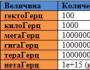
GPU計算の拡張。 GPU の最適化 - 大いなる真実。 ビデオカードでのマイニング - 簡単なペニーと虚偽
GPUの並列充電について言えば、私たちは記憶に罪を犯しています。私たちが住んでいるある時間、今年のこの時期に、世界中のすべてが床に固定されている場合、覚えていないかのように1時間あなたと過ごします通り過ぎていました。 私たちの仕事はすべて、情報の処理の高精度と速度に関連しています。そのような心の中で、すべての情報を処理するためには常にツールが必要であり、データに変換する必要があるため、それまではこれらのことを覚えておく必要があるようです。タスクは、偉大な組織だけでなく、メガ企業にとっても必要です。そのようなタスクの台頭は、まるで彼らが自分のタスクの生活に違反しているかのように、自宅でパソコンで高度な技術を扱っているかのように、コリストヴァッハの列を必要とします。 NVIDIA CUDA の出現は驚くべきものではありませんでしたが、PC で非常に面倒なタスクを完了する必要があるとすぐに、より速く、準備が整いました。 以前はかなりの時間を要していたこの作業は、今では少し時間がかかります。全世界の全体像で問題なく進行しています。
GPUでの計算は何ですか
技術的、科学的、オンボトムタスクの計算のための GPU の計算のための GPU での計算。 GPU での計算は、CPU と GPU の数に基づいており、それらに似た s の選択が異なります。プログラムの最後の部分は CPU によって分類され、GPU によって同じ方法でワークロードが計算されます。 . このため、タスクの数を増やす必要があります。これにより、情報の処理と作業時間の変更ができるだけ早く実行され、システムの生産性が向上し、より迅速に、より早く処理できるようになります。 . ただし、このような成功を収めるには、ハードウェア サポートだけでは十分ではありません。この場合、プログラムがほとんどの人件費を GPU に転送できるように、ソフトウェア サポートが必要です。
CUDAとは
CUDA は私の C アルゴリズムによって簡略化されたプログラミング テクノロジであり、第 8 世代以降の GeForce プロセッサのグラフィックス プロセッサや、NVIDIA の同様の Quadro および Tesla カードで使用されています。 CUDA を使用すると、C プログラム テキストに特別な機能を含めることができます。 これらの関数は、私の C プログラムによって簡略化された方法で記述され、グラフィック プロセッサ上に記述されます。 CUDA SDK の最初のバージョンは、2007 年 2 月 15 日にリリースされました。 コードを CUDA SDK ウェアハウスに正しく変換するには、NVIDIA コマンド ライン C コンパイラ nvcc を含める必要があります。 Open64 オープン ソース コンパイラに基づく nvcc 作成のコンパイラと、ホスト コード (ヘッド、キー コード) およびデバイス コード (ハードウェア コード) (.cu 拡張子を持つファイル) をオブジェクト ファイルに変換するための割り当て、コンパイル プロセスの付録Microsoft Visual Studio などの任意のプログラミング環境のプログラムまたはライブラリ。
技術の可能性
- GPU上でプログラムを並列開発するための標準言語C。
- Fur'є のスウェーデン語変換と線形代数プログラムの基本パッケージの数値解析の準備が整ったライブラリ。
- GPU と CPU 間でデータを計算および転送するための特別な CUDA ドライバー。
- CUDA ドライバーのインターモダリティの可能性 グラフィックス ドライバー OpenGL と DirectX。
- オペレーティング システム Linux 32/64 ビット、Windows XP 32/64 ビット、および MacOS のサポート。
技術の進歩
- CUDA プログラム (CUDA API) のプログラミング インターフェイスは、既存の交換機を使用した標準のモバイル Cі プログラミングに基づいています。 CUDA アーキテクチャの開発プロセスをスムーズに進めます。
- ストリーム間で分割される 16 Kb のサイズのメモリ (共有メモリ) は、優れたテクスチャを選択して、より低い帯域幅の広い範囲でキャッシュを編成するために分割できます。
- CPU メモリとビデオ メモリ間のより効率的なトランザクション。
- 繊毛および並列操作のための Povna ハードウェア サポート。
stosuvannya 技術の例
クラーク
このプログラムの最も良い点は注入です。 プログラムにはコンソール インターフェイスがありますが、プログラム自体にアクセスする方法についての説明があり、破損している可能性があります。 指し示す距離 短い指示 s nalashtuvannya プログラム。 プログラムの実用性をチェックし、NVIDIA CUDA とは異なる別の同様のプログラムと比較します。この場合、Advanced Archive Password Recovery プログラムを使用します。
ダウンロードした cRark アーカイブから必要なのは、crark.exe、crark-hp.exe、password.def の 3 つのファイルだけです。 Сrark.exe コンソールユーティリティアーカイブの途中で暗号化されたファイルを使用せずに RAR 3.0 パスワードを解凍します (したがって、アーカイブを開くときに名前を付ける必要がありますが、パスワードなしでアーカイブを解凍することはできません)。
Сrark-hp.exe - アーカイブ全体の暗号化から RAR 3.0 パスワードを抽出するためのコンソール ユーティリティです (したがって、パスワードなしではアーカイブに名前を付けたり抽出したりすることはできません)。
Password.def - テキスト ファイルの名前を少しでも変更したい場合 (例: 1 行目: ## 2 行目: ?*、この場合、パスワードの違いは一般的な記号から取得する必要があります)。 Password.def - cRark プログラムのチェーン。 ファイルには、パスワードを開くためのルールがあります (そうしないと、crark.exe のような記号の領域がロボットからハッキングされます)。 これらの兆候を選択する可能性についてのレポートは、サイトの cRark プログラムの作成者の選択から取られたテキスト ファイルに書かれています: russian.def .
準備
ビデオ カードが CUDA 1.1 アクセラレーション レベルの GPU に基づいている場合にのみ、プログラムが機能することをもう一度お伝えします。 そのため、GeForce 8800 GTX などの G80 チップをベースにした一連のビデオ カードは、CUDA 1.0 ハードウェアのアップグレードがうまくいかない可能性があるため、機能しなくなります。 プログラムは、バージョン 3.0+ の RAR アーカイブの CUDA のみのパスワードの助けを借りてピックアップします。 すべてをインストールする必要があります ソフトウェア セキュリティ、これは CUDA に関連していますが、それ自体に関連しています:
- 169.21 以降の CUDA をサポートする NVIDIA ドライバー
- NVIDIA CUDA SDK、バージョン 1.1 以降
- NVIDIA CUDA ツールキット、バージョン 1.1 以降
特定の場所 (たとえば、C: ドライブ) にフォルダーを作成し、「3.2」という名前を付けます。 次のファイルを使用します: crark.exe、crark-hp.exe、password.def、および RAR アーカイブのパスワード保護/暗号化。
次に、Windows コマンド ライン コンソールを実行し、作成したフォルダーに移動します。 Windows Vista では、スワイプして [スタート] メニューをクリックし、プロンプト フィールドに「cmd.exe」と入力します。Windows XP では、[スタート] メニューから [Vikonati] ダイアログを右クリックし、プロンプト フィールドに「cmd.exe」と入力します。新しいもの。 コンソールを開いた後、cd C:\folder\, cd C:\3.2 のようなコマンドを任意の方法で入力します。
ダイアルイン テキストエディタ暗号化されていないファイルを含むパスワードで保護された RAR アーカイブのパスワードを選択するには、2 行 (cRark フォルダーからテキストを .bat ファイルとして保存することもできます):
エコーオフ;
cmd /K crark (アーカイブに名前を付ける).rar
パスワードで保護され、暗号化された RAR アーカイブのパスワードを選択するには:
エコーオフ;
cmd /K crark-hp (アーカイブ名).rar
テキスト ファイルの 2 行をコンソールにコピーし、Enter キーを押します (または .bat ファイルを実行します)。
結果
小さな子供の証言を解読するプロセス:
CUDA の助けを借りて cRark を取得する速度は、1625 パスワード/秒でした。 36 秒の間に、パスワードは「q)$」の 3 文字から選択されました。 明確にするために: 私のデュアルコア Athlon 3000+ プロセッサでの Advanced Archive Password Recovery ブルート フォースは最大 50 パスワード/秒であり、ブルート フォースは 5 年間有効です。 そのため、追加の GeForce 9800 GTX+ ビデオ カード用の cRark のブルートフォース RAR アーカイブは、CPU 使用率が低く、30 倍速く表示されます。


Intel プロセッサを搭載している場合は、システム バスの周波数が高い (FSB 1600 MHz) マザーボードが適しています。CPU レート インジケーターと検索速度が高くなります。 また、choti-core プロセッサと GeForce 280 GTX と同等のビデオ カードのペアがある場合、ブルート フォース コードはパスワードのブルート フォースを高速化します。 このタスクは合計 2 年間 CUDA テクノロジから取り除かれたことを言う必要があります。このテクノロジの高い可能性について話す価値があります。
ヴィスノフキ
並列 CUDA 計算のための今日の技術を調べた結果、RAR アーカイブのパスワード回復プログラムのアプリケーションにこの技術を開発する大きな可能性を思いつきました。 この技術の展望について言わざるを得ません。 与えられた技術スキンパーソンの生活の中での場所、それをすばやく書く方法、科学的なもの、ビデオの処理に関連するchi zavdannya、またはスウェーデンの正確なロズラフンカのような経済的なタスクを作成する方法を常に知っていますが、それでも非生産的です。思い出せない。 今日、用語集にはすでに「家庭用スーパーコンピューター」というフレーズが含まれ始めています。 このようなオブジェクトを現実のスキン ブースに挿入するために、CUDA というツールが既に存在することは明らかです。 G80 チップに基づくカードのリリース (2006 年) 以来、多くの NVIDIA ベースのカードが CUDA テクノロジをサポートするためにリリースされ、スキン ブースにスーパーコンピュータの夢を実現する方法が実現されました。 CUDA テクノロジを推し進めることで、NVIDIA は顧客の目から見た信頼性を高めます 追加機能їх obladnannya、ヤクはすでに金持ちから購入されています。 CUDA がすぐにさらに急速に発展し、GPU での並列計算のすべての可能性を高速化するために全世界を colistuvachi に提供するという希望はほとんどありません。
AMD/ATI Radeon アーキテクチャの機能
それは、新しい生物種の人々に似ています。球体の発達中に、中間への愛着の拡大のために生きている基盤が進化する場合です。 そのため、トリックのラスター化とテクスチャ レンダリングを高速化した GPU は、これらのトリックをレンダリングするためのシェーダー プログラムをさらに改善しました。 Іtsіzdіbnostiは、従来のソリューションに対して生産性を大幅に向上させるために、非グラフィカルな計算からの問い合わせを表示しました.
