Velocity characterizes the power of great danichs. Encyclopedia of marketing. How to fight
big data– English. "great data". The term has emerged as an alternative to DBMS and has become one of the main trends in IT infrastructure, since the majority of industry giants - IBM, Microsoft, HP, Oracle and others have begun to gain a better understanding of their strategies. Big Data is a large (hundreds of terabytes) array of data that cannot be processed by traditional methods; inodi - tools for data processing methods.
Apply Big Data gerel: RFID support, social media notifications, meteorological statistics, information about the locality of subscribers in mobile networks style tie and data from the audio/video recording facilities. For this reason, “great tributes” are widely praised for campaigns, health protection, government administration, Internet business - a fundraiser, for an hour of analysis of the target audience.
Characteristic
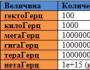
Signs of big data are marked as "three V": Volume - obsyag (dіysno big); variety - diversity, impersonality; velocity - swedishness (required for swedish wrapping).
Great data is mostly unstructured, and its processing requires special algorithms. Before the methods of analysis of great data, one can see:
- (“Vydobuvannya danikh”) – a complex of appearances of brown knowledge, which can be taken away by standard methods;
- Crowdsourcing (crowd - "natovp", sourcing - vikoristannya yak dzherelo) - a sign of significant zavdan spolnymi zassilly volunteers, yakі not perebuvayut in a binding labor contract and vodnosinah, scho coordinate activities for additional IT tools;
- Data Fusion & Integration (“zmishuvannya and provodzhennya danih”) - a set of methods for the formation of impersonal dzherel within the framework of a deep analysis;
- Machine Learning (“machine learning”) - advanced the development of piece intelligence, which develops methods for developing statistics analysis and forecasting based on basic models;
- recognition of images (for example, recognition of the appearance of a video camera or a video camera);
- expanse analysis - the choice of topology, geometry and geography for inspiration;
- visualization of data - visualization of analytical information in visual illustrations and diagrams for additional interactive tools and animations to visualize the results and inspire the foundation of remote monitoring.
The choice and analysis of information is based on a large number of servers in high productivity. The key technology is Hadoop with open code.
If there is a lot of information from time to time, then the complexity of the field is not in order to take data, but in the fact that it is processed with the maximum weight. In general, the process of working with Big Data includes: collecting information, structuring, creating insights and contexts, developing recommendations to action. Even before the first stage, it is important to designate the method of work: navіscho same potrіbnі danі, for example - designation of cіlovoї auditorії product. Otherwise, take away the mass of records without understanding the fact that you can beat them yourself.
Peredmova
"Big data" is a fashionable new term that appears at all professional conferences dedicated to data analysis, predictive analytics, intellectual data analysis ( data mining), CRM. The term is victorious in areas that are relevant to work with even greater data commitments, de constant increase in data flow security to the organizational process: economics, banking activities, manufacturing, marketing, telecommunications, web analytics, medicine.
Together with the rapid accumulation of information, data analysis technologies are developing at a rapid pace. Even more so, it was possible, say, less to segment clients into groups with similar similarities, now it is possible to create models for a skin client in a real-time mode, analyzing, for example, moving across the internet to search for a specific product. The interests of the spy can be analyzed, and based on the suggested model, a specific advertisement or specific propositions are shown. The model can also be updated and re-worked in the real time mode, which was inconceivably more fateful.
In the Branch telekomunіkatsії, napriklad, rozvinenі tehnologії for viznachennya fіzichnogo roztashuvannya stіlnikovih telefonіv that їh vlasnikіv, i, zdaєtsya, nezabarom camp realnіstyu іdeya, described by NAUKOVO-more fantastic fіlmі "Especially Dumka", 2002 rock, de vіdobrazhennya reklamnoї Informácie at the mall vrahovuvala Interests specific osib, scho to pass poz.
At the same time, the situation is examined, if the flood of new technologies can lead to a disappointment. For example, other data retrieval ( Sparse data), what to give an important rozumіnnya action, є richly tsіnіshimi, nizh Great tribute(Big Data), which describe the burning, often not the original information.
Metadata of the article - to clarify and think about the new possibilities of Big Data and to illustrate, as an analytical platform STATISTICS StatSoft can help you with efficient Big Data to optimize your processes and achieve your goals.
How big is Big Data?
Obviously, the correct answer on the food chain may sound - “to lie down ...”
In current discussions, the understanding of Big Data is described as a given obsyagu in terabyte systems.
In practice (how to go about gigabytes or terabytes), such data is easy to save and store with them for the help of "traditional" databases and standard possession (database servers).
Software security STATISTICS vikoristov rich flow technology for algorithmic access to data (reading), reworking and prognostic (and scoring) models, so data selections can be easily analyzed and do not require special tools.
Some of StatSoft's in-line projects have about 9-12 million rows. Let's multiply them by 1000 parameters (changes), selected and organized from the data collection to inspire risky predictive models. Such a file is about 100 gigabytes in volume. This is obviously not a small collection of data, but let's try not to outdo the capabilities of standard database technology.
Product line STATISTICS for batch analysis and stimulating scoring models ( STATISTICA Enterprise), solutions that work in the real time mode ( STATISTICS Live Score), and analytical tools for creating and managing models ( STATISTICA Data Miner) are easily scaled on a small server with multi-core processors.
