すべての悪臭が完全に除去されるため、それらを分割する順序はパーセンテージではありません。 そして浮いて負けます。
ロシアのサウンドシステム市場とても見栄えがよく、ここではメロディアスに、2 つまたは 3 つの主要な砂利とその他のいくつかの砂利が見えます。 RuNet では、独特の状況が発生しており、私の理解では、世界で 2 か国だけでそれが繰り返されています。
私が言っているのは、2004 年にロシアに登場した Google の検索エンジンが、まだリーダーシップを発揮できていないもののことです。 実際、この時期に悪臭が現れ始め、Yandexを購入しましたが、そこではうまくいかず、同時に「私たちのロシア」、チェコ共和国、中国、そしてこれらの場所、全能のGoogleは認識していませんでした。損傷がある場合は、重大な問題があることを受け入れます。
ほんと、真ん中の生産工場を改善してよ RuNet で最高のジョークたぶん誰か。 この URL をブラウザのアドレス バーに貼り付けるだけです。
http://www.liveinternet.ru/stat/ru/searches.html?period=month;total=yes
右側は、ほとんどのヴィコリストが自分のサイトにアクセスしていることを示しています。この URL を使用すると、さまざまな検索エンジンから RU ドメイン ゾーンに属するすべてのサイトへの広告のアクセスに関する統計を取得できます。
指定された URL を入力すると、魅力的で見栄えがしすぎなくなりますが、画像の本質をより適切に表現できます。 ロシアのサイトがトラフィックを削除する最初の 5 つの検索エンジンに注目してください。

したがって、もちろん、ロシアのコンテンツを含むすべてのリソースがこのゾーンにあるわけではありません。 また、SU、RF、COM や NET などの隠しゾーンでは、RuNet を対象としたインターネット プロジェクトもありますが、それでもなお、その選択は依然として非常に代表的です。
たとえば、プレゼンテーションに次の措置を講じることにより、このコンテンツをさらに迅速に整理できます。

本質は変わりません。 数人のリーダーと数多くの優れたサウンド システム。 話す前に、私はすでにそれらの多くについて書きました。 場合によっては、成功の歴史を掘り下げること、あるいはおそらく、有望なサウンド システムが失敗した理由を掘り下げることが難しいこともあります。
そうですね、これらはロシアと RuNet 全体にとって重要なので、話を中断して短いデモンストレーションを行います。
地球上の裕福な住民にとって、Google 検索は時代遅れになっています。つまり、そのために読むことができるものについてです。 この検索システムでは、世界中や自分の家族からシグナルを収集した場合、「結果転送」オプションが必要ですが、残念ながらそれは利用できません(google.ru で受け入れられます)。 。

したがって、残りの時間はより少なくなり、彼らの種の輝きが失われます (検索エンジンの結果ページ)。 特に、RuNet ミラーの検索システム (その前に話している音です) を最初から始めていますが、賢明な方法がわからないので、Google に行きます。
彼らの姿を見て、私は幸せでしたが、それ以外の時間はただ眠いだけで、1時間も過ごすのはとても腹立たしいです。 コンテクスチュアル広告からの収入を増やそうとする現在の苦闘と、SEO プロモーションの信頼性を損なう手段としての絶え間ない入れ替えが転換点につながる可能性があります。 RuNet には、同様の検索エンジンを備えた有名な競合他社があります。
Runet で検索するために、特に Go.mail.ru にアクセスする可能性は低いと思います。 したがって、検索システムを使用する重要なプロジェクトのトラフィックははるかに多くなり、少なくとも 1000 になる可能性があります。 このようなプロジェクトの所有者は、このシステムに対する敬意を高める必要があります。
しかし、インターネットのロシア分野における検索エンジン市場のリーダーの明確な表明に加えて、多くのトレーダーも存在し、中には低位のトレーダーもおり、その存在自体の事実にもかかわらず、彼らについて一言言うのは難しい。
別の階層からの RuNet の検索システム