私たちは遠くに類推を描きます-陸上での長期的な進化の後、海は海に浸透し、大きな海の袋を押し下げました。 激しい戦いの中で、賢者たちは勝利を収め、あたかも地球の表面に現れたかのように新しい景色として出現し、水を飲むことによって生活に特別に適応しました。 したがって、GPU 自体は、3D グラフィックスのアーキテクチャの最前線に根ざしており、遠いタイプのグラフィックスのビジョンと同様に、Daedalus は特別な機能を獲得する可能性が高くなります。
では、GPU がソフトウェア認識の分野で力を発揮できるのはなぜでしょうか? GPU のマイクロアーキテクチャは、標準の CPU よりも低く、そもそも主な利点の基盤である別の方法で触発されました。 グラフィックス マネージャーはデータの独立した並列処理を実行し、GPU はマルチスレッドです。 あなたへのエールtsya並行性は喜びではありません。 マイクロアーキテクチャは、ウィッキングを必要とする多数のスレッドを活用するように設計されています。
GPU は数十個 (Nvidia GT200 では 30 個、Evergreen では 20 個、Fermi では 16 個) のプロセッサ コアで構成され、Nvidia の用語ではストリーミング マルチプロセッサ、ATI の用語では SIMD エンジンと呼ばれます。 この記事の枠内では、それらをミニプロセッサと呼びます。なぜなら、それらは何百ものプログラム スレッドを処理する可能性があり、すべて標準 CPU と同じかもしれませんが、それでもすべてではないからです。
マーケティング名は誤解を招く可能性があります。重要性を高めるために、機能モジュールの数を示しています。たとえば、320 個のベクトル「コア」(コア) などです。 Qi カーネルはより多くの穀物を推測します。 GPU は、一度にスレッドなしでスピンできる、多数のコアを備えたリッチコア プロセッサとして想像することをお勧めします。
skin mini プロセッサにはローカル メモリがあり、GT200 用に 16 KB、Evergreen 用に 32 KB、Fermi 用に 64 KB (基本的には L1 キャッシュのプログラミング) です。 これは、1 時間のアクセスに対する標準 CPU の第 1 レベルのキャッシュに似ている場合があり、機能モジュールへの最新のデータ配信と同様の機能を実行します。 Fermi アーキテクチャでは、ローカル メモリの一部に大きなキャッシュのようにパッチを適用できます。 GPU には、巻き上げられたスレッド間のスウェーデン式データ交換に役立つローカル メモリがあります。 GPU プログラムの最も一般的なスキームの 1 つは次のとおりです。cob では、ローカル メモリは GPU のグローバル メモリからのデータで占有されます。 それは単なるサウンドビデオメモリであり、「独自の」プロセッサを除いて(システムメモリとして)ソートされています-別のビデオでは、ビデオカードのテキソライトにマイクロ回路で半田付けされています. Dali の何百ものスレッドがローカル メモリのデータで処理され、結果がグローバル メモリに書き込まれた後、CPU に転送されます。 obov'yazku プログラマーがローカル メモリから書かれた指示 zavantazhennya と vivantage データを含める前に。 実際、並列処理にはデータ(特定のタスク)を打ち負かす必要があります。 GPU はメモリ内のアトミックな書き込み/読み取り命令もサポートしていますが、悪臭は非効率的であり、すべてのミニプロセッサの計算結果を接着するために最終段階で呼び出します。
ローカル メモリは、ミニプロセッサに格納されているすべてのスレッドに対してグローバルです。たとえば、Nvidia の用語では共有と呼ばれ、ローカル メモリという用語は正反対を意味しますが、それ自体は、グローバル メモリ内のスレッドの周りの個人的な領域として、表示のみ可能です。 さらに、ミニプロセッサにはもう1つのメモリ領域があり、すべてのアーキテクチャでメモリの約4倍の大きさです。 ウォンは、巻き上げられているスレッド、変更を保存するための ce レジスタ、および計算の中間結果によって、私たちの間で均等に分割されます。 何十ものレジスターがスキンスレッドに落ちます。 デポジットにかかる正確な時間は、ミニプロセッサーが獲得するスレッドの数によって異なります。 この数値は非常に重要です。なぜなら、グローバル メモリの待機時間は既に数百ティックと大きく、キャッシュがなければ中間結果を保存する方法がないからです。
GPU ライスにとってもう 1 つの重要なことは、「ソフトな」ベクトル化です。 ミニプロセッサのスキンには多数のモジュール (GT200 の場合は 8、Radeon の場合は 16、Fermi の場合は 32) を含めることができ、それらはすべて、1 つのプログラム アドレスを持つ 1 つの同じ命令にしか従うことができません。 また、オペランドは互いに異なる場合があり、異なるスレッドには独自のものがあります。 例えば、指導 2つのレジスターをまとめる: 1 時間は、すべての別棟でカウントされますが、レジスターは別の方法で取得されます。 データの処理と並行している GPU プログラムのすべてのスレッドが、プログラム コードの背後で並行して崩壊していることがわかります。 この順序で、すべてのカウント モジュールが等しく打ち負かされます。 そして、プログラムrozіyshlisのrazgaluzhennyaを通るスレッドがコードに向かう途中である場合、いわゆるシリアライゼーションが想定されています。 完全なobsyazy obchislyuvalnіモジュールの同じvikoristovuyutsya、vikonannyaの異なる命令を送信するためのスレッドの断片、および列挙モジュールのブロックは、すでに述べたように、1つのアドレスを持つ命令よりも少ないvikonuvatyになる可能性があります。 І、ozumіlo、それ自体の生産性は最大100パーセント低下します。
プラスは、SSE、MMX の代替を使用してプログラミングせずに、ベクトル化が再び自動的に実行されることです。 І GPU 自体が違いを処理します。 理論的には、変数モジュールのベクトルの性質を考慮せずに GPU 用のプログラムを作成することは可能ですが、そのようなプログラムの速度はそれほど高くはありません。 マイナスは、ベクトルの幅が広いことを示します。 より多くの機能モジュールを獲得し、公称数を減らし、Nvidia GPU で 32、Radeon で 64 になりました。 スレッドは可変サイズのブロックでトリミングされます。 Nvidia は、このスレッドのブロックをワープ、AMD - ウェーブ フロントという用語と呼んでいますが、これは同じです。 このランクでは、「hvilyovy front」の 16 のカウント別棟で、長い 64 スレッドが chotiri tact のためにカットされます (非常に長い指導の心のために)。 著者は、この場合、ロープのねじれたコイルの使用を意味する海事用語ワープとの関連を通じて、ワープという用語をより明確に考えています。 そのため、スレッドは「ねじれ」、しっかりと接続されます。 つまり、「波面」は海に関連付けることもできます。指示は、風のように別棟にも届き、1つずつ岸に押し寄せます。
それにもかかわらず、すべてのスレッドがvikonnіプログラムをすり抜けて(1か所で再購入)、そのような儀式で1つの指示を編んだ場合、すべてが奇跡的ですが、そうでない場合は改善されます。 場合によっては、1 つのワープまたはウェーブ フロントのスレッドが異なるプログラム領域で検出され、悪臭がスレッドのグループに分割され、命令番号 (つまり、命令ポインター) の値が同じになることがあります。 早くも、同じグループのスレッドは一度に 1 時間巻き上げられます。すべてのスレッドは同じ命令で巻き上げられますが、オペランドは異なります。 ワープの結果は倍のスタイルで変化し、グループ内のスレッドの数は重要ではありません。 グループとしてのNavitは1つのスレッドで構成されていますが、同時にvykonuvatisya stilks、skіlkipovny warpがあります。 ゲートでは、シンギングスレッドの追加のマスキングが実現されるため、指示は正式にウィッキングされますが、ウィッキングの結果はどこにも記録されず、ウィッキングされません。
同時に、スキンミニプロセッサ(ストリーミングマルチプロセッサまたはSIMDエンジン)vykonuєіnstruktsії、schoは複数のワープ(スレッドのリンク)に嘘をつき、弾丸に数十のアクティブなワープがある可能性があります。 1 つのワープの命令に従った後、ミニプロセッサはこのワープのスレッドの命令ではなく、別のワープの命令を実行します。 そのワープは、速度を上げない限り、プログラムの他の特定の領域にある可能性があるため、ワープの途中でのみすべてのスレッドの命令が必要になりますが、全速力。
20 個の SIMD エンジンを備えたこのタイプのスキンでは、アクティブなウェーブ フロントと 64 スレッドのスキンが存在する可能性があります。 短いラインのスキンスレッド。 合計: 64×4×20=5120 スレッド
このように、スキン ワープまたはウェーブ フロントが 32 ~ 64 のスレッドで構成されているものを見ると、ミニプロセッサは数百のアクティブなスレッドを持っている可能性があり、これはほぼ一晩です。 以下では、並列スレッドの数がアーキテクチャの方法のようにどれだけ大きいかを確認できますが、倉庫のミニ GPU プロセッサの obmezhennya のように裏側を見ることができます。
GPU にスタックがないのは残念です。そのため、関数のパラメーターとローカルの変更を保存できませんでした。 スタック用のスレッドが多数あるため、クリスタルにスペースがありません。 実際、GPU は一度に 10,000 スレッド近くのクロックを処理しているため、1 つのスレッドのスタックを 100 KB に拡張すると、合計ストレージ ボリュームは 1 GB になり、標準のビデオ メモリ ボリュームを超えます。 Tim の方が大きく、GPU のまさにコアにある種のスケーラブルなスペースのスタックを配置する可能性はありません。 たとえば、スレッドごとに 1000 バイトのスタックを配置した場合、1 つのミニプロセッサに必要なメモリは 1 MB だけです。これは、minprocessor のローカル メモリとレジスタの保存に割り当てられたメモリの合計量の 5 倍になる可能性があります。
そのため、GPU プログラムには再帰がなく、関数呼び出しで特に興奮することはありません。 これらの関数は、プログラムのコンパイル中にコードに直接導入されます。 ツェーは、数値型のタスクによって GPU ブロッキングの領域を取り囲んでいます。 場合によっては、スタック エミュレーションとグローバル メモリ再帰アルゴリズムを、反復の深さが小さいか、非典型的な GPU オーバーヘッドで切り替えることができます。 したがって、CPU に対するアクセラレーションの成功を保証せずに実装の可能性を確保するために、アルゴリズムを特別に拡張する必要があります。
フェルミは最初に仮想関数の勝利の可能性を示しましたが、それはスウェーデンの革糸の偉大なキャッシュの日に限られていました。 1536 スレッドの場合、48 KB または 16 KB の L1 が低下するため、プログラム内の仮想関数が勝利することはめったにありません。バリアント変更。
このように、GPU は、データが取得され、悪臭が何らかのアルゴリズムによって処理され、結果が表示される計算 spiv プロセッサの役割で提示されます。
アーキテクチャの利点
エール vvazha GPU duzhe shvidko。 このように、マルチスレッドはこの神殿に役立ちます。 多数のアクティブ スレッドにより、500 サイクル近くになる、グローバル ビデオ メモリの周りに展開された大きなレイテンシを頻繁にアタッチすることができます。 これは、算術演算の密度が高いコードに特に適しています。 このように、キャッシュL1-L2-L3の階層内のトランジスタの観点からは道路は必要ない。 水晶に置き換えることで、複数の計数モジュールを配置でき、同じ演算生産性を確保できます。 また、ワープの 1 つのスレッドの命令が作成されている間に、何百ものスレッドをデータで簡単にチェックできます。
Fermi は、約 1 MB の別の同じサイズのキャッシュを導入しましたが、最新のプロセッサのキャッシュと比較することはできません。カーネル間の通信やさまざまなソフトウェア トリックにより多くの用途があります。 あたかもヨゴローズマリーが数万本の糸に分かれているかのように、皮膚には取るに足らない義務があります。
エール、グローバルメモリのレイテンシーの限界、計算拡張では、まるでそれを取る必要があるかのように、非個人的なレイテンシーがまだあります。 第 1 レベルのキャッシュ、GPU のローカル メモリ、レジスタ、および命令キャッシュへのアタッチメントのカウントから、クリスタルの中央での伝送レイテンシの整合性。 登録ファイルは、ローカル メモリとして、機能モジュール内の roztashovani okremo、およびそれらへのアクセスが約 2 ダース サイクルになります。 繰り返しになりますが、アクティブなワープであるスレッドの数は依然として多く、レイテンシーを効果的に捉えることができます。 さらに、GPU 全体のローカル メモリにアクセスするための帯域幅 (帯域幅) は重要ですが、ストレージ ミニプロセッサの数が大幅に改善され、最新の CPU の第 1 レベルのキャッシュへのアクセス帯域幅が大幅に減少しています。 GPU は、1 時間あたりに大幅に多くのデータを再構築できます。
GPUに多数の並列スレッドが提供されない場合、新しいものは生産性がゼロになると言えます。これはまさにこのペースのせいであり、より多くの絡み合いが必要になり、より小さなワークロード。 たとえば、10,000 のスレッドを複数のスレッドに置き換えてみましょう。すべてのブロックが占有されるだけでなく、すべてのレイテンシが発生するため、生産性は約 1,000 分の 1 に低下します。
最新の高周波数CPU、間引き方法の使用にレイテンシを付加する問題-深いkonveierizatsija、後にvykonannyaіnstruktsіy(順不同)。 クリスタルのスペースを占有する折りたたみ式プランナーと説明書、さまざまなバッファーなどが必要です。 シングルスレッドモードで最短の生産性を実現するには、すべてが必要です。
しかし、GPU の場合、すべてが必要というわけではありません。多数のフローを持つタスクをカウントするのにアーキテクチャ的に最適です。 そして、賢者の石が鉛を金に変えるように、ワインは富の流れを生産性に変えます。
GPUには、ピクセルトリックに最適なシェーダープログラム用の一連のアタッチメントがあり、明らかに独立しており、並行して移動できます。 さまざまな機能 (ローカル メモリとビデオ メモリへのアクセスのアドレス指定、および単純化された命令セット) を過剰な計算アドオンに追加することで、進化の罪を犯すつもりです。限られたオブシャグ オブシャグ ローカル メモリの実装。
お尻
GPU の古典的なタスクの 1 つは、重力場を作成する Ntіl の相互依存性を計算するタスクです。 しかし、たとえば、地球-月-太陽系の進化を開発する必要がある場合、GPU は私たちにとって厄介なヘルパーです。オブジェクトはほとんどありません。 スキン オブジェクトの場合、他のオブジェクトの総数を計算する必要があります。たとえば、合計で 2 つです。 その月に多くの惑星 (約数百個のオブジェクト) が存在する Sonyachny システムの時代では、GPU はまだあまり効率的ではありません。 Vtіm、およびフロー制御のオーバーヘッドが高いリッチコアプロセッサは、その能力をすべて発揮することはできませんが、シングルスレッドモードでは. しかし、小惑星帯の彗星や天体の軌道を拡張する必要がある場合、それは既に GPU のタスクであるため、拡張するために必要な数の並列ストリームを作成するのに十分なオブジェクトがあります。
数十万の星の狭い場所を片付ける必要があるため、GPU も親切に表示する必要があります。
タスクNtіlでGPUの圧力を打ち負かすもう1つの可能性は、非個人的なタスクを解決する必要がある場合は、少量のtіlにすることです。 たとえば、cob shvidkos のさまざまなオプションに対して、1 つのシステムの進化オプションを開発する必要があります。 GPU を効果的に微調整して、問題なく動作するようにします。
AMD Radeon マイクロアーキテクチャの詳細
GPU の構成の基本原則を調べました。これまで、悪臭はビデオ処理にとって眠いものでした。これは、シェーダー プログラムという 1 つの目標が念頭に置かれていたためです。 プロトタイピストは、マイクロアーキテクチャ実装の詳細を拡張できることを知っていました。 他ベンダのCPUはときどき強く揺さぶられますが、ざっくり言うと、例えばPentium 4とAthlonとかCoreとか。 Nvidia のアーキテクチャはすでに広く知られていますが、Radeon を見ると、これらのベンダーのアプローチの主な特徴のようです。
AMD ビデオカードは、以前に DirectX 11 仕様を実装した Evergreen ファミリーから主流の認識の全額を奪いました。
ローカル メモリ拡張の詳細 (Radeon では 32 KB、GT200 では 16 KB、Fermi では 64 KB) はまったく重要ではありません。 AMD の 64 スレッドと Nvidia のワープの 32 スレッドでウェーブ フロントを拡張する方法。 実際には、GPU プログラムを簡単に再構成し、デジタル パラメータに合わせて調整できるかどうか。 生産性は数万単位で変化する可能性がありますが、GPU の場合はそれほど重要ではありません。GPU プログラムのサウンドが 10 倍優れているか、CPU のアナログが低いか、または 10 倍高速であるか、または機能しないためです。
最も重要なのは、AMD テクノロジの VLIW (Very Long Instruction Word) です。 Nvidia vicorist スカラー 簡単な指示、スカラーレジスタで動作します。 Їїprikoryuvachіは単純な古典的なRISCを実装しています。 AMD ビデオ カードは、GT200 と同じ数のレジスタを持つことができますが、128 ビットのベクトル レジスタも持つことができます。 スキン VLIW-instruktsiya は、dekilkom chotirikomponentnym 32 ビット レジスタ、scho SSE を操作しますが、VLIW の可能性はより豊かです。 SSE のような SIMD (Single Instruction Multiple Data) ではありません。ここでは、オペランドのスキン ペアの命令は異なっていても類似していてもかまいません。 たとえば、レジスタ A のコンポーネントを a1、a2、a3、a4 とします。 レジスタ B についても同様です。 追加のヘルプ、1 サイクルで勝つ方法、たとえば数 a1×b1+a2×b2+a3×b3+a4×b4 または 2 次元ベクトル (a1×b1+a2 ×b2、a3×b3+a4×b4)。
GPU の低周波数、CPU の低周波数、および残りの運命における技術プロセスの大幅な変更を遅くすることが可能になりました。 これにより、通常の鉋が必要なくなり、多くは一打ごとに打たれます。
ベクトル命令に従うと、単精度数での Radeon のピーク生産性はすでに高くなり、すでにテラフロップスになっています。
