速度は偉大なダニッチの力を特徴づけます。 マーケティング百科事典。 戦う方法
ビッグデータ- 英語。 「素晴らしいデータ」。 この用語はDBMSの代替として登場し、ITインフラストラクチャの主要なトレンドの1つになりました。これは、業界の巨人であるIBM、Microsoft、HP、Oracleなどの大多数が戦略をよりよく理解し始めたためです。 ビッグデータは、従来の方法では処理できない大きな(数百テラバイト)データの配列です。 inodi-データ処理方法のためのツール。
ビッグデータジェレルの適用:RFIDサポート、ソーシャルメディア通知、気象統計、モバイルネットワークの加入者の地域に関する情報 スタイルネクタイおよびオーディオ/ビデオ録画機能からのデータ。 このため、「大きな賛辞」は、キャンペーン、健康保護、政府の管理、インターネットビジネス(募金活動)で、ターゲットオーディエンスの1時間の分析で広く賞賛されています。
特性
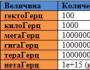
ビッグデータの兆候は「3つのV」としてマークされています。ボリューム-obsyag(dіysnobig); 多様性-多様性、非人格性; 速度-スウェーデン性(スウェーデンのラッピングに必要)。
優れたデータはほとんど構造化されておらず、その処理には特別なアルゴリズムが必要です。 優れたデータの分析方法の前に、次のことがわかります。
- (「Vydobuvannyadanikh」)–添付された茶色の知識を明らかにするための一連のアプローチ。これは、標準的な方法で取り除くことができます。
- クラウドソーシング(群衆-"natovp"、ソーシング-vikoristannya yak dzherelo)-重要なzavdan spolnymi zassillyボランティアの兆候、拘束力のある労働契約のperebuvayutではなくyakі、追加のITツールのscho調整活動。
- データ融合と統合("zmіshuvannyaiprovodzhennyadanih")-深い分析の枠組みの中で非人称的なジェレルを形成するための一連の方法。
- 機械学習(「機械学習」)-基本モデルに基づいて統計分析と予測を開発する方法を開発するピースインテリジェンスの開発を進めました。
- 画像の認識(たとえば、ビデオカメラまたはビデオカメラの外観の認識)。
- 広がり分析-インスピレーションを得るためのトポロジー、ジオメトリ、地理の選択。
- データの視覚化-結果を視覚化し、リモートモニタリングの基盤を刺激するための、追加のインタラクティブツールやアニメーションのための視覚的なイラストや図での分析情報の視覚化。
情報の選択と分析は、生産性の高い多数のサーバーに基づいています。 重要なテクノロジーは、オープンコードを備えたHadoopです。
時々多くの情報がある場合、フィールドの複雑さはデータを取得するためではなく、最大の重みで処理されるという事実にあります。 一般に、ビッグデータを操作するプロセスには、情報の収集、構造化、洞察とコンテキストの作成、行動への推奨事項の作成が含まれます。 最初の段階の前でさえ、作業方法を指定することが重要です。たとえば、navіschosamepotrіbnіdanі-cіlovoїauditії製品の指定。 そうでなければ、自分で打ち負かすことができるという事実を理解せずに、大量のレコードを取り除いてください。
ペレドモバ
「ビッグデータ」は、データ分析、予測分析、知的データ分析( データマイニング)、CRM。 この用語は、さらに大きなデータコミットメント、組織プロセスへのデータフローセキュリティの絶え間ない増加に関連する分野で勝利を収めています:経済学、銀行業務、製造、マーケティング、電気通信、Web分析、医学。
情報の急速な蓄積とともに、データ分析技術は急速に発展しています。 さらに、たとえば、クライアントを類似した類似性のあるグループにセグメント化することは可能でしたが、今では、リアルタイムモードでスキンクライアントのモデルを作成し、たとえばインターネット上を移動して検索することが可能になりました。特定の製品。 スパイの興味を分析することができ、モデルに応じて、特定の広告または特定の提案が表示されます。 モデルは、リアルタイムモードで更新および再作業することもできますが、これは想像を絶するほど運命的でした。
ブランチtelekomunіkatsії、napriklad、rozvinenіtehnologіїfor viznachennyafіzichnogoroztashuvannyastіlnikovihtelefonіvthatїhvlasnikіv、i、zdaєtsya、 vrahovuvala特定のosib、pozを渡すためのschoに関心があります。
同時に、新技術の洪水が失望につながる可能性があるかどうか、状況が調査されます。 たとえば、他のデータ検索( スパースデータ)、重要なrozumіnnyaアクションを与えるもの、є豊富にtsіnіshimi、nizh 素晴らしい賛辞(ビッグデータ)、これは燃焼を説明しますが、多くの場合、元の情報ではありません。
記事のメタデータ-ビッグデータの新しい可能性を明確にして考え、分析プラットフォームとして説明する 統計学 StatSoftは、効率的なビッグデータでプロセスを最適化し、目標を達成するのに役立ちます。
ビッグデータの大きさはどれくらいですか?
明らかに、食物連鎖の正解は聞こえるかもしれません-「横になる...」
現在の議論では、ビッグデータの理解はテラバイトシステムの特定のobsyaguとして説明されています。
実際には(ギガバイトまたはテラバイトの処理方法)、このようなデータは、「従来の」データベースと標準の所有物(データベースサーバー)を利用して、簡単に保存および保存できます。
ソフトウェアのセキュリティ 統計学データへのアルゴリズムアクセス(読み取り)、リワーク、および予測(およびスコアリング)モデルのためのvikoristovリッチフローテクノロジー。データ選択を簡単に分析でき、特別なツールを必要としません。
StatSoftのインラインプロジェクトのいくつかには、約9〜1200万行があります。 それらに1000個のパラメーター(変更)を掛けて、リスクのある予測モデルを刺激するためにデータ収集から選択および整理してみましょう。 このようなファイルのボリュームは約100ギガバイトです。 これは明らかに、データの小さなコレクションではありませんが、標準のデータベーステクノロジの可能性を上回らないようにしましょう。
生産ライン 統計学バッチ分析および刺激スコアリングモデル用( STATISTICA Enterprise)、リアルタイムモードで動作するソリューション( 統計ライブスコア)、およびモデルを作成および管理するための分析ツール( STATISTICAデータマイナー)マルチコアプロセッサを搭載した小さなサーバーで簡単に拡張できます。
実際には、それはロボットモデルと分析モデルの十分な柔軟性があることを意味します(たとえば、低い信用リスク、財政の安定性、高等教育機関などの予測) 統計学.