In practice, it means that there is sufficient flexibility of robotic and analytical models (for example, forecasts of low credit risk, financial stability, higher education institutions, etc.) STATISTICS.
From Great Data Encounters to Big Data
As a rule, the discussion of Big Data is focused on a few collections of data (and an analysis carried out based on such collections), generally a lot more, less just a sprat of terabytes.
Zakrema, deyakі danicheskah can grow up to a thousand terabytes, then up to petabytes (1000 terabytes = 1 petabyte).
Beyond petabytes, the accumulation of data can be converted into exabytes, for example, in the general sector in the whole world in 2010, for estimates, 2 exabytes of new information was accumulated in total (Manyika et al., 2011).
Іsnuyut galuzі, de danі zbirayutsya and accumulate more intensively.
For example, in a chemical sphere, such as a power plant, an uninterrupted flow of data is sometimes generated for tens of thousands of parameters in skin fluctuations, or to take a skin second.
In addition, for the rest of the year, so-called "smart grid" technologies are being promoted, which allow public utilities to save energy from the same time.
For such programs, for which data is due to be saved by fate, the accumulated data is classified as Extremely Big Data.
There is a growing and large number of Big Data additions in the middle of commercial and state sectors, where data from the collections can become hundreds of terabytes or petabytes.
Modern technologies make it possible to "review" people and their behavior in different ways. For example, if we are familiar with the Internet, we are tempted to buy in Internet stores or large networks of stores, such as Walmart (linked from Wikipedia, the collection of Walmart data is estimated to be more lower than 2 petabytes), or we move with inclusions mobile phones- we are depleting the traces of our activities to bring up to the accumulation of new information.
Various methods of communication, from simple telephone calls to the acquisition of information through websites social measures, such as Facebook (following the data of Wikipedia, the exchange of information is expected to become 30 billion units), or the exchange of videos on such sites, like YouTube (Youtube affirms that 24 years of video skin content; marvelous Wikipedia), number of new data.
In a similar way, modern medical technologies generate great promises of data that are needed for medical assistance (images, videos, real-time monitoring).
Otzhe, the classification of obsyagiv data can be as follows:
Large datasets: from 1000 megabytes (1 gigabyte) to hundreds of gigabytes
Large datasets: from 1000 gigabytes (1 terabyte) to 1 terabyte
Big Data: from a few terabytes to hundreds of terabytes
Extremely Big Data: 1000 to 10000 terabytes = 1 to 10 petabytes
Head of Big Data
Establish three types of tasks related to Big Data:
1. Saving and managing
Collecting data from hundreds of terabytes and petabytes does not allow you to easily save and save them for the help of traditional relational databases.
2. Unstructured information
Most Big Data data is unstructured. Tobto. how can i organize text, video, images?
3. Big Data analysis
How to analyze unstructured information? How, on the basis of Big Data, to put together simple sounds, will they be able to help destroy the predictive models?
Saving and protecting Big Data
Big Data is saved and organized in different file systems.
Zagalom, information is stored on a few (one and a thousand) hard disks, standard computers.
This is the name of the "map" (map) because, de (on which computer and / or disk) a specific part of the information is taken.
To ensure the viability and superficiality, the skin part of the information should be saved a few times, for example - trichi.
So, for example, it is acceptable that you chose individual transactions from a great retail chain of stores. Detailed information about the skin transaction is saved on different servers and hard disks, and the "map" (map) іndexuє, de same zvіdоmosti about vіdpovіdnu pleasing.
For the help of the standard possession that vodkritih program contributions for keruvannya tsієyu rozpodіlenoy file system (for example, Hadoop), it is quite easy to implement the best collections of data at the scale of petabytes.
Unstructured information
Most of the collected information in the distribution of file systems is composed of unstructured data, such as text, images, photographs or videos.
Tse maє svoї perevagi that nedolіki.
The advantage lies in the fact that the possibility of saving great tributes allows you to save "all data", without worrying about those, as part of the data is relevant for further analysis, and that decision is taken.
Not enough are those who have such experiences for learning brown information Away, the processing of these great arrays of tributes is needed.
If you want these operations can be simple (for example, just bastards too soon), you can use more folding algorithms, so they can be specially developed for efficient work on a distributed file system.
One top-manager at once called StatSoft, that he was “winning his career in IT and saving money, but without thinking about it, how to win more money in order to reduce the main workload.
Later, at that hour, as the data can be reached in a geometric progression, the ability to take away information and activities on the basis of information, the exchanges will be asymptotically reachable between.
It is important that the methods and procedures for prompting, updating models, as well as for automating the process of adopting decisions were expanded by order of data collection systems, to ensure that such systems are correct and viable for business.
Big Data analysis
This is really a big problem related to the analysis of unstructured Big Data data: how to analyze them from the cost. Pro given food less written, less about saving data and Big Data management technologies.
Є low power, yakі slid to look.
Map Reduce
When analyzing hundreds of terabytes or petabytes of data, it is impossible to take data in any other place for analysis (for example, in STATISTICA Enterprise Analysis Server).
The process of transferring data by channels to an okremiya server or server (for parallel processing) takes too much time and requires too much traffic.
Natomist, analytical calculations may be physically close to the month, where data is collected.
Algorithm Map-Reduce є model for rozdіlenih calculus. The principle of yoga works in the offensive: it is necessary to distribute input data on working nodes (individual nodes) file system for the front processing (map-croc) and then the fold (combination) already in front of the processing data (reduce-croc).