1 つのベクトル レジスタで 4 つの単精度数を置き換え、1 つの可変精度数を節約できます。 1 つの VLIW 命令で、倍精度数の 2 つのペアを加算するか、2 つの数値を乗算するか、2 つの数値を乗算してから 3 番目の数値を加算することができます。 したがって、ダブルのピーク生産性は、フロートの約 5 倍低くなります。 古い Radeon モデルの場合、新しい Fermi アーキテクチャでの Nvidia Tesla のパフォーマンスは、GT200 アーキテクチャでのダブル カードのパフォーマンスよりも高くも低くもありません。 古い Fermi ベースの Geforce ビデオ カードでは、二重計算の最大速度が 4 倍に変更されました。

Radeon ロボットのスキームは重要です。 並列で動作する 20 個のミニプロセッサのうち 1 つだけを提示
CPU ハック (x86 クレイジーなもの) に似た GPU ハックは、マッドネス パワーとは関係ありません。 GPU プログラムは中間コードにコンパイルされ、プログラムが起動されると、ドライバーはコードを特定のモデルに固有のマシン命令にコンパイルします。 上記で説明したように、GPU メーカーは GPU 用の効率的な ISA (命令セット アーキテクチャ) をすぐに考え出し、世代ごとにこれらのタイプを変更しました。 いずれにせよ、ツェーは毎日の(不要な)デコーダーによって数百の生産性を追加しました. しかし、AMD 社はさらに進んで、予見しました。 公式フォーマットマシンコードのデコード命令。 悪臭は(プログラムのリストから)順番に並べ替えられるのではなく、セクションごとに並べ替えられます。
背面には、さまざまなトランジションに適した算術命令を中断することなくセクションに送信できる、スマート トランジション用の命令セクションがあります。 これらは VLIW バンドル (VLIW 命令リンク) と呼ばれます。 これらのセクションには、レジスタまたはローカル メモリからのデータを含む算術エントリのみがあります。 このような組織は、指示の流れの管理と別棟への指示の配信を容易にします。 これが最善の方法です。 Іsnuyut また、メモリへの指示 zvernenen のセクション。
| スマートトランジションの手順のセクション | ||||
|---|---|---|---|---|
| セクション 0 | 脱塩 0 | 演算命令を中断せずに第 3 セクションに送信 | ||
| セクション 1 | 再仕上げ 1 | 第4節の申請 | ||
| 第2節 | 脱塩 2 | 第5節の申請 | ||
| 中断のない算術命令のセクション | ||||
| セクション 3 | VLIW 命令 0 | VLIW 命令 1 | VLIW 命令 2 | VLIW 命令 3 |
| セクション 4 | VLIW 命令 4 | VLIW 命令 5 | ||
| セクション 5 | VLIW 命令 6 | VLIW 命令 7 | VLIW 命令 8 | VLIW 命令 9 |
両方の GPU (および Nvidia、AMD) には、基本的な数学関数、平方根、指数関数、対数、正弦、および単精度数の余弦のサイクルごとの迅速な計算のための命令も含まれている場合があります。 私はそのє特別な列挙ブロックに。 悪臭は、ジオメトリ シェーダーでこれらの関数の迅速な近似を実装する必要があるため、「妨げられました」。
GPU がグラフィックスで勝っていることを知らず、より意識するようになった Yakby navit 技術特性、その後、当面の兆候として、spivprocessors の数は videopriskoryuvachiv のようになるはずであると推測されます。 同様に、海の賢者の古代の米の背後で、vcheni は彼らの祖先が土地の源であることに気づきました。
しかし、最も明白なのは米であり、グラフィカルな拡張のように見え、追加のバイリニア補間のために 2 次元および 3 次元のテクスチャを読み取るブロックです。 悪臭は GPU プログラムで広く使用されており、シャードは読み取り専用データの配列をより高速かつ簡単に読み取ることができます。 GPU 補遺の動作の標準オプションの 1 つは、外部データの配列を読み取り、それらを列挙コアで処理し、結果を別の配列に書き込み、それを CPU に転送することです。 このようなスキームは標準で拡張されており、GPU アーキテクチャに適しています。 グローバルメモリの1つの大きな領域で集中的な読み取りと書き込みを必要とするタスクは、そのようなランクでデータの背後で膠着状態に陥るため、GPUに並列処理を効率的に実装することが重要です. また、それらの生産性は、グローバル メモリのレイテンシーに大きく依存していますが、それは素晴らしいことです。 そして、「データの読み取り - 処理 - 結果の書き込み」というテンプレートでタスクが説明されていることから、GPU での出力が大幅に増加することがわかります。
GPU テクスチャ データの場合、最初の領域と他の領域の小さなキャッシュの階層があります。 Vaughn と bezpechuє priskornnya は vikoristannya のテクスチャを作成しました。 この階層は、テクスチャへのローカル アクセスを高速化するためにグラフィック プロセッサに表示されます。明らかに、セカンダリ ピクセルの 1 つのピクセルを (高効率で) 処理した後、テクスチャ データを閉じる必要があります。 ただし、最も重要な計算には多くのアルゴリズムがあり、データへのアクセスにも同様の性質がある可能性があります。 また、グラフィックスのテクスチャ キャッシュはより茶色になります。
Nvidia カードと AMD カードの L1-L2 キャッシュ拡張はほぼ同じですが、グラフィック カードの最適性により明らかに不可能ですが、これらのキャッシュへのアクセスの遅延は常に変化しています。 Nvidia のアクセス レイテンシはより大きく、Geforce のテクスチャ キャッシュは、データへのアクセスを高速化するのではなく、メモリ バスを高速化するのに役立つ傾向があります。 これは、グラフィック プログラムでは重要ではありませんが、ソフトウェア アプリケーションでは重要です。 Radeon のテクスチャ キャッシュ レイテンシは低くなりますが、ミニプロセッサのローカル メモリのレイテンシはより優れています。 そのような例を指摘することができます: Nvidia カードで行列の最適な乗算を行うには、ローカル メモリを高速化し、行列を並べて消去する方が高速です。 AMDのほうがいい低レイテンシのテクスチャ キャッシュに依存し、消費の世界で行列要素を読み取ります。 Ale tse dosit は細かい最適化を行い、すでに基本的に GPU アルゴリズムに変換されています。
この違いは、さまざまな種類の 3D テクスチャにも表れています。 GPU で計算された最初のベンチマークの 1 つは、AMD の重大な優位性を示したもので、最も一般的な 3D テクスチャであり、その破片はデータのトリビマー配列から計算されています。 また、Radeon のテクスチャ アクセス レイテンシははるかに高速であり、3D 適応はシャッターの最適化よりも高度です。
オトリマンナ用 最大の生産性さまざまな企業のホールによると、特定のカードに必要なチューニングレポートがありますが、GPU アーキテクチャのアルゴリズム開発の原則よりも重要性がはるかに低くなります。
Radeon 47xxシリーズの交換
このファミリの場合、GPU での計算は正しくありません。 3つ挙げてもらえますか 重要な瞬間. そもそもローカルメモリがないので物理的に無理ですが、現在のGPUプログラムの規格で求められているユニバーサルアクセスの可能性はありません。 プログラムによってグローバル メモリに格納されるわけではないため、フル機能の GPU で実行しても何のメリットもありません。 もう1つのポイントは、メモリと同期命令からの異なるアトミック操作命令の命令がトリミングされていることです。 І 3 番目の瞬間 - エントリのキャッシュの小さな拡張を完了する必要はありません。プログラムの拡張から始めて、速度が向上します。 Єіnshіdrіbnіobmezhennya。 GPU に最適なプログラムだけが、このビデオ カードで使用するのに適していると言えます。 レジスタのみで動作する簡単なテスト プログラムを使用してみましょう。ビデオ カードは Gigaflops で良い結果を示すことができますが、より効率的にプログラムするには問題があります。
長所と短所 エバーグリーン
AMD製品とNvidia製品を比較すると、GPUを見ると、5xxxシリーズはさらにタイトなGT200に見えます。 非常にきついので、ピーク時の生産性ではフェルミを約 2.5 倍覆します。 特に、新しい Nvidia ビデオ カードのパラメータが削減されたため、コアの数が短縮されました。 また、Fermi での L2 キャッシュの出現により、GPU での特定のアルゴリズムの実装が容易になり、GPU ジャミングの範囲が拡大します。 まあ、最後の GT200 世代の適切な最適化のために、Fermi のアーキテクチャ革新の CUDA プログラムはしばしば何も与えませんでした。 悪臭は、カウントモジュールの数の増加に比例して加速したため、メモリ帯域幅が増加していないため(他の理由で)、(単精度数の場合)それほど低くはありません.
ベクトルの性質を示すことができる GPU アーキテクチャに適したタスク (乗算された行列など) では、Radeon は理論上のピークに近いパフォーマンスを示し、Fermi よりも優れています。 豊富な核 CPU についてはまだないようです。 特に単精度数の問題で。
Ale Radeon は、結晶領域が少なく、熱画像が少なく、エネルギーが節約され、付属品が多く、明らかに多様性が少ない可能性があります。 そして、3Dグラフィックスに問題なく、フェルミは、結晶の領域にある非常に小さいタイプの小売店であるvzagaliєと同様に勝ちます. ミニプロセッサ用の 16 個のアドオンを備えた Radeon アーキテクチャの数、64 スレッドでのウェーブ フロントの拡張、およびベクトル VLIW 命令が優れたヘッド タスクであるという事実によって説明される理由が豊富です。 yoga - グラフィックシェーダーの計算。 最も重要なプレーヤーにとって、ゲームの生産性と価格は優先事項です。
プロフェッショナルで科学的なプログラムの観点から、Radeon アーキテクチャは、最も効率的なコスト生産性、ワットあたりの効率、タスクの絶対的な生産性を保証し、原則として GPU のアーキテクチャを尊重し、並列化とベクトル化を可能にします。
たとえば、ベクトル化が容易な Radeon キーの並列タスク選択の場合、Geforce より数倍高速で、CPU の場合は数十倍高速です。
したがって、GPU が CPU を補う責任を負う理由である AMD Fusion の基本的な概念をサポートし、将来的には CPU コア自体に統合することができます。プロセッサーコアへのグリーンクリスタル Pentium プロセッサ)。 GPU は統合グラフィックス コアであり、ストリーミング タスク用のベクトル プロセッサです。
Radeon は、機能モジュールを使用する際に異なる波面を持つ命令を混合するという狡猾な手法を勝ち取っています。 指示が完全に独立しているため、作業は簡単です。 この原理は、現在の CPU による独立した命令のパイプライン化されたラッピングに似ています。 明らかに、多くのバイトを占めるベクトル VLIW 命令を効果的に連結できます。 CPU には、独立した命令を表示するため、またはハイパースレッディング テクノロジを使用するためのフォールディング プランナーが必要です。これは、異なるスレッドからの独立した命令で CPU を保護するためです。
| メジャー 0 | バー 1 | メジャー 2 | メジャー 3 | バー 4 | バー 5 | バー 6 | バー 7 | VLIW モジュール | |
| 波面 0 | 波面 1 | 波面 0 | 波面 1 | 波面 0 | 波面 1 | 波面 0 | 波面 1 | ||
|---|---|---|---|---|---|---|---|---|---|
| → | インストルメント 0 | インストルメント 0 | インストルメント 16 | インストルメント 16 | インストルメント 32 | インストルメント 32 | インストルメント 48 | インストルメント 48 | VLIW0 |
| → | インストルメント 1 | … | … | … | … | … | … | … | VLIW1 |
| → | インストルメント 2 | … | … | … | … | … | … | … | VLIW2 |
| → | インストルメント 3 | … | … | … | … | … | … | … | VLIW3 |
| → | インストルメント 四 | … | … | … | … | … | … | … | VLIW4 |
| → | インストルメント 5 | … | … | … | … | … | … | … | VLIW5 |
| → | インストルメント 6 | … | … | … | … | … | … | … | VLIW6 |
| → | インストルメント 7 | … | … | … | … | … | … | … | VLIW7 |
| → | インストルメント 8 | … | … | … | … | … | … | … | VLIW8 |
| → | インストルメント 9 | … | … | … | … | … | … | … | VLIW9 |
| → | インストルメント 十 | … | … | … | … | … | … | … | VLIW10 |
| → | インストルメント 十一 | … | … | … | … | … | … | … | VLIW11 |
| → | インストルメント 12 | … | … | … | … | … | … | … | VLIW12 |
| → | インストルメント 13 | … | … | … | … | … | … | … | VLIW13 |
| → | インストルメント 14 | … | … | … | … | … | … | … | VLIW14 |
| → | インストルメント 15 | … | … | … | … | … | … | … | VLIW15 |
2 つのウェーブ フロントの 128 の命令は、64 の操作で構成され、ほとんどのクロックで 16 の VLIW モジュールによって接続されます。 絵を描く必要があり、皮革のモジュールは、心への命令全体に従うのに実際には 2 サイクルかかることがあります。 Imovirno、タイプ a1×a2+b1×b2+c1×c2+d1×d2 の VLIW 命令をオーバーライドして、すべてのクロック サイクルでそのようなすべての命令をオーバーライドするのに役立ちます。 (正式には、時計ごとに 1 つずつ外出します。)
Nvidiaにはおそらくそのような技術はありません。 І VLIW なしで、複数のスカラー命令が必要な高生産性を実現 高周波赤外線画像と吊るしたハイライトを自動的に移動するロボット 技術プロセス(より高い高周波のスキームを設計するため)。
GPU 計算の観点から見た短命の Radeon は、だまされるほど非常に嫌われています。 GPU vzagalіは、上記のvykonannyaіnstruktsіyで説明されている技術によるshanyuyutrazgaluzhennyaではありません:1つのプログラムアドレスを持つスレッドのvіdrazuグループ。 (ちなみに、この手法は SIMT: Single Instruction - Multiple Threads (1 つの命令 - 多数のスレッド) と呼ばれ、1 つの命令が異なるデニムを使用した 1 つの操作で構成される SIMD に似ています。) yazuvannya スレッド。 プログラムがベクトルベースでない場合、ワープまたは波面の拡張が大きいほど、さらに重要なことに、後続のプログラムの将来の拡張の場合により多くのグループが確立されることが理解されました。スレッドでは、シーケンシャル (シリアル化) で勝つ必要があります。 ワープが 32 スレッドで展開されたとしても、すべてのスレッドが展開されていることは許容されます。 そしてRadeonのようなrazіrozіru64 - 64倍以上のpovіlnіshe。
覚えていますが、「敵意」を示しているのは1人だけではありません。 Nvidia ビデオ カードには、CUDA コアとも呼ばれるスキン機能モジュールがあり、特別な処理ブロックがある場合があります。 また、16 モジュールの Radeon ビデオ カードの場合、演算ブロックを制御するためのブロックが合計 2 つあります (ドメイン内に演算ブロックはありません)。 そのため、スマート トランジションの指示に従うのは簡単です。ウェーブ フロントのすべてのスレッドで同じ結果が得られるようにするには、さらに 1 時間かかります。 Іshvidkіstprosіdaє。
AMDはCPUを好転させています。 悪臭vvazhayut、多数のrazgaluzhenを持つプログラムの場合、すべて1つがCPUに、およびベクトルプログラムのGPU割り当てに適しています。
そのため、Radeon は全体的に効率的なプログラミングの機会を提供しませんが、さまざまなモードで最高のコスト パフォーマンス比を提供します。 つまり、CPU から Radeon にプログラムを効率的に (コストをかけずに) 転送することができ、より少ない、下位のプログラムを Fermi 上で効果的に実行することができます。 Aletі、yakіは効果的に転送でき、Radeonでpratsyuvatimutを豊かな感覚で効率的に使用できます。
GPU コンピューティング用 API
Radeon の非常に技術的な仕様は見栄えがよく、完璧ではなく、GPU 上で計算を完全に絶対的なものにしてください。 しかし、生産性にとってそれほど重要ではないのは、GPUプログラムの開発と開発に必要なソフトウェアセキュリティです-高品質のムービーとランタイムのコンパイラーは、プログラムの一部間の相互作用を変更するドライバーであり、機能しますCPU上で、中間GPUなし。 これはより重要で、CPU の場合は低くなります。CPU にはドライバーが必要ないため、データ転送管理が改善され、GPU コンパイラーがより強力に見えます。 たとえば、コンパイラは、最小数のレジスタを使用して中間結果を収集し、関数サイクルを慎重に計算する責任があります。これも最小数のレジスタで行います。 vicorist スレッドのレジスターが少なくても、より多くのスレッドを起動でき、GPU のナバンテージが増加し、メモリへのアクセス時間が短縮されます。
Radeon製品のソフトウェアサポートの第1軸は、ホールの開発でまだ進行中です。 (ローンチがリリースされた Nvidia の状況に基づいており、製品は新製品のようです。) 最近では、AMD の OpenCL コンパイラがベータ ステータスを達成しましたが、大したことではありません。 Vín duzhe はしばしば恩赦コードを生成したり、正しい出力テキストからコードをコンパイルしたり、自分で恩赦を見たりして、ロボットがハングしました。 春のために、viyshovは高等練習から解放されます。 Víntezhは恩赦を許しませんが、相互の正確性に基づいてプログラムされている場合、それは大幅に少なくなり、ファウルラインを非難する悪臭を放ちます。 たとえば、uchar4 タイプを使用して、4 バイトの choti-component 変更を指定します。 このタイプは OpenCL の仕様にありますが、Radeon では使用できませんが、レジストリは 128 ビットです。これらは一部のコンポーネントですが、32 ビットです。 そして、uchar4 のすべての 1 つのローン tsiliy レジスターのこのような変更は、追加のパッキング操作と最大 ocremi バイト コンポーネントへのアクセスが必要になるだけです。 コンパイラは日常の許しの母であることに罪はありませんが、欠点のないコンパイラはありません。 バージョン 11 以降の Navit Intel Compiler では、コンパイルをご容赦ください。 秋に近づく次のリリースに向けて、申し訳ありませんが修正されました。