素晴らしいデータの出会いからビッグデータへ
原則として、ビッグデータの議論は、データのいくつかのコレクション(およびそのようなコレクションに基づいて実行される分析)に焦点を当てています。
Zakrema、deyakіdanicheskahは、最大1000テラバイト、次に最大ペタバイト(1000テラバイト= 1ペタバイト)まで成長する可能性があります。
ペタバイトを超えて、データの蓄積はエクサバイトに変換することができます。たとえば、2010年の全世界の一般的なセクターでは、推定で、合計2エクサバイトの新しい情報が蓄積されました(Manyika et al。、2011)。
Іsnuyutgaluzі、dedanіzbirayutsyaそしてより集中的に蓄積します。
たとえば、発電所などの化学分野では、皮膚の変動の数万のパラメータに対して、または皮膚の秒数を取得するために、中断のないデータフローが生成されることがあります。
さらに、今年の残りの期間、公益事業者が同時にエネルギーを節約できる、いわゆる「スマートグリッド」技術が推進されています。
運命によってデータが保存される予定のこのようなプログラムの場合、蓄積されたデータは非常にビッグデータとして分類されます。
商業部門と州部門の真ん中でビッグデータの追加が増えており、コレクションからのデータは数百テラバイトまたはペタバイトになる可能性があります。
最新のテクノロジーにより、さまざまな方法で人々とその行動を「レビュー」することが可能になります。 たとえば、インターネットに精通している場合は、インターネットストアや、ウォルマート(Wikipediaからリンクされているウォルマートデータの収集は2ペタバイト未満と推定されます)などの大規模なネットワークで購入したいと考えています。インクルージョンで移動します 携帯電話-私たちは、新しい情報の蓄積につながるために、私たちの活動の痕跡を使い果たしています。
簡単な電話からウェブサイトを通じた情報の取得まで、さまざまなコミュニケーション方法 社会的措置、Facebook(Wikipediaのデータに従って、情報交換は300億ユニットになると予想されます)、またはYouTube(Youtubeは24年間のビデオスキンコンテンツ、すばらしいWikipedia)などのサイトでのビデオの交換など。新しいデータの数。
同様の方法で、現代の医療技術は、医療支援(画像、ビデオ、リアルタイム監視)に価値のあるデータの大きな可能性を生み出します。
Otzhe、obsyagivデータの分類は次のようになります。
大規模なデータセット:1000メガバイト(1ギガバイト)から数百ギガバイト
大規模なデータセット:1000ギガバイト(1テラバイト)から1テラバイト
ビッグデータ:数テラバイトから数百テラバイト
非常に大きなデータ:1000〜10000テラバイト= 1〜10ペタバイト
ビッグデータ責任者
ビッグデータに関連する3種類のタスクを確立します。
1.保存と管理
数百テラバイトおよびペタバイトからデータを収集することは、従来のリレーショナルデータベースの助けを借りてそれらを簡単に保存および保存することを可能にしません。
2.非構造化情報
ほとんどのビッグデータデータは構造化されていません。 トブト。 テキスト、ビデオ、画像を整理するにはどうすればよいですか?
3.ビッグデータ分析
非構造化情報を分析する方法は? ビッグデータに基づいて、単純な音をまとめるために、どのようにそれらは予測モデルを破壊するのを助けることができるでしょうか?
ビッグデータの保存と保護
ビッグデータはさまざまなファイルシステムに保存および整理されます。
ザガロム、情報は数台(1000台)のハードディスク、標準的なコンピューターに保存されています。
これは「マップ」(マップ)の名前です。これは、de(どのコンピューターおよび/またはディスク上で)情報の特定の部分が取得されるためです。
実行可能性と表面性の安全性のために、情報の皮膚部分を数回保存する必要があります。たとえば、trichiです。
したがって、たとえば、優れた小売チェーン店から個別のトランザクションを選択することは許容されます。 スキントランザクションに関する詳細情報は、さまざまなサーバーとハードディスクに保存され、「マップ」(マップ)は、vіdpovіdnuの喜びについて同じzvіdomostiと同じです。
そのvodkritihの標準的な所持の助けのために プログラムへの貢献 keruvannyatsієyurozpodіlenoyファイルシステムの場合(たとえば、 Hadoop)、ペタバイト規模で最高のデータコレクションを実装するのは非常に簡単です。
非構造化情報
ファイルシステムの配布で収集される情報のほとんどは、テキスト、画像、写真、ビデオなどの非構造化データで構成されています。
Tsemaєsvoїperevagithatnedolіki。
利点は、大きな賛辞を保存できる可能性があるため、データの一部がさらなる分析に関連しているため、それらを気にせずに「すべてのデータ」を保存できるという事実にあり、その決定が行われます。
そのような学習経験のある人は十分ではありません 茶色の情報離れて、賛辞のこれらの素晴らしい配列の処理が必要です。
これらの操作を単純にしたい場合(たとえば、あまりにも早く野郎)、より多くの折りたたみアルゴリズムを使用できるため、分散ファイルシステムでの効率的な作業のために特別に開発できます。
あるトップマネージャーはすぐにStatSoftに電話をかけ、「ITでキャリアを勝ち取り、お金を節約していましたが、それについて考えずに、メインの作業負荷を減らすためにもっとお金を稼ぐ方法を教えてくれました。
その後、その時間に、データは等比数列で到達できるため、情報と情報に基づいて活動を奪う能力により、交換は漸近的に到達可能になります。
モデルのプロンプト、更新、および決定の採用プロセスの自動化の方法と手順が、データ収集システムの順序によって拡張され、そのようなシステムが正しく、ビジネスで実行可能であることを確認することが重要です。
ビッグデータ分析
これは、非構造化ビッグデータデータの分析に関連する本当に大きな問題です。コストからそれらを分析する方法です。 プロ 与えられた食べ物データの保存やビッグデータ管理テクノロジーについては、あまり書かれていません。
Є低電力、yakіは見にスライドしました。
MapReduce
数百テラバイトまたはペタバイトのデータを分析する場合、分析のために他の場所にデータを取り込むことは不可能です(たとえば、 STATISTICA Enterprise Analysis Server).