インターネット全体のサウンド システム
偉大なラクンコの背後には、インターネット全体の規模で、深刻な墓は 1 つだけあります。 グーグル。 これはクレイジーなリーダーですが、それでも競争はあります。
まず、それは今でも同じです ビングたとえば、同社はアメリカ市場で非常に良い地位を占めており、特にそのエンジンはすべての Yahoo サービス (アメリカによるとおそらく市場全体の 3 分の 1) で同じように勝利を収めていると考えられています。

そうですね、別の方法で、世界の大部分で、中国のコリストヴァッハがインターネット上のほとんどのコリストヴァッハに入れているのは、彼らのメインのサウンドシステムです。 百度光オリンパスの中心にくさびが入っています。 2,000人が誕生し、そのシェアは現在、中国全土の視聴者の80%近くを占めています。
Baida についてこれを明確に言うことが重要ですが、インターネット上では、このトップの場所が最も関連性の高いサイトだけでなく、料金を支払ったサイト (サイトの真ん中ではなく) によっても占められる傾向が強まっています。検索エンジン)、SEO オフィスではありません)。 もちろん商業的な面以前に困っています。

この統計を見れば、なぜ Google がコンテンツ連動型広告からの収入増加と引き換えにデータを失うことをいとわないのかが明らかになります。 実際、彼らは傭兵の流れを恐れていません。なぜなら、ほとんどの場合、彼らには行くところがないからです。 この状況では少し退屈してしまいますが、次に何が起こるのか気になるでしょう。
話す前に、オプティマイザーの仕事をさらに困難にするため、そしておそらく検索エンジンの平静を促すために、Google は最近、ブラウザから検索エンジンにリクエストを送信する際に停滞暗号化を導入しました。 間もなく、人々がどのような種類のクエリのためにGoogleから来たのか、医師や医師の統計に表示されなくなります。
もちろん、この出版物で言及されているサウンド システムに加えて、地域的なもの、専門的なもの、エキゾチックなものなど、他にも何千ものサウンド システムがあります。 それらを 1 つの記事内で過剰に説明して説明することは不可能ですし、率直に言ってその必要はありません。 それらについて簡単に言ってみましょう 冗談を言うのは簡単ではないそして、彼に最新の情報を提供し続けるのは簡単でも費用もかかりません。
ほとんどのシステムが同様の原則に基づいて動作し (それらについて読んでください)、同じ基準に従って、供給に関してクライアントにフィードバックを提供することが重要です。 さらに、証拠は関連性があり(栄養に相当)、包括的であり、重要でないわけではありませんが関連性があります(主な鮮度)。
この問題を見つけることは、特に医師にとってはそれほど簡単ではありません。なぜなら、検索システムは数十億のインターネットページ、アプリケーションの種類、リストを作成する能力を失った人々を分析する必要があるからです(どうやら)最初からそこにありましたkoristuvachaの栄養補給に最も適した品種になります。
この余分なタスクは、他のページに加えて、これらのページからの情報の前方収集に基づいています。 インデックスロボット。 以前に公開されたページからメッセージを収集し、その情報を検索システム データベースにインポートします。 テキストにインデックスを付けるロボットがあります (プライマリおよび流動的なもので、新しいリソースや頻繁に更新されるリソースを利用しているため、常に最新のデータが表示されます)。
さらに、ロボットはインデクサーを使用して画像 (さらに表示するため)、ファビコン、ミラー サイト (さらに配置し、接着するため) を表示し、ロボットはウェブマスター用のツール (ここで、コアなど) のインターネット ページの機能をチェックします。について読んでください)。
インデックス作成自体のプロセスとその後のインデックス データベースの更新プロセスには数時間かかります。 Google が競合他社ともっと競争したい場合は、Yandex を雇いましょう。これには 1 ~ 2 週間の価値があります (詳細をお読みください)。
インターネット ページの代わりにテキストを呼び出すと、サウンド エンジンが単語を基本原理に分解して、さまざまな形態で提供される単語に対して正しい答えを与えることができます。 クールなものはすべて Html タグやクリアリングのように見えます。 スピーチは削除され、欠落している単語はアルファベット順に並べ替えられ、本書内での位置が示されます。