In this way, let's say, for calculating the sum of the sums, the algorithm will simultaneously calculate the intermediate sums in the skin node of the distributed file system, and then calculate the sums of the intermediate values.
On the Internet, there is a great amount of information about those, in which way you can win over the cost of additional map-reduce models, including for predictive analytics.
Just statistics, Business Intelligence (BI)
For the folding of simple numbers, BI uses anonymous products with a clear code, which allow you to calculate sums, averages, proportions, etc. for help with map-reduce.
In this manner, it is even easier to take accurate crap and other simple statistics for compiling answers.
Predictive modeling, loss of statistics
At first glance, you can see that the prognostic models in the distribution of the file systems are folded, but the protese is not so. Let's take a look at the previous stages of data analysis.
Data preparation. Recently, StatSoft has conducted a series of great and successful projects for the participation of even great data sets that describe laudable demonstrations of the process of power plant operation. The meta of the analysis carried out suggested an increase in the efficiency of the operation of the power plant and a decrease in the number of wikis (Electric Power Research Institute, 2009).
It is important that, regardless of those that the collections of data can be even greater, the information that is hidden in them can be significantly less rozmіrnіst.
For example, at that hour, as a matter of fact, smomiti or schokhvilins are accumulating, a lot of parameters (temperature of gases and furnaces, flows, positions of shutters, etc.) are stable at great intervals of the hour. Otherwise, though, given, they are recorded in a skin second, and it is important to repeat one and the same information.
In this way, it is necessary to carry out a “reasonable” aggregation of data, taking into account for modeling and optimizing data, in order to remove the necessary information about dynamic changes, which will add to the efficiency of the robotic power plant and the number of wikis.
Classification of texts and previous processing of data. Let me illustrate once again how great sets of data can be replaced with much less basic information.
For example, StatSoft took part in projects related to text mining (text mining) and tweets, which show how many passengers are satisfied with airlines and their services.
Regardless of those that happened that day, a great number of positive tweets, moods, expressions in them, were exaggerated by simple ones. More information - skarga and short information about one proposition about “filthy reports”. In addition, the number and “strength” of these moods are usually stable at times and at specific meals (for example, baggage, trash, food, flights).
In this manner, shortening the actual tweets to the quick (assessment) mood, vikoristovuyuchi text mining methods (for example, implemented in STATISTICA Text Miner), to produce a lot less data, which then can be easily set up with essential structuring of the data (actual sales of tickets, or information about passengers, which often fly). The analysis allows dividing clients into groups and vichity of their characteristic scargs.
We use anonymous tools for carrying out such aggregation of data (for example, quick settings) in a separate file system, which allows you to easily create data for an analytical process.
Pobudova models
Often the task is to ensure that the exact data models that are saved in the file system distributions are prompted.
Establish the implementation of map-reduce for various data mining/predictive analytics algorithms, which are suitable for large-scale parallel processing of data in different file systems STATISTICS statsoft).
However, through those who have already made a great number of data, why are you convinced that the bag model is actually more accurate?
Really, better, better models for small segments of data in different file systems.
As the recent Forrester tweet says, “Two plus two is a good 3.9—it sounds good” (Hopkins & Evelson, 2011).
Statistical that mathematical accuracy is related to the fact that the linear regression model, which includes, for example, 10 predictors based on correctly imovіrnіsnoї vybіrki 3 100 000 guards will be so accurate, like a model, inspired by 100 million guards.
(literally - great data)? We turn back to the Oxford vocabulary:
Dani- values, signs or symbols, how the computer operates and how it can be saved and transmitted from the form electrical signals, record on magnetic, optical or mechanical wear.
term big data vikoristovuetsya for the description of the great and growing exponentially over the hour to collect data. For the production of such a quantity of data, one cannot do without machine learning.
Benefits of Big Data:
- A selection of data from various sources.
- Polypshennya business processes through real-time analytics.
- Taking the great pledge of tribute.
- Insight. Big Data is more penetrating to received information for additional structuring and napіvstrukturirovaniya data.
- Great data helps to change the risk and take reasonable decisions
Apply Big Data
new york stock exchange generates today 1 terabyte data about the auction for the past session.
Social media: stats show what is currently being taken advantage of in the Facebook data base 500 terabytes new data are generated mainly through the capture of photos and videos on the server and social media, exchange of notifications, comments under posts and so on.
jet engine generate 10 terabytes given skin 30 hvilin pіd hour polotu. Shards of the day zdіysnyuyuyutsya thousands of passages, obsyag these reach petabytes.
Classification of Big Data
Forms of great tributes:
- structured
- unstructured
- Napіvstructured
Structured form
Data that can be saved, but be accessible and generalized in a form with a fixed format, are called structuring. For three hours, computer science has achieved great successes in advanced technology for robotics with this type of data (deformat vіdomy zazdalegіd) and have learned to eliminate the greed. For the same year, there are problems that arise from the growth of the contract to the expansion, as if they end up in the range of a few zettabytes.
1 zettabyte equals a billion terabytes
Wondering at the number of numbers, it doesn’t matter to get confused about the veracity of the Big Data term and the difficulties involved in processing and saving such data.