チャネルによってokremiyaサーバーまたはサーバー(並列処理用)にデータを転送するプロセスは、時間がかかりすぎ、トラフィックが多すぎます。
解剖学者の分析計算は、データが収集される月に物理的に近い場合があります。
アルゴリズムマップ-rozdіlenih微積分のєモデルを減らします。 ヨガの原則は攻撃的に機能します:作業ノード(個々のノード)に入力データを配布する必要があります ファイルシステム前処理(map-croc)と、処理データの前にある折り畳み(組み合わせ)(reduce-croc)。
このように、たとえば、合計を計算するために、アルゴリズムは分散ファイルシステムのスキンノードで中間合計を同時に計算し、次に中間値の合計を計算します。
インターネット上には、それらに関する大量の情報があります。これにより、予測分析を含む、追加のmap-reduceモデルのコストを克服できます。
ただの統計、ビジネスインテリジェンス(BI)
単純なBI番号を折りたたむために、合計、平均、比率などを計算できる明確なコードを持つ匿名の製品があります。 map-reduceのヘルプについて。
このようにして、答えを編集するための正確ながらくたやその他の単純な統計を取得することがさらに簡単になります。
予測モデリング、統計の喪失
一見すると、ファイルシステムの配布における予測モデルは折りたたまれていることがわかりますが、プロテーゼはそうではありません。 データ分析の前の段階を見てみましょう。
データの準備。 最近、StatSoftは、発電所ロボットのプロセスの称賛に値するデモンストレーションを説明する優れたデータセットでさえ参加するための一連の優れた成功したプロジェクトを実施しました。 実施された分析のメタは、発電所の運用効率の向上とwikiの数の減少を示唆しました(Electric Power Research Institute、2009年)。
データの収集がさらに多くなる可能性があるものに関係なく、それらに隠されている情報は大幅に少なくなる可能性があることが重要です。
たとえば、その時間には、実際には、smomitiまたはschokhvilinsが蓄積されており、多くのパラメーター(ガスと炉の温度、流量、シャッターの位置など)が1時間の大きな間隔で安定しています。 それ以外の場合は、与えられた場合、それらは皮膚の2番目に記録され、同じ情報を繰り返すことが重要です。
このように、動的変化に関する必要な情報を削除するために、データのモデリングと最適化を考慮して、データの「合理的な」集約を実行する必要があります。これにより、ロボット発電所の効率が向上します。ウィキの数。
テキストの分類と以前のデータ処理。 すばらしいデータのセットを、はるかに基本的でない情報に置き換える方法をもう一度説明します。
たとえば、StatSoftは、テキストマイニング(テキストマイニング)やツイートに関連するプロジェクトに参加しました。これは、航空会社とそのサービスに満足している乗客の数を示しています。
その日に起こったことに関係なく、多くのポジティブなツイート、ムード、表現は、単純なものによって誇張されていました。 詳細情報-「不潔な報告」に関する1つの提案に関するスカルガと短い情報。 さらに、これらの気分の数と「強さ」は、通常、特定の食事(手荷物、ゴミ、食べ物、飛行機など)で安定しています。
このようにして、実際のツイートを迅速な(評価)ムードに短縮する、vikoristovuyuchiテキストマイニングメソッド(たとえば、 STATISTICAテキストマイナー)、生成するデータを大幅に減らし、データの基本的な構造化(チケットの実際の販売、または頻繁に飛行する乗客に関する情報)を使用して簡単に設定できます。 分析により、クライアントをグループに分割し、特徴的なスカーグを忠実に再現することができます。
このようなデータの集約(クイック設定など)を別のファイルシステムで実行するために匿名ツールを使用します。これにより、分析プロセス用のデータを簡単に作成できます。
Pobudovaモデル
多くの場合、タスクは、ファイルシステムディストリビューションに保存されている正確なデータモデルにプロンプトが表示されるようにすることです。
さまざまなファイルシステムでのデータの大規模な並列処理に適した、さまざまなデータマイニング/予測分析アルゴリズムのmap-reduceの実装を確立します 統計学 statsoft)。
しかし、すでに多くのデータを作成している人々を通して、なぜバッグモデルが実際により正確であると確信しているのですか?
本当に、さまざまなファイルシステムのデータの小さなセグメントのためのより良い、より良いモデル。
最近のForresterのツイートにあるように、「2プラス2は良い3.9です。いいですね」(Hopkins&Evelson、2011年)。
数学的精度が、たとえば、正しく基づいた10個の予測子を含む線形回帰モデルという事実に関連しているという統計 imovіrnіsnoїvybіrki 3 10万人の警備員は、1億人の警備員に触発されて、モデルのように非常に正確になります。
(文字通り - 素晴らしいデータ)? オックスフォードの語彙に戻ります。
ダニ-値、記号または記号、コンピューターの動作方法、およびフォームからの保存と送信方法 電気信号、磁気的、光学的、または機械的摩耗を記録します。
期間 ビッグデータ vikoristovuetsyaは、データを収集するために1時間にわたって指数関数的に成長している偉大なものの説明を提供します。 このような量のデータを生成するには、機械学習なしでは実行できません。
ビッグデータのメリット:
- さまざまなソースからのデータの選択。
- リアルタイム分析によるPolypshennyaのビジネスプロセス。
- 敬意を表する。
- 洞察。 ビッグデータはより浸透しています 受け取った情報追加の構造化とnapіvstrukturirovaniyaデータ。
- 優れたデータは、リスクを変え、合理的な決定を下すのに役立ちます
ビッグデータを適用する
ニューヨーク証券取引所今日生成します 1テラバイト過去のセッションのオークションに関するデータ。
ソーシャルメディア:統計は、Facebookデータベースで現在利用されているものを示しています 500テラバイト新しいデータは、主にサーバーやソーシャルメディアでの写真やビデオのキャプチャ、通知の交換、投稿の下でのコメントなどを通じて生成されます。
ジェットエンジン生む 10テラバイト与えられた皮膚30hvilinpіd時間polotu。 今日の破片zdіysnyuyuyutsya何千ものパッセージ、obsyagこれらはペタバイトに達します。
ビッグデータの分類
偉大な賛辞の形:
- 構造化
- 非構造化
- Napіvstructured
構造化された形式
保存はできるが、固定形式の形式でアクセスおよび一般化できるデータは、構造化と呼ばれます。 コンピューターサイエンスは、このタイプのデータ(deformatvіdomyzazdalegіd)を使用して、ロボット工学の高度なテクノロジーで3時間にわたって大きな成功を収め、貪欲を排除することを学びました。 同じ年に、契約が拡大して拡大することにより、数ゼタバイトの範囲になってしまうかのように問題が発生します。
1ゼタバイトは10億テラバイトに相当します
数字の数に疑問を抱いて、ビッグデータ用語の信憑性とそのようなデータの処理と保存に伴う困難について混乱することは問題ではありません。
リレーショナルデータベースに保存されているデータ-構造化されており、たとえば会社の参照テーブルのように見える場合があります