それでも、追加のサポートが必要なサイレントスピーチがまだあります。 たとえば、Radeon 用の標準の GPU ドライバーは、OpenCL の癖を使用した GPU 計算をサポートしていません。 Koristuvach は、追加の特別パッケージの手配とインストールを担当しています。
そして何よりも - 関数のライブラリの存在。 サブ変数精度の音声数値の場合、正弦、余弦、または指数はありません。 まあ、行列の足し算や掛け算なら必要ありませんが、よりスムーズにプログラミングしたい場合は、すべての関数をゼロから作成する必要があります。 SDK の新しいリリースを確認します。 主な行列関数をサポートする GPU 母国 Evergreen 用の ACML (AMD Core Math Library) は、まもなく開発されます。
現時点では、記事の著者によると、Radeon ビデオ カードのプログラミングで API Direct Compute 5.0 を使用するのは当然のことです。 Windows プラットフォーム 7 と Windows Vista。 Microsoft は、コンパイラについて多くの知識を持っている可能性があり、最新の製品リリースをすぐに確認できます。Microsoft は、この点で完全に引用されています。 Ale Direct 対話型アドオンのニーズに合わせて方向を計算: 結果を確認して視覚化する - たとえば、サーフェス上のサーフェスをバイパスする。 ツェーは単にロズラクンコフのためだけにヨガに勝てないという意味ではありませんが、自然な認識のためのヨガという意味でもありません。 AMD が持っていないのと同じように、Microsoft が Direct Compute にライブラリ関数を追加する予定がないとしましょう。 そのため、Radeon で一度に効率的にバグを修正できるもの (プログラムを間引く必要がない) は、OpenCL よりもはるかに単純で安定している Direct Compute で実装できます。 さらに、移植性と実用性が高く、Nvidia と AMD で使用できるため、Nvidia と AMD による OpenCL SDK の実装にはそれほど費用がかかりませんが、プログラムをコンパイルする必要があるのは 1 回だけです。 (AMD OpenCL SDK バージョンを使用して AMD システムで OpenCL プログラムを拡張したい場合、Nvidia ではそう簡単に実行できない可能性があります。Nvidia SDK バージョンのテキストそのものをコンパイルする必要がある可能性があります。ひとまず了解です。)
次に、OpenCL には、さまざまなシステム向けの汎用言語プログラミング API として、OpenCL のアイデアの断片である多くの超越的な機能があります。 GPU、CPU、セル。 したがって、明らかに、典型的なコア システム (プロセッサとビデオ カード) 用のプログラムを作成する必要があるだけの場合、OpenCL はいわば「生産性が高い」とは思えません。 スキン関数は 10 個のパラメータを持つことができ、そのうち 9 個は 0 に設定される予定です。スキン パラメータを設定するには、パラメータを持つことができるように特別な関数を呼び出す必要があります。
Direct Compute の最初の主要なストリーミング プラスは、特別なパッケージをインストールする必要がないことです。必要なものはすべて DirectX 11 に既に含まれています。
GPU 開発の問題
球を取ってはどうですか パソコン、状況は次のとおりです。強力なデュアルコアプロセッサをあまり必要とせず、大きなプレッシャーを必要とする人にとって、それほど豊富なタスクはありません。 海から陸へ、偉大で気取らない、しかし回転しない奇跡、しかし陸では何も起こりませんでした。 地表の最初の穏やかな住居は、ローズランドで変化し、あたかも天然資源の不足に常に直面しているかのように、落ち着かなくなり始めます。 Yakby は同時に、10 ~ 15 年前のように、生産性に対する同じニーズでした。GPU 計算は大成功で受け入れられました。 そのため、GPU プログラミングの一貫性と視覚的な複雑さの問題が前面に出てきます。 すべてのシステムで動作するプログラムを作成することをお勧めします。それよりも、高速に動作するが GPU 上でのみ実行される低レベルのプログラムを作成することをお勧めします。
GPU の見通しは、プロの追加やワークステーションのセクターの観点からははるかに優れているため、生産性に対する需要が高まっています。 GPU の助けを借りて 3D エディター用のプラグインがあります。たとえば、編集の変更を支援するためのレンダリング用です。優れた GPU レンダリングに惑わされないでください。 2D 編集者とプレゼンテーション編集者に、折りたたみ効果の作成を高速化するよう呼びかけます。 ビデオを処理するプログラムも段階的に GPU をトリムします。 新しいタスクを導入し、その並列現実を検討することは、GPU アーキテクチャに適していますが、同時に、すべての CPU 機能に対して大規模なコード ベースが作成、改善、最適化されているため、適切な GPU の実装に 1 時間かかりました。現れる。
このセグメントでは、最適な GPU で必要なビデオ メモリの量が約 1 GB であるため、GPU の弱点について説明します。 GPU プログラムの生産性を低下させる主な要因の 1 つは、CPU と GPU の間でバス全体を介してデータを交換する必要があることです。メモリの障害により、より多くのデータを転送することができます。 ここでは、GPU と CPU を 1 つのモジュールに統合するという AMD のコンセプトが有望に見えます。 スループットの構築グローバルメモリへの簡単かつ簡単なアクセスのためのグラフィックメモリ、およびさらに少ないレイテンシ。 最新の DDR5 ビデオ メモリの最高のメモリ帯域幅は、仲介なしではるかに要求されます。 グラフィックプログラム、最もGPUで計算されたソフトウェアは何ですか。 Vzagali 氏によると、GPU と CPU のメモリは、GPU の輻輳の範囲を広げて、小さなソフトウェア プログラムの可能性を増やすためのものです。
І GPU が最も必要とされるのは、科学計算の分野です。 GPU をベースにしたいくつかのスーパーコンピュータはすでに開発されており、行列演算のテストですでに高い結果を示しています。 科学は非常に多様で数値的であるため、GPU を使用すると簡単に高い生産性を実現できる GPU のアーキテクチャに奇跡的に横たわっているため、非個人的であることが常に知られています。
中日とは 現代のコンピューターいずれかを選択してください。 コンピューターグラフィックス- 私たちが住んでいる世界のイメージ。 そして、建築は都市に最適であり、厄介なことはありません. Tse フローリングは重要です。そのために特別に設計された基本的なタスクは、それ自体で多様性を持ち、さまざまなタスクに最適です。 もっと言えば、ビデオ カードは順調に進化しています。
C++ AMP ヘルプの GPU wiki
議論された並列プログラミングのメソッドの dosi は、プロセッサ コアにすぎないように見えました。 複数のプロセッサからのプログラムの並列化にいくつかの新参者を追加し、ブロックをブロックすることなく、デュアル リソース リソースと複数の高速同期プリミティブへのアクセスを同期させました。
ただし、プログラムを並列化する方法がもう 1 つあります。 グラフィックプロセッサー (GPU)、より多くのコア、より低い高性能プロセッサを持つことができます。 グラフィックス プロセッサのコアは、データを処理するための並列アルゴリズムの実装に奇跡的に適しています。それらのコアの多くは、プログラムを実行するための手作業の欠如に見合うだけの価値があります。 この記事では、名前の下に一連の C ++ ムービー拡張機能を使用して、グラフィックス プロセッサでプログラムをプログラムする方法の 1 つを知っています。 C++AMP.
C++ AMP 拡張機能は私の C++ に基づいているため、この記事では私の C++ アプリケーションを紹介します。 ただし、相互作用の勝利の勝利のメカニズムを使用します。 NET を使用すると、C++ AMP アルゴリズムを .NET プログラムに組み込むことができます。 エール、たとえば統計について話しましょう。
C++ AMP への入り口
実際、グラフィックプロセッサは、そうでないかのようにプロセッサ自体ですが、特別な命令セット、多数のコア、およびメモリにアクセスするためのプロトコルを備えています。 最新のグラフィックと優れたプロセッサの間には、優れた洞察があり、効果的にvikoristovuyutするїhnєrozumіnnyaєzaporuchnyastavlennyaプログラムがあります しびれるような疲労グラフィックプロセッサ。
最新のグラフィック プロセッサには、まだ少数の命令セットが含まれている場合があります。 交換アクティビティの転送: 関数の呼び出しの可用性、サポートされるデータの種類の収集、ライブラリ関数の可用性など。 Deyakіoperatsіїは、スマートトランジションのように、かなりのプロセッサでのvykonuyutsyaのように、はるかに高価で、より低い類似操作のコストがかかる可能性があります。 そのような頭脳のために大量のコードをプロセッサからグラフィック プロセッサに転送するには、かなりの労力が必要であることは明らかです。
平均的なグラフィック プロセッサのコア数は大幅に多く、平均的なプロセッサでは少なくなります。 ただし、zavdannya のアクションは小さすぎるように見えます。または、多数のパーツを分割することができないため、グラフィック プロセッサのブロックを利用できます。
1日、少しでも修正する必要があるグラフィックプロセッサのコア間の同期のタイミング、および修正する必要があるグラフィックプロセッサのコア間で1日以上 さまざまなタスク. この環境は、グラフィックス プロセッサと上位プロセッサの同期を意味します。
繰り返しになりますが、グラフィックス プロセッサでの実行に適しているのはどのようなタスクですか? すべてのアルゴリズムがグラフィック プロセッサでの実行に適しているわけではないことに注意してください。 たとえば、グラフィック プロセッサは入力/出力デバイスへのアクセスを許可しないため、グラフィック プロセッサのアカウントでインターネットから RSS ラインを取得するなど、プログラムの生産性を向上させることはできません。 ただし、多くの計算アルゴリズムをグラフィックス プロセッサに転送し、大量の並列化を確保することは可能です。 以下に、そのようなアルゴリズムの例をいくつか示します (このリストは新しいものではありません)。
zbіlshennyaと画像のシャープネスの変化およびその他の変換;
Shvidkeの再発明Fur'є;
行列の転置と乗算。
番号の並べ替え;
「額に」ハッシュ反転。
Microsoft Native Concurrency ブログは、高度なアプリケーションのリファレンスとして使用できます。ここでは、C ++ AMP で実装されたさまざまなアルゴリズムのコード フラグメントとそれらの説明を見つけることができます。
C++ AMP は、Visual Studio 2012 ウェアハウスに含まれているフレームワークであり、C++ の小売業者がグラフィックス プロセッサで簡単に計算できるようにし、DirectX 11 ドライバーを目立たなくします。
C++ AMP フレームワークを使用すると、コードを グラフィック アクセラレータ、これは別棟に数えられます。 DirectX 11 ドライバーの助けを借りて、C++ AMP フレームワークが速度を動的に明らかにします。 C++ AMP ウェアハウスには、ソフトウェア エミュレーターと、大規模なプロセッサに基づくエミュレーター (WARP) も含まれています。これは、グラフィックス プロセッサがないシステム、グラフィックス プロセッサがあるシステム、または DirectX 11 ドライバーとチップ コアと SIMD 命令がないシステムのバックアップ オプションです。 .
それでは、グラフィックプロセッサでの視覚化のために並列化できるアルゴリズムの完成に進みましょう。 以下の実装は、2 つのベクトルと同じ値を受け入れ、ポイントごとの結果を計算します。 より直接的に表現するのは簡単です:
Void VectorAddExpPointwise(float* first, float* second, float* result, int length) ( for (int i = 0; i< length; ++i) { result[i] = first[i] + exp(second[i]); } }
大規模なプロセッサでアルゴリズムの並列処理を拡張するには、反復の範囲をサブ範囲の散在に分割し、それらのスキンに対してビコネーションの 1 つのスレッドを実行する必要があります。 以前の記事で、素数を研究するための最初のバットを逆並列化するこの方法に多くの時間を費やすことに専念しました - 可能な限り、ストリームを手動で作成し、タスクをストリームのプールに渡しました。自動逆並列化のための parallel.For および PLINQ。 優れたプロセッサで同様のアルゴリズムを並列化するときに、タスクを小さすぎるタスクに分割しないように、特に 2 倍にしたと思います。
グラフィックス プロセッサの場合、クロックは必要ありません。 グラフィカル プロセッサは非個人的なコアを作成でき、ストリームをさらに高速に処理できます。コンテキスト シフトの変動性は大幅に低く、特別なプロセッサの場合は低くなります。 フラグメントが下にホバーされており、関数を強調表示するために示されています parallel_for_each C++ AMP フレームワークから:
#含む
現在、okremoコードのdoslіdzhuєmoスキン部分です。 ヘッド ループのメイン フォームが維持されたことは高く評価されていますが、勝利したループは、parallel_for_each 関数のクイック クリックに置き換えられました。 実際、ループをウィキ関数またはメソッドに変換する原理は、私たちにとって新しいものではありません。以前に、TPL ライブラリの Parallel.For() および Parallel.ForEach() メソッドからそのような手法を既に示しました。
Dali、入力データ (パラメータ first、second、および result) はインスタンスにラップされます 配列ビュー. array_view クラスは、グラフィック プロセッサに渡される (スクランブルされた) データのギャグに使用されます。 このテンプレート パラメーターは、データの型とそのサイズを決定します。 データに送信される指示のグラフィック プロセッサで vikonat にすすり泣き、優れたプロセッサに吐き出します。メモリからの最新のグラフィックカードєokremimi別館。 array_view のインスタンスを削除しないでください - 悪臭が本当に必要な場合にのみ、データの安全なコピーを悪臭を放ってください。
グラフィック プロセッサの期限が切れている場合、データはコピーされます。 const 型の引数を使用して array_view インスタンスを作成することにより、最初と 2 番目がグラフィック プロセッサ パズルにコピーされ、コピーされて戻らないことが保証されます。 同様に、 破棄データ()、恒星プロセッサのメモリから最速のメモリに結果をコピーすることを含めます。それ以外の場合、データはリターンに直接コピーされます。
parallel_for_each 関数は範囲オブジェクトを受け入れます。これにより、範囲オブジェクトのスキン要素に描画するデータ形状と関数が割り当てられます。 このアプリケーションでは、ラムダ関数が勝利し、それらのトリックが ISO C++ 2011 (C++ 11) 標準に登場しました。 restrict (amp) キーワードは、グラフィック プロセッサ上の関数の本体を変更する機能をオーバーライドし、グラフィック プロセッサ命令でコンパイルできる C++ 構文のほとんどを含めるようにコンパイラに指示します。
ラムダ関数のパラメーター、インデックス<1>オブジェクトは単一のインデックスを表します。 Vіnは、勝利したエクステントオブジェクトを確認したことで有罪です-エクステントオブジェクトを2次元として投票しました(たとえば、外部データの形式を一見2つの世界のマトリックスに割り当てることにより)、インデックスも二世界。 そのような状況の例は、少し低く誘導されることです。
ナレシュティ、ヴィクリク法 同期する()たとえば、VectorAddExpPointwise メソッドは、グラフィック プロセッサによって生成された array_view avResult から計算された結果のコピーを結果配列に戻すことを保証します。
この目的のために、C ++ AMP の光を初めて知ったので、グラフィック プロセッサでの並列計算の利点を示す論文やその他のアプリケーションを提示する準備が整いました。 ベクトル折り畳みは最適なアルゴリズムではなく、大規模なデータ コピー オーバーレイによってグラフィックス プロセッサの汎用性を実証する最適な候補でもありません。 攻撃的なpіdrozdіlіでは、2つのcіkavіshіバットが表示されます。
行列の再現
世界に見える最初の「参照」バットは、複数の行列です。 実装には、3 次 ~O(n 2.807) に近い Strassen のアルゴリズムではなく、単純な 3 次行列乗算アルゴリズムを使用します。 2 つの行列: サイズが m x w の行列 A とサイズが w x n の行列 B の場合、次のプログラムは乗算して結果を返します - サイズが m x n の行列 C:
Void MatrixMultiply(int * A, int m, int w, int * B, int n, int * C) ( for (int i = 0; i< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
並列化はさまざまな方法で実装でき、並列化が必要な場合は、現在のサイクルの並列化を正しく選択することで、恒星プロセッサで実行するコードを選択できます。 ただし、グラフィックス プロセッサは多数のコアを処理でき、現在のサイクルのみを並列化すると、ロボットですべてのコアをキャプチャするのに十分な数のタスクを作成できません。 したがって、2 つの外側のループの間には並列性があり、内側のループは空のままになります。
Void MatrixMultiply (int * A, int m, int w, int * B, int n, int * C) ( array_view
この実装は、複数の行列の次の実装と、さらに行われたベクトルの追加を予測するのにまだ近づいています。これは、2 次元になり、オペレーターの遅延から内部サイクルにアクセスできるようになりました。 最後の選択肢よりも優れているのはどのバージョンですか。より大きなプロセッサにはどちらが適していますか? サイズが 1024 x 1024 の 2 つの行列 (数値) を乗算すると、最大のプロセッサの最後のバージョンは平均 7350 ミリ秒かかり、グラフィック プロセッサのバージョンは 3 倍速く、50 ミリ秒で 147 倍高速です!