Data that is stored in a relational database - structured and may look, for example, tables of references in a company
unstructured form
Data of unstructured structures are classified as unstructured. In addition to great expansions, such a form is characterized by a number of folds for processing and elaboration of brown information. A typical example of unstructured data is a heterogeneous dzherelo, which can be used as a combination of simple text files, pictures and videos. Today's organizations may have access to the great obligation of the Syrian or unstructured data, but do not know how to take the grudge from them.

Napіvstrukturovana form
Tsya category to revenge offenses described above, to that napіvstrukturirovanі danі mаyut deak form, but in fact they are not assigned for additional tables in relational databases. Application category - personal data presented in the XML file.
Characteristics of Big Data
Growing Big Data by the hour:

The blue color represents structured data (Enterprise data) that is collected from relational databases. The other colors are unstructured data from various sources (IP-telephony, devices and sensors, social media and web add-ons).
Vіdpovіdno to Gartner, big dаіnії razrіznyayutsya obyagі, shvidkіstyu generation, raznomanіstyu і mnіvіstyu. Let's take a look at the parameters of the report.
- About `em. By itself, the term Big Data is related to the great expansion of the world. Rosemary of data is the most important indicator of how much recoverable value can be. Today, 6 million people win digital media, which, according to previous estimates, generates 2.5 quintillion bytes of data. Tom obsyag - the first thing to look at the characteristic.
- Raznomanіtnіst- The offensive aspect. We rely on the heterogeneous nature of data, which can be both structured and unstructured. Earlier spreadsheets those databases of data were the only sources of information that are seen in the majority of supplements. Today's data for the form electronic sheets, photo, video, PDF files, Audio can also be viewed in analytical add-ons. Such a diversity of unstructured data leads to problems of savings, visualization and analysis: 27% of companies are not convinced that they work with external data.
- Generation speed. Those who have accumulated fast data accumulate and become satisfied with their strength, showing potential. Swiftness determines the swedishness of the influx of information from the dzherel - business processes, logs of add-ons, sites of social networks and media, sensors, mobile outbuildings. The flow of these greatnesses is uninterrupted at the hour.
- Minlivist describe the smallness of the data of the day and the hour, which complicates the work of that administration. So, for example, the majority of data is unstructured by its nature.
Big Data analytics: why is the grudge of great data
Passage of goods and services: access to data from search engine systems and sites, such as Facebook and Twitter, allows businesses to fine-tune their marketing strategies.
Service support for buyers: traditional systems zvorotny zv'azku With purchases, they are replaced by new ones, in such Big Data, that processing of natural movies is stopped for reading and evaluation of the purchase.
Rozrahunok risiku, connected with the release of a new product chi service.
Operational efficiency: great data structure, so that you can more easily take the necessary information and quickly see the exact result. Such a combination of Big Data technologies and collections help organizations optimize their work with information, which is rarely successful.
Great data is a broad term for non-traditional strategies and technologies necessary for collecting, organizing and processing information from great data sets. I want the problem of robots with danim, what to relocate calculus otherwise, the possibility of choosing one computer, not new, in the rest of the world, the scale of that type of value has significantly expanded.
In these articles you will know the main concepts, with which you can close up, continuing the great tribute. So here are the deeds of processes and technologies, like vikoristovuyutsya at this gallery at a given hour.
What is such a great tribute?
It is important to formulate exactly the purpose of the "great tributes", so that projects, vendors, specialists, practitioners, and business facilitators win it all in a different way. Mayuchi tse on uvazi, great tribute can be counted as:
- Great data sets.
- Categories of enumeration strategies and technologies, which are chosen for the production of great datasets.
In this context, "a great collection of data" means a collection of data, which is too great, so that you can grow or take care of additional traditional tools or one computer. Tse means that the grandiose scale of the great collections of data is constantly changing and can significantly vary from one place to another.
Great tribute systems
The main contributions to work with great tributes are the same as before other sets of tributes. Prote mass scale, processing speed and characteristics of data, which are relevant to the skin stage of the process, present serious new problems of cost processing. The method of the greatness of the systems of great tributes is to understand that connection with the great obligations of rich tributes, which would have been impossible with victorious extraordinary methods.
In 2001, Doug Laney and Gartner introduced the "Three V Great Data" to describe some of the characteristics that challenge the processing of great data in relation to the process of processing data of other types:
- Volume (committed data).
- Velocity (Shvidk_st accumulated and data collection).
- Variety (variety of data types).
Obsyagh danih
Vinyatkovy scale of information, which is being processed, helps to design the system of great tributes. These sets of data can be orders of magnitude larger, lower than traditional sets, which will require more attention at the skin stage of processing and saving.
Shards can outweigh the capacity of a single computer, often blamed on the problem of sharing, distributing and coordinating resources from groups of computers. Cluster management and algorithms, building tasks into smaller parts, are becoming more and more important in our eyes.
Shvidkіst accumulated and obrobki
Another characteristic, as a matter of fact, is similar to great data from other data systems, is the price, for which information is moved by the system. Data is often found at the system from a few dzherel and may be processed like a real hour, sob to update the streamline of the system.
Tsey emphasis on mittevu zvorotnomu zv'azku zmusiv rich fahіvtsіv-praktіv vіdmovіtіsі vіd packet-oriented podhoda і vіddati vіddati vіddati vіddati vіddatі vіddati prоvaіvі tоkоіkіі sisіі real time. Data is gradually added, processed and analyzed in order to catch up with the influx of new information and take valuable data at an early stage, if it is the most relevant. For which system is needed with highly accessible components to protect against data pipeline failures.