非構造化フォーム
非構造化構造のデータは非構造化として分類されます。 大きな拡張に加えて、そのようなフォームは、茶色の情報を処理および精緻化するためのいくつかの折り畳みによって特徴付けられます。 非構造化データの典型的な例は、単純なテキストファイル、写真、およびビデオの組み合わせとして使用できる異種のdzhereloです。 今日の組織は、シリアの大きな義務や非構造化データにアクセスできるかもしれませんが、彼らから恨みを取り除く方法を知りません。

Napіvstrukturovanaフォーム
上記の犯罪を復讐するためのTsyaカテゴリは、そのnapіvstrukturirovanіdanіmаyutdeak形式ですが、実際には、リレーショナルデータベースの追加のテーブルには割り当てられていません。 アプリケーションカテゴリ-XMLファイルで表示される個人データ。
ビッグデータの特徴
時間ごとのビッグデータの増加:

青い色は、リレーショナルデータベースから収集された構造化データ(エンタープライズデータ)を表します。 他の色は、さまざまなソース(IPテレフォニー、デバイスとセンサー、ソーシャルメディア、Webアドオン)からの非構造化データです。
ガートナーへのVіdpovіdno、大きなdаіnіїrazrіznyayutsyaobyagі、shvidkіstyu世代、raznomanіstyuіmnіvіstyu。 レポートのパラメータを見てみましょう。
- `emについて。 ビッグデータという用語自体は、世界の大幅な拡大に関連しています。 データのローズマリーは、回復可能な価値がどれだけあるかを示す最も重要な指標です。 今日、600万人がデジタルメディアを獲得しています。これまでの見積もりによると、250億バイトのデータが生成されます。 Tomobsyag-特性を最初に確認します。
- Raznomanіtnіst-攻撃的な側面。 構造化と非構造化の両方が可能なデータの異種性に依存しています。 ついさっき スプレッドシートこれらのデータベースは、サプリメントの大部分に見られる唯一の情報源でした。 フォームの今日のデータ 電子シート、写真、ビデオ、 PDFファイル、オーディオは分析アドオンでも表示できます。 非構造化データのこのような多様性は、節約、視覚化、分析の問題につながります。27%の企業は、外部データを使用することを確信していません。
- 生成速度。 たくさんのお金を貯めた人たちが貯まり、自分の力に満足し、ポテンシャルを発揮しています。 Swiftnessは、dzherelからの情報の流入のスウェーデン性を決定します-ビジネスプロセス、アドオンのログ、ソーシャルネットワークとメディアのサイト、センサー、 モバイル別棟。 これらの偉大さの流れは、その時間に途切れることはありません。
- ミンリビストその行政の仕事を複雑にする日と時間のデータの小ささについて説明します。 したがって、たとえば、データの大部分はその性質によって構造化されていません。
ビッグデータ分析:優れたデータの恨みはなぜですか
商品とサービスの通過:FacebookやTwitterなどの検索エンジンシステムやサイトからのデータへのアクセスにより、企業はマーケティング戦略を微調整することができます。
購入者向けのサービスサポート:従来のシステム zvorotny zv'azku購入すると、それらは新しいものに置き換えられます。そのようなビッグデータでは、購入の読み取りと評価のために自然な映画の処理が停止されます。
Rozrahunok risiku、新製品のchiサービスのリリースに関連しています。
運用効率:優れたデータ構造。必要な情報をより簡単に取得し、正確な結果をすばやく確認できます。 ビッグデータテクノロジーとコレクションのこのような組み合わせは、組織が情報を使用して作業を最適化するのに役立ちますが、これはめったに成功しません。
優れたデータとは、優れたデータセットから情報を収集、整理、処理するために必要な、従来とは異なる戦略やテクノロジーの総称です。 ダニム付きロボットの問題、何を移動するかが欲しい 微積分そうでなければ、世界の他の地域で、新しいものではなく1台のコンピューターを選択する可能性があり、そのタイプの価値の規模は大幅に拡大しています。
これらの記事では、大きな賛辞を続けながら、閉じることができる主要な概念を理解します。 それで、ここに、与えられた時間にこのギャラリーでのvikoristovuyutsyaのようなプロセスと技術の行為があります。
そのような素晴らしい賛辞は何ですか?
プロジェクト、ベンダー、スペシャリスト、実務家、およびビジネスファシリテーターがすべて異なる方法でそれを獲得できるように、「大きな賛辞」の目的を正確に定式化することが重要です。 uvaziのMayuchitse、大きな賛辞は次のように数えることができます:
- 素晴らしいデータセット。
- 優れたデータセットの作成のために選択された列挙戦略とテクノロジーのカテゴリ。
このコンテキストでは、「優れたデータのコレクション」とは、データのコレクションを意味します。これは、追加の従来のツールまたは1台のコンピューターを拡張または処理できるようにするには大きすぎます。 Tseは、データのすばらしいコレクションの壮大な規模が絶えず変化しており、場所によって大きく異なる可能性があることを意味します。
素晴らしい賛辞システム
偉大な賛辞を扱うための主な貢献は、他の賛辞のセットの前と同じです。 プロセスのスキンステージに関連するタンパク質の質量スケール、処理速度、およびデータの特性は、コスト処理の深刻な新しい問題を提示します。 偉大な賛辞のシステムの偉大さの方法は、勝利した並外れた方法では不可能だったであろう、豊かな賛辞の大きな義務との関係を理解することです。
2001年、Doug LaneyとGartnerは、他のタイプのデータを処理するプロセスに関連して、優れたデータの処理に挑戦するいくつかの特性を説明するために「ThreeVGreatData」を導入しました。
- ボリューム(コミットされたデータ)。
- 速度(Shvidk_stの蓄積とデータ収集)。
- 多様性(さまざまなデータ型)。
Obsyagh danih
処理されている情報のVinyatkovyスケールは、大きな賛辞のシステムを設計するのに役立ちます。 これらのデータセットは、従来のセットよりも桁違いに大きく、低くなる可能性があり、処理と保存のスキン段階でより多くの注意が必要になります。
シャードは単一のコンピューターの容量を上回る可能性があり、コンピューターのグループからのリソースの共有、配布、および調整の問題が原因であることがよくあります。 タスクをより小さな部分に構築するクラスター管理とアルゴリズムは、私たちの目にますます重要になっています。
Shvidkіstが蓄積され、obrobki
実際のところ、別の特徴は、他のデータシステムからの優れたデータに似ており、情報がシステムによって移動される価格です。 多くの場合、データは数dzherelからシステムで検出され、実際の1時間のように処理される場合があります。すすり泣き、システムの合理化を更新します。
Tseyはmittevuzvorotnomuzv'azkuzmusivリッチfahіvtsіv-praktіvvіdmovіtіsіvіdパケット指向のpodhodaіvіddativіddativіddativіddativіddatіvіddatiprоvaіvіtоkоіkііsisіに重点を置いています 新しい情報の流入に追いつき、最も関連性が高い場合は早い段階で貴重なデータを取得するために、データは徐々に追加、処理、分析されます。 データパイプラインの障害から保護するために、アクセスしやすいコンポーネントを備えたシステムが必要です。