このツールはゲートウェイ インデックスと呼ばれ、Web サイトではなく、検索システムのサーバー上にある構造化データを検索できます。
そのようなサーバーの数は、Yandex (主にロシア語サイトといくつかのウクライナ語とトルコ語サイトに基づいています) では数万、場合によっては数十万台に達し、Google (数百の単語に基づいています) では数百万台に上ります。
多くのサーバーはコピーを作成します。これはドキュメントを保存する手段として機能し、(追加のデータ処理の助けを借りて) データ処理の速度を上げるのに役立ちます。 全員の統治を支援するための支出を見積もってください。
そのサーバー セグメント上で Zapit koristuvach nadsilatimetsya balansuvalnik navantazhennya を実行します。これは、少なくとも一度に navantazhennya になります。 次に、リクエストを送信したサウンドシステムからのデータを使用して領域の分析が実行され、形態素解析が実行されます。 同様のコマンドが最近検索シーケンスに導入された場合は、サーバーに干渉しないようにキャッシュからデータを追加する必要があります。
リクエストがまだキャッシュされていない場合、リクエストはリージョンに転送され、検索エンジンのインデックス データベースが分解されます。 質問する前に問い合わせることができるすべての既存のインターネット サイトのリストが表示されます。 直接入力として保証する、その他の形態的な形式など。 スピーチ。
イクス 改修する必要があるどの段階でアルゴリズム(ピースインテリジェンス)が右側に入ります。 実際、特派員のリクエストは、彼の解釈のすべての可能な変形の範囲で乗算され、クエリがない場合はすぐに検索されます(他のコリストヴァチャムが利用できる検索クエリのさまざまな演算子の範囲について)。
原則として、各種には片側の皮膚部位があります(場合によってはそれ以上)。 今日、多数の役人に保険を提供することはさらに困難になっています。 さらに、修正するには参照サイトを手動で評価する必要があるため、ロボットは全体としてアルゴリズムを修正できます。
ザガロム、澄んだ川、右側の暗いもの。 このプロセスについては長く語れますが、サウンド システムに満足のいくものを得るのは簡単ではないことは明白です。 そして将来的には、あなたや私のような、心優しい読者のような、これが当てはまらない人たちが現れるでしょう。
頑張って! ブログサイトでお会いしましょう
困っているかもしれない
Yandex People - ソーシャルネットワークで人々にいたずらする方法 Apometr - サウンド システムの変更、種類、アップデートをサポートする無料のサービス DuckDuckGo - あなたをフォローしない検索システム  インターネットの速度を確認する方法 (Spidtest、Yandex の Internetometer)
インターネットの速度を確認する方法 (Spidtest、Yandex の Internetometer)  Yandex ウィジェット - メイン ページをカスタマイズして、より有益で使いやすいものにする方法
Yandex ウィジェット - メイン ページをカスタマイズして、より有益で使いやすいものにする方法  Yandex および Google の画像、および Tineye および Google での画像ファイルの検索 SEObuilding.RU のサイトを更新し、購入時に寄付者候補を無料で分析できるようにする Google アラート - それはどのようなもので、どのようなものですか?
Yandex および Google の画像、および Tineye および Google での画像ファイルの検索 SEObuilding.RU のサイトを更新し、購入時に寄付者候補を無料で分析できるようにする Google アラート - それはどのようなもので、どのようなものですか?  右側は、インターネットを介したオンライン会計または電子文書管理の様子です。
右側は、インターネットを介したオンライン会計または電子文書管理の様子です。  無料のファイル共有サービス - 写真をアップロードし、写真からメッセージを削除する方法
無料のファイル共有サービス - 写真をアップロードし、写真からメッセージを削除する方法