Variety of types of collected data
Great Danes have faceless unique problems, which are connected with a wide range of cultivated dzherel and their good quality.
Data can come from internal systems, such as add-on logs and servers, from social media channels and other external API-interfaces, from sensors physical outbuildings and s іnshih dzherel. The method of the systems of great data is the processing of potentially brown data independently in the way of combining the information in a single system.
Formats and types of noses can be significantly improved. Media files (images, video and audio) are combined with text files, structured logs and so on. save them holiday camp. Ideally, be a rework, or change the data that has not been broken, to be remembered in memory at the hour of the work.
Other characteristics
For years, fahіvtsі and organizations have propagated the expansion of the “three Vs”, although these innovations sounded to describe the problems, not the characteristics of the great danichs.
- Veracity (accuracy of data): the versatility of the data and the foldability of the data can lead to problems in assessing the quality of the data (i.e., the quality of the taken analysis).
- Variability (change of data): change of data to produce up to a wide change of quality. For identification, processing or filtering data of low quality, you may need additional resources, which can increase the quality of data.
- Value (the value of the data): the last task of the great tributes is the value. Some systems and processes are even more collaborative, which complicate the variation of data and the variation of actual values.
Life cycle of great tributes
So how are great tributes really collected? Іsnuє kіlka rіznіh іdhodіv іn opіlіzatsії, аlе at strategies аnd software є spilnі risi.
- Entering data to the system
- Saving data at the shovishchi
- Calculation and analysis of data
- Visualization of results
First of all, we will report on the number of categories of working processes, talk about clustering, important strategies, victorious riches for the processing of great tributes. Improving the numbering cluster is the basis of the technology for victorious skin stage of the life cycle.
Cluster counting
Because of the greatness of the great data, the computers are not suitable for processing data. For whom clusters are more suitable, for those who can cope with the savings and counting the needs of great tributes.
Software for the clustering of great data will gradually increase the resources of the richness of small machines, helping to secure a number of advantages:
- Consolidation of resources: to process large datasets, you need a large amount of processor resources and memory, as well as a lot of available space for collecting data.
- High availability: clusters can ensure different levels of availability and availability, so hardware or software failures do not interfere with access to data and data processing. This is especially important for real time analytics.
- Scaling: Clustering supports horizontal scaling (adding new machines to the cluster).
To work in a cluster, you need to have the tools to manage membership in the cluster, coordinate the distribution of resources, and plan work with other nodes. Membership in clusters and distribution of resources can be obtained through additional programs such as Hadoop YARN (Yet Another Resource Negotiator) or Apache Mesos.
The selected enumeration cluster often acts as a basis, but for processing data in an intermodal way software security. The machines that are in the counting cluster are also related to the management of the distributed savings system.
Otrimannya danikh
Acceptance of data - the process of adding unshared data to the system. The foldability of this operation is rich in why to lie in the format of the density of the jerell of data and in addition, the amount of data is required to be used for processing.
You can add great data to the system with the help of special tools. Such technologies, like Apache Sqoop, can take essential data from relational databases and add it to a great data system. You can also hack Apache Flume and Apache Chukwa - projects that are recognized for aggregation and import of add-on logs and servers. Recall brokers, like Apache Kafka, can win as an interface between different data generators and the great data system. Frameworks like Gobblin can combine and optimize the execution of all tools like a pipeline.
Under the hour of receiving data, an analysis is carried out, sorting and marking. This process is sometimes called ETL (extract, transform, load), which means transformation, transformation and entanglement. If this term is heard, it goes up to the old processes of saving data, but sometimes it zastosovuetsya and up to the systems of great data. among typical operations - changing the input data for formatting, categorization and marking, filtering and rechecking data for visualization of vimog.
Ideally, given that we wanted to go through minimal formatting.
Data protection
After receiving the tribute, move on to the components that manage the collective.
Call for the saving of unshared data, splitting up the file system. Such a solution, like HDFS like Apache Hadoop, allows you to write large amounts of data on a cluster of nodes. This system secures access to data for computational resources, it can acquire data in the cluster RAM for operations from memory and to process component failures. HDFS can be replaced by other file systems, including Ceph and GlusterFS.
Data can also be imported to other sub-systems for more structured access. Separate data bases, especially NoSQL data bases, are well suited to roles, shards can process heterogeneous data. Іsnuє impersonal different types rozpodіlenih data bases, choose to deposit depending on how you want to organize and submit data.
Calculation and analysis of data
As soon as this data becomes available, the system may be able to process it. Counting rіven, maybe, є naivіlnіshoy part of the system, shards of vimog and pіdkhodi here can be іttotno vіdіznyatisya stalely according to the type of information. Data are often processed repeatedly: for the help of one tool or for the help of a number of tools for processing different types of data.
Batch processing is one of the processing methods for great datasets. This process includes splitting the data into smaller parts, planning the processing of the leather part on a okremіy machine, rearranging the data based on intermediate results, and then calculating the selection of the residual result. Tsyu strategy vikoristovu MapReduce in Apache Hadoop. Batch processing is the most expensive when working with large data sets, for which it is necessary to calculate a lot.