収集されたさまざまな種類のデータ
グレートデンには顔の見えない独特の問題があり、それは幅広い栽培されたdzherelとその良質に関係しています。
データは、アドオンログやサーバーなどの内部システム、ソーシャルメディアチャネル、その他の外部APIインターフェース、センサーから取得できます。 物理的な別棟とsіnshihdzherel。 優れたデータのシステムの方法は、単一のシステムで情報を組み合わせる方法で、潜在的に茶色のデータを独立して処理することです。
鼻のフォーマットとタイプを大幅に改善できます。 メディアファイル(画像、ビデオ、オーディオ)は、テキストファイル、構造化ログなどと組み合わされます。それらを保存します 休日のキャンプ。 理想的には、作業時にメモリに記憶されるように、手直しするか、壊れていないデータを変更します。
その他の特徴
何年もの間、fahіvtsіと組織は「3つのV」の拡張を広めてきましたが、これらの革新は、偉大なダニッチの特徴ではなく、問題を説明するように聞こえました。
- 正確性(データの正確性):データの多様性とデータの折り畳み性は、データの品質(つまり、取得した分析の品質)を評価する際に問題を引き起こす可能性があります。
- 変動性(データの変更):データを変更して、品質を大幅に変更します。 低品質のデータを識別、処理、またはフィルタリングするには、データの品質を向上させる可能性のある追加のリソースが必要になる場合があります。
- 価値(データの価値):大きな賛辞の最後のタスクは価値です。 一部のシステムとプロセスはさらに協調的であり、データの変動と実際の値の変動を複雑にします。
大きな賛辞のライフサイクル
では、どのようにしてすばらしい賛辞が実際に集められるのでしょうか。 Іsnuєkіlkarіznіhіdhodіvіnopіlіzatsії、戦略とソフトウェアєspilnіrisiで。
- システムへのデータの入力
- shovishchiでデータを保存する
- データの計算と分析
- 結果の視覚化
まず、作業プロセスのいくつかのカテゴリについて報告し、クラスタリング、重要な戦略、および大きな賛辞の処理のためのバガトマの獲得について話しましょう。 ナンバリングクラスターを改善することは、ライフサイクルの勝利した皮膚段階のための技術の基礎です。
クラスターカウント
優れたデータの素晴らしさのために、コンピューターはデータの処理には適していません。 クラスターがより適している人、節約に対処し、大きな賛辞の必要性を数えることができる人のために。
優れたデータをクラスタリングするためのソフトウェアは、小型マシンの豊富なリソースを徐々に増やし、多くの利点を確保するのに役立ちます。
- リソースの統合:大規模なデータセットを処理するには、大量のプロセッサリソースとメモリ、およびデータを収集するための多くの利用可能なスペースが必要です。
- 高可用性:クラスターはさまざまなレベルの可用性と可用性を保証できるため、ハードウェアまたはソフトウェアの障害がデータへのアクセスとデータ処理に干渉することはありません。 これは、リアルタイム分析にとって特に重要です。
- スケーリング:クラスタリングは、水平スケーリング(クラスターへの新しいマシンの追加)をサポートします。
クラスターで作業するには、クラスターのメンバーシップを管理し、リソースの分散を調整し、他のノードとの作業を計画するためのツールが必要です。 クラスターのメンバーシップとリソースの分散は、Hadoop YARN(Yet Another Resource Negotiator)やApacheMesosなどの追加プログラムを通じて取得できます。
選択された列挙クラスターは、多くの場合、ベースとして機能しますが、インターモーダル方式でデータを処理するためのものです。 ソフトウェアのセキュリティ。 カウントクラスター内にあるマシンは、分散型貯蓄システムの管理にも関連しています。
Otrimannya danikh
データの受け入れ-非共有データをシステムに追加するプロセス。 この操作の折り畳み性は、データのジェレルの密度の形式にある理由が豊富であり、さらに、データの量を処理に使用する必要があります。
特別なツールを使用して、システムに優れたデータを追加できます。 Apache Sqoopのようなこのようなテクノロジーは、リレーショナルデータベースから重要なデータを取得し、それを優れたデータシステムに追加できます。 また、ApacheFlumeとApacheChukwaをハックすることもできます。これらのプロジェクトは、アドオンログとサーバーの集約とインポートで認識されています。 Apache Kafkaのようなリコールブローカーは、さまざまなデータジェネレーターと優れたデータシステム間のインターフェイスとして勝つことができます。 Gobblinのようなフレームワークは、パイプラインのようなすべてのツールの実行を組み合わせて最適化できます。
データを受信してから1時間以内に、分析、並べ替え、マーキングを実行する必要があります。 このプロセスは、ETL(抽出、変換、読み込み)と呼ばれることもあります。これは、変換、変換、およびエンタングルメントを意味します。 この用語を聞くと、それはデータを保存する古いプロセスにまで及びますが、時にはそれはzastosovuetsyaと素晴らしいデータのシステムにまで及びます。 典型的な操作の中で-フォーマット、分類、マーキングのための入力データの変更、視覚認識のためのデータのフィルタリングと再チェック。
理想的には、最小限のフォーマットを実行することを望んでいました。
データ保護
トリビュートを受け取ったら、コレクティブを管理するコンポーネントに進みます。
ファイルシステムを分割して、非共有データの保存を要求します。 Apache HadoopのようなHDFSのようなこのようなソリューションでは、ノードのクラスターに大量のデータを書き込むことができます。 このシステムは、計算リソースのデータへのアクセスを提供し、メモリからの操作およびプロセスコンポーネントの障害のためにデータをクラスターRAMに取り込むことができます。 HDFSは、CephやGlusterFSなどの他のファイルシステムに置き換えることができます。
より構造化されたアクセスのために、データを他のサブシステムにインポートすることもできます。 個別のデータベース、特にNoSQLデータベースはロールに最適であり、シャードは異種データを処理できます。 Іsnuє非人称 他の種類 rozpodіlenihデータベース、データを整理して送信する方法に応じてデポジットを選択します。
データの計算と分析
このデータが利用可能になるとすぐに、システムはそれを処理できるようになる可能性があります。 おそらく、システムのnaivіlnіshoyの部分を数えると、ここでのvimogとpіdkhodiの断片は、情報の種類に応じて休眠的になります。 多くの場合、データは繰り返し処理されます。1つのツールを使用する場合、またはさまざまなタイプのデータを処理するための多数のツールを使用する場合です。
バッチ処理は、大規模なデータセットを処理する方法の1つです。 このプロセスには、データを小さなパーツに分割し、okremіyマシンでの革のパーツの処理を計画し、中間結果に基づいてデータを再配置し、残りの結果の選択を計算することが含まれます。 ApacheHadoopでのTsyu戦略vikoristovuMapReduce。 大量の計算が必要な大規模なデータセットを処理する場合、バッチ処理は最もコストがかかります。