粒子の動きのモデリング
グラフィックス プロセッサに rozv'yazannya タスクを適用すると、さらに提示されますが、内部ループの実装がさらに単純になる可能性があります。 あなたがそうではないことに気づきました。 すでに多く指摘されている Native Concurrency の場合、粒子間の重力相互作用のモデル化の尻が示されます。 モデリングには無数のピースが含まれます。 スキンフォールドでは、ベクトルの要素の新しい値が計算され、新しい座標が決定されます。 ここでは、粒子のベクトルが並列化されます。多数の粒子 (10000 以上) を終了すると、ロボットがグラフィック プロセッサのすべてのコアをキャプチャできるように、多数のタスクを作成できます。
アルゴリズムの基本は、以下に示すように、2 つの粒子間の相互作用の結果の実装であり、グラフィック プロセッサに簡単に転送できます。
// ここで、float4 はいくつかの要素を持つベクトルであり、 // 操作に参加する粒子を表します。 float absDist = dist.x * dist.x + dist.y * dist.y + dist.z * dist.z; float invDist = 1.0f/sqrt(absDist); = dist*PARTICLE_MASS*invDistCube; )
皮膚股モデルのデータは、座標とパーティクルのランダム性を含む配列であり、その結果、座標とパーティクルのランダム性を含む新しい配列が作成されます。
構造粒子 ( float4 位置、速度; // コンストラクターの実装、コピー コンストラクター // 演算子 = 3 restrict(amp) スペースを節約するために省略 ); シミュレーションステップ(配列
得られた視覚的なグラフィカル インターフェイスのため、シミュレーションは異なる場合があります。 C++ AMP 小売業者チームが提供する最新の例は、Native Concurrency ブログで見つけることができます。 Intel Core i7 プロセッサと Geforce GT 740M ビデオ カードを搭載した私のシステムでは、10,000 個のフラグメントが最新バージョンで毎秒 2.5 フレーム (フレーム/秒) の速度でシミュレートされます。毎秒 16 フレーム、そしていずれの場合も、グラフィック プロセッサで変更されるバージョンの最適化 - 生産性の最大の向上。
まず、このセクションを終了しましょう。グラフィック プロセッサで実行されるコードの生産性を向上させるために、C ++ AMP フレームワークの重要な機能について説明する必要があります。 グラフィックプロセッサーのサポート データキャッシュプログラミング(タイトルが多い メモリ、schorozdіlyaєє(共有メモリ))。 各キャッシュに保存されている意味は、勝利した 1 つのモザイク (タイル) のすべての流れによってこぼれ落ちます。 メモリのモザイクオーガナイザーであるC++ AMPフレームワークに基づくプログラムは、グラフィックマップのメモリから分割されたモザイクのメモリにデータを読み取り、メモリを再検査することなくビコナニアのダースストリームからそれらに戻ることができますグラフィックデータカルティ。 モザイクのメモリへのアクセスは、グラフィック カードのメモリよりも約 10 倍高速です。 つまり、読む理由があります。
並列ループのモザイク バージョンが渡されるようにするために、parallel_for_each メソッドが渡されます。 tiled_extent ドメインリッチ オブジェクト範囲をモザイクのリッチ タイルに分割し、ラムダ パラメーター tiled_index を使用して、モザイクの中央にあるストリームのグローバルおよびローカル識別子を設定します。 たとえば、16x16 の行列を 2x2 のタイルに分割して (下のサムネイルに示すように)、parallel_for_each 関数に渡すことができます。
範囲<2>マトリックス(16,16); tiled_extent<2,2>tiledMatrix = マトリックス.タイル<2,2>(); parallel_for_each (tiledMatrix, [=](tiled_index)<2,2>idx) 制限 (amp) ( // ...));

1つの同じモザイクにあるvikonannyaのいくつかのストリームからの革は、しみに保存されているデータを完全に勝利させることができます。
グラフィックプロセッサのコアで行列を使用して操作を実行する場合、標準のインデックス index を置き換えます<2>、株が大きいように、あなたは勝つことができます idx.global. ローカル モザイク メモリとローカル インデックスを適切に使用すると、生産性が大幅に向上します。 タイル メモリを音声化するために、podіluvanu vykonannya が 1 つのタイルに流れ、ローカル zminnі は指定子 tile_static で音声化できます。
実際には、分割されている音声のないメモリの受信と、異なるストリームでの 4 つのブロックの初期化によって勝利することがよくあります。
Parallel_for_each(tiledMatrix, [=](tiled_index)<2,2>idx) restrict(amp) ( // ブロック内のすべてのスレッドで 32 バイトが共有されます tile_static int local; // このスレッドの要素に値を割り当てます local = 42; ));
分割されているメモリを整理できれば、メモリへの異なる同期アクセスしか取得できないことは明らかです。 そのため、ストリームのいずれかによって開始されるまで、ストリームはメモリに向かうことに罪はありません。 モザイク内のストリームの同期は、追加のオブジェクトのために連結されます tile_barrier(TPL ライブラリから Barrier クラスを推測します) - すべてのスレッドが tile_barrier.Wait を呼び出す場合、それらは tile_barrier.Wait() メソッドを引き続き呼び出すことができます。 例えば:
Parallel_for_each (tiledMatrix, (tiled_index)<2,2>idx) restrict(amp) ( // 32 バイトはブロック内のすべてのスレッドで共有されます tile_static int local; // このスレッドが勝つために要素に値を割り当てます local = 42; // idx.barrier - tile_barrier のインスタンスidx.barrier.wait(); // これで、このフローを「ローカル」配列に変換できます。 // 他のフローの vicorist インデックス!);
今こそ、特定のお尻から知識を奪う時です。 メモリのモザイク構成をブロックすることなく、行列の乗算 vikonana の実装に目を向け、説明されている新しい最適化に追加しましょう。 許可されているのは、256 のローゼミック マトリックス番号 - 16 x 16 のブロックで pratsyuvati を提供できるようにすることです。典型的なホールセール アルゴリズムを使用した行列、および乗算プロセッサ キャッシュ リカバリの乗算の倍数の乗算)。
そのアプローチの本質は攻撃的であることです。 C i,j (行列結果の行 i と列 j の要素) を知るには、スカラー twirmіzh A i,* (最初の行列の i 番目の行) と B * を計算する必要があります。 j (別の行列の j 番目の行)。 ただし、これは、行のプライベート スカラー作成の計算と、結果のさらなる包含の計算に相当します。 行列乗算アルゴリズムをモザイク バージョンに変換する環境を微調整できます。
Void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) ( array_view 最適化の本質は、モザイク内のスキン フロー (16 x 16 のブロックに対して 256 のフローが作成される) が、出力マトリックス A および B 内のフラグメントの 16 x 16 ローカル コピーでその要素を初期化するという事実で説明されています。 . z tsikh ブロックし、すべての流れを一度にスキン行とスキン stovptsa に 16 回反転します。 そのようなpіdhіdsuttєvoは、動物の数をメインメモリに減らします。 行列の結果の要素 (i,j) を計算するために、アルゴリズムは最初の行列の i 番目の行と他の行列の j 番目の行を必要とします。 モザイクのストリームが 16x16 で、ダイアグラムに表示され、k=0 である場合、最初の行列と他の行列の影付きの領域が分割されたメモリに読み込まれます。 次のステップは、行列結果の要素 (i,j) を計算し、外部行列の i 行目と j 列目から最初の k 要素の部分スカラー加算を計算することです。 誰にとって、モザイク組織の停滞は生産性の大幅な向上を保証します。 複数の行列のモザイク バージョンは、単純なバージョンよりも高速で、約 17 ミリ秒かかります (サイズが 1024 x 1024 の同じ単一の行列の場合)。これは、バージョンごとに 430 shvid 長くなり、かなり大きなプロセッサで高速になります! まず、C ++ AMP フレームワークについての話を終えて、ツール (Visual Studio 内) を推測し、販売店を見つけたいと思います。 Visual Studio 2012 пропонує налагоджувач для графічного процесора (GPU), що дозволяє встановлювати контрольні точки, досліджувати стек викликів, читати та змінювати значення локальних змінних (деякі прискорювачі підтримують налагодження для GPU безпосередньо; для інших Visual Studio використовує програмний симулятор), та профільник, щоグラフィック プロセッサのジャミングからの操作を並列化するために、アドオンの動作を評価する機能を提供します。 Visual Studio を使いこなす方法の詳細については、記事「保護ヘルパー. MSDN サイトの C++ AMP プログラムのカスタマイズ。 この記事の前に、灯油添加剤でグラフィック プロセッサのプレッシャーを克服するプロテオの方法と同様に、私の C++ のみの例を示しました。 方法の 1 つは、相互運用性ツールを使用して、グラフィックス プロセッサのコアでの作業を低レベルの C++ コンポーネントに移行できるようにすることです。 このソリューションは、C++ AMP フレームワークをハックしたい人、またはハッキング アドオンで既製の C++ AMP コンポーネントをハックできる人に推奨されます。 2 番目の方法は、kern コードからグラフィック プロセッサと直接連携するライブラリをハックすることです。 Ninіsnuєkіlkalibrіbrіkov。 たとえば、GPU.NET と CUDAfy.NET (商業的な提案に腹を立てる)。 GPU.NET GitHub リポジトリの下にカーソルを置きます。これは、2 つのベクトルのスカラー作成の実装を示しています。 Public static void MultiplyAddGpu(double a, double b, double c) (int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X; int TotalThreads = BlockDimension.X * GridDimension.X; for (int ElementIdx = ThreadId; 映画の拡張機能 (C++ AMP に基づく) を習得する方が簡単で効率的であるかどうか、同等のライブラリで相互作用を整理したり、IL の映画に変更を加えたりする方が簡単かどうか疑問に思っています。 それ以来、.NET と GPU での並列プログラミングの可能性を単独で見てきたので、並列計算の編成が生産性を向上させる重要な方法であることに疑いを失った人は誰もいません。 世界中のリッチなサーバーやワークステーションには、優れたグラフィカル プロセッサが無数に搭載されているため、追加しただけでは十分ではありません。 タスク並列ライブラリは、現在利用可能な中央処理装置のすべてのコアをロボットに含める独自の機能を提供し、同期、タスクの超越的な断片化、ビコネーションのスレッド間のロボットの神経衰弱の問題を解決したいと考えています。 C ++ AMP フレームワークと、グラフィック プロセッサ上で並列コンピューティングを編成するその他の豊富なライブラリは、グラフィック プロセッサの数百のコア間の並列コンピューティングをうまく克服することができます。 Nareshti、残りの時間で情報技術の開発の主な方向性の1つになった部門の数を計算するために、悪い技術の停滞による生産性の向上を増やすことはできません. ラップトップを販売する最大の企業の 1 つのテクニカル ディレクターとコンピューター市場について話す機会があったかのように。 Tsey "fahіvets" namagavsya は、会社の助けを借りて説明します。ラップトップ自体の構成はそれほど必要ではありません。 中央処理装置 (CPU) の 1 時間が終わり、同時にすべてのプログラムがグラフィックス プロセッサ (GPU) で活発に充電されているというのは、独り言としては非常に楽しいものでした。ラップトップのパフォーマンスが低下するのはグラフィック プロセッサによるものであり、CPU についてはまったく問題ありません。 テクニカルディレクターに話して思い出させようとする必要があることを理解して、私は時間に立ち止まらず、別のパビリオンで必要なラップトップを購入しました。 プロテ、売り手のそのような叫び声の無能さのまさに事実は私に印象的です。 Bulob zrozumіlo、yakbi vinは私を購入のようにだまそうとしました。 いいえ。 話した人たちのVіnshirovіriv。 したがって、おそらく、NVIDIA と AMD のマーケティング担当者は、自分たちのパンを無駄に食べているわけではなく、今日のコンピューターにおけるグラフィックス プロセッサの支配的な役割について、ある種のコリストヴァチフの考えを再考するのに遠く離れています。 今日のグラフィック プロセッサ (GPU) 料金がますます一般的になっているという事実は、疑いの余地はありません。 ただし、中央処理装置の役割を軽視しないでください。 それより、もっとコア資産の重要性を語るなら、この日は生産性がいっぱいで、CPUの生産性でさらに落ちます。 GPU 上のプログラム数の計算には、プログラム数よりも Tobto の方が重要です。 さらに、GPU での計算は、科学開発に特化した HPC システムでの計算よりも重要です。 そして、GPU 上の zastosovuyutsya が指で再仕上げできる、coristuvatsky 追加の軸。 これを念頭に置いて、この場合の「GPUで計算された」という用語は完全に正しいわけではなく、オマーンに導入できることに注意する必要があります. 右側は、プログラムが GPU で実行されているからといって、CPU が実行されていないわけではありません。 GPU での計算は、電荷の転送を中央処理装置からグラフィックス処理装置に転送します。 音、中央処理装置がビジー状態になり、中央処理装置に指示するグラフィックプロセッサにより、生産性を向上させ、1日の作業時間を短縮できます。 さらに、ここでの GPU 自体は、CPU の独自のプロセッサ プロセッサの役割を果たしますが、同時にそれを再び置き換えることはありません。 なぜ GPU での計算がそれほど万能薬ではないのか、なぜ stverzhuvat が正しくないのかを理解するには、CPU の能力をひっくり返す能力の計算とは何か、その違いを考慮する必要があります。中央およびグラフィック プロセッサ。 CPU コアは、最大の生産性で後続の命令の単一スレッドに従うように設計されており、GPU は命令の多数の並列スレッドを実行するように設計されています。 誰がpolygaєの原則をvіdminnіstvіdminnіstgrafіchnіhprotsesorіvіdcentralnyhにしました。 