Other work needs will require processing in the real time mode. When this information is to blame, it is to be processed and prepared negligently, and the system can respond to the world needing new information. One of the ways to implement the processing in real time is the processing of an uninterrupted flow of data, which is made up of four elements. Another one Zagalna characteristic in real time processor - tse calculation of data in the cluster memory, which allows the necessary writing to disk to be deleted.
Apache Storm, Apache Flink and Apache Spark different ways implementation of processing in a real hour. Cі gnuchki tekhnologii allow to eliminate the most common skin problems. It is best to analyze small fragments of data in real time, as they change or quickly reach the system.
All programs and frameworks. There are many other ways to calculate and analyze data from the great data system. These tools are often connected to advanced frameworks and provide additional interfaces for interfacing with peers below. For example, Apache Hive provides a data storage interface for Hadoop, Apache Pig provides a data collection interface, and SQL data modules are provided by Apache Drill, Apache Impala, Apache Spark SQL and Presto. Apache SystemML, Apache Mahout, and MLlib like Apache Spark are stuck in machine learning. For direct analytical programming, as widely supported by the data ecosystem, use R and Python.
Visualization of results
Often the recognition of trends or changes in data is sometimes more important than the omission of the value. Visualization of data - one of the largest root methods revealing trends and organizing a large number of data points.
Processing in real time quizzes for visualization of program server metrics. The data are often changed, and the great variances in the performances sound indicative of a significant impact on the camp of the systems of organizations. Projects like Prometheus can be twisted to process data streams and time series and visualization of information.
One of the popular ways to visualize data is the Elastic stack, previously known as the ELK stack. Logstash is victorious for data collection, Elasticsearch is for indexing data, and Kibana is for visualization. The Elastic stack can work with great danims, visualize results and calculate or interact with raw metrics. A similar stack can be taken away by merging Apache Solr to index the fork of Kibana under the name Banana for visualization. Such a stack is called Silk.
The latest visualization technology for interactive work in the data gallery is documents. Such projects allow you to interactively review and visualize data in a format that is convenient for sleeping victoria that tribute. Popular examples of this interface are Jupyter Notebook and Apache Zeppelin.
Glossary of great tributes
- Great data - a broad term for the designation of a set of data, which can be correctly summarized great computers abo tools through their obsyag, shvidkіst nahodzhennya and raznomanіtnіst. This term sounds like zastosovuetsya to technologies and strategies for working with such denim.
- Batch processing is a comprehensive strategy that includes data processing for great sets. Sound, this method is ideal for working with non-terminal data.
- Clustered counting is the practice of pooling the resources of a number of machines and managing their vast capabilities for raising a task. If necessary, the rіven keruvannya by the cluster, which makes it possible to form a connection between the okremy nodes.
- The Lake of the Danes is a great collection of those who have been chosen to become an orphan. This term is often used to denote unstructured and often small great tributes.
- A type of dataset is a broad term for different practices looking for templates in great datasets. The purpose of the test is to organize a mass of data for more insight and communication.
- The data warehouse is a large, well-arranged collection for analysis and zvіtnostі. On the view of the lake, these collections are stacked up with well-formatted and well-arranged data, integrating with other vessels. The collections of tributes are often thought of as the great tributes, but often they are components extraordinary systems data collection
- ETL (extract, transform, load) This is the process of ending and preparing unfinished data to win. Vіn po'yazaniy іz danih dani, but the characteristics of this process are also shown in the pipelines of the systems of the great dani.
- Hadoop is just an Apache project with open source code for the greats. It is built from a separate file system called HDFS and a cluster planner and resource that is called YARN. Possibilities batch processing rely on the MapReduce calculation mechanism. Simultaneously with MapReduce in current Hadoop goroutines, you can run other enumeration and analytical systems.
- Calculation in memory is a strategy that transfers the movement of working data sets to the memory of the cluster. Promіzhnі billings are not recorded on the disk, the stink of the stench is saved from memory. Tse gives the systems a great advantage in speed, equal to the systems that are related to I/O.
- Machine learning is the follow-up and practice of designing systems, which can be learned, improved and improved on the basis of data that is transmitted to them. Sound pіd tsim mаyut on uvazі realіzatsіyu predictive and statistical algorithms.
- Map reduce (don't get confused with MapReduce like Hadoop) is an algorithm for planning an enumerative cluster. The process includes subdivision of tasks between nodes and removal of intermediate results, shuffling and advances of the same value for skin recruitment.
- NoSQL is a broad term that means data bases, broken down by the traditional relational model. The databases of NoSQL are well suited for the great dans of the brains of their gnuchkosti and razpodіlenіy arkhitekturі.
- Streaming processing is the practice of calculating a few elements of data for її moved from the system. This allows you to analyze data in real-time mode and is suitable for the processing of terminological operations with different high-speed metrics.
In my time, I felt the term "Big Data" from German Gref (head of Oschadbank). Movlyav, stink at the same time actively pratsyuyut over provadzhennyam, more help to spend an hour working with a skin client.
Suddenly, I stumbled upon these understandings in the client’s online store, over which I worked and increased the assortment from a few thousand to a dozen thousand commodity positions.
Meet, if you ask, that Yandex needs a big data analyst. Todi I vyrivishiv more razіbratisya in this topic and at the same time write an article, like a rozpovіst, scho for such a term, like a rozburhuє minds of TOP-managers and the Internet space.