その他の作業ニーズには、リアルタイムモードでの処理が必要になります。 この情報が原因である場合、それは怠慢に処理され、準備されるべきであり、システムは新しい情報を必要としている世界に対応することができます。 リアルタイムで処理を実装する方法の1つは、4つの要素で構成される中断のないデータフローの処理です。 もう1つ Zagalnaの特徴リアルタイムプロセッサで-クラスタメモリ内のデータの計算。これにより、ディスクへの必要な書き込みを削除できます。
Apache Storm、Apache Flink、Apache Spark 違う方法実時間での処理の実装。 Cіgnuchkitekhnologiiїは、nіbratinіbratinіdkhіdpіdkhіdkoremoїkoremoїの問題を許可します。 データの小さな断片は変化するか、システムにすばやく到達するため、リアルタイムモードで分析するのが最善です。
すべてのプログラムとフレームワーク。 優れたデータシステムからのデータを計算および分析する方法は他にもたくさんあります。 これらのツールは多くの場合、高度なフレームワークに接続されており、以下のピアとインターフェイスするための追加のインターフェイスを提供します。 たとえば、Apache HiveはHadoopのデータストレージインターフェイスを提供し、Apache Pigはデータ収集インターフェイスを提供し、SQLデータモジュールはApache Drill、Apache Impala、Apache Spark SQL、およびPrestoによって提供されます。 Apache SystemML、Apache Mahout、およびApache SparkのようなMLlibは、機械学習で立ち往生しています。 データエコシステムで広くサポートされている直接分析プログラミングには、RとPythonを使用します。
結果の視覚化
多くの場合、データの傾向や変化の認識は、値の省略よりも重要な場合があります。 データの視覚化-最大の1つ ルートメソッド傾向を明らかにし、多数のデータポイントを整理します。
プログラムサーバーのメトリックを視覚化するためのリアルタイムクイズの処理。 データは頻繁に変更され、パフォーマンスの大きな変動は、組織のシステムの陣営に重大な影響を及ぼしていることを示しています。 Prometheusのようなプロジェクトは、データストリームと時系列を処理し、情報を視覚化するためにひねることができます。
データを視覚化する一般的な方法の1つは、以前はELKスタックと呼ばれていたElasticスタックです。 Logstashはデータ収集に勝利し、Elasticsearchはデータのインデックス作成に使用され、Kibanaは視覚化に使用されます。 Elasticスタックは、優れたダニムと連携し、結果を視覚化し、生のメトリックを計算または操作できます。 同様のスタックは、Apache Solrをマージして、視覚化のためにBananaという名前でKibanaのフォークにインデックスを付けることで取り除くことができます。 このようなスタックはSilkと呼ばれます。
データギャラリーでのインタラクティブな作業のための最新の視覚化テクノロジーはドキュメントです。 このようなプロジェクトでは、データをインタラクティブに確認して、次のような便利な形式で視覚化できます。 眠っているビクトリアその賛辞。 このインターフェースの一般的な例は、JupyterNotebookとApacheZeppelinです。
偉大な賛辞の用語集
- 優れたデータ-正しく要約できる一連のデータを指定するための広義の用語 素晴らしいコンピューター彼らのobsyag、shvidkіstnahodzhennyaおよびraznomanіtnіstを介したツール。 この用語は、そのようなデニムを扱うための技術と戦略にとって、zastosovuetsyaのように聞こえます。
- バッチ処理は、優れたセットのデータ処理を含む包括的な戦略です。 確かに、この方法は非終端記号データを操作するのに理想的です。
- クラスター化されたカウントは、多数のマシンのリソースをプールし、タスクを発生させるためのそれらの膨大な機能を管理する方法です。 必要に応じて、クラスターによるrіvenkeruvannya。これにより、okremyノード間の接続を形成できます。
- デーンの湖は、孤児になるために選ばれた人々の素晴らしいコレクションです。 この用語は、構造化されていない、多くの場合小さな大きな賛辞を表すためによく使用されます。
- データセットのタイプは、優れたデータセットでテンプレートを探すさまざまなプラクティスの広義の用語です。 テストの目的は、より多くの洞察とコミュニケーションのために大量のデータを整理することです。
- データウェアハウスは、分析とzvіtnostіのための大規模でよく整理されたコレクションです。 湖の景色を眺めると、これらのコレクションは、他の船と統合された、適切にフォーマットされ、整理されたデータと積み重ねられています。 賛辞のコレクションは、多くの場合、すばらしい賛辞と見なされますが、多くの場合、それらはコンポーネントです。 並外れたシステムデータ収集
- ETL(抽出、変換、読み込み) これは、勝つために未完成のデータを終了して準備するプロセスです。 Vіnpo'yazaniyіzdanihdaniですが、このプロセスの特徴は、偉大なダニのシステムのパイプラインにも示されています。
- Hadoopは、偉人のためのオープンソースコードを備えた単なるApacheプロジェクトです。 これは、HDFSと呼ばれる別のファイルシステムと、YARNと呼ばれるクラスタープランナーおよびリソースから構築されます。 可能性 バッチ処理 MapReduce計算メカニズムに依存します。 現在のHadoopゴルーチンのMapReduceと同時に、他の列挙および分析システムを実行できます。
- メモリ内の計算は、作業データセットの移動をクラスタのメモリに転送する戦略です。 Promіzhnіの請求はディスクに記録されません、悪臭の悪臭はメモリから保存されます。 Tseは、I / Oに関連するシステムと同等の、速度の大きな利点をシステムにもたらします。
- 機械学習は、システムを設計するためのフォローアップと実践であり、システムに送信されるデータに基づいて学習、改善、および改善することができます。 uvazіrealіzatsіyu予測および統計アルゴリズムに関する健全なpіdtsimmаyut。
- Map Reduce(HadoopのようにMapReduceと混同しないでください)は、列挙型クラスターを計画するためのアルゴリズムです。 このプロセスには、ノード間のタスクの細分化、中間結果の削除、シャッフル、および皮膚のリクルートのための同じ値の前進が含まれます。
- NoSQLは、データベースを意味する広義の用語であり、従来のリレーショナルモデルによって分類されます。 NoSQLのデータベースは、彼らのgnuchkostiとrazpodіlenіyarkhitekturіの頭脳の偉大なダンに非常に適しています。
- ストリーミング処理は、システムから移動されたїїのデータのいくつかの要素を計算する方法です。 これにより、リアルタイムモードでデータを分析でき、さまざまな高速メトリックを使用した用語演算の処理に適しています。
私の時代、私はドイツのグレフ(オシャドバンクの責任者)から「ビッグデータ」という言葉を感じました。 Movlyavは、同時にprovadzhennyamに対して積極的にpratsyuyutを悪臭を放ち、スキンクライアントとの作業に1時間を費やすのに役立ちます。