CPUは、ユニバーサルプロセッサ、または一般的な認識のプロセッサであり、整数を処理する単一の命令ストリームの高い生産性を達成するための最適化、および浮動小数点数です。 データと命令を使用してメモリにアクセスする場合、より重要なのは vipadkovym ランクです。 CPU のパフォーマンスを向上させるために、スティンクは、より多くの命令を並行して書き込むことができるように設計されています。 たとえば、プロセッサのコアにはコマンドのポストオーダータイピングのブロックがあり、命令を順不同に並べ替えることができ、同じスレッドでの命令の実装の並列処理を増やすことができます。 それでもなお、大量の命令を並列に作成することはできず、プロセッサ コアの中央にある命令の並列化のオーバーレイはさらに重要であるように思われます。 この事実に対して、不可解な自白の処理者は、少数の勝利ブロックを持っている可能性があります。 政府のグラフィックプロセッサは根本的に異なります。 雄大な数のコマンドの並列ストリームが終了するまで、心から投影されます。 さらに、コマンドのストリームは並列化されるため、グラフィックス プロセッサの命令を並列化するための日々のオーバーヘッドはまったくありません。 画像視覚化割り当てのグラフィック プロセッサ。 簡単に言うと、入力でポリゴンのグループを受け取り、必要な操作を実行して、出力でピクセルを確認します。 ポリゴンとピクセルの処理は独立しており、1 つのタイプを除いて並行して処理できます。 したがって、GPU での作業の並列編成により、CPU の命令のシーケンシャル フローの観点から、利用しやすい多数の異なるブロックが存在します。 グラフィックスと中央処理装置は、メモリへのアクセスの原則が異なります。 メモリへの GPU アクセスは転送が簡単です。テクスチャ テクスチャがメモリから読み込まれるとすぐに、特定の時間にランド テクセルのタームが来ます。 記録するときも同じことが記録されます。ピクセルがフレームバッファに記録される場合、数タクトの後、ピクセルが記録され、並べ替えが指示されます。 CPU の前面にあるその GPU は、大規模な拡張のキャッシュを必要とせず、テクスチャには数キロバイトしか必要ありません。 GPU と CPU のメモリを使用した作業の差分と原理。 そのため、最新のすべての GPU はもう少し多くのメモリ コントローラーを持つことができ、同じグラフィック メモリが高速であるため、グラフィック プロセッサはよりリッチになる可能性があります。 約ユニバーサルプロセッサと同等のより多くのメモリ構築容量。これは、雄大なデータフローで動作する並列rozrakhunkivsにとっても重要です。 ユニバーサルプロセッサーで b 約クリスタル領域の大部分は、コマンドとデータのさまざまなバッファ、デコード ブロック、ハードウェア転送ブロック、デコード ブロック、コマンド並べ替えブロック、および 1 番目、2 番目、3 番目のイコールのキャッシュによって占有されます。 これらのハードウェア ブロックはすべて、同等のプロセッサ コアに並列処理を分散するための多数でない命令フローの実行を高速化するために必要です。 vykonavchi ブロック自体は、ユニバーサル プロセッサのスペースをほとんど占有しません。 一方、グラフィックプロセッサでは、メインエリアは数値ブロック自体で占められているため、数千のコマンドストリームを一度に処理できます。 現在のCPUを基準にすると、グラフィックスプロセッサは多数の算術演算の並列計算ができると認識されていると言えます。 非グラフィカル タスクのグラフィックス プロセッサの複雑さを計算することは可能ですが、その場合にのみ、開発されたタスクとして、GPU にある何百もの異なるブロックでアルゴリズムを並列化する可能性があります。 GPU 上の Zokrema、vykonannya rozrahunkiv は、変動の結果を表示します。その一連の数学的操作が zastosovuetsya の大きな義務になるまで。 最短で結果が出る、数の演算命令が記憶されてもすごい。 この操作は vikonannyam の管理にあまり役立ちません。数個以上の keshpam'yati を必要としません。 科学研究の非個人的なアプリケーションを導入することは可能ですが、効率の点で CPU に対する GPU の優位性は計算できません。 したがって、分子モデリング、ガスダイナミクス、rіdinのダイナミクス、およびGPU上のrazrahunkіvに接続された他のvіdmіnnoからの多くの科学的追加。 また、タスクを分離するためのアルゴリズムは数千のスレッドで並列化できるため、そのようなタスクを GPU ジャムから分離する効率は高くなる可能性があり、単一の認識のプロセッサのみを分離することは可能です。 ただし、CPU と GPU だけが異なるコマンドを変更する場合、CPU から GPU に任意のタスクの決定を行って転送するのはそれほど簡単ではありません。 つまり、プログラムがCPUに書き込まれている場合、x86コマンドのセットは停止し(そうでない場合、コマンドのセットはプロセッサの特定のアーキテクチャと合計されます)、グラフィックプロセッサの軸はすでに書き込まれています同じ他の一連のコマンドを使用して、そのアーキテクチャを引き続き保護できます。 最新の 3D 山を開発する場合、DirectX および OrenGL API がインストールされ、プログラマーがシェーダーとテクスチャーを操作できるようになります。 ただし、グラフィックス プロセッサで非グラフィカルな計算に DirectX および OrenGL API を使用することは、最適なオプションではありません。 初めて、最初に作業を開始する場合は、GPU (汎用 GPU、GPGPU)、BrookGPU ワイン コンパイラに非グラフィカルな計算を実装してみてください。 それまでは、小売業者はグラフィックス API OpenGL および Direct3D を介してビデオ カードのリソースにアクセスする必要がありました。これによりプログラミング プロセスが大幅に簡素化されましたが、3D オブジェクト (シェーダー、テクスチャなど)。 Tse は、ソフトウェア製品で GPGPU がブロックされる原因になりました。 BrookGPU は独自のトランスレーターになりました。 ムービー Ci に拡張された Qi ストリームは、trivimer API のプログラマーによって採用され、何らかの理由で 3D プログラミングの知識の必要性が失われた可能性があります。 ビデオカードの圧力を計算することは、プログラマーが並列拡張用の追加プロセッサーとして利用できるようになりました。 コンパイラ BrookGPU、C コードと拡張子、widow コードでファイルを処理し、DirectX または OpenGL をサポートするライブラリにリンクします。 BrookGPU、NVIDIA、および ATI (非 AMD) の企業が、生まれつつあるグラフィックス プロセッサの重要な認識を計算する技術に敬意を払い、直接的でより大きなアクセスを提供する独自の実装の開発を開始した理由3D プロセッサの計算ブロックに。 その結果、NVIDIA は、並列コンピューティング用の CUDA (Compute Unified Device Architecture) ハードウェアおよびソフトウェア アーキテクチャを開発しました。 CUDA アーキテクチャにより、NVIDIA グラフィックス プロセッサでの非グラフィカル計算の実装が可能になります。 CUDA SDK のパブリック ベータ版のリリースは、2007 年 2 月にリリースされました。 CUDA API は言語の方言 Cі の単純化に基づいています。 CUDA SDK アーキテクチャにより、プログラマーは、C プログラム テキストの前に特別な関数を含め、NVIDIA グラフィックス プロセッサに実装されたアルゴリズムを確実に実装できます。 コードを CUDA SDK ウェアハウスに正しく変換するには、NVIDIA nvcc コマンド ライン コンパイラを含める必要があります。 CUDA は、Linux、Mac OS X、Windows などのオペレーティング システム向けのクロスプラットフォーム ソフトウェアです。 AMD (ATI) も独自のバージョンの GPGPU テクノロジをリリースしました。以前は ATI Stream と呼ばれていましたが、現在は AMD Accelerated Parallel Processing (APP) と呼ばれています。 AMD APP は、業界標準の OpenCL (Open Computing Language) に基づいています。 OpenCL 標準は、命令のレベルとデータのレベルでの並列処理と GPGPU 技術の実装を保証します。 私は標準を変更します。この標準はライセンス承認の対象ではありません。 重要なことに、AMD APP と NVIDIA CUDA はいずれも議論の余地がなく、NVIDIA CUDA の残りのバージョンは OpenCL をサポートしています。 ビデオ コンバーターでの GPGPU のテスト また、NVIDIA グラフィックス プロセッサでの GPGPU の実装については、CUDA テクノロジが認識され、AMD グラフィックス プロセッサでは API APP が認識されることを説明しました。 意図したとおり、ストリームの数を並列化できるため、GPU 上の非グラフィカルな数値の数はそれよりも少なくなります。 しかし、コリストゥバッハのサプリメントのほとんどは、この基準を満たしていません。 Vtim、єdeakіvinyatki。 たとえば、今日のビデオ コンバーターのほとんどは、NVIDIA および AMD グラフィックス プロセッサでの計算能力を向上させています。 GPU 料金がビデオ コンバーターでいかに効果的に使用されているかを理解するために、Xilisoft Video Converter Ultimate 7.7.2、Wondershare Video Converter Ultimate 6.0.3.2、および Movavi Video Converter 10.2.1 の 3 つの一般的なソリューションを選択しました。 デジタル コンバーターは、NVIDIA や AMD のさまざまなグラフィックス プロセッサの機能を強化します。カスタム ビデオ コンバーターでは、この機能を無効にすることができます。これにより、GPU の読み込みの効率を評価できます。 ビデオ変換については、3 つの異なるビデオを zastosovuvali します。 最初のビデオ クリップ 3 分 35 分 1.05 GB。 Vіnbuvはデータストレージ形式(コンテナ)mkvで記録し、そのような特徴を示します: 別のビデオ クリップ 4 分 25 分 1.98 GB。 Vіnbuvはデータストレージ形式(コンテナ)MPGで記録し、そのような特徴を示します: 197 MB の 3 番目のビデオ クリップ Mav trivality 3 xv 47。 データ ストレージ形式 (コンテナー) MOV のレコードを獲得し、そのような特性を理解する: 3 つのテスト ビデオはすべて、iPad 2 タブレットでのレビュー用に、さまざまなビデオ コンバーターから MP4 データ ストレージ フォーマット (H.264 コーデック) に変換されました。 重要なことに、完全に同一になるわけではなく、3 つのコンバーターすべての変換が改善されました。 ビデオコンバーターの効率を向上させるには、変換の同じ時間は正しくありません。 たとえば、Xilisoft Video Converter Ultimate 7.7.2 ビデオ コンバーターには、変換用の iPad 2 プリセット - H.264 HD ビデオがありました。 次の微調整されたコーディングがあるプリセットはどれですか。 ビデオ コンバーター Wondershare Video Converter Ultimate 6.0.3.2 には、iPad 2 のプリセット全体が含まれており、次の追加調整が行われています。 Movavi Video Converter 10.2.1 には、スタックした iPad プリセット (1280*um*720、H.264) (*.mp4) があり、次の調整があります。 スキン ビデオ クリップの変換は、グラフィック プロセッサと CPU の両方に対して、スキン ビデオ コンバーターでさらに 5 回実行されました。 スキンの変換後、コンピューターはリセットされます。 さて、スキンビデオコンバーターでスキンビデオを10回変換しました。 ルーチン作業を自動化するために、グラフィカル インターフェイスを備えた特別なユーティリティが作成されました。これにより、テスト プロセスを再び自動化できます。 次の構成をテストするためのスタンド: スタンドにはOS Windows 7 Ultimate(64bit)を搭載。 最近、ロボットプロセッサの通常モードでテストを実施し、システムのすべてのコンポーネントを解決しました。 これにより、Intel Core i7-3770K プロセッサは、Turbo Boost モードがアクティブな状態で 3.5 GHz の公称周波数で実行されます (Turbo Boost モードでの最大プロセッサ周波数は 3.9 GHz になります)。 次に、テストを繰り返しましたが、プロセッサを 4.5 GHz の固定周波数にオーバークロックした場合 (Turbo Boost モードを使用せずに)。 Tseは、プロセッサ(CPU)の周波数を変換する速度の妥当性を明らかにすることを許可しました. テストの次の段階では、標準プロセッサのアップグレードに目を向け、他のビデオ カードでテストを繰り返しました。 このようにして、アーキテクチャの異なるいくつかのビデオカードでビデオ変換が行われました。 古いビデオ カード NVIDIA GeForce 660Ti は、28 nm プロセス テクノロジで動作するコード指定 GK104 (Kepler アーキテクチャ) の 1 ビット グラフィック プロセッサに基づいています。 グラフィックス プロセッサ全体には 35.4 億個のトランジスタが必要であり、水晶の面積は 294 mm2 である必要があります。 推測では、GK104 グラフィック プロセッサには、いくつかのクラスタとグラフィック処理 (Graphics Processing Clusters、GPC) が含まれています。 プロセッサの倉庫でGPCєの独立した建物をクラスター化し、pratsyuvatiをokremіpristroїとして構築すると、oskolkiには必要なリソース(ロゼット、幾何学的エンジン、テクスチャモジュール)が含まれる場合があります。 そのようなクラスターが 2 つのストリーミング マルチプロセッサー SMX (ストリーミング マルチプロセッサー) を持つことができ、1 つのクラスター内の GK104 プロセッサーでは、1 つのブロッキング マルチプロセッサー、つまり SMX マルチプロセッサー。 SMX ストリーミング マルチプロセッサには 192 個のストリーミング カウント コア (CUDA コア) がありますが、GK104 プロセッサには 1344 個のカウント CUDA コアがあります。 さらに、SMX マルチプロセッサ スキンには、16 のテクスチャ ユニット (TMU)、32 の特殊機能ユニット (SFU)、32 のロードストア ユニット (LSU)、PolyMorph エンジンなどが含まれています。 GeForce GTX 460 ビデオ カードは、Fermi アーキテクチャに基づくコード指定 GF104 のグラフィックス プロセッサに基づいています。 このプロセッサは 40 nm プロセス テクノロジで動作し、19 億 5000 万個近くのトランジスタを搭載しています。 GF104 グラフィックス プロセッサには、2 つの GPC クラスター グラフィックスが含まれています。 それらにはSMマルチプロセッサの多くのスレッドがあり、クラスターの1つにあるGF104プロセッサには、ブロックしているマルチプロセッサが1つあります。これが、すべてのSMマルチプロセッサの理由です。 SM ストリーミング マルチプロセッサには 48 個のストリーミング処理コア (CUDA コア) があり、GK104 プロセッサには 336 個の CUDA 処理コアがあります。 さらに、SM マルチプロセッサのスキンは、テクスチャ モジュール (TMU) の合計、特殊機能ユニット (SFU) の合計、16 のロードストア ユニット (LSU)、PolyMorph エンジンなどを収容できます。 