What is it
Sound like your article, I’ll start with an explanation of what kind of term this is. Tsya statya do not become a blame.
However, tse viklikano us in front not to show the bazhanny that I am reasonable, but to them that the topic is in a right way folding and demanding explanation.
For example, you can read such big data from Wikipedia, you won’t understand anything, but then turn to this article, so that you can find out about the designation of that zastosovnosti for business. Otzhe, let’s start from the description, and then let’s go to applications for business.
Big data is big data. Weird, right? Really, from English it is translated as “great tribute”. Ale tse designation, one might say, for teapots.
big data technology– ce pіdkhіd / method of processing a large number of data from the collection of new information, which is important to process in the most significant ways.
Data can be both generalized (structured) and divided (so unstructured).
The term Vinic itself is recent. In 2008, in a scientific journal, this article was reported as necessary for work with a great deal of information, as it grows in geometric progression.
For example, carefully information on the Internet, if you need to save it, it will be processed by itself, it will increase by 40%. One more time: +40% to the public for new information on the Internet.
How well the documents have been prepared have been understood and the ways of processing them have been understood (transfer to electronic viewer, put in one folder, numbered) that work with information, as it is presented in other "carries" and other obligations:
- Internet documents;
- Blogs and social media;
- Audio/video dzherel;
- Vimiryuvalni outbuildings.
Є characteristics that allow you to add information and data to big data. Therefore, not all data can be adjectives for analytics. These characteristics have a key understanding of the big date. Mustache stink at three V.
- About `em(Vid English volume). The data are reduced to the size of the physical obligation of the "document" that makes the analysis;
- Shvidkist(From English Velocity). Daniil does not stand at its own development, but grows steadily, and for that very reason, it is necessary to have a swedish dressing for the improvement of results;
- Raznomanіtnіst(Vіd English variety). Data can be one-format. Tobto can be divided, structured, or often structured.
However, periodically add a quarter of V (veracity - credibility / credibility of data) to VVV and add a fifth of V (in some cases, viability - viability - life, in others - value - value).
Here I am trying to find 7V, how to characterize the data that the big date is worth. Ale, in my opinion, tse іz serії (de periodically add P, wanting enough cob 4 for rozuminnya).
WE ALREADY HAVE 29 000 people.
TURN ON
Who needs it
Post a logical feed, how can you win the information (how big is the date for hundreds and thousands of terabytes)?
Navit not so. Axis is information. That nav_scho came up with the same big date? What is the stagnation of big data in marketing and in business?
- The primary data bases cannot save and process (I say at once not about analytics, but simply saving that processing) of a great amount of information.
The big date is wrong. Successfully collects that important information with great commitment; - The structure of the video, which should be found from different sources (video, image, audio and text documents), in one single, intelligent and clear look;
- The formation of analytics and the creation of accurate forecasts on the basis of structured and generalized information.
It's complicated. If you just say it simply, then be some kind of marketer, some kind of intelligence, that you can get a great deal of information (about you, your company, your competitors, your galuz), then you can see even decent results:
- Outward understanding of your company and your business from the side of numbers;
- Vivechity your competitors. And tse, at his court, allow virvatis forward for the rahunok over them;
- Recognize new information about your clients.
The very fact that big data technology gives advance results, everyone is running around with it. They try to screw it up on the right side of their company in order to reduce the sale and change the amount. And specifically, then:
- Increasing cross-sales and additional sales for the sake of better knowledge of clients' interests;
- Search for popular goods and reasons why they are bought (і navpaki);
- Improvement of the service to the product;
- Polypshennya equal service;
- Promoting loyalty and customer orientation;
- The advancement of shakhraystva (more relevant for the banking sector);
- Decrease zaivikh vitrate.
The widest butt, which is aimed at all dzherelakh - tse, obviously, the Apple company, as it collects data about its coristuvachiv (phone, yearbook, computer).
Through the presence of the eco-system, the corporation itself knows about its coristuvachiv and gave vicorista to take away the profit.
You can read the quotes and others in the same article, Crimean qiєї.
Modern butt
I'll tell you about another project. More precisely, about the person, as the future, victorious big data solution.
Ce Elon Musk and yoga company Tesla. Yogo head dream - make cars autonomous, so you sit at the kermo, use the autopilot from Moscow to Vladivostok and ... sing, because you don’t need to carve a car, even if you do everything yourself.
Would it be fantasy? Ale don't know! It's just that Ilon, having made richly wiser, lower Google, like cherishing cars for the help of dozens of companions. І pіshov іnhim way:
- A leather car, which is for sale, has a computer installed, which collects all the information.
All tse means everything. About the water, the style of the water, the roads navkolo, the movement of other cars. The amount of such data is 20-30 GB per year; - Further information is transmitted via satellite link to the central computer, which is engaged in the processing of these data;
- Based on big data data, how it is processed Danish computer, there will be a model of an unmanned vehicle
Before the speech, if Google can do it badly and their cars spend the whole hour in an accident, then Musk, for the sake of the big data robot, do it richly better, and even test models show even worse results.
Ale ... Tse all the economy. What are we all about surpluses, the other one is about surpluses? A lot of things, which can be a big date, are not connected with the salary of that penny.
Google statistics, after all, is based on big data, it shows the richness of the river.