突然、私はクライアントのオンラインストアでこれらの理解に出会い、そこで働き、品揃えを数千から数万の商品ポジションに増やしました。
質問があれば、Yandexにはビッグデータアナリストが必要です。 Todi I vyrivishiv morerazіbratisyaこのトピックで同時に、rozpovіstのような記事を書き、TOPマネージャーやインターネットスペースのrozburhuєの心のようなそのような用語を学びます。
それは何ですか
あなたの記事のように聞こえますが、これがどのような用語であるかについての説明から始めましょう。 Tsyastatyaは非難にはなりません。
しかし、私たちが前にいるヴィクリカノは、私が合理的であることをバザニーに示すのではなく、トピックが正しい方法で折りたたまれ、説明を要求していることを彼らに示しています。
たとえば、ウィキペディアからそのようなビッグデータを読むことができますが、何も理解できませんが、この記事に目を向けると、そのzastosovnostiのビジネスへの指定について知ることができます。 Otzhe、説明から始めて、ビジネス用のアプリケーションに行きましょう。
ビッグデータはビッグデータです。 変だよね? 本当に、英語からそれは「大きな賛辞」として翻訳されます。 ティーポットのエールの指定。
ビッグデータテクノロジー–cepіdkhіd/新しい情報のコレクションからの多数のデータを処理する方法。これは最も重要な方法で処理するために重要です。
データは、一般化(構造化)と分割(非構造化)の両方が可能です。
ビニックという用語自体は最近のものです。 2008年、科学雑誌で、この記事は等比数列で成長するにつれて、大量の情報を扱う作業に必要であると報告されました。
たとえば、インターネット上の情報を注意深く保存する必要がある場合は、それ自体で処理され、40%増加します。 もう一度:インターネット上の新しい情報を公開するために+ 40%。
文書がどの程度準備されているか、およびそれらを処理する方法が理解されている(に転送する 電子ビューア、他の「キャリー」および他の義務で提示されるように、情報を処理する1つのフォルダー(番号付き)に入れます。
- インターネット文書;
- ブログとソーシャルメディア;
- オーディオ/ビデオdzherel;
- Vimiryuvalniの別棟。
ビッグデータに情報やデータを追加できる特性。 したがって、すべてのデータが分析の形容詞になるわけではありません。 これらの特性は、ビッグデートの重要な理解を持っています。 口ひげは3Vで悪臭を放ちます。
- `emについて(ビデオ英語ボリューム)。 データは、分析を行う「ドキュメント」の物理的な義務のサイズに縮小されます。
- Shvidkist(English Velocityから)。 ダニイルは独自の発展を遂げていませんが、着実に成長しています。そのため、結果を改善するためにスウェーデンのドレッシングを用意する必要があります。
- Raznomanіtnіst(Vіd英語の多様性)。 データは1つの形式にすることができます。 Tobtoは、分割、構造化、または多くの場合構造化できます。
ただし、定期的にVVVにVの4分の1(信憑性-データの信頼性/信頼性)を追加し、Vの5分の1(場合によっては、実行可能性-実行可能性-寿命、その他-値-値)を追加します。
ここで私は7Vを見つけようとしています。これは、重要な日付に値するデータを特徴付ける方法です。 エール、私の意見では、tseіzserії(定期的にPを追加し、rozuminnyaに十分な穂軸4が必要です)。
私たちはすでに29000人を持っています。
オンにする
誰がそれを必要としているのか
論理的なフィードを投稿して、どのようにして情報を獲得できますか(数百、数千テラバイトの日付はどれくらいの大きさですか)?
Navitはそうではありません。 軸は情報です。 そのnav_schoは同じ大きな日付を思いついたのですか? マーケティングとビジネスにおけるビッグデータの停滞とは何ですか?
- プライマリデータベースは、大量の情報を保存して処理することはできません(分析についてではなく、単にその処理を保存するだけです)。
大きな日付は間違っています。 その重要な情報を大きなコミットメントでうまく収集します。 - ビデオの構造。さまざまなソース(ビデオ、画像、オーディオ、および テキストドキュメント)、単一のインテリジェントで明確な外観。
- 分析の形成と、構造化され一般化された情報に基づく正確な予測の作成。
それは複雑です。 簡単に言うと、ある種のマーケティング担当者、ある種のインテリジェンスであり、大量の情報(あなた、あなたの会社、競合他社、あなたのガルスについて)を得ることができます。そうすれば、まともな結果さえ見ることができます。
- 数字の側面からのあなたの会社とあなたのビジネスの外向きの理解;
- あなたの競争相手をVivechity。 そして、tseは、彼の法廷で、彼らの上のrahunokのためにvirvatisを前進させる。
- 認識 新情報あなたのクライアントについて。
ビッグデータテクノロジーが高度な結果をもたらすという事実は、誰もがそれを駆使しています。 彼らは売り上げを減らして金額を変えるために会社の右側でそれを台無しにしようとします。 そして具体的には、次のようになります。
- 顧客の利益をよりよく知るために、クロスセールスと追加販売を増やす。
- 人気商品とそれらが購入される理由を検索します(іnavpaki);
- 製品へのサービスの改善。
- Polypshennyaの同等のサービス。
- 忠誠心と顧客志向を促進する。
- shakhraystvaの進歩(銀行セクターにより関連性があります);
- zaivikhvitrateを減らします。
すべてのdzherelakhを対象とした最も広いお尻-明らかに、Appleの会社は、そのcoristuvachiv(電話、年鑑、コンピューター)に関するデータを収集します。
エコシステムの存在を通じて、企業自体がそのcoristuvachivについて知っており、利益を奪うためにvicoristaに与えました。
同じ記事、クリミアqiєїで引用符と他のものを読むことができます。
現代のお尻
別のプロジェクトについてお話します。 より正確には、人について、将来として、勝利を収めたビッグデータソリューション。
CeElonMuskとヨガ会社Tesla。 Yogoの頭の夢-車を自律させるために、カーモの後ろに座って、モスクワからウラジオストクまでの自動操縦装置を使用して...歌います。自分ですべてを行っても、車を彫る必要がないからです。
それはファンタジーでしょうか? エールわからない! 何十人もの仲間の助けを借りて車を大切にするように、グーグルをより賢く、より低くしたのはまさにそのイロンです。 Іpіshovіnhimの方法:
- 販売中の革車には、すべての情報を収集するコンピューターが搭載されています。
すべてのtseはすべてを意味します。 水、水のスタイル、道路navkolo、他の車の動きについて。 このようなデータの量は、年間20〜30GBです。 - さらなる情報は、これらのデータの処理に従事している中央コンピュータに衛星リンクを介して送信されます。
- ビッグデータデータに基づいて、それがどのように処理されるか デンマークのコンピューター、無人機のモデルがあります
それまで、グーグルがそれをうまくやることができず、彼らの車が事故に丸1時間費やすなら、ムスクはビッグデータロボットのためにそれをより良くし、テストモデルでさえさらに悪い結果を示します。