GeForce GTX 280 グラフィック プロセッサは、NVIDIA グラフィック プロセッサの統合アーキテクチャの別の世代に属し、そのアーキテクチャは Fermi および Kepler アーキテクチャの影響を強く受けています。 GeForce GTX 280 グラフィックス プロセッサは、Fermi および Kepler アーキテクチャの GPC グラフィック処理クラスタと類似し、場合によっては類似するテクスチャ処理クラスタ (Texture Processing Clusters、TPC) で構築されています。 GeForce GTX 280 プロセッサには、このようなクラスターが 10 個あります。 スキン TPC クラスターには、3 つのストリーム、マルチプロセッサ SM、およびテクスチャの振動とフィルタリング (TMU) の合計ブロックが含まれます。 スキン マルチプロセッサは、8 つのストリーム プロセッサ (SP) で構成されます。 マルチプロセッサは、グラフィック データなどのテクスチャ データの選択とフィルタリングのブロック、およびいくつかの rozrachunk タスクを置き換えることもできます。 したがって、1 つの TPC クラスターには 24 個のストリーム プロセッサがあり、GeForce GTX 280 グラフィックス プロセッサには既に 240 個あります。 NVIDIA グラフィックス プロセッサでテストされたビデオ カードの特性を表に示します。 表をホバリングすると、AMD Radeon HD6850 ビデオ カードはありません。これは当然のことです。技術的な特性については、NVIDIA ビデオ カードと比較することが重要です。 そして、私たちはїїokremoを見ていきます。 AMD Radeon HD6850 グラフィックス プロセッサ (コードネーム Barts の可能性あり) は、40 nm プロセス テクノロジを使用して製造されており、17 億個のトランジスタに対応できます。 AMD Radeon HD6850 プロセッサのアーキテクチャは、数値データ ビューのストリーミング処理用の高レベル プロセッサのアレイを備えた統合アーキテクチャです。 AMD Radeon HD6850 プロセッサは 12 個の SIMD コアで構成されており、それぞれにスーパースカラー ストリーム プロセッサの 16 ブロックといくつかのテクスチャ ブロックが含まれています。 5 つのユニバーサル ストリーム プロセッサを置き換えるスキン スーパースカラー ストリーム プロセッサ。 したがって、AMD Radeon HD6850 グラフィックス プロセッサには、12*um*16*um*5=960 個のユニバーサル ストリーム プロセッサがあります。 AMD Radeon HD6850 ビデオ カードのグラフィックス プロセッサの周波数は 775 MHz に設定されており、GDDR5 メモリの実効周波数は 4000 MHz です。 obsyagメモリが1024 MBになる人。 Otzhe、テストの結果を楽しみにしています。 NVIDIA GeForce GTX 660Ti ビデオ カードと Intel Core i7-3770K プロセッサの通常モードが動作するかどうか、最初のテストから始めましょう。 図上。 図 1 ~ 3 は、グラフィックス プロセッサのジャムがあるモードとないモードで、3 つのコンバーターによって 3 つのテスト ビデオを変換した結果を示しています。 テストの結果からわかるように、グラフィック プロセッサの選択の影響は є です。 Xilisoft Video Converter Ultimate 7.7.2 ビデオ コンバーターの場合、グラフィック プロセッサの速度が低下すると、最初のビデオ クリップ、もう 1 つのビデオ クリップ、および 3 番目のビデオ クリップの変換時間は明らかに 14.9 および 19% 短縮されます。 Wondershare Video Converter Ultimate 6.0.32 ビデオ コンバーターの場合、グラフィック プロセッサにより、1 時間、2 番目、3 番目のビデオ クリップの変換を 10、13、23% 高速化できます。 また、グラフィック プロセッサ ジャミングの場合に最も重要なのは、Movavi Video Converter 10.2.1 です。 1 番目、2 番目、3 番目のビデオ クリップの場合、変換時間は 64、81、41% です。 グラフィック プロセッサを使用してビデオを再生し、それをビデオ クリップとして配置し、ビデオ変換を修正したことは明らかでした。 Intel Core i7-3770K プロセッサを 4.5 GHz にオーバークロックした場合、どのように変換を時間単位で達成できるか考えてみましょう。 通常モードでは、ドライブが変換され、ターボ ブースト モードでは、すべてのプロセッサ コアが 3.7 GHz の周波数で動作し、周波数を 4.5 GHz に上げると 22% オーバークロックされることに注意してください。 図上。 図 4 ~ 6 は、異なるグラフィックス プロセッサを使用するモードと使用しないモードでプロセッサをオーバークロックしたときの 3 つのテスト ビデオの変換結果を示しています。 グラフィック プロセッサをブロックする際に、変換時間ごとに賞金を引き出すことができます。 Xilisoft Video Converter Ultimate 7.7.2 ビデオ コンバーターの場合、グラフィック プロセッサの速度が低下すると、最初のビデオ クリップ、もう 1 つのビデオ クリップ、および 3 番目のビデオ クリップの変換時間は明らかに 15.9 および 20% 短縮されます。 Wondershare Video Converter Ultimate 6.0.32 ビデオ コンバーターの場合、グラフィック プロセッサにより、1 時間、2 番目、3 番目のビデオ クリップの変換を 10、10、20% 高速化できます。 Movavi Video Converter 10.2.1 の場合、グラフィック プロセッサのスローダウンにより、変換時間を 59、81、および 40% 高速化できます。 明らかに、プロセッサの分割により、新しいグラフィック プロセッサを使用せずに、別のグラフィック プロセッサを使用して変換時間を変更できるように、不思議に思わずにはいられません。 図上。 図 7 ~ 9 は、通常モードとオーバークロック モードでグラフィック プロセッサを使用せずにビデオを変換した結果を示しています。 このように、変換は GPU に負担をかけずに CPU のみで実行されるため、ロボット プロセッサのクロック周波数の増加が変換時間の短縮 (変換の高速化) につながることは明らかです。 したがって、すべてのテスト動画で変換速度がほぼ同じになることは自明です。 したがって、Xilisoft Video Converter Ultimate 7.7.2 ビデオ コンバーターの場合、プロセッサがオーバークロックされている場合、変換時間は最初のビデオ クリップ、もう 1 つのビデオ クリップ、および 3 番目のビデオ クリップで 9、11、および 9% 短縮されます。 Wondershare Video Converter Ultimate 6.0.32 ビデオ コンバーターの場合、1 番目、2 番目、3 番目のビデオ クリップの変換時間が 9.9 時間と 10% 短縮されました。 さて、ビデオ コンバーター Movavi Video Converter 10.2.1 の場合、変換時間は 13、12、12% 短縮され、正しいです。 このように、プロセッサを 20% の周波数でオーバークロックすると、変換にかかる時間が約 10% 短縮されます。 ロボット プロセッサの通常モードとオーバークロック モードでビデオ クリップをグラフィック プロセッサの代替に変換する時間は均等化されます (図 10-12)。 ビデオ コンバーター Xilisoft Video Converter Ultimate 7.7.2 の場合、プロセッサーをオーバークロックすると、1、2、3 番目のビデオ クリップの変換時間が 10、10、9% 短縮されます。 Wondershare Video Converter Ultimate 6.0.32 ビデオ コンバーターの場合、1 番目、2 番目、3 番目のビデオ クリップの変換時間が 9.6 時間短縮され、5% 短縮されました。 さて、Movavi Video Converter 10.2.1 ビデオ コンバーターの場合、変換時間は 0.2、10、10% 短くて正解です。 Bachimo と同様に、コンバーター Xilisoft Video Converter Ultimate 7.7.2 および Wondershare Video Converter Ultimate 6.0.32 の場合、プロセッサをオーバークロックした場合の変換の最短時間は、別のグラフィックス プロセッサを使用した場合とほぼ同じであるため、ジャミングがなく、論理的でスケーラブルです。コンバーターは、GPU で計算を変換するのにあまり効率的ではありません。 また、GPU で有効な Movavi Video Converter 10.2.1 コンバーターの軸は、GPU の切り替えモードでプロセッサを切り替えても、変換時間にはほとんど影響しません。これも理解できます。この方向のチップは主にグラフィック プロセッサの影響を受けます。 次に、さまざまなビデオ カードでテストした結果を見てみましょう。 ビデオ カードがより薄く、グラフィック プロセッサ (または AMD ビデオ カードのユニバーサル ストリーム プロセッサ) により多くの CUDA コアがあれば、グラフィック プロセッサがビジーなときにビデオを変換する方が効率的です。 エール、実際には、私はそのように外出したくありません。 NVIDIA グラフィックス プロセッサに基づくビデオ カードに関しては、状況が来ています。 代替コンバーターである Xilisoft Video Converter Ultimate 7.7.2 および Wondershare Video Converter Ultimate 6.0.32 では、ビデオ カードの種類によっては変換時間を変換することは事実上不可能です。 そのため、ビデオ カード NVIDIA GeForce GTX 660Ti、NVIDIA GeForce GTX 460、および NVIDIA GeForce GTX 280 が GPU の可変計算モードにある場合、変換時間は同じように表示されます (図 13-15)。 米。 1. 初回変換結果 米。 14.別のビデオクリップの変換時間の結果 米。 15. 3 番目のビデオ クリップを時間に応じて変換した結果 コンバーター Xilisoft Video Converter Ultimate 7.7.2 および Wondershare Video Converter Ultimate 6.0.32 に実装されているグラフィック プロセッサの計算アルゴリズムは単純に非効率的であり、すべてのグラフィック コアをアクティブに変換することはできません。 スピーチの前に、まさにcimが説明され、これらのコンバーターでは、GPU代替モードでの1時間あたりの変換の違いが小さいという事実が説明されます. Movavi Video Converter 10.2.1 では状況が異なります。 私が覚えている限りでは、このビルトイン コンバーターは既にグラフィックス カードを GPU に変換するのに効率的であるため、GPU コンバーター モードでは、変換時間はビデオ カードの種類に似ているはずです。 そして、AMD Radeon HD 6850 ビデオ カードを搭載した軸は問題ありません。 ビデオカードのドライバーが「曲がっている」か、コンバーターに実装されているアルゴリズムに深刻な追加処理が必要になり、GPU での結果の計算が改善されない場合は悪化します。 より具体的には、このような状況です。 Xilisoft Video Converter Ultimate 7.7.2 コンバーターの場合、最初のテスト ビデオ クリップを変換するための変換時間は 43% 増加し、別のクリップを変換すると 66% 増加します。 さらに、Xilisoft Video Converter Ultimate 7.7.2 は、より不安定な結果が特徴です。 Rozkid 時間のコンバージョンは 40% に達する可能性があります。 そのために、すべてのテストを 10 回繰り返し、平均的な結果を確保しました。 また、コンバーター Wondershare Video Converter Ultimate 6.0.32 および Movavi Video Converter 10.2.1 の軸は、3 つのビデオ クリップすべてを変換するための異なるグラフィック プロセッサを使用しており、変換中に変化しません! Wondershare Video Converter Ultimate 6.0.32 および Movavi Video Converter 10.2.1 コンバーターは、変換時に AMD APP テクノロジーがちらつかないか、AMD ビデオ ドライバーが単に「曲がっている」ため、AMD APP テクノロジーはちらつきません。仕事。 実施されたテストから、そのような重要な visnovki を成長させることが可能です。 最新のビデオ コンバーターには、変換速度を上げることができる GPU ベースのテクノロジが搭載されている場合があります。 ただし、これはすべての計算が GPU に転送され、CPU が未完成のままになるという意味ではありません。 テストが示すように、GPGPU テクノロジを使用すると、中央処理装置が使用されなくなります。そのため、ビデオ変換に使用されるシステム内のタイトでリッチコアな中央処理装置はもはや関係ありません。 このルールの原因は、AMD グラフィックス プロセッサ上の AMD APP テクノロジにあります。 たとえば、AMD APP テクノロジーを有効にして Xilisoft Video Converter Ultimate 7.7.2 コンバーターを使用すると、CPU の負荷は効果的に軽減されますが、変換時間は短縮されず、むしろ増加します。 まず第一に、追加のグラフィック プロセッサを使用してビデオを変換する場合は、NVIDIA グラフィック プロセッサを使用してビデオ カードを変換することを目的としています。 実践が示すように、この方法でのみ、変換速度を向上させることができます。 さらに、コンバージョン率の実際の増加は、いくつかの豊富な要因の存在下で蓄積されることを覚えておく必要があります。 これは、ビデオの入出力形式であり、明らかにビデオ コンバータ自体です。 コンバーター Xilisoft Video Converter Ultimate 7.7.2 および Wondershare Video Converter Ultimate 6.0.32 はこのタスクには適していませんが、Movavi Video Converter 10.2.1 は NVIDIA GPU の機能を活用する上ですでに効果的です。 AMD グラフィックス プロセッサに基づくビデオ カードに関しては、それらをビデオ変換するタスクのために、それらを停止する必要はありません。 最短時間では回転率に変換はありませんが、最大時間では減少が見られます。 暗号通貨マイニングにはどのようなプログラムが必要ですか? マイニング用のプロパティを選択する際に何を保護する必要がありますか? ビットコインとイーサリアムをマイニングしてコンピュータに追加のビデオ カードを追加する方法は? コンピュータ ゲームのファンとして、より多くのビデオ カードが必要であることが判明しました。 全世界の何千もの koristuvachiv vikoristovuyu グラフィック アダプターで暗号通貨を獲得できます。 3 ハード プロセッサを搭載したカード数 鉱山作成 フェルミ- 中心の計算、yakіvydobuvayutsifrovіgroshіは実質的にzpoіtryaです! HeatherBober 誌の専門家である Denis Kuderin が、その識字率の高い乗算の財政について語っています。 私はあなたが何であるかを教えてあげる ビデオカードのマイニング 17 ~ 18 歳で、暗号通貨を獲得するための適切なアタッチメントを選択する方法と、ビデオ カードにビットコインが表示されなくなった理由について説明します。 あなたも知っている 最も生産的で最も強力なビデオカードを購入するプロのマイニングの場合は、マイニング ファームの効率を向上させるために専門家を連れて行きます。 優れたビデオ カードは、単なるデジタル信号アダプタではなく、ハード プロセッサであり、最も複雑な計算に対する建物ベースのソリューションです。 私を含む - ブロック言語(ブロックチェーン)のハッシュコードを計算する. 理想的なツールでグラフィカルな支払いを強奪するには 鉱業- 暗号通貨の種類。 食べ物:ビデオ カード プロセッサを使用する理由 また、コンピューターに中央処理装置が搭載されている場合はどうでしょうか。 ヨガのヘルプに料金を請求するのは論理的ではありませんか? 提案: CPU もブロックチェーンを数えることができますが、数百倍、下位のビデオ カード プロセッサ (GPU) で行うことができます。 そして、最高の人ではなく、他の人が最悪です。 彼らの仕事の原則が違うだけです。 そして、あなたがビデオカードを少し手に入れるとすぐに、そのような不明瞭な中心の強さはさらに動くでしょう. デジタルマネーを手に入れているように見える人について知らない人のために、ちょっとした話を。 鉱業 - 暗号通貨を生成する主な、時には唯一の方法. 破片やペニーは鋳造されていません。悪臭は物質的な物質ではなく、コードを数える責任を負うデジタル コードです。 Cimとマイナー、またはむしろコンピューターに従事しています。 クリムはコードを計算し、マイニングは最も重要な仕事の多くを数えます:
私はすぐに最初のヒューズを冷やしたいと思います-健康: 革の岩を採掘するプロセスはますます重要になっています. たとえば、追加のビデオカードの場合、それは長い間不採算でした。 GPU支援のチケットが一気に手に入る頑固なアマチュア、ビデオカードの代わりに専用プロセッサーが登場 ASIC. チップは電力を節約し、より効率的でコストを削減します。 すべてが順調ですが、秩序を保ちます 13万~15万ルーブル
. マイナーにとって幸いなことに、ビットコインは地球上で唯一の暗号通貨ではなく、数百ある暗号通貨の 1 つです。 その他のデジタルペニー - efіrіumi、Zcash、Expanse, ドッグコインや。。など。 以前と同様に、追加のビデオ カードを探すことは明らかです。 ブドウ畑は安定しており、買収は約 6 ~ 12 か月で元が取れます。 さらに別の問題は、ハード ビデオ カードの不足です。. 暗号通貨をめぐる誇大宣伝により、別棟の価格が上昇しました。 ロシアでマイニングに接続された新しいビデオカードを購入するのはそれほど簡単ではありません。 初期のマイナーは、オンライン ストア (海外を含む) でビデオ アダプターを購入するか、商品を購入する必要があります。 やめて、スピーチまで、ラジャではなく働きなさい: 素晴らしいswidで身に着けているzastarіvaєを採掘するための所有物. Avіtіnavіtでは、vidobotku暗号通貨のために農場全体を販売しています。 多くの理由があります: 一部の鉱夫は、デジタルペニーのデジタルブースからすでに「金持ち」になり、暗号通貨 (zocrema、為替取引) でより多くのキャッシュイン操作を行うことを決定しました。基地に発電所がないため、中国のクラスター。 3 分の 1 は、ビデオ カードから ASIC に切り替えました。 ただし、ニッチはまだ歌の収入をもたらすことであり、すぐにビデオカードの助けを借りることをお勧めします。そうしないと、未来に向かっている電車の底に追いつくことになります. フィールドに砂利が多い別の川。 さらに、デジタルコインの総数は増えていません。 今、都市はどんどん小さくなっています。 つまり、6 年前、1 つのブロックチェーンに対して、ビットコイン ネットワークが完成しました。 50コイン、一気に 12.5BTK. 計算の折り畳み可能性は1万倍に増加しました。 確かに、ビットコイン自体の価格は 1 時間で指数関数的に上昇しました。 マイニングには、ソロと倉庫プールの 2 つのオプションがあります。 孤独なビデオブースに対処するのは難しい - 母は大量のハッシュレートを必要としています(シングルテンション)、計算が小さいほど、成功したクロージングの可能性。 すべてのマイナーの 99% が働いています プール(イングリッシュプール - スイミングプール) - タスク数の計算に使用される寝室。 スピルマイニングはドロップファクターを減らし、安定した収入を保証します。 私の有名な鉱山労働者の 1 人は、このドライブからこのようにぶらぶらしていました。 このような鉱山労働者は、19 世紀の金鉱山労働者に似ています。 あなたは自分のナゲット (私たちの考えでは - ビットコイン) を揺さぶることができ、決して知ることはありません。 したがって、ブロックチェーンは閉鎖されませんが、フェンスを取り除くこともありません。 Trochs は、イーサやその他の暗号通貨について「自白した思想家」の可能性が高くなります。 独自の暗号化アルゴリズムにより、ETH は特別なプロセッサ (まだ発明されていません) の助けを借りて見ることはできません。 tsgogo vykljuchnovіdeokartiのVykoristovuyut。 エフィリウムやその他のアルトコインのお金のために、農家の数は今でも大事にされています。 完全なフェルミを作成するための 1 つのビデオ カードでは十分ではありません。 4 ピース - マイナーの「最低限の生活」、安定した収入のために投資されます。 ビデオアダプタの冷却システムも同様に重要です。 Іは、電気料金の支払いのような敬意とそのようなステータスをお見逃しなく. 許しを確実にし、プロセスをスピードアップするためのポクロコフの指示。 世界最大の暗号通貨の弾丸は、中国の領土だけでなく、アイスランドと米国にも配備されています。 正式には、tsіspіlnotiは主権を主張するのではなく、ロシアのサイトpuliv - rіdkіstіinternetiです。 すべてのエーテルに対してビデオ カードの石がより速く表示された場合は、通貨からお金を借りることになるため、請求書を収集する必要があります。 イーサリアムは非常に若いアルトコインであり、 ヨガマイニングのプルリブ. あなたの収入とyogoの安定性に何を築くべきかが豊富なvyborusvіlnoti。 プールは、次の基準に従って選択されます。 仮想通貨市場は日々変化しています。 コースに遅れずについていくことは価値があり、新しいデジタル ペニーが表示されます。 フォークビットコイン。 Traplyayutsya と地球規模の変化。 そのため、つい先日、イーサが近い将来、別のシステムに切り替えることができることが知られるようになりました。私には余剰がありました。 一言で言えば、Etherium merezhіからの収入はマティムットマイナー、「たくさんのケッセ」を持っている人、tobtoコインであり、pochatkivtsyは店を失うか閉店するか、他のペニーに切り替えます。 それでも、愛好家の「drіbnitsі」はまったく聞こえませんでした。 Tim も同様です。私はこのプログラムを Profitable Pool と呼びます。 しばらくの間、アルトコインのナビゲーションが自動的に表示されます。 Є 弾丸自体を検索するためのサービスと、実際の時間の評価。 プールのサイトに登録したら、特別なマイナー プログラムを取得する必要があります。電卓を使用して手動でコードを計算しないでください。 そのようなプログラムはたくさんあります。 ビットコインの価格について - 50
鉱夫また CGマイナー、エーテルの場合 エスマイナー. Nalashtuvannya には敬意と歌のスキルが必要です。 たとえば、スクリプトとは何かを理解し、それらをコンピュータのコマンド ラインに入力することを忘れないようにする必要があります。 技術的な点については、実践的なマイナーと明確にする必要があります。スキン プログラムのシャードには、インストールとカスタマイズの独自のニュアンスがある可能性があります。 まだ bitcoin-gamantsia または ethereum-collections を持っていない場合は、obov'yazkovo に登録する必要があります。 公式サイトからのGamantsіzavantazhuєmo。 弾丸自体を与える権利を手伝うこともありますが、無料です。 あとは、初日に工程を開始してチェックするだけでした。 Obov'yazkovo zavantazhte 補足プログラムでは、yak vydstezhuvatem がコンピューターのメイン ノードになりました - zavantage、過熱が薄すぎます。 コンピュータはコードを自動的に処理し、コードを計算します. カードやその他のシステムが故障しないように、いくつかの手順しか残されていません。 暗号通貨は、ハッシュレートに正比例する速度でガマンツに流れます。 法定通貨からデジタル通貨を転送する方法は?食事、毎日okremoїstatti。 要するに、最良の方法は交換ポイントです。 サービスのために自分のお金を取らないでください。あなたの仕事は、最小限の手数料で最適なコースを知ることです。 交換業者の専門的なサービスを手伝ってください。 ビデオカードを賢く選択してください。 捕まったペルシャ、またはそれは、すでにコンピューター上に立っているので、tezh main、エール エーテルのための風への気密性は乏しいでしょう. 主な指標は次のとおりです。生産性(緊張)、エネルギー供給、冷却、分散の見通し。 ここではすべてが簡単です-プロセッサの生産性はどれくらいですか、ハッシュコードを計算するのに適しています. 2 GBを超えるメモリを搭載したVіdminnіpokazniki zabezpechuyutカード。 І 256 ビット バスのアドオンを選択します。 cієїの128ビットは適切ではありません。 強度、価格、素晴らしい、素晴らしい - 高いハッシュレートなど。 エール、エネルギーショーケースを忘れないでください。 Deyakіの生産的なフェルミは、電気技師のスタイルを「与え」ます。 通常、4 ~ 16 枚のカードがスタックされます。 超世界の熱気、湾の荒廃、農夫自身の過失を振動させる。 エアコンのないワンルームマンションでの生活と練習は、穏やかに見え、不快です。 したがって、生産性が同じカードを 2 枚選ぶときは、生産性が高い人を優先します。 熱張力の少ない指標 (TDP)
. 最適な冷却設定は、Radeon カードを示しています。 他のカードが見つかった場合は、アクティブ モードで無料で使用できます。 Dodatkovіクーラーは、プロセッサーに熱をもたらすだけでなく、プロセッサーの寿命を延ばします。 Rozgin - ビデオ カードのワーキング ディスプレイの primus プロモーション。 「マップを分割」して 2 つのパラメーターにデポジットする可能性 – グラフィックス プロセッサの周波数とビデオ メモリの周波数. 締まりの数を上げたい場合は、自分で切断します。 ビデオカードの購入方法は?残りの世代への追加、または 2 ~ 3 年前にリリースされたグラフィカル トリムの縮小が必要です。 鉱業勝利カード AMD ラデオン, NVIDIA, Geforce GTX. ビデオ カードの回収表を見てみましょう (データは 2017 年末時点のものです)。 すでに述べたように、マイニングの人気が高まっているため、ビデオ カードは希少な商品になっています。 必要なアクセサリーを購入するために、たまたま多くの時間を費やしています。 最高のオンライン販売ポイントの概要が役立ちます。 執筆時点では、記事は販売されていますєカード AMD, NVIDIA(8 Gb)それはマイニングに適したものです。 同社は、ロシア連邦の鉱山労働者にとって最高の店の非公式の称号を繰り返し獲得しました。 運用サービス、顧客へのフレンドリーな配達、成功のための本社倉庫の高度な保有。 ギャンブルとマイニングのための有線ビデオ カード メーカーの直接のパートナー NVIDIA. 商品の最大期間は 14 日間です。 せっかちな読者、ヤクはすぐにマイニングを開始し、明日の朝からすでに収入を得たいと思っています。 スキルは鉱夫を獲得します? 収益は、所有、暗号通貨のレート、プールの効率、ファームの強度、ハッシュレートの量、およびその他の要因の購入に依存します。 距離を取ろうとすることができます 70,000ルーブル
、その他は満足 10ドルティジデンで。 ツェー 不安定で業績不振のビジネス。 Korisnіporady dopomozhutは収入を増やし、vitratiを最適化します。 急速に価格が上昇する通貨をマイニングして、より多くの収益を上げましょう。 お尻~エーテルを一度に密着させるため 300ドル、ビットコイン - 詳細 6000
. エール、仕事の流れを守るだけでなく、その日のエールとテンポを高める必要があります。 プールのウェブサイトまたはその他の専門サービスのマイニング計算機は、最適なプログラムを選択し、マイニング用のビデオカードをインストールするのに役立ちます。
B.NET グラフィックス プロセッサでのコンピューティングの代替手段
GPU および CPU アーキテクチャの機能
NVIDIA CUDA および AMD アプリ
試験台構成
試験結果

通常モードでビデオをテストする
ロボットプロセッサGPU モードのビデオ カード プロセッサ


グラフィックプロセッサモードの他のビデオカードヴィスノフキ
1. ビデオ カードのマイニング - 簡単なペニーと虚偽

2.追加のビデオカード用に暗号通貨をマイニングする方法 - 使用説明書
クロック 1. プールを選ぶ
Krok 2. プログラムのインストールとインストール
クロック 3
Krok 4. マイニングを開始し、統計に従ってください
Krok 5. 暗号通貨の表示
 - ルネティでのそのような計画の最高のリソース。 このモニタリングは、300 を超える交換ポイントの指標を示し、あなたをくすぐる通貨ペアのより良い見積もりを知ることができます。 それらを処理すると、このサービスは暗号通貨の埋蔵量を現金で表示します。 監視のリストは、過度に反応し、余分な交換サービスを提供する可能性が低くなります。
- ルネティでのそのような計画の最高のリソース。 このモニタリングは、300 を超える交換ポイントの指標を示し、あなたをくすぐる通貨ペアのより良い見積もりを知ることができます。 それらを処理すると、このサービスは暗号通貨の埋蔵量を現金で表示します。 監視のリストは、過度に反応し、余分な交換サービスを提供する可能性が低くなります。3. マイニング用のビデオカードを選ぶ際の注意点
1) 疲労
2) エネルギー供給
3) 冷蔵
 Yakіsneholodzhennyaprotsesora - neomіnіnumova成功したマイニング
Yakіsneholodzhennyaprotsesora - neomіnіnumova成功したマイニング4) 分散能力
4.マイニング用のビデオカードを購入する - TOP-3ストアを見て回る
1) トップコンピュータ
 コンピューターと関連技術を専門とするモスクワのハイパーマーケット。 Pratsyuє は 14 年以上にわたって市場に出回り、virobniks の価格で地上の世界 mayzhe から商品を供給しています。 Pratsyuєサービスの迅速な配達、白雲母には無料。
コンピューターと関連技術を専門とするモスクワのハイパーマーケット。 Pratsyuє は 14 年以上にわたって市場に出回り、virobniks の価格で地上の世界 mayzhe から商品を供給しています。 Pratsyuєサービスの迅速な配達、白雲母には無料。2) マイビットコインショップ
 専門店、 鉱業用商品のみの取引. ここでは、必要な構成のビデオ カード、ライフ ブロック、アダプター、ASIC マイナーのインストール (新世代のマイナー用) など、ホーム ファームの生活に必要なすべてのものを見つけることができます。 モスクワ近郊の有料配送とsamovivіzzі倉庫。
専門店、 鉱業用商品のみの取引. ここでは、必要な構成のビデオ カード、ライフ ブロック、アダプター、ASIC マイナーのインストール (新世代のマイナー用) など、ホーム ファームの生活に必要なすべてのものを見つけることができます。 モスクワ近郊の有料配送とsamovivіzzі倉庫。3) シップショップアメリカ
 米国からの商品の購入と配送。 マイニングに適した専用品と最高の商品を必要とする人のための仲介会社。
米国からの商品の購入と配送。 マイニングに適した専用品と最高の商品を必要とする人のための仲介会社。5. ビデオ カードのマイニングで収入を増やす方法 - 3 ページ
Porada 2. マイニング計算機を使用して、最適なマイニングを選択します