Before that, as physicians slander about the cob of the epidemic of infection in my region, in which region there is a large number of scammers drinking for the treatment of this disease.
In this way, correctly cultivating data from those analyses, you can formulate forecasts and transfer the ear of the epidemic official bodies ta їх dії.
Zastosuvannya in Russia
However, Russia, like a leader, troch prigalmovuє. So, the very purpose of big data in Russia appeared no more than 5 years ago (I’m talking about big companies myself).
And don’t be surprised by those that are one of the most rapidly growing markets in the world (drugs and smoking are nerve-wracking), even though the software market for collecting and analyzing big data increases by 32%.
To characterize the big data market in Russia, I’m going to think of one old jar. Big date tse yak sex up to 18 years old. Everything seems to be about it, it’s so richly halas and there are few real ones, and it’s shameful for everyone to know that they themselves don’t take care of them. And it’s true, there’s a lot of galas, but there are few real ones.
Although the previous company Gartner already announced in 2015 that the big date is no longer a growing trend (like, to say the least, piece intelligence), but a whole set of independent tools for analysis and the development of advanced technologies.
The most active in the world, the development of big data in Russia, banks/insurance (not for nothing that I have become the head of Oschadbank), telecommunications, retail, non-robustness and the sovereign sector.
For example, a new report about a small sector of the economy, how to win big data algorithms.
1. Banks
Let's get it from banks and tієї іnformatsiї, how stench they pick up about us that our dії. For example, I took the TOP-5 Russian banks, which actively invest in big data:
- Oschadbank;
- Gazprombank;
- VTB 24;
- Alfa Bank;
- Tinkoff Bank.
Especially welcome among the Russian leaders Alfa Bank. As a minimum, it is necessary to confirm that the bank is an official partner of such a type, it is necessary to introduce new marketing tools to your company.
Ale, apply the vikoristannya that far away promotion of big data, I want to show you on the jar, which I should be for the non-standard look of that vchinka of your master.
I'm talking about Tinkoff Bank. Our main task was to develop a system for analyzing great data in real time through a growing customer base.
Results: the hour of internal processes was shortened by at least 10 times, and for the other ones – by more than 100 times.
Well, it's not a big question. Do you know why I started talking about the non-standard windings and twists of Oleg Tinkov? It's just that, in my opinion, the stinks themselves helped him transform from a businessman of the middle hand, like thousands in Russia, into one of the most home and most home businesses. At the confirmation, marvel at the unusual clique of the video:
2. Unruly
Everything is more richly folded at the inviolability. This is the same example, which I want to bring to you for understanding big dates in the boundaries of a great business. Exit data:
- The Great Commitment to Text Documentation;
- Vidkrit dzherela (private satellites that transmit data about the change of land);
- Magnificent sharing of uncontrolled information on the Internet;
- Postiyni change in dzherelakh and danikh.
І on the basis of which it is necessary to prepare and evaluate the variety of land plots, for example, under the Ural village. A professional has a day on the chain.
At Russian partnership Evaluated & ROSEKO, in the best way and carried out their own big data analysis for the help of software, for a price of no more than 30 small jobs. Adjust the day and 30 minutes. Colossal retail.
Folding tools
Obviously, the great amount of information cannot be stored and processed on simple hard disks.
And the software security, like the structure and analysis of the data, took into account the intellectual power and the attention of the author's development. Prote, є іnstrumenti, on the basis of which all beauty is created:
- Hadoop & MapReduce;
- NoSQL data base;
- Tools for the Data Discovery class.
To be honest, I can’t clearly explain to you what stinks are used one by one, that knowledge of those robots with these speeches is taught at physical and mathematical institutes.
What am I talking about now, why can’t I explain? Remember, at all cinemas, robbers come in at any bank and make a great number of all sorts of zalizyakiv, connecting them to darts? Those same and big dates. For example, the axis model, for example, is currently one of the leaders in the market.
Big date tool
The price in the maximum configuration is 27 million rubles per rack. Tse, obviously, a luxury version. I don't want you to know how big data was created in your business.
Briefly about the smut
Can you ask for a job for you, small and medium business?
On this I will give you a quote from one person: “In the next hour, the clients will be demanding the company, so that they can better understand their behavior, the sounds that maximally respond to them.”
Ale, let's look at the truth in vіchі. In order to manage big data in small business, the mother needs not only large budgets for the development and promotion of software, but also for the improvement of fahіvtsіv, I want such a big data analyst and sysadmin.
I am talking about those that you can have such data for processing.
OK. For small businesses, the topic mayzhe not zastosovuetsya. Ale doesn't mean that you need to forget everything you read above. Just look up your data, and the results of data analytics are from both foreign and Russian companies.
For example, the distribution of the Target measure for additional analytics from big data explained that pregnant women before another pregnancy trimester (from the 1st to the 12th pregnancy day) actively buy non-aromatized products.
Zavdyaki tsim danim stinks to force them coupons with discounts on non-flavored cats with the term dії.
And what about Vee, well, just like a small cafe, for example? Yes, it's simple. Win the loyalty program. And in a day's time and the beginning of the accumulation of information, You can not only pronounce to customers relevant to their needs, but also to encourage non-sold and high-margin rates literally with a pair of clicks of the bear.
Zvіdsi vysnovok. It’s unlikely that it’s a big deal for a small business, and the axis of winning the results of other companies’ efforts is obov’yazkovo.