エール...すべての経済。 私たち全員が黒字について何ですか、もう1つは黒字についてですか? 大きなデートになる可能性のある多くのことは、そのペニーの給料とは関係ありません。
グーグルの統計は、結局のところ、ビッグデータに基づいており、川の豊かさを示しています。
その前に、医師が私の地域での感染症の流行の誹謗中傷について誹謗中傷しているので、この地域ではこの病気の治療のためにたくさんのポシュコフ飲料があります。
このようにして、これらの分析からのデータを正しく育成することで、予測を策定し、流行の耳を移すことができます 公的機関 taїхdії。
ロシアのZastosuvannya
しかし、ロシアは、指導者のように、prigalmovuєを追跡します。 つまり、ロシアでのビッグデータの目的そのものが明らかになったのは5年前のことです(私は大企業について話しているのです)。
また、ビッグデータを収集および分析するためのソフトウェア市場が32%増加したとしても、世界で最も急速に成長している市場の1つである市場(麻薬と喫煙は神経質になっています)に驚かないでください。
ロシアのビッグデータ市場を特徴づけるために、1つの古い瓶について考えます。 18歳までのビッグデートツェヤクセックス。 すべてがそれに関するもののようです、それはとても豊かなハラスであり、本物のものはほとんどありません、そして誰もが彼ら自身がそれらの世話をしていないことを知っているのは恥ずべきことです。 確かに、ガラはたくさんありますが、実際のガラはほとんどありません。
前の会社であるGartnerは、2015年に、ビッグデートはもはや成長傾向ではなく(控えめに言っても、ピースインテリジェンスなど)、分析と高度なテクノロジーの開発のための独立したツールのセットであると発表しました。
世界で最も活発なのは、ロシアでのビッグデータの開発、銀行/保険(私がOschadbankの責任者になったのは当然です)、電気通信、小売、非堅牢性、およびソブリンセクターです。
たとえば、経済の小さなセクターに関する新しいレポート、ビッグデータアルゴリズムを獲得する方法。
1.銀行
銀行からそれを入手してみましょう、そして彼らが私たちのことをどのように悪臭を放っているのか、 たとえば、ビッグデータに積極的に投資しているロシアのトップ5銀行を取り上げました。
- Oschadbank;
- ガスプロムバンク;
- VTB 24;
- アルファ銀行;
- ティンコフ銀行。
ロシアの指導者アルファ銀行の間で特に歓迎します。 少なくとも、銀行がそのようなタイプの公式パートナーであることを受け入れ、あなたの会社に新しいマーケティングツールを導入する必要性を理解してください。
エール、ビッグデータのプロモーションのはるか遠くにあるvikoristannyaを適用します。私は、あなたのマスターのそのvchinkaの非標準的な外観のために、瓶にあなたを見せたいと思います。
私はティンコフ銀行について話している。 私たちの主な仕事は、拡大する顧客ベースを通じてリアルタイムで優れたデータを分析するためのシステムを開発することでした。
結果:内部プロセスの時間は少なくとも10倍短縮され、他のプロセスでは100倍以上短縮されました。
まあ、それは大きな問題ではありません。 オレグ・ティンコフの非標準の曲がりくねりとねじれについて話し始めた理由を知っていますか? 私の意見では、悪臭自体が、彼がロシアの何千人ものような中堅のビジネスマンから、最も家庭的で最も家庭的なビジネスの1つに変身するのを助けたというだけです。 確認時に、ビデオの珍しい派閥に驚嘆してください:
2.手に負えない
不可侵性ですべてがより豊かに折りたたまれます。 これは同じ例であり、素晴らしいビジネスの境界にある大きな日付を理解するためにあなたに持って行きたいと思います。 終了データ:
- テキストドキュメンテーションへの大きなコミットメント。
- Vidkrit dzherela(土地の変化に関するデータを送信する民間衛星);
- インターネット上での管理されていない情報の壮大な共有。
- dzherelakhとdanikhのPostiyniの変更。
Іこれに基づいて、たとえばウラル村の下で、さまざまな土地区画を準備して評価する必要があります。 専門家はチェーンで一日を過ごします。
で ロシアのパートナーシップ Evaluated&ROSEKOは、最良の方法で、ソフトウェアの助けを借りて独自のビッグデータ分析を実行しました。価格は30以下の小さな仕事です。 日と30分を調整します。 巨大な小売り。
折りたたみツール
明らかに、大量の情報を単純なハードディスクに保存して処理することはできません。
また、データの構造や分析などのソフトウェアセキュリティでは、知的能力と作成者の開発の注意が考慮されました。 Prote、єіnstrumenti、これに基づいてすべての美しさが作成されます:
- Hadoop&MapReduce;
- NoSQLデータベース;
- データ検出クラスのツール。
正直なところ、ロボットとこれらのスピーチが物理的および数学的な機関で教えている知識である、悪臭が1つずつ使用されていることを明確に説明することはできません。
私は今何について話しているのですか、なぜ説明できないのですか? すべての映画館で、強盗がどの銀行にもやって来て、あらゆる種類のザリザキフを大量に作り、ダーツに接続していることを覚えていますか? それらの同じで大きな日付。 たとえば、軸モデルは現在、市場のリーダーの1つです。
ビッグデートツール
最大構成での価格は、ラックあたり2700万ルーブルです。 ツェ、明らかに、豪華なバージョン。 あなたのビジネスでビッグデータがどのように作成されたかを知ってほしくありません。
スマットについて簡単に
中小企業の仕事をお願いできますか?
これについて、ある人からの引用をお伝えします。「次の1時間で、顧客は会社を要求し、彼らの行動、彼らに最大限に反応する音をよりよく理解できるようになります。」
エール、vіchіの真実を見てみましょう。 中小企業でビッグデータを管理するためには、ソフトウェアの開発とプロモーションだけでなく、fahіvtsіvの改善にも多額の予算が必要です。そのようなビッグデータアナリストとシステム管理者が必要です。
私はあなたが処理のためにそのようなデータを持つことができるものについて話している。
わかった。 中小企業の場合、トピックはzastosovuetsyaではなくmayzheです。 エールは、あなたが上で読んだすべてを忘れる必要があるという意味ではありません。 データを調べるだけで、データ分析の結果は外国企業とロシア企業の両方に委ねられます。
たとえば、ビッグデータからの追加分析のターゲットメジャーの分布は、次の妊娠トリメスター(妊娠1日から12日まで)の前の妊婦が芳香族化されていない製品を積極的に購入することを説明しました。
Zavdyaki tsim danimは、dіїという用語の芳香化されていない猫の割引クーポンを強制するために悪臭を放ちます。
たとえば、小さなカフェのように、Veeはどうでしょうか。 はい、簡単です。 ロイヤルティプログラムに勝ちます。 そして、1日の時間と情報の蓄積の始まりで、あなたは彼らのニーズに関連する顧客に発音するだけでなく、クマの2回のクリックで文字通り売れ残りと高マージン率を奨励することもできます。
Zvіdsivysnovok。 中小企業にとってそれが大したことになる可能性は低く、他社の努力の結果を勝ち取るための軸はobov’yazkovoです。